自动(智能)驾驶系列|(二)环境感知与识别(2)
承接上文,本文主要涉及基于激光雷达的目标检测,主要分为对点云的概述和点云神经网络两部分。
目录
1.点云的概述
2.点云深度学习
2.1PointNet及PointNet++
2.2VoxelNet
2.3SECOND
2.4PointPillars
1.点云的概述
本部分,我们研究目标是对激光雷达目标检测进行研究,那么研究对象就是由激光雷达得到的稠密的点云。
首先研究点云我们类比于对图像的处理,点云具有无序性,他没有严格的例如像素的坐标关系,也没有像素的相邻像素的概念具有稀疏性,所以起初我们研究点云还是非常困难的。对于点云的无序性,我们可以通过构建八叉树和k-d树建立关系,从而有序化;点云没有相邻但是有临域的概念,通常采用k近邻(及欧式距离最近的k个点)和半径临域(r内的所有点)。目前的点云有多种表征形式如单个点构成的点云(pointCloud)、由点三角化得到的三角mesh网点等等,点云的常见格式有.pcd和.ply等等。
这里我们常用于处理点云相关的库是PCL(pointcloud Librariy)

Point Cloud Library | The Point Cloud Library (PCL) is a standalone, large scale, open project for 2D/3D image and point cloud processing.The Point Cloud Library (PCL) is a standalone, large scale, open project for 2D/3D image and point cloud processing. https://pointclouds.org/包含了多种对于点云处理的操作。
https://pointclouds.org/包含了多种对于点云处理的操作。

和图像领域一样我们也是通过法向量变化来判断边界,也分为单点特征(如位置、强度、法线、曲率)、局部特征(PFH、FPFH、SHOT等)、全局特征(VFH)等。
通过这些特性我们可以实现点云的特征点提取、match以及匹配等,可以基于特征来识别物体,下图是通过VFH聚类查询得到模型相似性最高的几个模型:
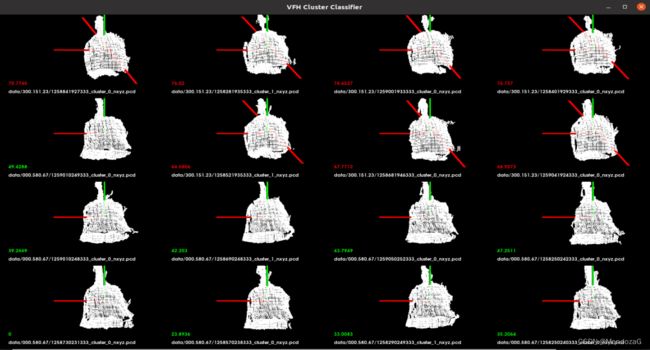
传统点云我们就说到这里。
2.点云深度学习
先放上3D图像分类、分割的发展图:
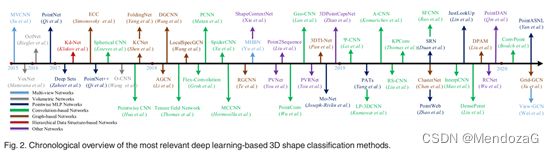

目前主流的对点云处理的方法有三种:point wise的(例如PointCloud系列)、体素化的(例如VoxelNet等)以及伪图像法(例如BEV方法)
2017年可以说是点云深度学习具有里程化的一年、PointNet的出现代表了以点云为处理对象的点云深度学习处理方法的诞生、苹果的VoxelNet则代表体素化处理的先河。
2.1PointNet及PointNet++
我们先来说PointNet,下面面是其网络结构,是比较简单的。

输入点云,通过Transformer-net保证点云位置都是一样的姿态保证匹配时的对应关系(后面证明这个网络加不加作用不大),通过一个权值共享的mlp,输出为n*64的feature map,再进行空间位置调整,再经过一个mlp扩维,输出n*1024,再通过max pool操作(文中最重要的操作)提取了1024维度的global feature再通过mlp完成分类任务,若是分割任务,则直接将提取到的global feature复制n份,和n*64的结果直接concat,在通过两个mlp,调整输出为n*m,每个输出的点都有m个socre用于分类。
PointNet咋ShapeNet上取得了较好的成果,但是缺点显而易见,对于局部特征没有很好的体现(Point wise)。而且对与空间中各个位置使用PointNet由于点云的稀疏性使得效率不高。

同年 Charles Qi又改进了PointNet ,提出了PointNet++:

对比PointNet,PointNet++的改动有,通过sampling和grouping构建局部邻域关系,不是直接采用maxpooling而采用逐级的降采样(Set Abstraction)得到不同层次局部及全局feature;在分割任务结合Skip connection进行上采样,多次使用pointnet结构输出全局的score。
在面对可能对于较为稀疏地方作用不佳的问题,提出了两种解决方法:

实际上是一个Encoder结构:
MSG:对于每层的中心点,进行不同半径的特征搜索,这样可以得到大小不一的同心球,再将结果拼接起来,这样最大的问题是消耗太大(epensive)it runs local PointNet at large scale neighborhoods for every centroid point,原文中这么描述。
对于MRG:则是对于两层的拼接,如上图右边的,是由两个vector拼接而成,分别对应两级(层)的特征点,左边的来源于更低层的子区域的特征的整合,而右边的则是直接通过单个PointNet对local(第二层)进行了特征的提取,也就是对应的Multi-Resolution。所以local(第二层)的点云密度比较低的时候,那么第一层由于是对第二层的提取(更加稀疏)显得更加不可靠,这时我么就降低第一层的权重而增加第二层的权重;相反的情况(当密度较高时),第一个向量因为反映了更低层级的features,所以可以提供更好的细节信息,就具有了在较低的级别上递归地检查较高分辨率的能力。这个效率更高,也是他们采用的方法。
在分割任务重,采用点云的反向插值:

再通过skip connection 这样就有了除了上一层的特征还有了local的信息,这样就有了全局point wise和local的信息(features)。
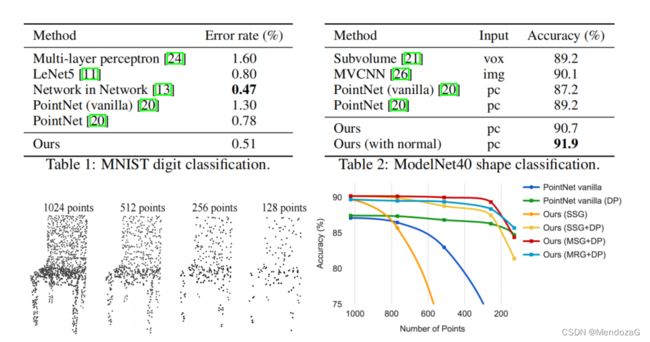
分类任务效果:
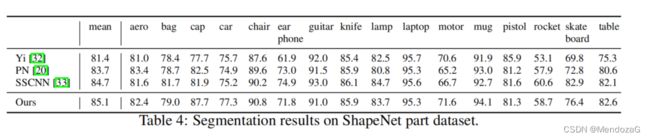
分割任务效果:
时间:

速度还是比较慢的。后续Charles Qi对其修改又有了 F-PointNet等等。
2.2VoxelNet
接下来说VoxelNet
是一种端到端的网络,不需要经过特征工程。文中也提到了PointNet及++,指出其需要很高的计算以及内存。受到广泛使用的RPN网络的启发,他们也想尝试这种方法,但是使用RPN网络要求数据需要稠密以及有组织性,显然直接拿到的激光雷达点云是不满足的。他们通过提出voxel feature encoding(VFE)layer使得体素中的点和点缠身联系,使用多个VFE层提取更加精细的3D特征。

Voxel Net将点云划分为空间中大小相等的3D体素块,使用堆叠的VFE层对美个体素编码,再通过三维卷积提取到local features,将点云转化为高纬度的体素,最后通过RPN网络,产生探测结果。如下图,分为三个部分。(也可从图上看出不同空间中的稀疏性不一)
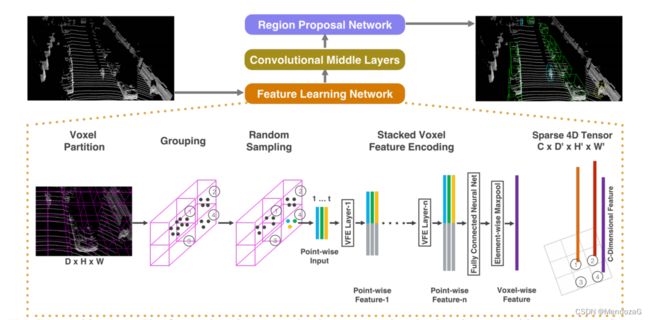
其最大的创新点就是创建了VFE layer,计算local 均值,求中心点,再通过偏移量表示每个点,通过FC层给每个点进行了编码,再通过 element wise的max pooling得到特征向量,再concat编码后的V,得到最后的features。

中间卷积层则都是由3D卷积、BN、和ReLU构成的。获取 voxel wise的features。
Conv3D(128, 64, 3, (2,1,1), (1,1,1)),
Conv3D(64, 64, 3, (1,1,1), (0,1,1)),
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
最终得到的tensor shape是(64,2,400,352)对Z维度进行了压缩,使得其变成和图像格式相似的三维。
RPN网络架构(分为3个block,进行了三次的FCN全卷积层,通过反卷积变成相同大小的特征图):

每种类别都有自己对应的网络,这个是其中一类(例如车)的结构,输出为分类的结果(channel为2,及RPN对应的2个anchor,对于车使用了90度和0度的两个anchor)以及anchor的回归结果(由于3D anchor,2*7,7代表了x,y,z,w,h,l六个方向的偏移量以及一个角度偏移量(相对于0度或者90度))。
人、车、骑手采用了不同的anchor策略和区分正负样本的IoU策略。在输入前做了数据增强。
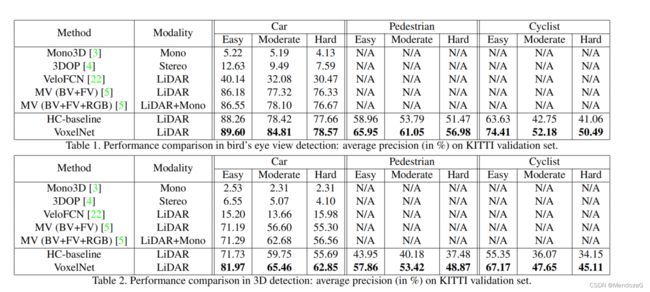
分两种形式在Kitti上的(将kitti trainning set 划分为3712与3769分别作为训练集和测试集)表现如上,仅用到了Lidar。
将3D bbox投影到图像中:
文中没有提到运行速度,是因为在计算三维卷积时占用大量内存,仅有2FPS远不能达到实时处理。
2.3SECOND
SECOND(Sparsely Embedded CONvolutional Detection)
本文主要对于voxelnet有三大改进:
1.加入了稀疏卷积,大大提高了效率;
2.对于VoxelNet对于朝向的损失函数设置问题进行了修正(对于朝向相反的情况VoxelNet给了过于大的惩罚这是有问题的);
3.提出了新的数据增强方法。
由于VoxelNet的3D卷积很耗时,而大量的空间位置都是空的(甚至90%以上),这大大减缓了效率。SECOND提出了用稀疏卷积,关于稀疏卷积理解:
通俗易懂的解释Sparse Convolution过程 - 知乎
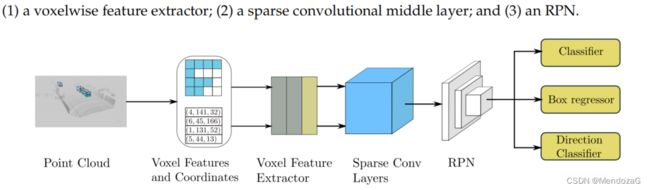
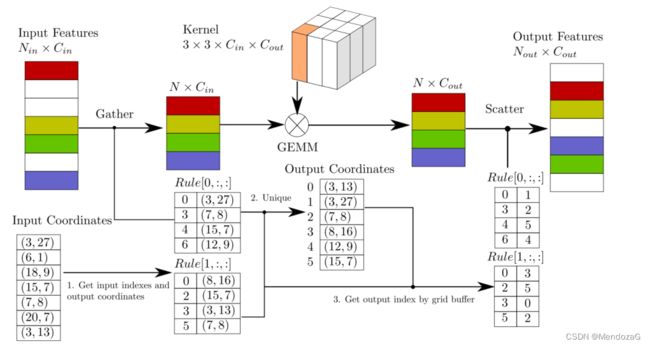
Rule稀疏卷积算法(传统的需要GPU与CPU交换信息,效率较慢)
中间特征提取层就用到了两个稀疏卷积层,通过压缩z轴,获得2D图像类似的数据:

Loss的改变:使用smoothL1,并代入的是sin

好处是,解决了翻转的问题(0和pi),适合角度翻转的IoU方程(这个项目都是正的),通过设计一个Classifier(yaw和z轴GT夹角来确定正负,大于零为正反之为负)。在分类问题采用了常用的Focal Loss。
在数据增强阶段,他们建立了数据库,每次训练随机选择一些GT对应的点云加入到原来的点云中,这样就更加丰富了,并且可以模拟出不同环境下的检测。但是有可能加入的是不符合逻辑的,他们通过碰撞检测移除了重叠单元。
结果对比:
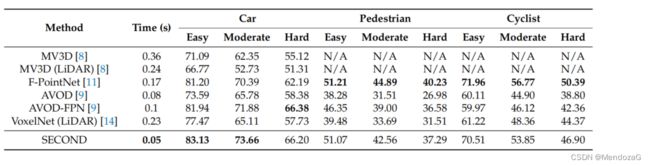
BEV结果:

可以看出速度快了很多。
2.4PointPillars
本节最后再说一个网络
PointPlillars
推荐阅读:
PointPillars论文解析和OpenPCDet代码解析_NNNNNathan的博客-CSDN博客_pointpillars代码
也是受到了SECOND的启发,采用稀疏结构,来自工业界,目前成为了非常主流的网络结构。有时候会用其作为点云数据集效果的评判。是一种single stage的方法:

PP代表本文的PointPillars,F代表F-Pointnet,A代表AVOD,S代表SECOND,V代表VoxelNet。
比较的是在Kitti上的BEV表现。
不同于SECOND,PointPillars采用的是伪图像的2D卷积。

本文最大的亮点就是提出了用Pillars也就是柱子。
对于激光雷达点云数据来说,最基础的有四个维度即(x,y,z,r)其中r为强度,我们把空间分成一个个pillar,每个pillar中计算中心点,并增加五个维度偏移量表示(这点和VoxelNet相似),中心点x,y,z的center,以及x与y方向的偏移量,加上原来的四个维度一共九维度(代码实现有的也计算了z的偏移量总共十维)
这样我们就把N*3(N个点云结构)变成了(D,P,N),D表示点云特征的维度(这里为9),P表示非空的立方体柱(index),N表示一个柱子中有多少个点。在运用中,使用简化的PointNet网络,进行数据特征提取,得到一个(C,P,N)的张量,然后用maxpooling操作输出特征(C,P),最后将其重新将每个index对应的features放回到原来的PIlllars得到伪图像。
在2D的BackBone中我们提取到的都是不为0的Pillars对应的伪图像,但是这个结果仍然很稀疏,通过卷积核拼接实现特征提取和融合。
对于检测头,参考了SSD的检测,使用了anchor,分为三个尺度(对应车、行人、自行车),每个框都有两种角度0度和90度,正负昂本的IoU设定也不同。(实现的时候有的直接使用了一个网络)
LossFun采用了和前面类似的,角度上用了和SECOND一样的sin方法。定位误差用了smoothL1,分类任务使用了focal loss,先验框分类:
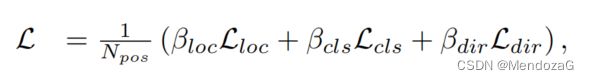
结果:

帧率大大提高。
这部分网络比较多,本部分暂时更到这里,后面还有发展:例如2020年的PV—RCNN等,这里就不赘述,有机会可能会补充。
下一节将介绍其他任务方法。欢迎大家交流!