Mobile V1-Keras复现
这是我第一次复现论文:复现地址
复现之前你需要了解的:
- MobileNet V1的网络结构

总结来说就是:
1个3*3的普通卷积,特别注意stride = 2,作用是压缩图像大小,提取关键特征
6个深度可分离卷积,注意stride分别为1, 2, 1, 2, 1, 2。在经过stride = 2的卷积核之后,图像的大小减半。
5个可选的深度可分离卷积,stride = 2
1个stride = 2和1个stride = 1的深度可分离卷积
平均池化,全连接层,Softmax层
共28层
- 超参数
width multiplier(宽度乘数)——在深度可分离的卷集中按比例减少通道数
resolution multiplier(分辨率乘数)——改变输入层的分辨率
1. 关于数据预处理
在传进参数时,有这样的一个函数:
input_shape = _obtain_input_shape(input_shape,
default_size=224,
min_size=96,
data_format=K.image_data_format(),
require_flatten=True)_obtain_input_shape这个函数主要是为了确定合适的输入形状,其中重要的参数有:
- min_size:模型所能接受的最小长宽
- data_format:数据所使用的格式
- require_flatten:是否通过一个Flatten层再连接到分类器
下面也有一个数据简单处理:
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not K.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor- Input将shape转换为Keras的数据类型格式
- 如果是Tensor的数据各格式,需要再进行判断是否为keras指定的数据类型
在定义完网络结构之后,我们可以看到如下的数据处理:
if input_tensor is not None:
inputs = get_source_inputs(input_tensor)
else:
inputs = img_input- get_source_inputs返回计算需要的数据列表,List of input tensors.
2. 两个重要的卷积函数:
在mobilenet中,主要是使用深度可分离卷积,深度可分离卷积可以分解成一个深度卷积和一个普通卷积,对应的函数为DepthwiseConv2D和Convolution2D,当然,在Keras2.2.2的版本中,它们也可以合并为一个操作,即深度可分离卷积SeparableConv2D,其中DepthwiseConv2D和SeparableConv2D的参数具体介绍如下:keras中的深度可分离卷积 SeparableConv2D与DepthwiseConv2D
3. SeparableConv2D不能很好地满足模型的要求
我们以论文中的模型为例,论文中将标准的3*3卷积操作分解成深度卷积和普通卷积,在这两个卷积背后都有都有BN层和Relu层,如图所示:

但是Keras中的SeparableConv2D卷积存在一个问题:在进行完深度卷积后没有BN层和Relu层,也就是说,我们在不修改底层代码的前提下,我们无法实现在3*3 Depthwise Conv后添加BN和Relu层。下面是对比:

传入为112*112的图片,32通道,那么在SeparableConv2D中(filter = 3*3),所需要的参数为(3*3*32)+(1*1*32*64) = 288 + 2048 = 2336(这里并没有BN的参数),但是论文中的实现应该如下:
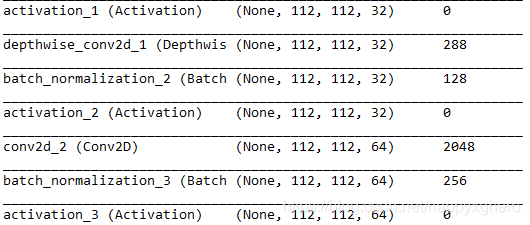
depthwise_conv2d_1:3 * 3 * 32 = 288
batch_normalization_2:32 * 4 =128
conv2d_2(1 * 1):1 * 1 * 32 * 64 = 2048
batch_normalization_3:64 * 4 = 256
模型搭建之后,在cifar10上测试:
设置参数:
def MobileNet(input_tensor=None, input_shape=None, alpha=1,
shallow=False, classes=10)
train_history = model.fit(x_img_train, y_label_train,
validation_split=0.2, epochs=10,
batch_size=128, verbose=2)
训练结果
第一次训练:
模型加载失败!从头开始训练
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
- 34s - loss: 1.5331 - acc: 0.4323 - val_loss: 1.8564 - val_acc: 0.4284
Epoch 2/10
- 26s - loss: 1.1971 - acc: 0.5717 - val_loss: 1.7528 - val_acc: 0.5151
Epoch 3/10
- 26s - loss: 1.0296 - acc: 0.6370 - val_loss: 1.3777 - val_acc: 0.5713
Epoch 4/10
- 26s - loss: 0.9036 - acc: 0.6843 - val_loss: 1.3622 - val_acc: 0.5898
Epoch 5/10
- 26s - loss: 0.7925 - acc: 0.7243 - val_loss: 1.3450 - val_acc: 0.5780
Epoch 6/10
- 26s - loss: 0.6982 - acc: 0.7579 - val_loss: 1.6974 - val_acc: 0.5504
Epoch 7/10
- 26s - loss: 0.6088 - acc: 0.7880 - val_loss: 1.5063 - val_acc: 0.5903
Epoch 8/10
- 26s - loss: 0.5358 - acc: 0.8152 - val_loss: 1.2562 - val_acc: 0.6417
Epoch 9/10
- 26s - loss: 0.4666 - acc: 0.8395 - val_loss: 1.5148 - val_acc: 0.6156
Epoch 10/10
- 26s - loss: 0.4039 - acc: 0.8602 - val_loss: 1.6205 - val_acc: 0.6308
保存模型成功!
第二次训练:
模型加载成功!继续训练
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
- 29s - loss: 0.3416 - acc: 0.8821 - val_loss: 1.3632 - val_acc: 0.6509
Epoch 2/10
- 27s - loss: 0.2751 - acc: 0.9052 - val_loss: 1.6339 - val_acc: 0.6316
Epoch 3/10
- 26s - loss: 0.2505 - acc: 0.9130 - val_loss: 1.3428 - val_acc: 0.6676
Epoch 4/10
- 27s - loss: 0.2201 - acc: 0.9228 - val_loss: 1.5963 - val_acc: 0.6614
Epoch 5/10
- 26s - loss: 0.2001 - acc: 0.9305 - val_loss: 1.4577 - val_acc: 0.6550
Epoch 6/10
- 26s - loss: 0.1804 - acc: 0.9376 - val_loss: 1.6836 - val_acc: 0.6426
Epoch 7/10
- 26s - loss: 0.1610 - acc: 0.9456 - val_loss: 1.6148 - val_acc: 0.6677
Epoch 8/10
- 26s - loss: 0.1551 - acc: 0.9456 - val_loss: 1.6716 - val_acc: 0.6430
Epoch 9/10
- 26s - loss: 0.1443 - acc: 0.9489 - val_loss: 1.6512 - val_acc: 0.6543
Epoch 10/10
- 26s - loss: 0.1315 - acc: 0.9538 - val_loss: 1.7415 - val_acc: 0.6481
保存模型成功!
在第二次训练的后半部分产生了过拟合的情况,最好的情况是14个Epoch:
loss: 0.2201 - acc: 0.9228 - val_loss: 1.5963 - val_acc: 0.6614
接下来我们测试去掉5个1 * 1stride的深度可分离卷积的模型:
def MobileNet(input_tensor=None, input_shape=None,
alpha=1, shallow=True, classes=10)
train_history = model.fit(x_img_train, y_label_train,
validation_split=0.2, epochs=10,
batch_size=128, verbose=2)第一次训练:
模型加载失败!从头开始训练
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
- 23s - loss: 1.4456 - acc: 0.4725 - val_loss: 1.6133 - val_acc: 0.4621
Epoch 2/10
- 19s - loss: 1.1143 - acc: 0.6021 - val_loss: 1.4213 - val_acc: 0.5320
Epoch 3/10
- 19s - loss: 0.9503 - acc: 0.6619 - val_loss: 1.5719 - val_acc: 0.5302
Epoch 4/10
- 19s - loss: 0.8102 - acc: 0.7130 - val_loss: 1.2614 - val_acc: 0.5958
Epoch 5/10
- 19s - loss: 0.6969 - acc: 0.7525 - val_loss: 1.2059 - val_acc: 0.5957
Epoch 6/10
- 19s - loss: 0.6057 - acc: 0.7846 - val_loss: 1.1094 - val_acc: 0.6464
Epoch 7/10
- 19s - loss: 0.5104 - acc: 0.8172 - val_loss: 1.0891 - val_acc: 0.6674
Epoch 8/10
- 19s - loss: 0.4509 - acc: 0.8385 - val_loss: 1.6324 - val_acc: 0.5797
Epoch 9/10
- 19s - loss: 0.3780 - acc: 0.8650 - val_loss: 1.3757 - val_acc: 0.6469
Epoch 10/10
- 19s - loss: 0.3158 - acc: 0.8864 - val_loss: 1.4056 - val_acc: 0.6483
保存模型成功!
第二次训练:
模型加载成功!继续训练
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
- 22s - loss: 0.2818 - acc: 0.8980 - val_loss: 1.4402 - val_acc: 0.6647
Epoch 2/10
- 20s - loss: 0.2313 - acc: 0.9172 - val_loss: 1.5205 - val_acc: 0.6505
Epoch 3/10
- 20s - loss: 0.2001 - acc: 0.9274 - val_loss: 1.5250 - val_acc: 0.6584
Epoch 4/10
- 21s - loss: 0.1743 - acc: 0.9387 - val_loss: 1.6416 - val_acc: 0.6671
Epoch 5/10
- 20s - loss: 0.1667 - acc: 0.9410 - val_loss: 1.6278 - val_acc: 0.6493
Epoch 6/10
- 20s - loss: 0.1589 - acc: 0.9427 - val_loss: 1.7327 - val_acc: 0.6668
Epoch 7/10
- 20s - loss: 0.1487 - acc: 0.9464 - val_loss: 1.7591 - val_acc: 0.6497
Epoch 8/10
- 20s - loss: 0.1231 - acc: 0.9562 - val_loss: 1.6630 - val_acc: 0.6742
Epoch 9/10
- 20s - loss: 0.1184 - acc: 0.9572 - val_loss: 1.8394 - val_acc: 0.6489
Epoch 10/10
- 20s - loss: 0.1183 - acc: 0.9584 - val_loss: 2.0322 - val_acc: 0.6319
保存模型成功!
在第二次训练的后半部分产生了过拟合的情况,最好的情况是18个Epoch:
- 20s - loss: 0.1231 - acc: 0.9562 - val_loss: 1.6630 - val_acc: 0.6742
Mobile-lite的表现比Mobile要好一点