UIE: 信息抽取的大一统模型

论文链接: https://arxiv.org/abs/2203.12277
背景
最近由于业务需要,一直在关注信息抽取领域的一些文章,实验上尝试了BERT+Softmax、BERT+NER以及GlobalPointer等模型,效果都还可以,就是标数据有点费人。所以,想找一些few-shot效果比较好的模型,可以辅助标注。无意间,就发现了这篇论文,尝试做了zero-shot实验,效果很惊人。
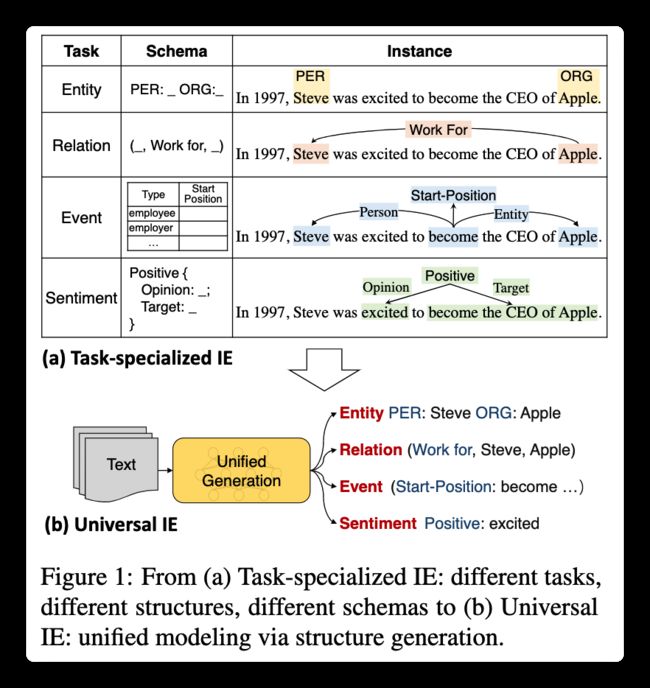
众所周知,信息抽取通常包含常见的四个子任务: 实体抽取、关系抽取、事件抽取以及情感分析等。在过去,因为不同的任务识别的实体、事件类型等等都不一样,所以针对特定的任务要训练特定的模型,定制化较高,不具有通用性。针对这种问题,本文从生成模型的角度去考虑信息抽取的问题,使得这几种子任务可以通过一个模型去完成。
下面我们看看模型的具体部分。
模型
SEL(Structured Extraction Language)
信息抽取任务的标签表示多种多样,有采用SBME的方式,也有直接用起始终止位置来表示的。本文为了统一建模,需要将不同的IE(information extraction)任务标签编码成统一的形式。因此提出了一种结构化抽取语言SEL。
IE结构其实可以归纳成两个原子操作:
- Spotting: 表示的是在句子中定位目标信息的片段,如事件中的实体或触发词。
- Associating: 表示的是两个不同信息片段之间的关系。例如,实体对之间的关系或事件的角色等。
举个例子:
假设输入的句子为:“Steve became CEO of Apple in 1997.”,有三个实体,人: Steve、公司:Apple、时间: 1997. 下图则为结构化抽取语言对于抽取结构的表示。如蓝色代表的是关系抽取,红色代表的事件抽取,最后则为实体的抽取。红色部分的触发词是became。雇主是Apple,雇员是Steve,时间在1997年。

可以看出SEL的优点有:
- 对不同的IE结构进行统一编码,因此可以将不同的IE任务建模为相同的text-to-structure生成过程;
- 有效地将一个句子的所有提取结果表示为同一结构,能够自然地进行联合提取;
- 生成的输出结构非常紧凑,大大降低了解码的复杂度。
SSI(Structural Schema Instructor)
使用SEL, UIE(本文提出的模型)可以均匀地生成不同的IE结构。然而,由于不同的IE任务有不同的模式,在提取过程中,如何自适应地控制我们想要生成的信息? 本文提出了一种结构化模式的指导,类似于Prompt。把需要提取的关系类型、实体类型等和句子进行拼接。如下图:

给定结构化模式的抽取类型S以及文本的序列X,通过UIE模型可以生成SEL结构化的信息。即:

具体的输入可以表示为:

其实就是上图的意思,将要抽取的类型和文本拼接起来,输入给模型。这里可能涉及到本文的一丢丢缺陷了,如果抽取的实体类型、关系类型非常多的话,输入文本长度可能会非常长,效率就是个大问题了。。
UIE( Universal Information Extraction)
前面讲了那么多,感觉还是云里雾里,模型到底是什么呢?其实就是一个标准的Transformer,包含了Encoder和Decoder。首先将SSI信息和句子拼接,用encoder去编码,如下所示:
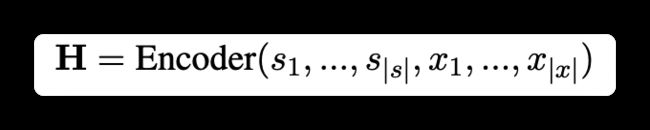
其中 s 1 , . . . , s ∣ s ∣ s_1, ..., s_{|s|} s1,...,s∣s∣是SSI信息, x 1 , . . . , x ∣ x ∣ x_1, ..., x_{|x|} x1,...,x∣x∣是句子。
接着,通过自回归的方式解码出抽取的信息。如下所示:
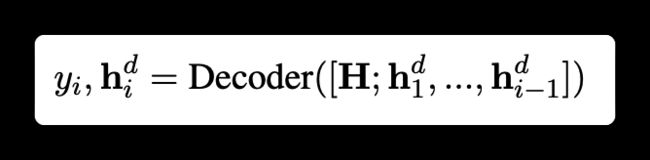
读到这里,有人可能感觉此方法有点扯,生成任务是不可控,如果生成的信息结构不符合前面定义的结构,那怎样抽出信息呢?作者通过了定义不同的损失避免的这种情况。
loss 设计
Text-to-Structure Pre-training using
首先,定义 D p a i r = ( x , y ) D_{pair} = {(x, y)} Dpair=(x,y)。具体x输入为:[spot] person [asso] work for [text]Steve became CEO of Apple in 1997.,y则为:((person: Steve(work for: Apple)))。可以发现在生成的过程中,person和work for在输出时是肯定要出现的。这两个东西就是我们此前定义的spotting、associating。作者发现如果在生成的token中,加个损失,用来判断当前token是不是spotting或者是不是associating效果会变好。这里的正样本就是spotting或者assocating,负样本则是随机抽取的token。损失如下:

Structure Generation Pre-training
这个损失就很容易理解了,就是生成任务中,自回归的一个损失。如下所示:

Retrofitting Semantic Representation
为了提高UIE的语义表示,作者还加了MLM任务。损失如下:
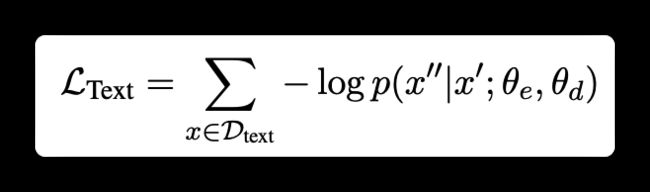
这里的MASK是针对目标文本的。跟bert有点区别。
最后将这三种损失相加,进行大规模的预训练。

至此,模型就讲到这里了。最后看看实验部分。
实验
本文在13个IE基准上进行了实验,涉及4个很有代表性的IE任务(包括实体提取、关系提取、事件提取、结构化情感提取)及其组合(例如,联合实体-关系提取)。结果如下:

其中SEL为没有预训练的UIE模型,也就是直接用T5做这种生成,可以发现效果也非常好。生成模型的大一统指日可待了。加上预训练,效果也得到了不同程度的提升。
另外,作者也给除了few-shot的效果,如下:

有点惊人。。。。