视觉-语言预训练模型综述
Li F, Zhang H, Zhang Y F, et al. Vision-Language Intelligence: Tasks, Representation Learning, and Large Models[J]. arXiv preprint arXiv:2203.01922, 2022.
按照时间顺序将VLP模型分为三个阶段:特定任务的方法,视觉语言预训练(VLP)方法,以及由大规模弱标记数据加持的更大的模型三大类。
- 第一阶段:特定任务方法
三类主流任务:Image Captioning、VQA、Image Text Matching
Image Captioning:早期图像字幕方法的发展主要有两个方面,即视觉表示和语言解码。视觉表示从图像级的全局特征发展到细粒度和对象级的区域特征,语言解码从LSTM发展到基于注意力的模型。
VQA:核心是获得图像和语言的联合表示(问题)。该领域的研究人员采用了各种方法来更好地编码和融合图像和语言,这为以下的VLP方法奠定了基础。这个领域的大多数工作都是独立地对图像和语言进行编码,然后将它们融合,这类似于VLP的双流方法。也有工作将图像嵌入视为一种语言标记,这类似于单流方法。
Image-Text Matching:图像-文本匹配是一个计算图像与文本相似性的问题。早期的工作将图像和文本编码为全局特征,并通过点积计算它们的余弦相似度。随后的工作采用了细粒度的特征——图像的对象级特征和语言的文字级特征。他们还开发了更复杂的算法来计算相似性,比如交叉注意力。
其他任务:Text-to-Image Generation、Visual Dialog、Visual Reasoning、Visual Entailment、Phrase Grounding and Reference Expression Comprehension
小结:在特定任务方法的时代,研究者为不同的任务设计特定的模型。尽管不同任务的模型差异很大,但它们遵循着相似的轨迹。它们都有三个阶段,如图1所示。这个时代的技术发展为VLP时代奠定了基础。

- 第二阶段: VISION LANGUAGE JOINT REPRESENTATION
主要任务是学习 object-level(对象级意味着学习到的表示法是细粒度的,并与对象对齐,而不是对整个图像齐), language-aligned(学习与语言单词保持一致的视觉特征,这是大多数VLP方法的目标), and semantic-rich visual representations(语义丰富致力于一种可以推广到广泛语义概念的表示,需要从大规模数据集中学习)。
Modality Embedding
1)Text Tokenization and Embedding
Word2Vec、BERT
2) Visual Tokenization and Embedding
region based:由预先训练好的对象检测器提取,常用Faster R-CNN,
grid based:网格特征是直接从相同大小的图像网格中用卷积特征提取器提取。网格特征的优点主要是两方面。第一个是方便的,因为它不需要一个预先训练过的对象检测器。第二,除了突出的对象外,网格特征还包含背景,这可能对下游任务有用。区域特征的优点是,它们有助于VLP模型关注图像中有意义的区域。这些区域通常与下游任务密切相关。
patch based:块特征通常通过均匀分割的图像块上的线性投影提取。斑块特征与网格特征的主要区别是,网格特征是从卷积模型的特征图中提取的,而斑块特征则直接利用线性投影。这种方式的优点是效率高。
网格特征和区域特征通常来自于预先训练过的卷积模型,而补丁特征可以简单地通过一个线性层来嵌入。
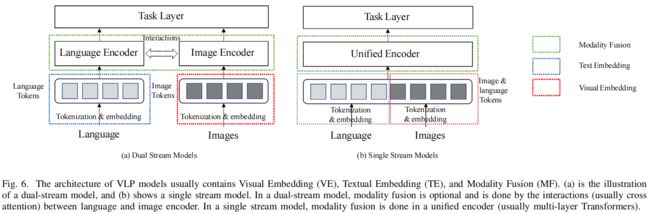
Modality Fusion
1)Dual stream modeling:采用两个独立的编码器来分别学习视觉和语言的高级表征。双流设计允许可变的网络深度和架构自适应每个模态。
2) Single stream modeling:单流建模的目的是学习一个联合表示。图像和文本标记被连接并输入到Transformer中,单流建模执行隐式的模态内融合和多模态融合,不受双流建模中融合阶段的架构设计的影响。
Training
通常使用自监督学习损失在大规模数据集上进行预训练,常用的三类预训练方法为:
Image Text Matching (ITM)
Masked Language Modeling(MLM)
Masked Visual Modeling (MVM):Masked Region Prediction (MRP)、Masked Region Classifification (MRC)、 Masked Region Classifification with KL-Divergence (MRC-KL)、Masked Visual Modeling with Visual Dictionary(MVMVD)
为了鼓励跨模态融合,一些工作,如UNITER-VL,在每次训练中只mask一种模态的token,以鼓励masked token关注另一种模态缺失信息。其次,对于MVMVD,相邻的图像网格倾向于映射到相同的VD标记,因为它们是高度相关的。在执行重建时,模型可以直接复制周围的标记。因此,所有映射到同一VD标记的视觉嵌入向量在SOHO中被mask在一起。尽管有上述提到的MVM方法,但有效的视觉建模仍然是一个具有挑战性的问题。在VLP模型中,如SOHO的一些消融研究的结果表明,添加MVM任务只会对性能产生很小的额外改进,VLP模型在下游任务中表现出倾向于关注文本信息,而不是视觉信息。

Landscape of General Pre-training Studies

1)Single Stream Models
代表:VideoBERT、 VisualBERT、 VL-BERT、UNITER
共性特点:它们都利用一个目标检测backbone来计算图像嵌入,均采用了Masked language建模任务,都采用了单流的BERT体系结构,区别在于在预训练的方法和数据集上彼此不同。
2)Dual Stream Models
代表:ViLBERT、LXMBERT
3)其他多模态融合方式
代表:SemVLP
4)Grid & Patch features
基于Faster-RCNN的区域特征缺点:类别受限、特征质量不高、缺乏背景上下文。
基于区域或网格的图像嵌入计算量大,提取的高级特征防止了交叉模态信息的早期融合。设计更好的模式融合可能是改善VLP模型表示的关键,而不是设计新的视觉嵌入。
5)Improve Aligned Representation
- 第三阶段: SCALE UP MODELS AND DATA
代表:CLIP、 DALL-E、ALIGN、SimVLM、 Florence、GODIVA、
- 未来趋势
1.Toward Modality Cooperation
模式合作是为了帮助不同的模式相互帮助,学习更好的表现
1) Improve Language Tasks with Vision Data
2) Improve Cross-Modal Tasks with Single-Modality Data
2.Toward General Unifified-Modality
3.VL+Knowledge