ViViT论文阅读
ViVit论文阅读
- 一、针对问题
- 二、相关内容介绍
-
- 1. 序列token的两种构建方式
-
- (1)Uniform frame sampling
- (2)Tubelet embedding
- 2. Vision Transformer
- 三、模型介绍
-
- 1. Model 1:Spatio-temporal attention
- 2. Model 2:Factorised encoder
- 3. Model 3:Factorised self-attention
- 4. Model 4:Factorised dot-product attention
- 四、利用预训练模型初始化
-
- 1. 位置编码
- 2. 映射参数—E
- 3. Model 3 的Transformer参数
- 五、消融实验
-
- 0. 基本设置
- 1. 输入编码
- 2. 模型变体
- 3. 模型正则化
- 4. Backbone
- 5. token数量
- 6. 输入帧数
- ViViT与其他模型的比较
- 六、总结

论文:ViViT: A Video Vision Transformer
论文地址:ViViT: A Video Vision Transformer
论文代码:https://github.com/google-research/scenic
一、针对问题
Transformer在NLP领域大获成功,ViT(Vision Transformer)将Transformer架构应用到视觉领域,它将图片按给定大小分为不重叠的patches,再将每个patch线性映射为一个token,随位置编码和cls token(可选)一起输入到Transformer的编码器中。作者尝试在视频中使用ViT模型,探究Video Vision Transformer的优化方式。
视频作为输入会产生大量的时空token,处理时必须考虑这些长范围token序列的上下文关系,同时要兼顾模型效率问题,作者在空间和时间维度上分别对Transformer编码器各组件进行分解,在ViT模型的基础上提出了三种用于视频分类的纯Transformer模型(ViViT)。同时,作者展示了如何在训练时有效地正则化模型,并利用预训练的图像模型在相对较小的数据集上进行训练。
二、相关内容介绍
1. 序列token的两种构建方式
在处理视频输入时,需要先将视频 V V V映射为序列token z ~ \tilde z z~,在 z ~ \tilde z z~上加入位置编码后进行reshape可获得transformer的输入token z z z。
作者提供了两种简单的方式,将视频 V V V映射为 z ~ \tilde z z~。
注:
视频 V V V维度为 T × H × W × C T×H×W×C T×H×W×C,序列token z ~ \tilde z z~维度为 n t × n h × n w × C n_t×n_h×n_w×C nt×nh×nw×C,输入token z z z维度为 N × d N×d N×d。
(1)Uniform frame sampling
均匀采样:从输入视频片段中均匀采样帧,使用与ViT相同的方法独立嵌入每个2D帧,并将所有这些token concat到一起,操作方式如下图

具体做法是,从每一个视频中采样 n t n_t nt帧,若从每一帧中提取的非重叠patch数量为 n h × n w n_h×n_w nh×nw,则一个视频有 n t × n h × n w n_t×n_h×n_w nt×nh×nw个token会被传递到Transformer的的Encoder中。
(2)Tubelet embedding
(1)中的均匀采样方式是2D的,Tubelet embedding可看做在3D层面上提取特征,定义非重叠的tube同时在空间和时间维度上进行线性映射,操作如下图
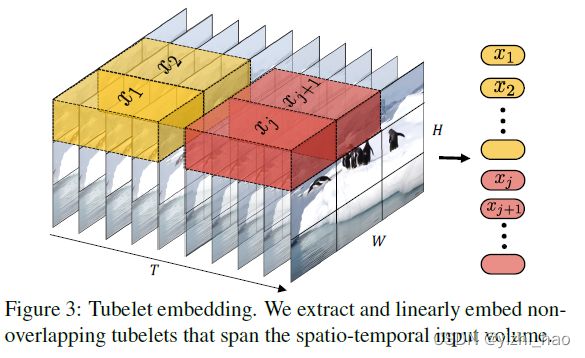
这种方式是ViT中映射方式在3D维度上的扩展,若tube维度为 t × h × w t×h×w t×h×w,同样每个视频有 n t × n h × n w n_t×n_h×n_w nt×nh×nw个token,其中
n t = T t , n h = H h , n w = W w n_t=\frac{T}{t},n_h=\frac{H}{h},n_w=\frac{W}{w} nt=tT,nh=hH,nw=wW
如上图,取t=5,共有T=10帧图像,可得到 2 × n h × n w 2×n_h×n_w 2×nh×nw个序列token。
与均匀采样相比,tubelet embedding融合了时间维度的帧信息,即这种构建方式获取的序列token同时融合了空间和时间信息。
2. Vision Transformer
文章提出的模型基于ViT,因此在介绍ViViT前回顾了ViT模型。
关于ViT模型可参考之前的一篇博文:
Vision Transformer(ViT)
三、模型介绍
作者首先将视频token直接在ViT上展开,然后提出了三种变体模型以提升效率。
1. Model 1:Spatio-temporal attention
模型1简单地套用ViT,效率太低。
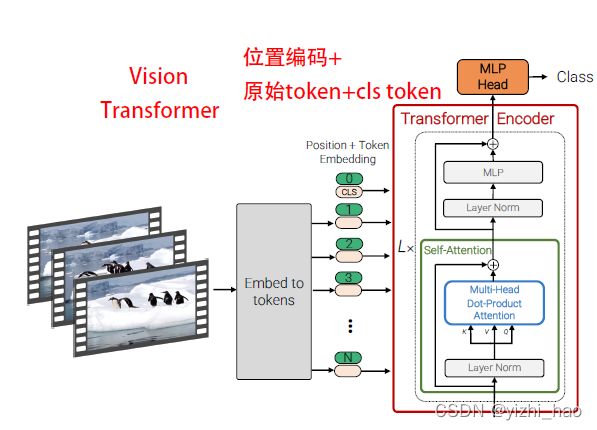
它将从视频中提取的token拼接后送入Transformer的Encoder中,Transformer层的Attention机制可以对所有token之间的关系建模,在Model 1中,模型从第一层Transformer开始就要对全部输入token进行成对建模,这使得多头注意力复杂度与token数量成平方级关系,复杂度为 O ( ( n t ∗ n h ∗ n w ) 2 ) O((n_t*n_h*n_w)^2) O((nt∗nh∗nw)2),这种效率是无法接受的。
2. Model 2:Factorised encoder
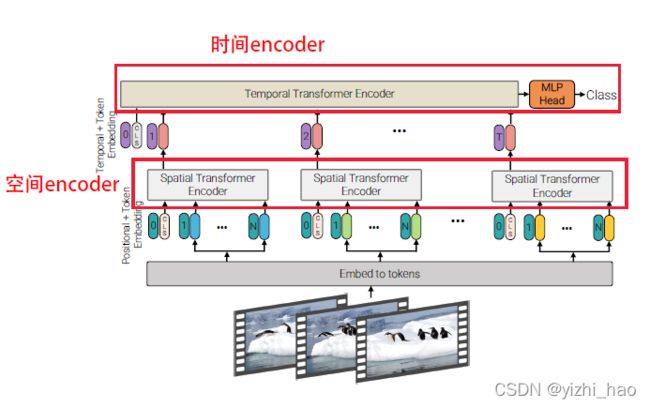
如上图,Model 2将Encoder分为空间Encoder和时间Encoder,Spatial Encoder有 L s L_s Ls层,对从相同时间序列提取的token的之间的关系建模,最终获得每一帧的表示 h i h_i hi(维度为 d d d),若输入有cls token的前缀,则做分类任务,否则对空间Encoder输出的所有token进行全局平均池化。
空间Encoder得到的帧级别表示信息 h i h_i hi,被连接成 n t × d n_t×d nt×d维度的 H H H,前向传输进入Temporal Encoder。时间Encoder有 L t L_t Lt层,对来自不同时间序列的token关系建模,对应空间和时间信息的后期融合,时间Encoder输出的token最终用于分类任务。这里论文提到了“late fusion”一词。
This model consists of two transformer encoders in series: the first models interactions between tokens extracted from the same temporal index to produce a latent representation per time-index. The second transformer models interactions between time steps. It thus corresponds to a “late fusion” of spatial- and temporal information.
可参考如下解释:
【深度学习】Early fusion vs Late fusion
这种方式与CNN类似,首先提取每一帧的特征,在分类之前将它们聚合为最终的表示。
综上,可总结Model 2的关键点如下:
- 将Encoder拆分成为Spatial Encoder和Temporal Encoder;
- Spatial Encoder提取每个时间序列的特征表示,输入为某一帧的tokens,输出为代表这个时间序列的一个token;
- Temporal Encoder聚合来自所有时间序列的表示,生成最终用于分类的表示,输入为来自Spatial Encoder的不同时间序列的tokens,输出结果送入MLP做分类任务;
- Model 2虽然有两个Transformer Encoder,但它的计算量小于Model 1,Model 2复杂度为 O ( ( n h ∗ n w ) 2 + n t 2 ) O((n_h*n_w)^2+n_t^2) O((nh∗nw)2+nt2)。
3. Model 3:Factorised self-attention
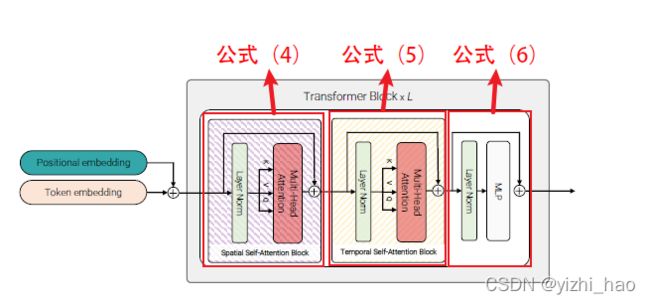
Model 3分解多头自注意力机制,它与Model 1的Transformer层数相同,在Model 1中, l l l层Transformer对所有tokens两两进行多头注意力计算,在Model 3中,将计算分解,先计算空间自注意力,然后再计算时间自注意力。
首先对来自同一时间序列的所有token计算空间自注意力,然后对相同空间序列的token计算时间注意力,对比Model1,Model 3将自注意力运算分解在更小的集合上,使得运算量与Model 2相同。
在Model 3中,利用reshape操作可以有效实现分解计算的操作。上文提到,输入token z z z维度为 N × d N×d N×d,其中 N = n t ∗ n h ∗ n w N=n_t*n_h*n_w N=nt∗nh∗nw,所以 z z z可以从 1 × n t ∗ n h ∗ n w ∗ d 1×n_t*n_h*n_w*d 1×nt∗nh∗nw∗d reshape为 n t × n h ∗ n w ∗ d n_t×n_h*n_w*d nt×nh∗nw∗d去计算空间多头自注意力得到 z t z_t zt,将 z t z_t zt reshape为 n h ∗ n w × n t ∗ d n_h*n_w×n_t*d nh∗nw×nt∗d去计算时间多头自注意力,这种分解计算可表示为公式(4)、(5)、(6),并分别对应上图标注位置。
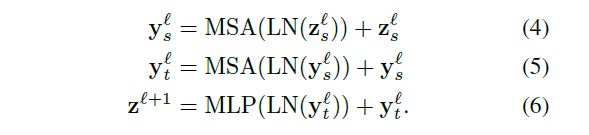
因为Model 3需要用到多次reshape操作,所以不使用cls token。
综上,可总结Model 3的关键点如下:
- 分开计算self-attention,分别对时空token计算空间MSA和时间MSA;
- Spatial Self-Attention Block仅对同一帧的不同token进行MSA计算;
- Temporal Self-Attention Block仅对不同帧相同位置的token进行MSA计算;
- 作者发现,Spatial Self-Attention Block和Temporal Self-Attention Block的先后顺序是无差别的。
4. Model 4:Factorised dot-product attention
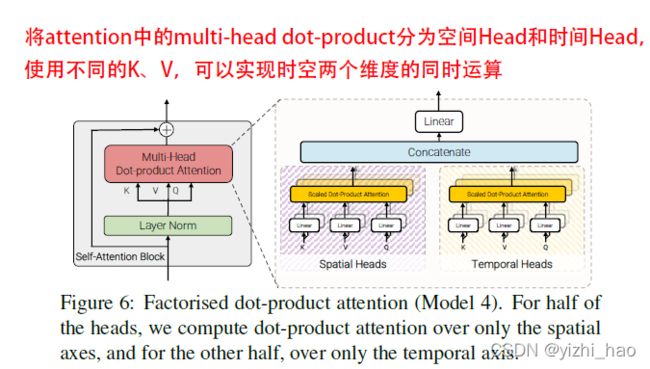
Model 4在参数量与Model 1相同的情况下,其计算量与Model 2、3一样,设计思想与Model 3相似,不同之处在于Model 4将点积拆分到不同维度,使用不同的head分别在空间和时间维度上计算attention权重,直观地看,Model 3计算空间注意力和时间注意力是串行的,而Model 4可并行计算。
如上图所示,具体做法是,将多头注意力一分为二,一半为Spatial Heads,另一半为Temporal Heads,给定前者有 K s 、 V s K_s、V_s Ks、Vs,维度为 n h ∗ n w × d n_h*n_w×d nh∗nw×d,用于计算空间维度上的注意力
Y s = A t t e n t i o n ( Q , K s , V s ) , d i m = N × d Y_s=Attention(Q,K_s,V_s),dim = N×d Ys=Attention(Q,Ks,Vs),dim=N×d
给定后者有 K t 、 V t K_t、V_t Kt、Vt维度为 n t × d n_t×d nt×d,用于计算时间维度上的注意力
Y t = A t t e n t i o n ( Q , K t , V t ) , d i m = N × d Y_t=Attention(Q,K_t,V_t),dim = N×d Yt=Attention(Q,Kt,Vt),dim=N×d
然后将两者通过线性映射合并,
Y = C o n c a t ( Y s , Y t ) W o Y=Concat(Y_s,Y_t)W_o Y=Concat(Ys,Yt)Wo
综上,可总结Model 4的关键点如下:
- 可视为Model 3的并行版;
- 与Model 3相似,Spatial Head计算的为同一帧内不同token,Temporal Head则为不同帧相同位置的token;
四、利用预训练模型初始化
从零开始到高精度地训练大型模型是极具挑战性的,往往会通过已有模型来初始化大型视频分类模型
1. 位置编码
在原始ViT中,输入到Transformer中的 z z z,应该包含cls token、从patches中投影的tokens和位置编码p,即
z = [ z c l s , E x 1 , E x 2 , . . . , E x N ] + p z=[z_{cls},Ex_1,Ex_2,...,Ex_N]+p z=[zcls,Ex1,Ex2,...,ExN]+p
但是,在ViViT中,token的数量是ViT的 n t n_t nt倍,我们采用这样一个策略来初始化位置编码,原文是这样表述的
As a result, we initialise the positional embeddings by “repeating” them temporally from nw* nh×d to nt * nh*nw×d. Therefore, at initialisation, all tokens with the same spatial index have the same embedding which is then fine-tuned.
即重复时间维度的位置编码,初始化时,相同的空间序列拥有相同的位置编码。
2. 映射参数—E
ViT中,将patches投影为token,使用的是2D卷积,当使用Tubelet embedding构建token时,需要的是3D的卷积核,如何将预训练模型中的二维tensor拓展为三维是一个问题,作者提供了两种方式。
考虑一种常见的做法,从2D卷积核初始化3D卷积核的常用方式是沿时间维度复制卷积核并对其取平均,从而“膨胀”2D卷积,如下
E = 1 t [ E i m a g e , . . . , E i m a g e , . . . , E i m a g e ] E=\frac{1}{t}[E_{image},...,E_{image},...,E_{image}] E=t1[Eimage,...,Eimage,...,Eimage]
作者还提供了另一种策略,将其称作“中心帧初始化”(center frame initialisation),这种方式下,除中心帧( t 2 \frac{t}{2} 2t位置)其余时间位置全为0,即
E = [ 0 , . . . , E i m a g e , . . . , 0 ] E=[0,...,E_{image},...,0] E=[0,...,Eimage,...,0]
3. Model 3 的Transformer参数
Model 3里有两个多头自注意力(MSA)模块,这与ViT预训练有不同,作者采取的策略是从预训练模块中初始化空间MSA,用0初始化时间MSA。
五、消融实验
0. 基本设置
实验的backbone为ViT和BERT,对ViT-B、ViT-L和ViT-H分别进行实验,使用带动量的SGD优化器,使用余弦学习率衰减的方式… …关于更多详细的训练与数据集设置,建议阅读原论文。
注:
论文对模型标注方式的解释,例如ViViT-B/16×2表示tubelet为 h × w × t = 16 × 16 × 2 h×w×t=16×16×2 h×w×t=16×16×2的以ViT-B为backbone的ViViT模型。
完成模型基本设置后,作者对输入编码方式、模型变体、正则化方式、backbone、token数量、网络输入帧数分别进行消融实验,具体情况下面展开。
1. 输入编码
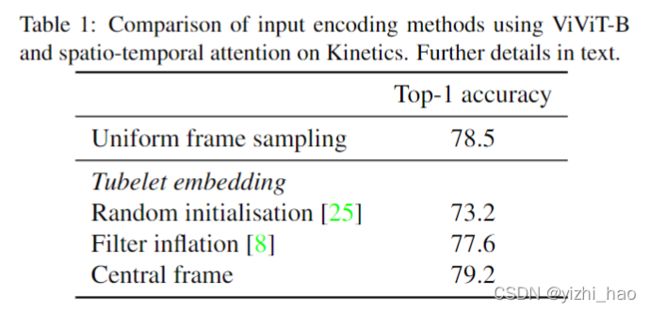
考虑不同的输入编码方式(对应内容2.1)对模型的影响,在Kinetics400数据集上使用Model 1形式的ViViT-B模型,网络输入为32帧,通过均匀采样8帧和 t = 4 t=4 t=4的tubelet来确保两种方式下token数目一致,并且针对tubelet embedding,分别使用不同的映射参数E初始化方法(对应内容4.2)探究其对结果的影响,实验结果如表1
2. 模型变体
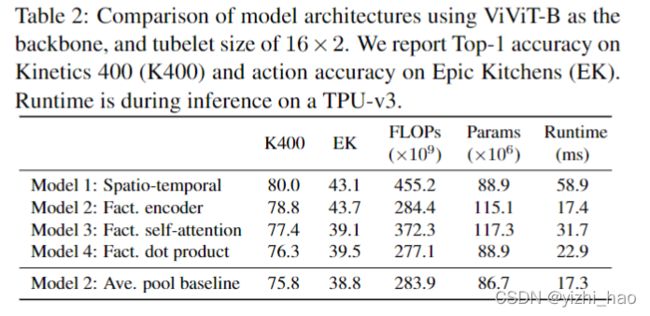
作者使用不同的ViViT模型在Kinetics400和Epic Kitchens数据集上进行实验,比较它们的准确率和效率,结果如表2
在Model 2 Factorised Encoder中有一个额外的参数 L t L_t Lt,即时间Transformer的层数,这也是一个超参数,但实际这个参数取值对模型基本无影响,作者为了说明这一点对 L t L_t Lt取值做了实验,结果如表3

所以在其他实验中,将 L t L_t Lt的值固定为4,不再变动。
3. 模型正则化
纯粹的Transformer模型需要大量的数据训练,在小型数据集如Epic Kitchens和SSv2会出现过拟合, 作者在模型2 Factorised encoder上使用不同种正则化策略,得到结果如表4

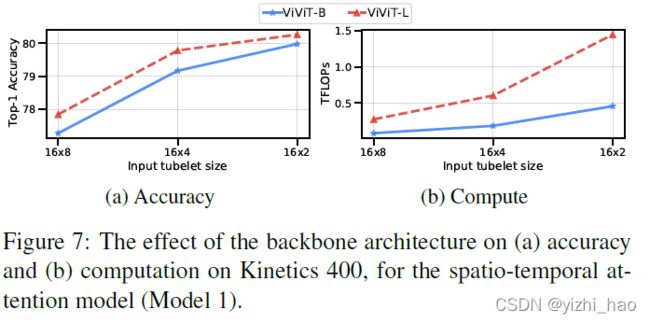
4. Backbone
Model 1上的ViViT-B和ViViT-L的准确率和效率如下图所示
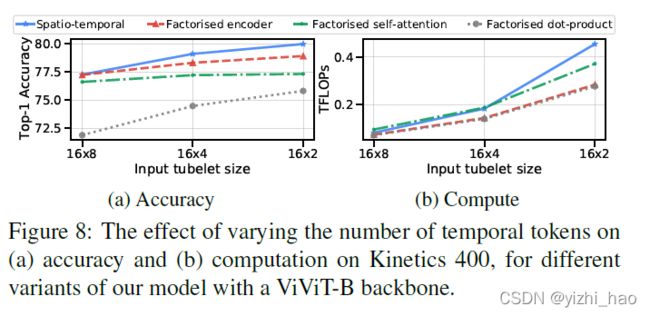
5. token数量
在Kinetics 400数据集上,不同数量的时间token对精度和计算量的影响如下图
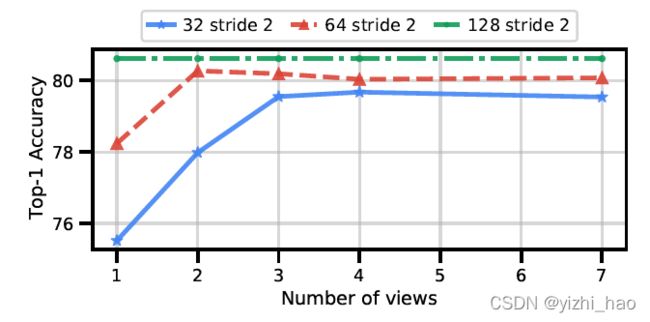
6. 输入帧数
之前的实验中,输入帧数一直是32,现增加输入帧数,并按比例增加token数量,观察对网络精度的影响,结果如下图
消融实验的细节部分,建议阅读原文,介绍的很详细。
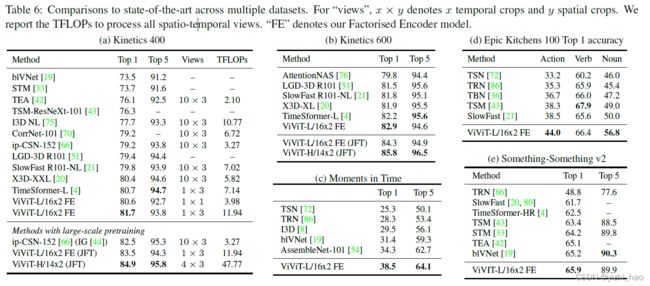
ViViT与其他模型的比较
作者使用ViViT模型与其他SOTA模型在不同数据集上进行比较,结果如表6
六、总结
论文的主要贡献有以下两点:
- 提出了四种用于视频分类的纯Transformer模型,在五个流行的数据集上达到了SOTA的结果;
- 展示了如何有效地在小规模数据集上训练大容量模型