信用风险计量模型汇总
信用风险计量模型汇总
信用风险计量模型的基本技术路线是,利用借款者的特征指标和宏观经济变量,收集这些特征指标和宏观变量的历史数据,并将其应用于预测违约借款人与履约借款人。预测模型旨在评估未知借款者将来是否还款的信用价值,将潜在借款者的特征值输入模型,从模型中输出信用价值评估,从而可对潜在借款人进行信用评估。
一般的评级方法可以分为专家经验判断法、参数模型和非参数模型。所谓的专家经验判断,就是相关专家根据主观经验进行打分,后两种方法都是根据模型进行客观的计算。而对于参数模型与非参数模型的区分:用代数方程、微分方程、微分方程组以及传递函数等描述的模型都是参数模型。建立参数模型就在于确定已知模型结构中的各个参数,通过理论分析总是得出参数模型;非参数模型是直接或间接地从实际系统的实验分析中得到的响应,例如通过实验记录到的系统脉冲响应或阶跃响应就是非参数模型。
下面的例子给大家通俗易懂的解释一下。
例子:项目组小翟最近喜欢上了一个姑娘,但是非常苦恼姑娘是不是喜欢自己。小翟来咨询他的人生导师-小张姐姐,小张姐姐根据自己的经验判断姑娘不会喜欢他,小翟非常伤心,这就是专家经验判断法。
之后,小翟又来咨询数据分析高手-小金哥哥,小金哥哥通过分析小翟和姑娘的生辰八字,列出了回归方程,判断姑娘会有37.28%概率喜欢上小翟,小翟非常伤心,这就是参数模型。
最后,小翟又来咨询数学专业高材生-小沈姐姐,小沈姐姐收集了几十对在一起的情侣又收集了几十对没有在一起的情侣,通过决策树的算法,判断小翟和姑娘的数据更偏向于没有在一起的情侣,小翟非常伤心,这就是非参数模型。
专家判断法
专家经验判断
专家经验判断是根据信贷专家多年从业经验进行定性判断。
- 层次分析法
层次分析法(简称AHP)是美国运筹学家Saaty教授于20世纪70年代初提出的,其特点是把复杂问题中的各种因素通过划分为相互联系的有序层次,使之条理化。作为规划、决策和评价的工具,AHP自问世以来,已在各个领域得到迅速普及和推广,取得了大量的研究成果。层次分析法主要用于确定综合评价的权重系数,所用数学工具主要是矩阵的运算。信用风险的测算是一个复杂的、多层次的评价过程,每个指标要素之间的关系是相互依存、相互作用的,它们是一个整体。
层次分析法计算过程如下:
一、每两个指标的相对重要性判断
- 假设函数f(x,y),它表示评价指标x对于评价指标y的重要程度。约定f(x,y)=1/f(y,x)。如下表所示。
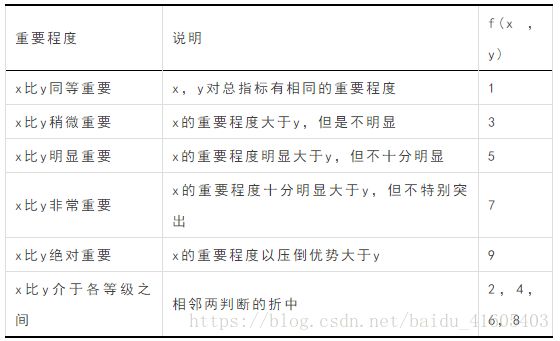
二、构造判断矩阵
- 设
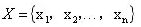 为全部评价指标所组成的一个集,按照上表中所列的各个指标之间的重要程度,对所有同层次之间的评价指标进行两两之间的对比,构造矩阵
为全部评价指标所组成的一个集,按照上表中所列的各个指标之间的重要程度,对所有同层次之间的评价指标进行两两之间的对比,构造矩阵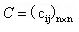 ,其中
,其中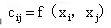 ,并且矩阵C称之为判断矩阵。
,并且矩阵C称之为判断矩阵。 
三、计算权重
- 根据上述构造的判断矩阵C,通过矩阵运算,计算它的最大特征值
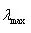 ,并求出矩阵C关于最大特征值的特征向量
,并求出矩阵C关于最大特征值的特征向量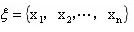 ,经过归一化处理后的xi就是各评价因子的权重。
,经过归一化处理后的xi就是各评价因子的权重。
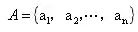 ,矩阵A即为权重向量。
,矩阵A即为权重向量。
四、一致性检验
-
根据下式计算一致性指标CI
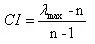
-
查找平均随机一致性指标RI.

根据下式计算一致性比例CR。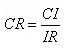
当CR<0.10,认为判断矩阵的一致性是可以接受的,否则对判断矩阵进行适当的修改,最终达到一致性要求。
参数模型
- 一、逻辑回归
Logistic回归用于分类的应用比较广泛,利用Logistic回归模型可以将因变量与自变量之间关系的求解转变为求解被解释变量发生类别的相应概率。Logistic回归模型的思想来自于线性回归,是一种非线性概率回归,多元线性回归用来预测由多个连续解释变量构成的函数模型的被解释变量数值的大小,而Logistic回归是用来预测由一个或多个解释变量构成的分类函数中属于其中一类的概率。
Logistic逻辑回归分析的假设前提为:
(1) 数据来自随机样本;
(2)自变量之间不存在多重共线性关系。
Logistic函数的形式为: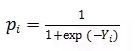
那么在回归模型基础上计算得出的发生的概率和之间存在如下的回归关系: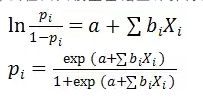
逻辑回归模型是解决0-1回归问题行之有效的方法,模型的曲线为S型,最大值趋近1,最小值趋近0。通过设定临界值作为事件发生与否的标准,如果事件发生的概率大于临界值,则判定事件发生;反之,判定事件不发生。和判别分析方法不同,Logistic回归模型在理论上并不存在“最优”的分割点,分割点的选取取决于模型使用者的具体目的。
实现方式
一般逻辑回归数据量不是特别大,spss操作起来简单易懂,同时SAS\Python都可以实现。
SAS基础代码:
proc logistic data=数据名 desending;model 因变量=自变量; run;
判别分析
纽约大学斯特恩商学院教授爱德华·阿特曼(Edward Altman)在1968年就对美国破产和非破产生产企业进行观察,采用了22个财务比率经过数理统计筛选建立了著名的5变量Z-score模型。Z-score模型是以多变量的统计方法为基础,以破产企业为样本,通过大量的实验,对企业的运行状况、破产与否进行分析、判别的系统。Z-score模型在美国、澳大利亚、巴西、加拿大、英国、法国、德国、爱尔兰、日本和荷兰得到了广泛的应用。
1973年,美国芝加哥大学教授 Fischer Black&Myron Scholes提出了著名的B-S定价模型,用于确定欧式股票期权价格,在学术界和实务界引起了强烈反响;同年,Robert C. Merton独立地提出了一个更为一般化的模型,布莱克-舒尔斯-默顿期权定价模型(下文简称B-S-M模型),并由此导出衍生证券定价的一般方法。舒尔斯和莫顿由此获得了1997年的诺贝尔经济学奖。现在,布莱克—斯科尔斯—莫顿定价公式已被期货市场参与者广泛接受,是金融工程中所有定价理论的基石。 信用资产的违约行为表现为借款人到期不能偿还贷款的本金利息。莫顿理论假设一旦借款人的资产市值在一年内低于其现有负债价值,则借款人将发生违约。如果我们能获得资产波动的相关性,借助以资产为基础的违约,就可以获得违约的相关性。而资产波动的相关性,在资本市场上是可以观察到的,并有完整的数据积累。当借款人的资产市场价值小于一个阀值(负债)时,借款人发生违约。 根据BSM模型,可以将贷款看做一种期权,一旦市值小于其负债就看做执行期权,产生违约。期权执行的概率=N(d2),即违约概率 对没有目标变量的数据集根据数据的相似性给出 “自然的”分组,类内对象相似性尽量大,类间对象相似性尽量小。根据结果类的分离性,聚类分为重叠聚类与互斥聚类。 首先定义能度量样品(或变量)间相似程度(亲疏关系)的统计量,在此基础上求出各样品(或变量)间相似程度的度量值;然后按相似程度的大小,把样品(或变量)逐一归类,关系密切的聚集到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到所有的样品(或变量)都聚合完毕,把不同的类型一一划分出来,形成一个由小到大的分类系统。 聚类分析可以由SPSS点击实现,也可以由SAS函数实现。聚类分析SAS代码: 决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。 决策树在SPSS里有成型的算法,直接单击使用即可。SAS中的Proc split或Proc hpsplit函数可以直接调用。R语言中的rpart()函数也可以直接调用生成决策树。 决策树有很多优点,比如:易于理解、易于解释、可视化、无需大量数据准备。使用决策树(预测数据)的成本是训练决策时所用数据的对数量级。 但这些模型往往不直接使用,决策树一些常见的缺陷是: 构建的树过于复杂,无法很好地在数据上实现泛化、数据的微小变动可能导致生成的树完全不同,因此决策树不够稳定、决策树学习算法在实践中通常基于启发式算法,如贪婪算法,在每一个结点作出局部最优决策。此类算法无法确保返回全局最优决策树。、如果某些类别占据主导地位,则决策树学习器构建的决策树会有偏差。因此推荐做法是在数据集与决策树拟合之前先使数据集保持均衡。 由于决策树容易对数据产生过拟合,因此分支更少(即减少区域 R_1, … ,R_J)的小树虽然偏差略微高一点,但其产生的方差更低,可解释性更强。减少决策树的方差可以通过袋装(bagging)和随机扥林方法来实现,由于随机森林在效果上好于袋装,下面只介绍随机森林函数。 顾名思义,森林是由很多颗树构成,随机森林也是由很多个决策树构成。随机森林通过随机扰动而令所有的树去相关,在构建每一棵树时,每一个结点分割前都是采用随机样本预测器。随机森林可以考虑使用大量预测器,不仅因为这种方法减少了偏差,同时局部特征预测器在树型结构中充当重要的决策。 随机森林可以使用巨量的预测器,甚至预测器的数量比观察样本的数量还多。采用随机森林方法最显著的优势是它能获得更多的信息以减少拟合数值和估计分割的偏差。 随机森林可由R语言中的randomforest()函数实现。函数默认生成500颗树,并且默认每个节点抽取个变量。 支持向量机分类器的基本原理是通过一个非线性变换将一个线性不可分的空间映射到另一个高维的线性可分的空间,并建立一个分类器,这个分类器具有极小的 VC 维数。该分类器仅由大量样本中的极少数支持向量确定,并且具有最大的边界宽度。支持向量机算法的好处在于不是直接计算复杂的非线性变换,而是通过计算非线性变换的点积,因而大大简化了计算量。通过把核函数引入到一些学习算法中来,可以很方便地把线性算法转换为非线性算法,将其与支持向量机一起称为基于核函数的方法。 从信用评级问题的特点来看,适合采用SVM进行处理。SVM的特点之一是简单、推广能力强和易于解释。银行信用评级历史数据的一个特点是分布零散,各个信用等级的样本数据量差别很大,而且可能存在较多的有缺陷的样本。如果使用一般的模式识别模型,由于各个类别样本数据量不对称,训练过程中分类器分类效果会向样本量大的类别倾斜。然而对商业银行来说,一些高风险类别的对象,其数量虽然少,但是将其识别出来却是至关重要的。 另一方面,借款人的历史数据中存在缺陷是很正常的,甚至会有虚假信息,这些样本应该被剔除掉。如果使用全部样本训练分类器的话,这些样本的存在可能会对分类器性能产生极大影响。但在SVM模型中,只有支持向量才对优化起作用,而支持向量的数量是非常有限的。因此,可以在使用SVM模型得到结果后。由专家对支持向量集进行研究。既可以得到对结果的深入认识,又可以对支持向量样本进行审查,如果其中包含了有严重缺陷的样本的话可以剔除出去重新训练。 SVM模型的另一个特点是泛化能力强,SVM模型的复杂度可以由支持向量的数量来描述,而这又很容易控制。因此,SVM模型不会出现过拟合问题,模型的稳定性相当好,能很好满足银行对信用评级系统的稳定性要求。 支持向量机可以通过R语言中kernlab包的ksvm()函数和e1071包中的svm()函数实现。 最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。 KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 R语言里的kknn包可以实现最邻近算法——使用kknn()函数。 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。 贝叶斯分类器可通过R语言朴素贝叶斯包 klaRNaiveBayes()实现。 -------------------- 
X1=(流动资产-流动负债)/资产总额;
X2=(未分配利润+盈余公积金)/资产总额;
X3=(税前利润十财务费用)/资产总额;
x4=(每股市价流通股数+每股净资产非流通股数)/负债总额;
X5=主营业务收入/资产总额
判断准则:Z<1.8,破产区;1.8≤Z<2.99,灰色区;2.99
经典BSM模型:

非参数模型
proc varclus data=数据集 outtree=tree;
var 变量;
run;
proc tree data =tree;run;
经典贝叶斯公式:
作者:baidu_41605403
来源:CSDN
原文:https://blog.csdn.net/baidu_41605403/article/details/83141847
版权声明:本文为博主原创文章,转载请附上博文链接!