全文链接:http://tecdat.cn/?p=27831
随着P2P网络金融平台的交易量的激增,其交易数据不能得到充分有效地利用。将聚类分析引入到P2P网络金融平台的管理之中,利用聚类分析技术对P2P网络金融平台的现存数据进行分析,进而为借款人、出款人和管理人员提供服务就成为P2P网络金融平台在发展过程中面临的新的课题。
鉴于上述出现的问题和需求,本文期望研究将聚类分析技术应用于P2P网络金融平台来探讨借款人的行为规律和出款人的行为规律,从而有益于平台的建设和发展。
聚类分析
聚类分析的定义
聚类分析,是知识发现中的一项重要研究内容,又被称为群分析类,简单来说就是具有相似特征的元素的集合。聚类,就是将具有较高的相似性的元素集中起来,最终,形成几个子集。
聚类分析的算法及流程
聚类算法是聚类技术优越性的主要体现,算法的可伸缩性、对不同属性的处理能力、对任意形状的聚类能力、对噪声数据的处理能力、对于输入记录的顺序不敏感、高维性、基于约束的聚类以及可解释性和可用性可衡量算法的好坏。
划分方法:划分方法是按照一定的规则或不同的划分方法将给定的大量数据通过划分为成多个组或簇, 其中,每个组或簇中一般至少包含一组数据, 不同类型的数据只能属于不同的组,每个组之间具有明显的不同。
层次方法:层次方法进行聚类分析是通过将数据划分为若干组形成树形的结构,也可根据构建数方式的不同分为自顶向下的分裂算法和自底向上的凝聚算法两种。
基于密度的方法:该方法是指通过相邻局域的密度超过某个阂值而发生持续聚类的方法, 也就是说, 在每个给定的区域内都将包含一定数目的点, 从而通过该方法来过滤掉一些异常点, 提高数据分析的效率。
典型的聚类分析过程一般主要包括数据(或称之为样本或模式)准备、特征选择和特征提取、接近度计算、聚类(或分组)、对聚类结果进行有效性评估等步骤。
聚类分析过程:
数据的准备过程:也就是数据的预处理,包括特征标准化和降维。
特征的选择过程:从最初的特征中选择最有效的特征存储于向量中。
特征的提取过程:通过对所选择的特征进行转换形成新的突出特征。
聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量;然后执行聚类或分组。
聚类结果评估:是指对聚类结果进行评估。若结果满意,可结束;如果不满意需调整上述“特征提取”环节,直至满意为止。
借款人行为聚类分析
研究数据说明
本文数据来源于平台后台数据库中历史交易信息,包括借款相关信息以及出借人信息等。
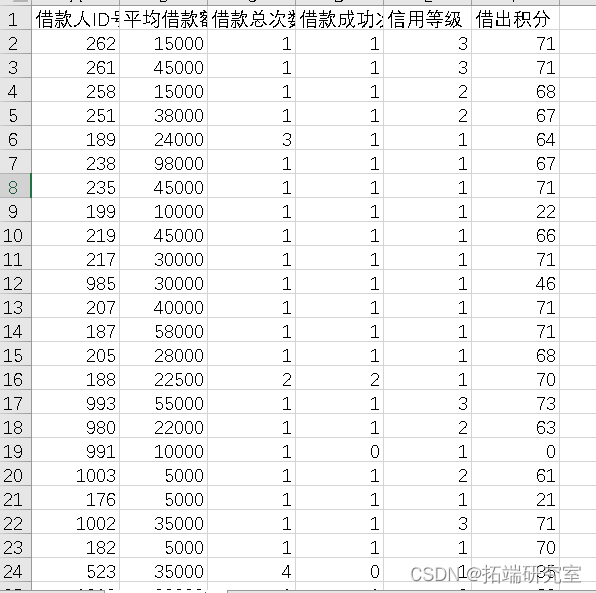
平台借款的状态分为:审核未通过、流标(指一个借款列表的投标期限已过,但是贷款没有足额筹集齐,即贷款失败)、借款成功(指借款满标,借贷关系已经成立)。
经过数据筛选梳理,最终研究的样本包括999条借款列表。其中,248审核未通过的有条;209条是流标;542条成功借款,169条已还完借款。成功交易总额达3090.93万元。
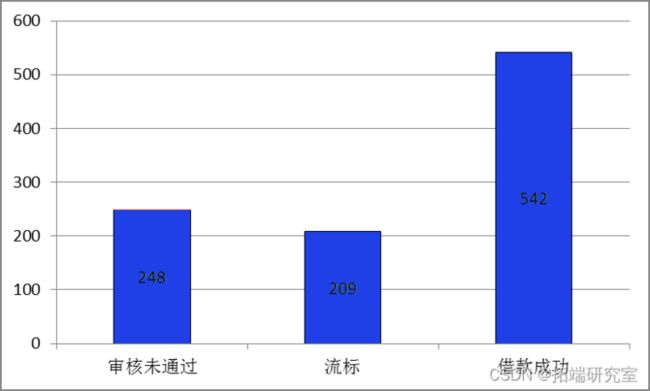
图 :样本数据组成
就整体研究数据来看,审核未通过的借款所占比例达到24.8%,流标所占比例达到20.9%,借款成功仅有54.3%,可以看出借款成功率亟需提高。
聚类分析研究目的
由于P2P网络借贷平台具有门槛低、限制少等特点,这往往加剧了P2P网络借贷的风险,所以,其信用体系建设至关重要。其信用体系是根据借款人的认证信息以及借还款情况来确定借款人的信用积分,根据信用积分分为AA、A、B、C、D、E、HR七个信用等级,其中AA类代表最高的信用等级,表示借款人在平台上借贷活跃且信用良好,信用风险低;然后逐渐递减,HR类表示信用等级最低、信用风险较大的借款人。
聚类分析的模型设计
借款人总体数据统计
本文从借款人信息表中提取出923条不重复且有效条的借款人信息。923位借款人中AA级仅1位,而A级也仅1位,而B类与C类相对较多,最多的是D、E、HR类占总人数的98%。
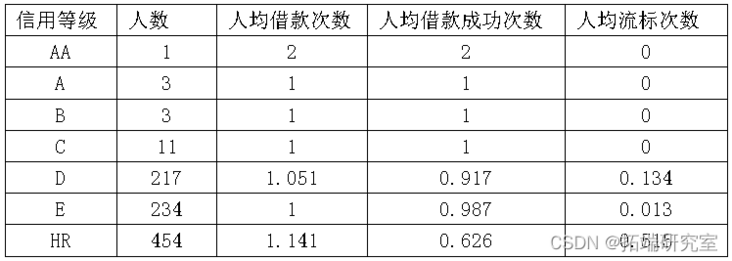
从表可以看出,借款人中AA、A、B、C、D、E、HR7类的人均借款成功次数次数大于人均流标次数。从平均值总体上看,借款人信用等级越低,其平均流标次数会逐渐增大,平均借款成功次数会逐渐减少。由此可以看出,借款人的信用等级越高,其借款成功的概率越高。但在E类借款人上,出现特殊情况,其借款人平均借款成功次数大于D类借款人,而平均流标次数小于D类借款人,由此,可以看出等级划分的不合理性。另一方面,从基数上来看,由于信用等级高的AA、A、B、C类借款人基数小,尽管借款成功率很高,但总借款次数远小于E、HR类借款人。由此说明,信用等级越高并不意味着借款成功次数会越多,而信用等级越低也并不意味着借款成功次数会越少。与丁婕信用等级越高,借款人的成功与失败次数都会更高结论相似。
数据准备与聚类变量选取
通过对数据源中借款人信息的整合,得到了用户活动数据,包括用户的借款次数、成功借款次数、信用等级、借款总额等信息。为了了解平台用户的不同行为模式与特征,这里本文选取借款人ID号、平均借款额度、借款总次数、借款成功次数、信用等级、借出积分(借款人作为出借人进行借贷所获得的借出积分)作为聚类变量。
聚类分析的应用实现
本文使用SPSS对923位有效借款人的数据进行聚类分析。其中,选择信用等级作为分类变量,由于样本数据既有连续变量也有分类变量,所以,本文使用两阶段聚类。与SPSS中提供的KMeans聚类法和层次聚类分析法不同的是,两阶段聚类法采用对数极大似然估计值度量类间距离,并能根据施瓦兹贝叶斯准则(BIC)或Akaike信息准则(AIC)等指标自动确定最佳聚类个数。
利用SPSS聚类过程如下:
将数据文件导入SPSS中。
点击“确认”按钮,得到结果,如下图。
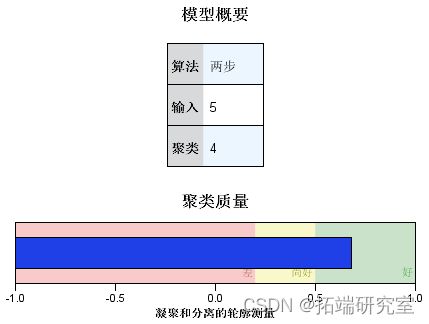
图 二阶聚类分析结果图
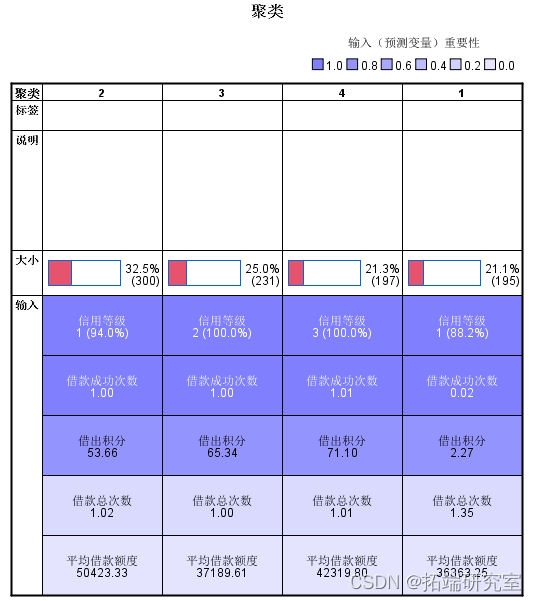
通过SPSS两阶段聚类方法,借款人被分为了4类,结果如下:
各类别用户组成和特征如表:

从表中可以得出,两阶段聚类分析并没有完全按照平台自身制定的信用等级对借款人进行划分,而是挖掘出借款人更为精确的行为信息。
第一类别中,HR等级借款人所占比重最大,D、E次之,该类借款人借款总次数在4类中最高,但平均借款额度、借款成功次数以及借出积分在4类中最低,可以看出此类别借款人虽然在平台上较为活跃但其值得信任程度很低,存在较为严重的诈骗风险。
第二类别中, D类信用级别借款人占100%,虽然平均借款款额度与借款总次数都不是最高,但是其借款成功次数与借出积分都是四类中最高水平,可以看出,此类借款人虽然以借款人身份在平台上不是很活跃,但是其发布借款的满标比例很高,并且他们还经常以出借人的身份活跃在平台上。
出借人行为聚类分析
聚类分析研究目的
本文借助聚类分析的方法,对P2P网络借贷平台中出借人进行客户细分,从而找出出借人的类别,最终使P2P网络借贷平台中对出借人有合理和准确的分类。
客户细分
基于RFM模型的客户分类原理分析
客户细分的方法有许多,但最终衡量方法是否适合的标准应该是细分结果的精确性以及与企业管理的匹配度。
RFM模型常用的客户细分的方法之一,作为一种定量分析模型,一般用于执行营销活动之前的预测与分析。其中,R(recenty)最近一次消费,是指最近一次消费与当前日期的时间间隔,理论上讲,客户上一次消费距离现在越近,对即时提供的商品或者服务有反应的几率越大;F(frequency)消费频率,是指某一时间段内,客户消费的次数,通常,客户消费次数越高,忠诚度就越高,也就意味着可以通过增加客户的消费次数来拥有更多的市场占有率;M(monetary)消费金额,是指某一段时间内,客户消费的总金额,消费金额是所有数据率报告的支柱,也可以验证“帕雷托法则”——公司80%的收入来自20%的顾客,通过消费金额可以看出哪些是重点客户,为公司营业额贡献最大。
根据P2P网络借贷平台的特点,将RFM指标做相应改变,如表。

基于K-Means聚类算法的客户分类
K-Means聚类法,也称K-均值聚类法广泛应用于基于划分的聚类算法。K-Means算法根据输入的分类个数k值,将聚类分析中的所有对象划分为k个分组,每个分组内对象之间有较高相似度。本文以K-Means聚类法为工具,以加权RFM为度量值,为P2P网络借贷平台中出借人进行分类,基本思路为:
1)将RFM中三指标标准化,在加权之前需要对数据进行标准化处理。用Ri、Fi、Mi分别表示标准化后的出借人i的R、F、M值。
并且,Ri=(RM-R)/(RM- RN),Fi=(F-FN)/(FM-FN),Mi=(M-MN)/(MM-MN) (1)
其中,RM、 RN分别为出借人中R的最大值与最小值,FM、FN分别为出借人中F的最大值与最小值,MM、MN分表为出借人M的最大值与最小值。
2)确定聚类分组的个数k。
3)对指标进行加权,并利用K-Means聚类法进行聚类得到k类出借人。
4)将每类出借人的RFM均值与总RFM均值进行比较,最后确定每类出借人的客户类型。
聚类分析在出借人客户细分中的应用实现
本文从借款人信息表中提取出500不重复且有效条的借款人信息。相关重要数据如下表。
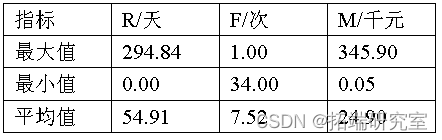
使用K-means均值进行聚类时,需要预先判断其聚类的类别数。RFM模型中,出借人客户分类是通过每个客户类别RFM平均值与总RFM平均值相比较来决定,而单个指标的比较只能有2种情况:大于(等于)或小于平均值,因此可能有2×2×2=8种类别,所以,本文将聚类的个数定为8个。首先,根据公式(1)对出借人的R、F、M值进行标准化,然后采用SPSS19.0软件对标准化的出借人R、F、M值进行K-Means聚类分析。
最后得到8类出借人类型,并将8类出借人的R、F、M均值与总R、F、M均值比较,其中“↑”表示大于平均值,“↓”表示小于平均值,结果如下表。

对于平台的用户培养策略讨论
如今,国内P2P网络借贷平台发展迅速,但是大多数都忽略了用户培养这部分,特别是对于出借人。平台在用户培养这个方面还未形成完善有效的机制与策略,短时间内,可能并不能体现出用户培养的重要性,但是长时间很有可能造成优质用户流失。
通过前面对借款人的聚类分析可以看出,借款人中存在一些重点发展客户,可能信用等级不高但是在平台上借款次数较多且能够按时还款,可以将这类借款人作为重点发展对象,提供给他们一些鼓励与优惠政策。对于平台上已经存在的优质借款人,可以根据他们实际需求推出相应的借款项目。

最受欢迎的见解
2.R语言基于温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
5.Python Monte Carlo K-Means聚类实战
7.R语言KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化
8.PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像