机器学习笔记(二)基础介绍(2)
本文包括以下内容:
1. 模型评估与模型选择
1.1 训练误差与测试误差
训练误差(training error)是模型关于训练集的平均损失;测试误差(test error)是模型关于测试误差的平均损失。测试误差反映了学习方法对未知的测试数据集的预测能力。
泛化能力(generalization ability):学习方法对未知数据的预测能力。
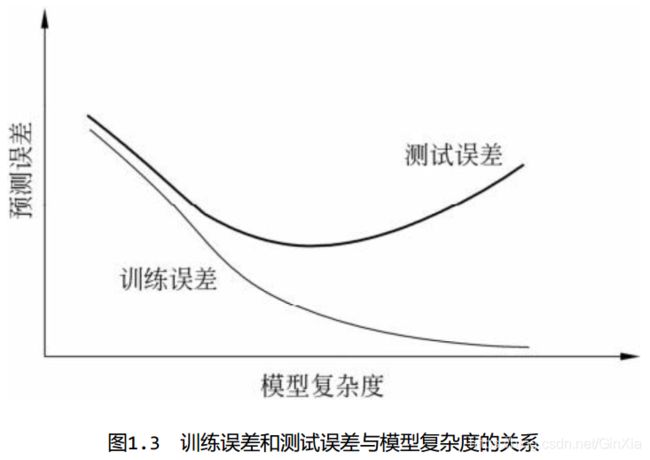
1.2 过拟合与模型选择
过拟合(over-fitting):指学习时选择的模型所包含的参数过多,以致于出现这一模型对已知数据预测得很好,但对未知数据预测得很差的现象。
模型选择(model selection):选择复杂度适当的模型,以达到使测试误差最小。
2. 模型选择方法:正则化与交叉验证
2.1 正则化
正则化(regularization)是最小化结构风险策略的实现,是在经验风险上加上一个正则化项或罚项。正则化项一般是模型复杂度的单调递增函数,模型复杂度越大,正则化项越大。正则化的作用是选择经验风险和模型复杂度同时都较小的模型。
2.2 交叉验证
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分别为
- 训练集(training set):训练模型
- 验证集(validation set):用于模型的选择
- 测试集(test set):用于最终对学习方法的评估。
在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型。如果验证集有足够的数据,用它对模型进行选择也是有效的,但现实中数据常常是不充足的,为了选择好的模型,可以采用交叉验证方法。 交叉验证的基本想法是重复地使用数据;把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、 测试以及模型选择。
2.2.1 简单交叉验证(留出法(hold-out))

训练/测试集的划分要尽可能保持数据分布的一致性。在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
2.2.2 K-折交叉验证(K-fold cross validation)
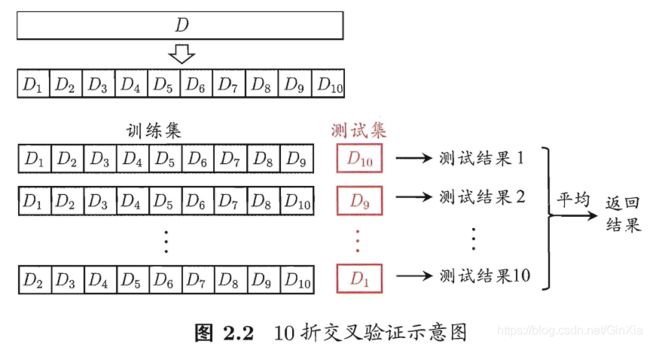
2.2.3 留一交叉验证(leave-one-out cross validation)
K折交叉验证的特殊情形是S=N,往往在数据缺乏的情况下使用。 这里,N是给定数据集的容量。
3. 生成模型与判别模型
监督学习方法又可以分为生成方法(generative approach)和判别方法(discriminative approach)。 所学到的模型分别称为生成模型(generative model)和判别模型(discriminative model)。
3.1 生成模型
生成方法由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:

典型的生成模型有:朴素贝叶斯法和隐马尔可夫模型。
生成方法的特点:生成方法可以还原出联合概率分布P(X,Y),而判别方法则不能;生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快地收敛于真实模型;当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用。
3.2 判别模型
判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。 判别方法关心的是对给定的输入X,应该预测什么样的输出Y。
典型的判别模型包括:k近邻法、 感知机、 决策树、 逻辑斯谛回归模型、 最大熵模型、支持向量机、 提升方法和条件随机场等。
判别方法的特点:判别方法直接学习的是条件概率P(Y|X)或决策函数f(X)(不用去计算先验概率和联合概率),直接面对预测,往往学习的准确率更高;由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象、 定义特征并使用特征,因此可以简化学习问题。
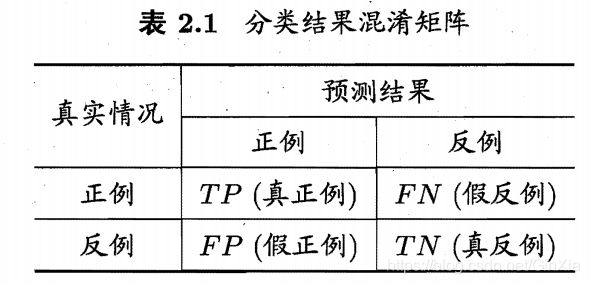
四、模型评价指标
- 准确率(Accuracy)

- 错误率(Error rate)
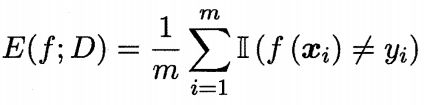
- 精确率/查准率(precision)
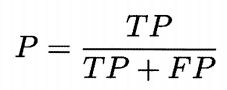
如:检索出的信息中有多少比例是用户感兴趣的。
- 召回率/查全率(recall)

如:用户感兴趣的信息中有多少被检索出来了。
-
P-R图
查准率和查全率是一对矛盾的度量.一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
A优于B优于C

"平衡点 " (Break-Event Point,简称 BEP)是" 查准率=查全率"时的取值。
 和
和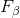 度量
度量




 = 1时退化为标准的 F1; > 1 时查全率有更大影响 ; < 1 时查准率有更大影响.
= 1时退化为标准的 F1; > 1 时查全率有更大影响 ; < 1 时查准率有更大影响.
-
ROC曲线("受试者工作特征" (Receiver Operating Characteristic))
真正例率(True Positive Rate,简称 TPR):

假正例率 (False Positive Rate,简称 FPR):
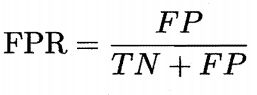
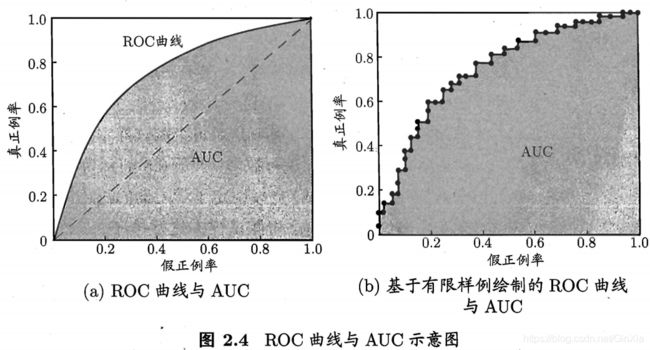
若一个学习器的 ROC 曲线被另 一个学习器的曲线完全"包住", 则可断言后者的性能优于前者;若两个学习器的 ROC 曲线发生交叉,则难以-般性地断言两者孰优孰劣 . 此时如果一定要进行比较, 则较为合理的判据是 比较 ROC 曲线下 的面积,即 AUC (Area Under ROC Curve)。
参考资料
1. 统计学习方法. 第2版. 清华大学出版社. 李航著
2. 机器学习. 清华大学出版社. 周志华著