PaddleDetection-YOLOv3模型结构解析(二)
2021SC@SDUSC
本文分析PaddleDetection-YOLOv3模型结构:
Head部分算法结构图:
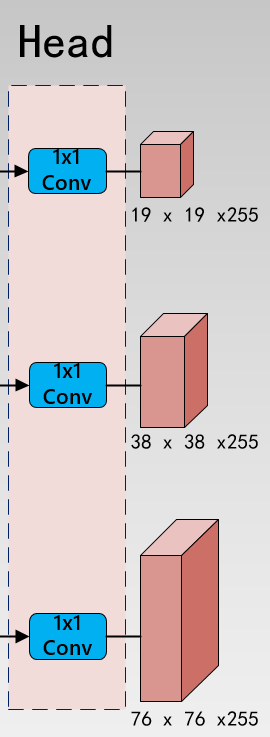
modeling/head/yolo_head.py源码解析:
在yaml的配置:/configs/_base_/models/yolov3_darknet53.yml
'''
YOLOv3Head:#初始化
anchors: [[10, 13], [16, 30], [33, 23],
[30, 61], [62, 45], [59, 119],
[116, 90], [156, 198], [373, 326]] #anchor大小
anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]] #anchor索引
loss: YOLOv3Loss #loss
YOLOv3Loss: #初始化
ignore_thresh: 0.7 #正例阈值
downsample: [32, 16, 8] #下采样倍数
label_smooth: true #是否采用label_smooth
'''相关库引用:
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import ParamAttr
from paddle.regularizer import L2Decay
from ppdet.core.workspace import register
from ..backbone.darknet import ConvBNLayer
YOLOv3Head模块,其中loss是下面YOLOv3Loss:
@register
class YOLOv3Head(nn.Layer):
__shared__ = ['num_classes']
__inject__ = ['loss']
def __init__(self,
anchors=[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]],
anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],
num_classes=80,
loss='YOLOv3Loss'):
super(YOLOv3Head, self).__init__()
self.num_classes = num_classes
self.loss = loss
self.parse_anchor(anchors, anchor_masks)
self.num_outputs = len(self.anchors)
self.yolo_outputs = []
for i in range(len(self.anchors)):
num_filters = self.num_outputs * (self.num_classes + 5)
name = 'yolo_output.{}'.format(i)
yolo_output = self.add_sublayer(
name,
nn.Conv2D(
in_channels=1024 // (2**i),
out_channels=num_filters,
kernel_size=1,
stride=1,
padding=0,
weight_attr=ParamAttr(name=name + '.conv.weights'),
bias_attr=ParamAttr(
name=name + '.conv.bias', regularizer=L2Decay(0.))))
self.yolo_outputs.append(yolo_output)
#anchor解析
def parse_anchor(self, anchors, anchor_masks):
self.anchors = [[anchors[i] for i in mask] for mask in anchor_masks]
self.mask_anchors = []
anchor_num = len(anchors)
for masks in anchor_masks:
self.mask_anchors.append([])
for mask in masks:
assert mask < anchor_num, "anchor mask index overflow"
self.mask_anchors[-1].extend(anchors[mask])
#前向传播
def forward(self, feats):
assert len(feats) == len(self.anchors)
yolo_outputs = []
for i, feat in enumerate(feats):
yolo_output = self.yolo_outputs[i](feat)
yolo_outputs.append(yolo_output)
return yolo_outputs
#计算loss
def get_loss(self, inputs, targets):
return self.loss(inputs, targets, self.anchors)modeling/loss/yolo_loss.py解析:
在yaml的配置文件:
'''
YOLOv3Loss:
ignore_thresh: 0.7
downsample: [32, 16, 8]
label_smooth: false
'''相关库引用:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from ppdet.core.workspace import register
from ..utils import decode_yolo, xywh2xyxy, iou_similarity
__all__ = ['YOLOv3Loss']yolo loss模块:
@register
class YOLOv3Loss(nn.Layer):
__inject__ = ['iou_loss', 'iou_aware_loss']
__shared__ = ['num_classes']
def __init__(self,
num_classes=80,
ignore_thresh=0.7,
label_smooth=False,
downsample=[32, 16, 8],
scale_x_y=1.,
iou_loss=None,
iou_aware_loss=None):
super(YOLOv3Loss, self).__init__()
self.num_classes = num_classes
self.ignore_thresh = ignore_thresh
self.label_smooth = label_smooth
self.downsample = downsample
self.scale_x_y = scale_x_y
self.iou_loss = iou_loss
self.iou_aware_loss = iou_aware_loss
# 目标损失
def obj_loss(self, pbox, gbox, pobj, tobj, anchor, downsample):
b, h, w, na = pbox.shape[:4]
pbox = decode_yolo(pbox, anchor, downsample)
pbox = pbox.reshape((b, -1, 4))
pbox = xywh2xyxy(pbox)
gbox = xywh2xyxy(gbox)
iou = iou_similarity(pbox, gbox)
iou.stop_gradient = True
iou_max = iou.max(2) # [N, M1]
iou_mask = paddle.cast(iou_max <= self.ignore_thresh, dtype=pbox.dtype)
iou_mask.stop_gradient = True
pobj = pobj.reshape((b, -1))
tobj = tobj.reshape((b, -1))
obj_mask = paddle.cast(tobj > 0, dtype=pbox.dtype)
obj_mask.stop_gradient = True
loss_obj = F.binary_cross_entropy_with_logits(
pobj, obj_mask, reduction='none')
loss_obj_pos = (loss_obj * tobj)
loss_obj_neg = (loss_obj * (1 - obj_mask) * iou_mask)
return loss_obj_pos + loss_obj_neg
# 分类损失
def cls_loss(self, pcls, tcls):
if self.label_smooth:
delta = min(1. / self.num_classes, 1. / 40)
pos, neg = 1 - delta, delta
# 1 for positive, 0 for negative
tcls = pos * paddle.cast(
tcls > 0., dtype=tcls.dtype) + neg * paddle.cast(
tcls <= 0., dtype=tcls.dtype)
loss_cls = F.binary_cross_entropy_with_logits(
pcls, tcls, reduction='none')
return loss_cls
# 计算总 yolo loss
def yolov3_loss(self, x, t, gt_box, anchor, downsample, scale=1.,
eps=1e-10):
na = len(anchor)
b, c, h, w = x.shape
no = c // na
x = x.reshape((b, na, no, h, w)).transpose((0, 3, 4, 1, 2))
xy, wh, obj = x[:, :, :, :, 0:2], x[:, :, :, :, 2:4], x[:, :, :, :, 4:5]
if self.iou_aware_loss:
ioup, pcls = x[:, :, :, :, 5:6], x[:, :, :, :, 6:]
else:
pcls = x[:, :, :, :, 5:]
t = t.transpose((0, 3, 4, 1, 2))
txy, twh, tscale = t[:, :, :, :, 0:2], t[:, :, :, :, 2:4], t[:, :, :, :,
4:5]
tobj, tcls = t[:, :, :, :, 5:6], t[:, :, :, :, 6:]
tscale_obj = tscale * tobj
loss = dict()
if abs(scale - 1.) < eps:
loss_xy = tscale_obj * F.binary_cross_entropy_with_logits(
xy, txy, reduction='none')
else:
xy = scale * F.sigmoid(xy) - 0.5 * (scale - 1.)
loss_xy = tscale_obj * paddle.abs(xy - txy)
loss_xy = loss_xy.sum([1, 2, 3, 4]).mean()
loss_wh = tscale_obj * paddle.abs(wh - twh)
loss_wh = loss_wh.sum([1, 2, 3, 4]).mean()
loss['loss_loc'] = loss_xy + loss_wh
x[:, :, :, :, 0:2] = scale * F.sigmoid(x[:, :, :, :, 0:2]) - 0.5 * (
scale - 1.)
box, tbox = x[:, :, :, :, 0:4], t[:, :, :, :, 0:4]
if self.iou_loss is not None:
# box and tbox will not change though they are modified in self.iou_loss function, so no need to clone
loss_iou = self.iou_loss(box, tbox, anchor, downsample, scale)
loss_iou = loss_iou * tscale_obj.reshape((b, -1))
loss_iou = loss_iou.sum(-1).mean()
loss['loss_iou'] = loss_iou
if self.iou_aware_loss is not None:
# box and tbox will not change though they are modified in self.iou_aware_loss function, so no need to clone
loss_iou_aware = self.iou_aware_loss(ioup, box, tbox, anchor,
downsample, scale)
loss_iou_aware = loss_iou_aware * tobj.reshape((b, -1))
loss_iou_aware = loss_iou_aware.sum(-1).mean()
loss['loss_iou_aware'] = loss_iou_aware
loss_obj = self.obj_loss(box, gt_box, obj, tobj, anchor, downsample)
loss_obj = loss_obj.sum(-1).mean()
loss['loss_obj'] = loss_obj
loss_cls = self.cls_loss(pcls, tcls) * tobj
loss_cls = loss_cls.sum([1, 2, 3, 4]).mean()
loss['loss_cls'] = loss_cls
return loss
#前向传播
def forward(self, inputs, targets, anchors):
np = len(inputs)
gt_targets = [targets['target{}'.format(i)] for i in range(np)]
gt_box = targets['gt_bbox']
yolo_losses = dict()
for x, t, anchor, downsample in zip(inputs, gt_targets, anchors,
self.downsample):
yolo_loss = self.yolov3_loss(x, t, gt_box, anchor, downsample)
for k, v in yolo_loss.items():
if k in yolo_losses:
yolo_losses[k] += v
else:
yolo_losses[k] = v
loss = 0
for k, v in yolo_losses.items():
loss += v
yolo_losses['loss'] = loss
return yolo_lossesPost_process部分:
post_process.py源码解析:
配置文件解析:
'''
BBoxPostProcess: #初始化
decode:
name: YOLOBox #类名
conf_thresh: 0.005 #阈值
downsample_ratio: 32 #下采样比例
clip_bbox: true #是否clip_bbox
nms: #nms实例化
name: MultiClassNMS # nms 类型参数,可以设置为[MultiClassNMS, MultiClassSoftNMS, MatrixNMS], 默认使用 MultiClassNMS
keep_top_k: 100 #bbox最大个数
score_threshold: 0.01 #置信度阈值
nms_threshold: 0.45 #nms阈值
nms_top_k: 1000 #nms最大框个数
normalized: false #是否正则化
background_label: -1 #是否有背景类
'''相关库引用:
'''
BBoxPostProcess: #初始化
decode:
name: YOLOBox #类名
conf_thresh: 0.005 #阈值
downsample_ratio: 32 #下采样比例
clip_bbox: true #是否clip_bbox
nms: #nms实例化
name: MultiClassNMS # nms 类型参数,可以设置为[MultiClassNMS, MultiClassSoftNMS, MatrixNMS], 默认使用 MultiClassNMS
keep_top_k: 100 #bbox最大个数
score_threshold: 0.01 #置信度阈值
nms_threshold: 0.45 #nms阈值
nms_top_k: 1000 #nms最大框个数
normalized: false #是否正则化
background_label: -1 #是否有背景类
'''BBox后处理模块
@register
class BBoxPostProcess(object):
__inject__ = ['decode', 'nms']
def __init__(self, decode=None, nms=None):
super(BBoxPostProcess, self).__init__()
self.decode = decode
self.nms = nms
def __call__(self,
head_out,
rois,
im_shape,
scale_factor=None,
var_weight=1.):
bboxes, score = self.decode(head_out, rois, im_shape, scale_factor,
var_weight)
bbox_pred, bbox_num, _ = self.nms(bboxes, score)
return bbox_pred, bbox_nummask后处理模块:
@register
class MaskPostProcess(object):
__shared__ = ['mask_resolution']
def __init__(self, mask_resolution=28, binary_thresh=0.5):
super(MaskPostProcess, self).__init__()
self.mask_resolution = mask_resolution
self.binary_thresh = binary_thresh
def __call__(self, bboxes, mask_head_out, im_shape, scale_factor=None):
# TODO: modify related ops for deploying
bboxes_np = (i.numpy() for i in bboxes)
mask = mask_post_process(bboxes_np,
mask_head_out.numpy(),
im_shape.numpy(), scale_factor[:, 0].numpy(),
self.mask_resolution, self.binary_thresh)
mask = {'mask': mask}
return mask优化器部分:
ppdet/optimizer.py源码解析:
在yaml的配置文件:./_base_/optimizers/yolov3_270e.yml
'''
#./_base_/optimizers/yolov3_270e.yml
epoch: 270 #训练epoch数
LearningRate: #实例化学习率
# 初始学习率, 一般情况下8卡gpu,batch size为2时设置为0.02
# 可以根据具体情况,按比例调整
# 比如说4卡V100,bs=2时,设置为0.01
base_lr: 0.001 #学习率
# if epoch < 216:
# learning_rate = 0.1
# elif 216 <= epoch < 243:
# learning_rate = 0.1 * 0.1
# else:
# learning_rate = 0.1 * (0.1)**2
schedulers: #实例化优化器策略
- !PiecewiseDecay #分段式衰减
gamma: 0.1 #衰减系数
milestones: #衰减点[列表]
- 216 #在epoch为216时学习率衰减一次
- 243 #在epoch为243时学习率衰再减一次
# 在训练开始时,调低学习率为base_lr * start_factor,然后逐步增长到base_lr,这个过程叫学习率热身,按照以下公式更新学习率
# linear_step = end_lr - start_lr
# lr = start_lr + linear_step * (global_step / warmup_steps)
# 具体实现参考[API](fluid.layers.linear_lr_warmup)
- !LinearWarmup #学习率从非常小的数值线性增加到预设值之后,然后再线性减小。
start_factor: 0.#初始值
steps: 4000 #线性增长步长
OptimizerBuilder: #构建优化器
optimizer: #优化器
momentum: 0.9 #动量系数
type: Momentum #类型
regularizer: #正则初始化
factor: 0.0005 #正则系数
type: L2 #L2正则相关库引用:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import math
import logging
import paddle
import paddle.nn as nn
import paddle.optimizer as optimizer
import paddle.fluid.regularizer as regularizer
from paddle import cos
from ppdet.core.workspace import register, serializable
__all__ = ['LearningRate', 'OptimizerBuilder']
logger = logging.getLogger(__name__)分段式衰减模块(调整学习率):
@serializable
class PiecewiseDecay(object):
"""
Multi step learning rate decay
Args:
gamma (float | list): decay factor
milestones (list): steps at which to decay learning rate
"""
def __init__(self, gamma=[0.1, 0.01], milestones=[60000, 80000]):
super(PiecewiseDecay, self).__init__()
if type(gamma) is not list:
self.gamma = []
for i in range(len(milestones)):
self.gamma.append(gamma / 10**i)
else:
self.gamma = gamma
self.milestones = milestones
def __call__(self, base_lr=None, boundary=None, value=None):
if boundary is not None:
boundary.extend(self.milestones)
if value is not None:
for i in self.gamma:
value.append(base_lr * i)
return optimizer.lr.PiecewiseDecay(boundary, value)线性预热模块(调整学习率):
@serializable
class LinearWarmup(object):
"""
Warm up learning rate linearly
Args:
steps (int): warm up steps
start_factor (float): initial learning rate factor
"""
def __init__(self, steps=500, start_factor=1. / 3):
super(LinearWarmup, self).__init__()
self.steps = steps
self.start_factor = start_factor
def __call__(self, base_lr):
boundary = []
value = []
for i in range(self.steps + 1):
alpha = i / self.steps
factor = self.start_factor * (1 - alpha) + alpha
lr = base_lr * factor
value.append(lr)
if i > 0:
boundary.append(i)
return boundary, value学习率优化模块(将上面两种学习率优化方法调入):
@register
class LearningRate(object):
"""
Learning Rate configuration
Args:
base_lr (float): base learning rate
schedulers (list): learning rate schedulers
"""
__category__ = 'optim'
def __init__(self,
base_lr=0.01,
schedulers=[PiecewiseDecay(), LinearWarmup()]):
super(LearningRate, self).__init__()
self.base_lr = base_lr
self.schedulers = schedulers
def __call__(self):
# TODO: split warmup & decay
# warmup
boundary, value = self.schedulers[1](self.base_lr)
# decay
decay_lr = self.schedulers[0](self.base_lr, boundary, value)
return decay_lr
优化器模块(学习率优化模块调入):
@register
class OptimizerBuilder():
"""
Build optimizer handles
Args:
regularizer (object): an `Regularizer` instance
optimizer (object): an `Optimizer` instance
"""
__category__ = 'optim'
def __init__(self,
clip_grad_by_norm=None,
regularizer={'type': 'L2',
'factor': .0001},
optimizer={'type': 'Momentum',
'momentum': .9}):
self.clip_grad_by_norm = clip_grad_by_norm
self.regularizer = regularizer
self.optimizer = optimizer
def __call__(self, learning_rate, params=None):
if self.clip_grad_by_norm is not None:
grad_clip = nn.GradientClipByGlobalNorm(
clip_norm=self.clip_grad_by_norm)
else:
grad_clip = None
if self.regularizer:
reg_type = self.regularizer['type'] + 'Decay'
reg_factor = self.regularizer['factor']
regularization = getattr(regularizer, reg_type)(reg_factor)
else:
regularization = None
optim_args = self.optimizer.copy()
optim_type = optim_args['type']
del optim_args['type']
op = getattr(optimizer, optim_type)
return op(learning_rate=learning_rate,
parameters=params,
weight_decay=regularization,
grad_clip=grad_clip,
**optim_args)由此整个YOLOV3完整的pipeline就是这样通过yaml文件构建好了,后面根据train、test、val的具体应用情况来拔插相应的模块。