GoogLeNet网络结构详解
毋论版本,重在结构
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed,Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich.
Going Deeper with Convolutions
https://arxiv.org/abs/1409.4842v1
1 GoogLeNet概述
下面我用尽量简短的文字描述一下GoogLeNet的发展。
1.1 Intro
GoogLeNet是谷歌公司发布的深度神经网络架构,为了向LeNet致敬,因此取名为GoogLeNet。
论文题目为Going Deeper with Convolutions,受电影盗梦空间“We need to go deeper”启发。

1.2 Motivation
在上一篇VGG中,不同的深度、不同宽度的网络结构效果不同,总体上来看似乎是越深越宽的网络预测效果越理想,这是我们直观的感受。GoogLeNet论文中也指出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是增加模型宽度(层核或者神经元数),但是一般情况下更深或更宽的网络会出现以下问题:
1)网络越深,梯度越往后穿越容易消失,难以优化模型;
2)参数太多,容易过拟合,若训练数据集有限,这一问题更加突出;
3)计算资源要求高,而且在训练过程中会使得很多参数趋于0,浪费资源
总结起来就是更大的网络容易产生过拟合且计算复杂度太高。针对这两点,GoogLeNet认为最基本的方法是使用稀疏连接代替全连接和卷积操作。
基于保持神经网络结构的稀疏性,又能充分利用密集矩阵的高计算性能的出发点,GoogleNet提出了名为Inception的模块化结构来实现此目的。
Inception是一种网中网(Network In Network)的结构,基于此结构的整个网络的宽度和深度都可扩大,并且能够带来2-3倍的性能提升,Inception目前有v1到v4总共4个版本。
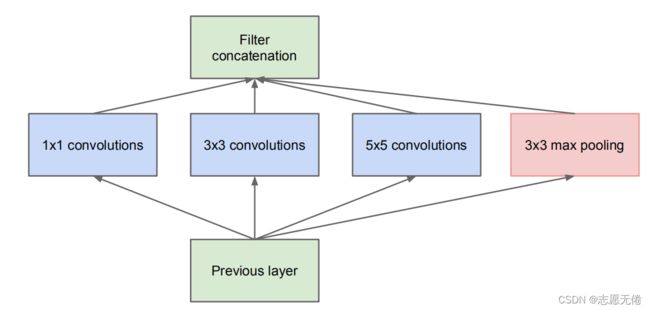
2 Inception详解
Inception是个网中网,网中总共包含4个子网,该结构将CNN 中常用的卷积(1x1,3x3, 5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺寸的适应性。下面结合Inception的代码及论文中的Inception模块具体解释一下:
class Inception(nn.Module):
def __init__(self, input_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj):
super().__init__()
# 1x1conv branch
self.b1 = nn.Sequential(
nn.Conv2d(input_channels, n1x1, kernel_size=1),
nn.BatchNorm2d(n1x1),
nn.ReLU(inplace=True)
)
# 1x1conv -> 3x3conv branch
self.b2 = nn.Sequential(
nn.Conv2d(input_channels, n3x3_reduce, kernel_size=1),
nn.BatchNorm2d(n3x3_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(n3x3_reduce, n3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(n3x3),
nn.ReLU(inplace=True)
)
# 1x1conv -> 5x5conv branch
# use 2 3x3 conv filters stacked instead of 1 5x5 filters to obtain the same receptive field with fewer parameters
self.b3 = nn.Sequential(
nn.Conv2d(input_channels, n5x5_reduce, kernel_size=1),
nn.BatchNorm2d(n5x5_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(n5x5_reduce, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5, n5x5),
nn.ReLU(inplace=True),
nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(inplace=True)
)
# 3x3pooling -> 1x1conv
# same conv
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(input_channels, pool_proj, kernel_size=1),
nn.BatchNorm2d(pool_proj),
nn.ReLU(inplace=True)
)
def forward(self, x):
return torch.cat([self.b1(x), self.b2(x), self.b3(x), self.b4(x)], dim=1)
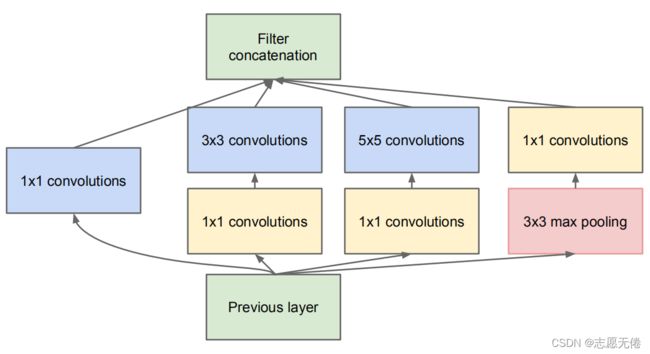
2.1 1x1conv branch
1x1conv branch就是上图中最左侧的分支,利用1x1卷积将网络加宽后进行BatchNorm最后再激活
2.2 1x1conv -> 3x3conv branch
这一步卷积核是3x3的尺寸,但是在进行3x3卷积之前,特征图会先经过1x1的卷积层降参(1x1卷积会使网络参数显著降低)
2.3 1x1conv -> 5x5conv branch
先经过1x1的卷积降参,后经过5x5的卷积层进行特征提取
InceptionV1中是用的kernel=5的卷积核进行特征提取的,在V2中将5x5换成了2个3x3的卷积核,因为二者等效且3x3的卷积参数量约是5x5的卷积操作的1/3。所以代码中的2个3x3卷积操作实际上就是图中右侧5x5的卷积操作。
2.4 3x3pooling -> 1x1conv
这里虽然用了池化核,但是具体的操作更像卷积。
以往的池化操作步长stride是与卷积核kernel大小相同的,并且不进行填充,这样HxW的特征图经过池化层后大小就变成H/s x W/s;
这里的池化操作stride=1,padding=1,kernel=3,实际上经过池化操作后特征图大小并不会改变,仅仅是利用池化层来提取与卷积操作不同的特征表达。
2.5 Inception in GoogleNet
结合GoogLeNet使用Inception时的操作,连同操作中的参数来讲更容易理解。
class GoogleNet(nn.Module):
def __init__(self, num_class=100):
super().__init__()
self.prelayer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 192, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(192),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
def forward(self, x):
x = self.prelayer(x)
x = self.maxpool(x)
x = self.a3(x)
x = self.b3(x)
return x
上面是GoogleNet中的部分代码,主要看Inception部分,其输入参数有7个:
Inception(input_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj)
Inception(192 , 64, 96, 128, 16, 32, 32)
例如在1x1conv -> 3x3conv branch这里:输入的channel=192,网络会先用1x1的卷积核将channel进行reduce到96,再利用3x3的卷积进行特征提取,提取后的channel为128,其他分支类同
那么请问,经过self.a3后,网络的channel输出为多少呢?
其实就是sele.a3中的第2、4、6、7个参数之和,即64+128+32+32=256
这也是下一层Inceptionself.b3中的input_channels
2.6 one more thing
明白以上几点,GoogleNet也就没什么神秘的了,说白了就是把Inception模块化后进行模块的串接,并且不会出现之前所说的3个问题。
2.6.1 We need to go deeper
开头所说的We need to go deeper也是电影《盗梦空间》中的一个表达,它通常使用电影中的屏幕截图来显示图像宏和垂直的多窗格。

2.6.2 辅助分类器
GoogLeNet用到了辅助分类器。GoogleNet一共有22层,除了最后一层的输出结果,中间节点的分类效果也有可能是很好的(例如叶片病虫害分类任务更注重浅层的纹理特征),所以GoogLeNet将中间某一层的输出作为分类,并以一个较小的权重(0.3和0.3)加到最终的分类结果中,一共有2个这样的辅助分类节点。
辅助分类器相当于对模型做了融合,同时给网络增加了反向传播的梯度信号,在一定程度上提供了正则化的作用。
3 源码及网络结构
以下是不带辅助分类器的GoogLeNet源码
import torch
import torch.nn as nn
class Inception(nn.Module):
def __init__(self, input_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj):
super().__init__()
#1x1conv branch
self.b1 = nn.Sequential(
nn.Conv2d(input_channels, n1x1, kernel_size=1),
nn.BatchNorm2d(n1x1),
nn.ReLU(inplace=True)
)
#1x1conv -> 3x3conv branch
self.b2 = nn.Sequential(
nn.Conv2d(input_channels, n3x3_reduce, kernel_size=1),
nn.BatchNorm2d(n3x3_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(n3x3_reduce, n3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(n3x3),
nn.ReLU(inplace=True)
)
#1x1conv -> 5x5conv branch
#we use 2 3x3 conv filters stacked instead
#of 1 5x5 filters to obtain the same receptive
#field with fewer parameters
self.b3 = nn.Sequential(
nn.Conv2d(input_channels, n5x5_reduce, kernel_size=1),
nn.BatchNorm2d(n5x5_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(n5x5_reduce, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5, n5x5),
nn.ReLU(inplace=True),
nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(inplace=True)
)
#3x3pooling -> 1x1conv
#same conv
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(input_channels, pool_proj, kernel_size=1),
nn.BatchNorm2d(pool_proj),
nn.ReLU(inplace=True)
)
def forward(self, x):
return torch.cat([self.b1(x), self.b2(x), self.b3(x), self.b4(x)], dim=1)
class GoogleNet(nn.Module):
def __init__(self, num_class=100):
super().__init__()
self.prelayer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 192, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(192),
nn.ReLU(inplace=True),
)
#although we only use 1 conv layer as prelayer,
#we still use name a3, b3.......
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
##"""In general, an Inception network is a network consisting of
##modules of the above type stacked upon each other, with occasional
##max-pooling layers with stride 2 to halve the resolution of the
##grid"""
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
#input feature size: 8*8*1024
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout2d(p=0.4)
self.linear = nn.Linear(1024, num_class)
def forward(self, x):
x = self.prelayer(x)
x = self.maxpool(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool(x)
x = self.a4(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
x = self.e4(x)
x = self.maxpool(x)
x = self.a5(x)
x = self.b5(x)
#"""It was found that a move from fully connected layers to
#average pooling improved the top-1 accuracy by about 0.6%,
#however the use of dropout remained essential even after
#removing the fully connected layers."""
x = self.avgpool(x)
x = self.dropout(x)
x = x.view(x.size()[0], -1)
x = self.linear(x)
return x
def googlenet():
return GoogleNet()
4 每日古文
宋濂 〔明代〕
余幼时即嗜学。家贫,无从致书以观,每假借于藏书之家,手自笔录,计日以还。天大寒,砚冰坚,手指不可屈伸,弗之怠。录毕,走送之,不敢稍逾约。以是人多以书假余,余因得遍观群书。既加冠,益慕圣贤之道 。又患无硕师名人与游,尝趋百里外,从乡之先达执经叩问。先达德隆望尊,门人弟子填其室,未尝稍降辞色。余立侍左右,援疑质理,俯身倾耳以请;或遇其叱咄,色愈恭,礼愈至,不敢出一言以复;俟其欣悦,则又请焉。故余虽愚,卒获有所闻。
当余之从师也,负箧曳屣行深山巨谷中。穷冬烈风,大雪深数尺,足肤皲裂而不知。至舍,四支僵劲不能动,媵人持汤沃灌,以衾拥覆,久而乃和。寓逆旅,主人日再食,无鲜肥滋味之享。同舍生皆被绮绣,戴朱缨宝饰之帽,腰白玉之环,左佩刀,右备容臭,烨然若神人;余则缊袍敝衣处其间,略无慕艳意,以中有足乐者,不知口体之奉不若人也。盖余之勤且艰若此。 今虽耄老,未有所成,犹幸预君子之列,而承天子之宠光,缀公卿之后,日侍坐备顾问,四海亦谬称其氏名,况才之过于余者乎?
今诸生学于太学,县官日有廪稍之供,父母岁有裘葛之遗,无冻馁之患矣;坐大厦之下而诵诗书,无奔走之劳矣;有司业、博士为之师,未有问而不告、求而不得者也;凡所宜有之书,皆集于此,不必若余之手录,假诸人而后见也。其业有不精、德有不成者,非天质之卑,则心不若余之专耳,岂他人之过哉?
东阳马生君则,在太学已二年,流辈甚称其贤。余朝京师,生以乡人子谒余,撰长书以为贽,辞甚畅达。与之论辨,言和而色夷。自谓少时用心于学甚劳,是可谓善学者矣。其将归见其亲也,余故道为学之难以告之。谓余勉乡人以学者,余之志也;诋我夸际遇之盛而骄乡人者,岂知予者哉?