数据结构:算法的时间复杂度和空间复杂度
本篇前言:
- 1.算法效率
- 2.时间复杂度
- 3.空间复杂度
- 4. 常见时间复杂度以及复杂度oj练习
1.算法效率
1.1 如何衡量一个算法的好坏
如何衡量一个算法的好坏呢?比如对于以下斐波那契数列:
long long Fib(int N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
斐波那契数列的递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?其实在这个算法中,斐波那契数列的递归法是属于较坏的一种,因为每自调用一次Fib函数,就会展开两层,两两算下去其实运行了2的N次方次,当N无限大时,这是一个非常大且可怕的运算次数,所以可得出它的运算效率是非常低的
1.2 算法的复杂度
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以如今已经不需要再特别关注一个算法的空间复杂度。
1.3 复杂度在校招中的考察
2.时间复杂度
2.1 时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个
分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
请计算一下Func1中++count语句总共执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
先分析下第一个for循环中 count的运行次数是N*N次,即为N的平方次
第二个for循环中运行次数为2*N次,即为2*N次
第三个while循环中为10次,即为10次
所以可以得出 Func1 执行的基本操作次数 :
![]()
假设一下N为各种数值时,整个程序的执行次数:
- N = 10 F(N) = 130
- N = 100 F(N) = 10210
- N = 1000 F(N) = 1002010
可以看出随着N的变大,后两项对整个结果的影响变小,从极限的说法 当N无限大的时候,后两项对结果的影响可以忽略不计
实际中计算时间复杂度时,其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这里使用大O的渐进表示法。
就好比如一个人有过亿的财产,我们在形容他有财产的时候有一亿的财产,而不是说精确到有一亿零多少的财产值 因为后面的小数财产值对它前面的财产值影响并不大
所以大O是进行一个估算大概,没必要算精确的次数
所以我们谈论一个算法的时间复杂度都是用 O(N^2)
大O的N方是如何求出来的?
先求出这个算法准确的次数,然后再看哪个是对这个结果最大的项,对结果影响不大项的就忽略掉
2.2 大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
比如
计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}
在这明确的运行100次,100是个常数 则用1代替 所以它的时间复杂度是O(1)2、在修改后的运行次数函数中,只保留最高阶项。就是忽略对结果影响不大的项 比如:
计算Func2的时间复杂度?
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
这里就是2*N+10 影响最大的就是2*N 忽略10
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
以2.为例, 2*N中的2为常数,则去除这个常数 得到的结果就是O(N)
因为当N无限大的时候 2N和N是没区别的,所以2对N来说影响不大
通俗点说,时间复杂度不是用来算这个算法跑了多少次,而是算这个算法是属于什么量级的!
举个比方说,当我和小明两个人,小明有3元 我有5元,那双方的量级或者说财富级是属于元这个水准,两个都差不了太多,无非就是说我喝的是元气森林,而小明喝的是可乐,但喝的都是气泡水,不可能说我能喝得起元气森林,而小明却喝得起800一瓶的红酒,不可能存在量级跳跃
时间复杂度就是属于一个量级评估
使用大O的渐进表示法以后,Func1的时间复杂度为:
- N = 10 F(N) = 100
- N = 100 F(N) = 10000
- N = 1000 F(N) = 1000000
通过上面会发现大O的渐进表去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
2.3常见时间复杂度计算举例
实例1:
计算Func2的时间复杂度?
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
实例1基本操作执行了2N+10次,通过推导大O阶方法知道,时间复杂度为 O(N)
实例2:
计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}
时间复杂度是O(N+M) 两个都保留下来
因为M和N都是不确定的,而我们自身也不能确定M和N哪个项对量级影响比较大
如果明确M远大于N 那么就是O(M) 或者M和N差不多大 也可以是O(M) 也可以是O(N)
但是没有这些明确条件之外 就是O(M+N)
实例3:
计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}
实例3基本操作执行了10次,通过推导大O阶方法,时间复杂度为 O(1)实例4:
计算strchr的时间复杂度?
const char * strchr ( const char * str, int character );
时间复杂度是O(N) 这个就是上面所讲的有些算法的时间复杂度存在最好最坏平均三种情况,
而在实际中一般情况下关注的是算法的最坏运行情况 , 简称时间复杂度的估算是一种悲观的估算
这个代码就是在一串字符串中查找字符
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界) 实例5:
计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
最好的情况是O(N) 最坏的情况是O(N^2)
最好情况: 数据本身有序,进入不到if =1的环节,到下面总共就遍历一个N遍
平均情况: 数据存在各别的无序,需要进行N-各别次遍历 也就是F (N-各别次)
最坏情况:所有数据都是混乱,需要进行 (N-1)*N/2次遍历 就是2分之N^2次方 除去常数2 和平均情况一样 都是O(N^2)
实例6:
计算BinarySearch的时间复杂度?
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n;
while (begin < end)
{
int mid = begin + ((end-begin)>>1);
if (a[mid] < x)
begin = mid+1;
else if (a[mid] > x)
end = mid;
else
return mid;
}
return -1;
}
最好的情况就是O(1)
最坏的情况就是O(log2N)
假设找了X次 中间值只剩下1个 那么就是1*X次2 = N 也就是2^X次方=N 这时X = log以2为底 N的对数
或者换个反向的假设说 x的值一直大于begin的值 那么就是 N/2/2/2/2….=1 这时候就是N除的次数 就是log2N要准确分析算法时间复杂度,一定要去看思想,不能只去看程序是几层循环!
譬如O(N) 其中N是1000 O(N)要查找1000次 那么O(log2N)则只需要10次 2的10次方就是1024
O(N)是100W O(N)要查找100W次 O(log2N)则只需要20次
O(N)是10亿 O(N)要查找10亿次 O(log2N)则只需要30次
根本就不是一个量级的 相比较之下 O(log2N)跟O(1)则是一个量级的, 但是log2N随着N的变化还是会不断增大,但是非常缓慢!
时间复杂度里面会把O(log2N)简写成O(logN) 有些资料里面也会简写成O(lgN) 不推荐这样写
其他log以3为底 以5为底该怎么写就怎么写 只有以2为底才简写 90%都是以2为底
实例7:
计算阶乘递归Fac的时间复杂度?
long long Fac(size_t N)
{
if(0 == N)
return 1;
return Fac(N-1)*N;
}
时间复杂度是O(N)
这个是个递归运行,是一次次把N减一递增下去,直到N=0 开始逐层返回,这时候运行的次数就是N次 所以是O(N)
但是每个递归并不是以运算次数为准 比如在中间再加上一个 for(size_t I = 0; i实例8:
计算斐波那契递归Fib的时间复杂度?
long long Fib(size_t N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
时间复杂度是O(2^N)
比如N是10 1层递归变2层 2层递归变4层 4层递归变8层,形成了等比数列
等到了N<3的时候实际就是2(N-1)次方-1, 后面的-1其实对总体量级没有大的影响,几乎可以忽略不计
所以这道题的时间复杂度就是O(2^N)
3.空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
实例1:
计算BubbleSort的空间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
空间复杂度为O(1)
end exchange i三个变量 是常数量 常数都为1实例2:
计算Fibonacci的空间复杂度?
返回斐波那契数列的前n项
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}
空间复杂度为O(N)
malloc n+1是随着N的增大而增大,对量级影响最大的是N 所以是O(N)实例3:
计算阶乘递归Fac的空间复杂度?
long long Fac(size_t N)
{
if(N == 0)
return 1;
return Fac(N-1)*N;
}
空间复杂度为O(N)
递归每次展开就会单独再次开辟栈帧如果是时间复杂度的实例8,那么它的空间复杂度就是O(N)
这里要明白一个原理,时间是累积的 不可复用的,而空间是回收以后可以重复利用的
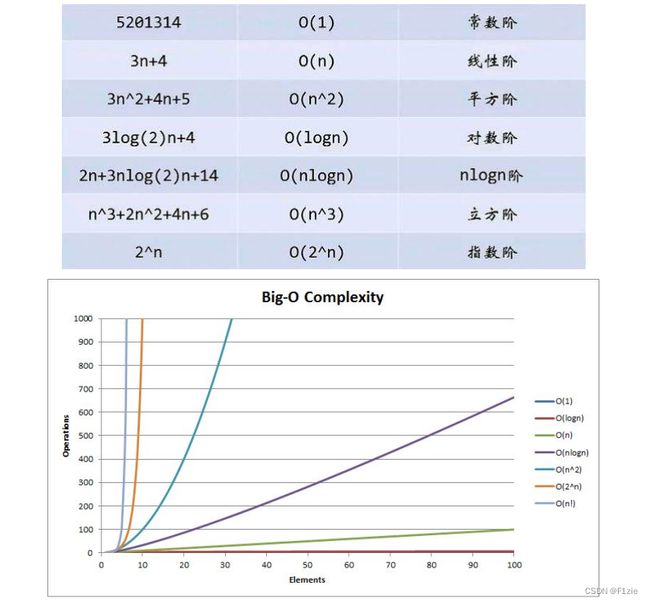
4. 常见复杂度对比
一般算法常见的复杂度如下: