pytorch实现yolov4的cam热力图可视化
参考视频:https://www.bilibili.com/video/av799922871/ 参考代码位置:https://github.com/IDayday/YOLOv4_CAM YOLOv4代码参考博主:https://blog.csdn.net/weixin_44791964/article/details/106214657
本文代码位置(后期会放到github上)
【下一篇:pytorch实现yolov4的Grad-cam热力图可视化】
CAM利用GAP(Global Average Pooling)替换掉了全连接层。
热力图可视化展示:

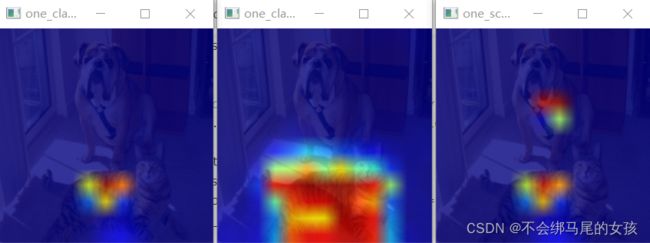
一、修改代码
在detect_image函数中,增加返回outputs
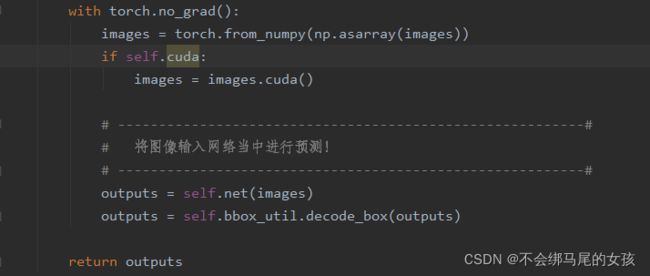
show_CAM函数:
def show_CAM(image_path, feature_maps, class_id, all_ids=85, show_one_layer=True):
"""
feature_maps: this is a list [tensor,tensor,tensor], tensor shape is [1, 3, N, N, all_ids]
"""
SHOW_NAME = ["score", "class", "class_score"]
img_ori = cv2.imread(image_path)
layers0 = feature_maps[0].reshape([-1, all_ids])#[,85]
layers1 = feature_maps[1].reshape([-1, all_ids])#[,85]
layers2 = feature_maps[2].reshape([-1, all_ids])#[,85]
layers = torch.cat([layers0, layers1, layers2], 0)#[,10]
#第五个参数
score_max_v = layers[:, 4].max()
score_min_v = layers[:, 4].min()
#分类的得分
class_max_v = layers[:, 5 + class_id].max()
class_min_v = layers[:, 5 + class_id].min()
all_ret = [[], [], []]
for j in range(3): # layers
layer_one = feature_maps[j]
# compute max of score from three anchor of the layer
anchors_score_max = layer_one[0, ..., 4].max(0)[0]
# compute max of class from three anchor of the layer
anchors_class_max = layer_one[0, ..., 5 + class_id].max(0)[0]
scores = ((anchors_score_max - score_min_v) / (
score_max_v - score_min_v))
classes = ((anchors_class_max - class_min_v) / (
class_max_v - class_min_v))
layer_one_list = []
layer_one_list.append(scores)#置信度--第一张图
layer_one_list.append(classes)#哪一个类别--第二张图
layer_one_list.append(scores * classes)#加权--第三张图
for idx, one in enumerate(layer_one_list):
layer_one = one.cpu().numpy()
ret = ((layer_one - layer_one.min()) / (layer_one.max() - layer_one.min())) * 255
ret = ret.astype(np.uint8)
gray = ret[:, :, None]
ret = cv2.applyColorMap(gray, cv2.COLORMAP_JET)
if not show_one_layer:
all_ret[j].append(cv2.resize(ret, (img_ori.shape[1], img_ori.shape[0])).copy())
else:
ret = cv2.resize(ret, (img_ori.shape[1], img_ori.shape[0]))
show = ret * 0.8 + img_ori * 0.2#热力图和原图片的比例
show = show.astype(np.uint8)
cv2.imshow(f"one_{SHOW_NAME[idx]}", show)
cv2.imwrite('./cam_results/head' + str(j) + 'layer' + str(idx) + SHOW_NAME[idx] + ".jpg", show)
# cv2.imshow(f"map_{SHOW_NAME[idx]}", ret)
if show_one_layer:
cv2.waitKey(0)
if not show_one_layer:
for idx, one_type in enumerate(all_ret):
map_show = one_type[0] / 3 + one_type[1] / 3 + one_type[2] / 3
show = map_show * 0.8 + img_ori * 0.2
show = show.astype(np.uint8)
map_show = map_show.astype(np.uint8)
cv2.imshow(f"all_{SHOW_NAME[idx]}", show)
cv2.imwrite('img/head_cont' + str(idx) + SHOW_NAME[idx] + ".jpg", show)
# cv2.imshow(f"map_{SHOW_NAME[idx]}", map_show)
cv2.waitKey(0)
all_ids要改为4+1+类别数,这里我使用的coco数据集总共有80类别,1是置信度,4是确定预测边框位置所需要的四个参数