随笔记录:关于SE模块插入位置的总结
一、前言
由于之前工作中,训练数据集普遍较小 以及 开发板对模型的限制,所以对SE模块的使用较少,对它的插入位置不是很清楚,这样不利于日后对它的使用。故最近查了下使用案例,记录总结如下。
二、正文
(一)plain模型
SE作者对SE模块在plain模型插入位置的建议是:在每个卷积的激活函数后面插入。这样一看会误以为在每个卷积层后面加个SE模块,一般是在每个block后面插入,下面结合实际的案例来做说明。
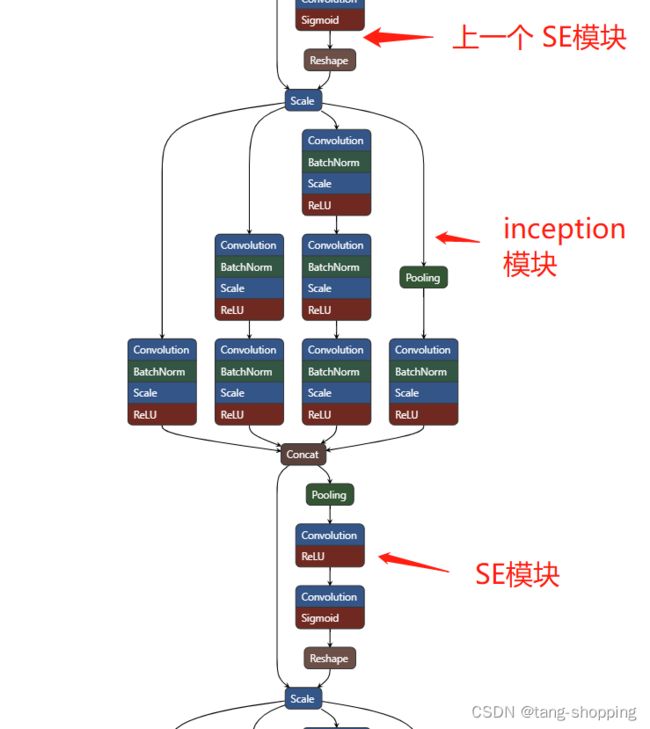
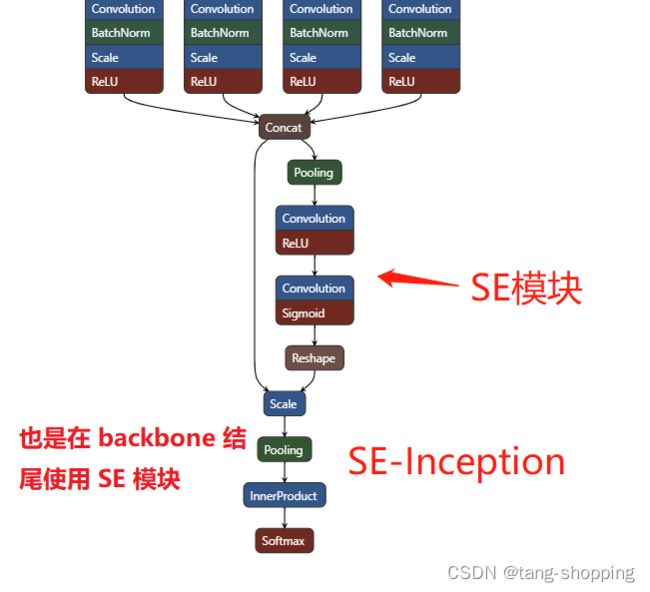
1. SE-Inception 模型
2. PP-LCNet 模型
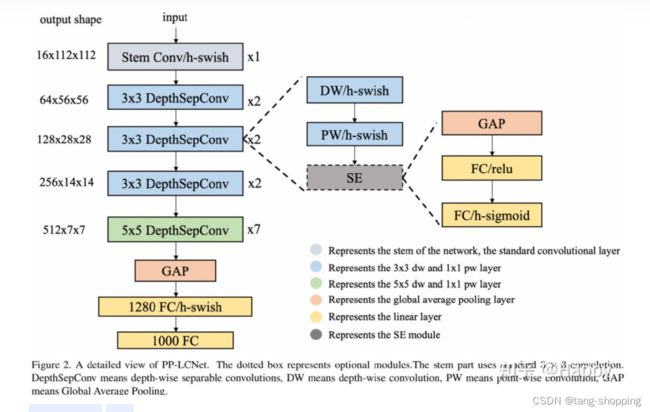
由上面两张图可见,SE模块在plain模型的插入位置,一般在上个block的结尾 下一个block之前的位置插入。
(二)skip connection 模型
skip connection 模型指ResNet、MobileNet v2/v3这种具有shortcut操作的模型。现在的模型基本是这个结构,它与plain模型block最大的不同就是多了个恒等映射的分支(一些变种可能不是恒等映射分支,意思明白就好)。
1. (类)residual unit外部,SE的插入位置
SE作者做了个实验,验证SE模块在residual unit外部时,放在哪个位置效果最好。这个实验虽然是用残差网络来做的,但是其他模型如MobileNet也可以借鉴,毕竟二者的思路是一致的。

验证结果如下,下图中的SE就是上图的 Standard SE block,其他名词含义与上图一致。
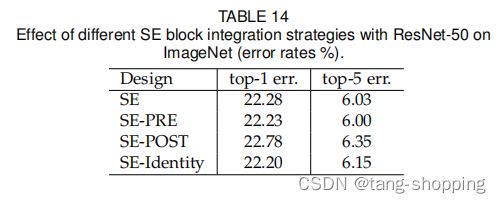
由上图可见,SE-POST block误差相对最大,所以作者建议:SE模块要加在两个分支汇合之前。
至于SE-PRE block、SE-Identity block的top1误差比Standard SE block还小,但SE作者最后并没有采用这种形式,而是用了Standard SE block(也即上图的SE)形式。我猜想可能是plain模型的思维惯性,即放在卷积后面。
在此还要说明一点,SE作者自己说过,这些插入位置什么的,不是SE论文的核心,所以他没做很多实验。他建议针对特定网络结构,针对性地插入SE模块,可能会得到更好的结果。所以SE-PRE block、SE-Identity block甚至SE-POST block都可以尝试一下。(反正深度学习是拿实验数据说话)
2. (类)residual unit内部,SE的插入位置
SE作者还实验了下,把插入位置由下图的 “SE模块” 换到 "SE_3X3"处(3x3指的是block中间那个3x3卷积)。另外说下,下图就是SE-ResNet50的模型图,也就是作者最终选定的结构样式。
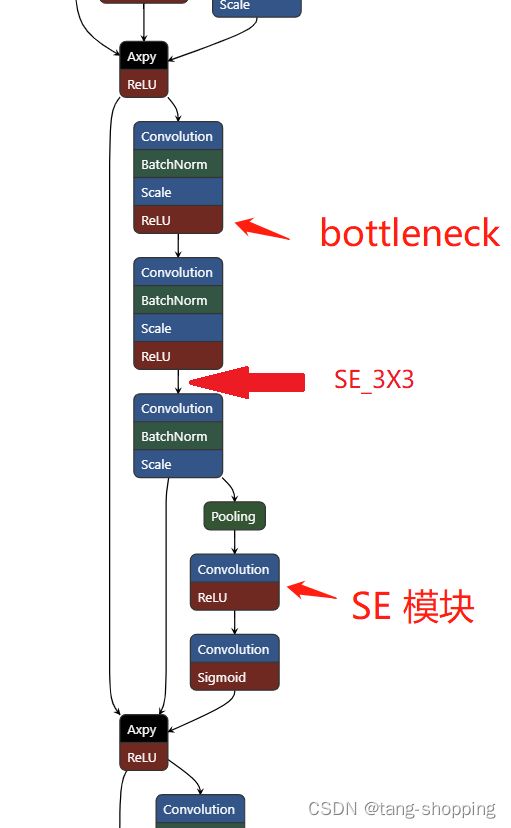
上面实验结果如下,可以发现二者的性能没什么差别,但因为ResNet的3x3卷积比下面1x1卷积的通道数更低,所以SE_3X3的参数量、计算量也更低。
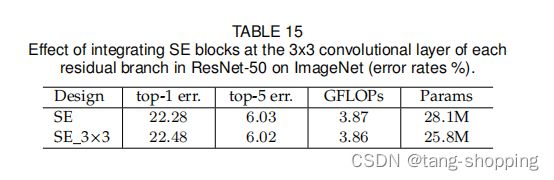
MobileNet v3也借鉴了SE_3X3的添加位置,由下图可见,也是放在3x3卷积与1x1卷积之间。
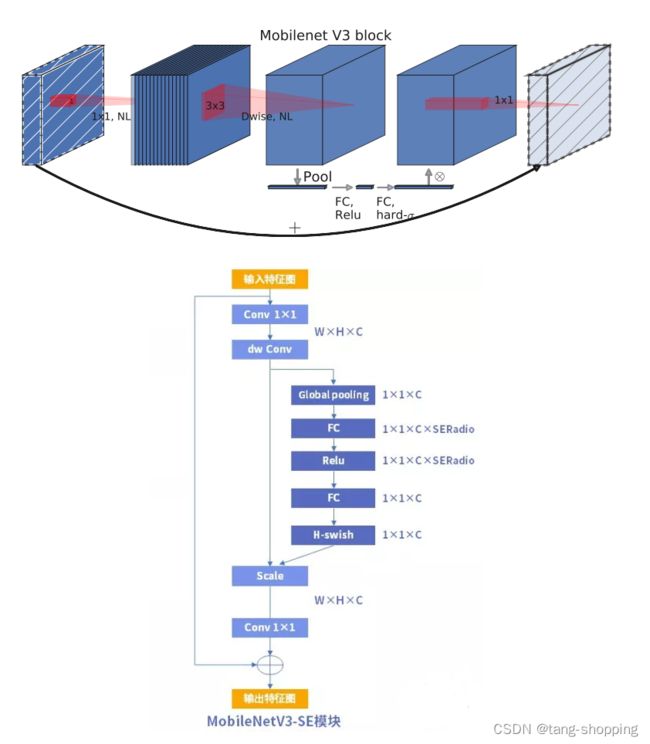
此外,看git上MobileNet v3代码,会发现SE的插入位置还有个版本,该版本插入位置与SE-ResNet50一致,在unit最后一个卷积后面。这里估计是想减少点参数量及计算复杂度,毕竟MobileNet v3的3x3卷积比下面1x1卷积的通道数更高。实际使用时,两个位置都可以试试。
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, kernel_size, in_size, expand_size, out_size, nolinear, semodule, stride):
"""
这块代码不重要,就不贴出来了,免得不好看博客
"""
def forward(self, x):
out = self.nolinear1(self.bn1(self.conv1(x)))
out = self.nolinear2(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.se != None: # 在 1x1卷积后面插入SE模块
out = self.se(out)
out = out + self.shortcut(x) if self.stride==1 else out
return out
自YOLO V5面世以来,针对其的改进也有添加SE模块的方式。纵观网上的博客,发现V5添加SE模块一般是在两个位置:
① 在C3-bottleneck中添加SE模块的,这样添加主要为了更好的做实验,参考博客;
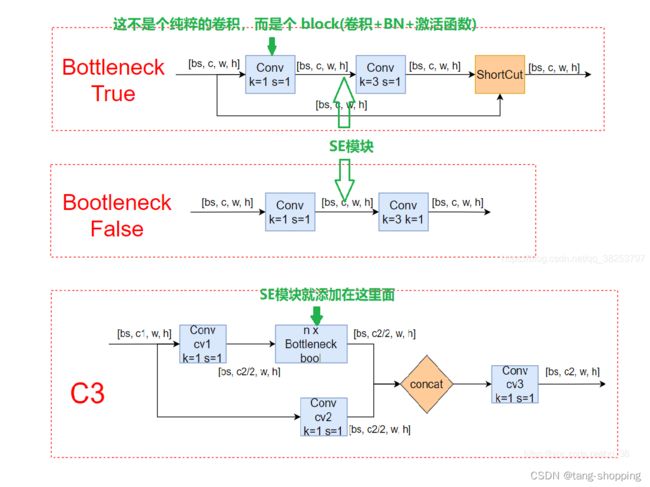
另外,目前一般是加在bottleneck中第一个卷积block后面,参考上面的博客内容,也可以试试放在第二个卷积block后面。最后我们可以看到,无论是YOLO V5、MobileNet v3还是SE-ResNet50,添加SE模块都是以block为单位目标来添加的,这点与我们在博文开头处的观点倒是不谋而合。
② 在V5-backbone结尾处添加SE模块。
这个添加位置比较少见,我也是看这个参考博客才知道,博主表示 backbone结尾添加一个注意力机制 会好点。
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Focus, [64, 3]], # 0-P1/2 #1
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 #2
[-1, 3, C3, [128]], #3
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 #4
[-1, 9, C3, [256]], #5
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 #6
[-1, 9, C3, [512]], #7
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 #8
[-1, 1, SPP, [1024, [5, 9, 13]]], #9
[-1, 3, C3, [1024, False]], # 9 #10
[-1, 1, SELayer, [1024, 4]], # SE模块加在block的外面,即 SE-POST block方式
]
想了一下,这点在SE论文里的SE-Inception也有体现。如下图:
3. 在模型哪几层插入SE模块
这对我们使用SE模块,确实是个问题,每层都用不合适,选一层的话又不知道应该选哪层。SE作者为此做了个实验。
先看看作者做实验的模型,绿色的字体是我打的,让各位更明白模型每个stage在模型中的位置,其中每个feature map尺寸就是一个stage。中间与右边两列中括号里的fc,[xx, xx]就是SE模块。
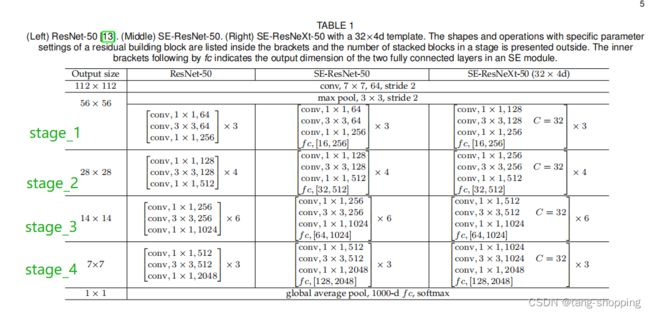
作者做了组对比实验,分别只在SE_stage_2,SE_stage_3,SE_stage_4 插入SE模块,最后又给出所有stage(SE_ALL)插入SE模块的实验结果。可以看见,每层都加的效果是最好的(其参数量与计算量也最高),所以作者最后也是每个block都添加了SE模块。
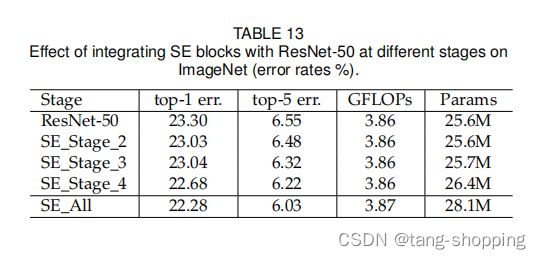
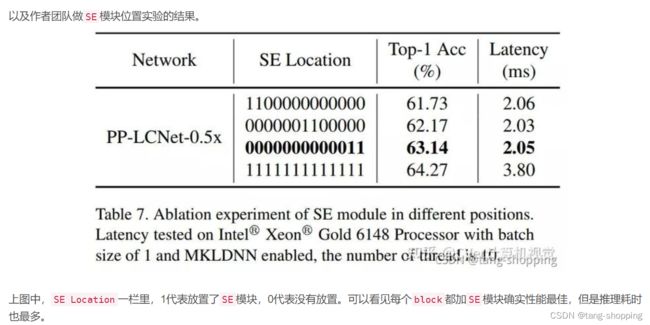
但要注意的是,在模型的最后三个block(SE_stage_4)添加SE模块,会发现 性能-计算复杂度取到一个比较好的平衡,这点在PP-LCNet里也得到了呼应。如下图所示,PP-LCNet在模型最后的两个block添加SE模块(也是最后一个stage),也是取得了性能-计算复杂度平衡,故以后部署平台算力紧张时,可以考虑这种策略。
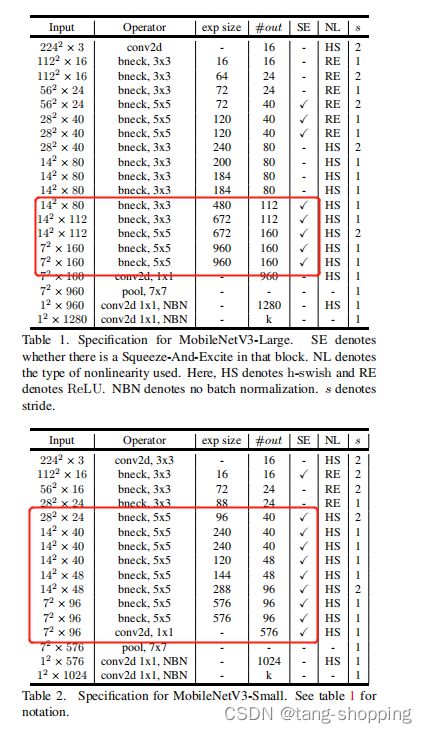
查看MobileNet v3论文,发现其对SE的用法也有点类似于前两者。据下图可知,MobileNet v3在其large与small版本的最后两个stage中都插入了SE模块。以后使用时,在模型最后两个stage添加SE模块性价比更高点,如果算力限制大,也可以试着只在最后一个stage添加SE模块。
三、后语
抛砖引玉之作,如有遗漏、补充,还请各位看官不吝指出,谢谢。