改进YOLOv5系列:5.CotNet Transformer结构的修改
YOLOAir:助力YOLO论文改进 、 不同数据集涨点、创新点改进

- YOLOAir项目:基于 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 本项目包含大量的改进方式,降低改进难度,改进点包含
Backbone、Neck、Head、注意力机制、IoU损失函数、NMS、Loss计算方式、自注意力机制、数据增强部分、激活函数等部分,详情可以关注 YOLOAir 的说明文档。 - 同时
附带各种改进点原理及对应的代码改进方式教程,用户可根据自身情况快速排列组合,在不同的数据集上实验, 应用组合写论文, 创造自己的毕业项目!
新的仓库链接:YOLOAir仓库:https://github.com/iscyy/yoloair
可以 fork 和 star,持续同步更新完善
本篇是《CotNet Transformer结构》的修改 演示
使用YOLOv5网络作为示范,可以无缝加入到 YOLOv7、YOLOX、YOLOR、YOLOv4、Scaled_YOLOv4、YOLOv3等一系列YOLO算法模块

论文:Contextual Transformer Networks for Visual Recognition
论文地址:https://arxiv.org/abs/2107.12292
文章目录
-
- YOLOAir:助力YOLO论文改进 、 不同数据集涨点、创新点改进
- CoTNet理论部分
- YOLOv5的yaml配置文件修改
- common.py配置
- yolo.py配置修改
- 训练yolov5s_cotnet.yaml模型
- 基于以上yolov5s_cotnet.yaml文件继续修改
CoTNet理论部分
具有自注意力的 Transformer 引发了自然语言处理领域的革命,最近激发了 Transformer 风格的架构设计的出现,并在众多计算机视觉任务中取得了具有竞争力的结果。然而,大多数现有设计直接在 2D 特征图上使用自注意力来获得基于每个空间位置的隔离查询和键对的注意力矩阵,但未充分利用相邻键之间的丰富上下文。在这项工作中,我们设计了一种新颖的 Transformer 风格的模块,即 Contextual Transformer ( CoT) 块,用于视觉识别。这样的设计充分利用了输入键之间的上下文信息来指导动态注意力矩阵的学习,从而增强了视觉表示的能力。从技术上讲,CoT 块首先通过上下文对输入键进行编码卷积,导致输入的静态上下文表示。我们进一步将编码键与输入查询连接起来,通过两个连续的卷积。学习到的注意力矩阵乘以输入值,以实现输入的动态上下文表示。静态和动态上下文表示的融合最终被作为输出。我们的 CoT 块很有吸引力,因为它可以很容易地替换每个ResNet 架构中的卷积,产生了一个名为 Contextual Transformer Networks ( CoTNet ) 的 Transformer 风格的主干。通过对广泛应用(例如,图像识别、对象检测和实例分割)的广泛实验,我们验证了 CoTNet 作为更强大主干网络的优越性。
Multi-head Self-attention
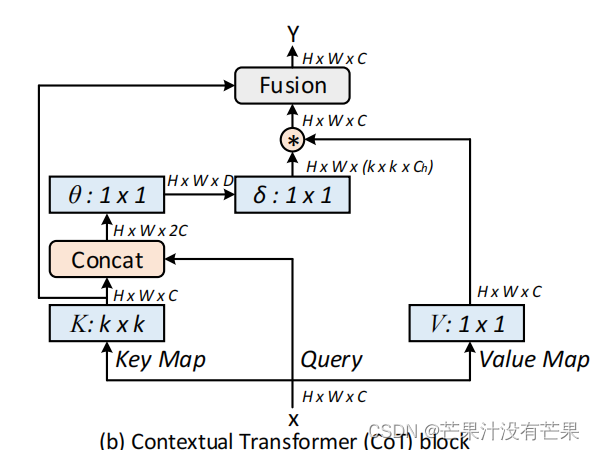
Contextual Transformer (CoT) block结构图
YOLOv5的yaml配置文件修改
增加以下yolov5s_cotnet.yaml文件
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, CoT3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, CoT3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, CoT3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, CoT3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
common.py配置
./models/common.py文件增加以下模块
class CoT3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[CoTBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class CoTBottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(CoTBottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = CoT(c_, 3)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class CoT(nn.Module):
# Contextual Transformer Networks https://arxiv.org/abs/2107.12292
def __init__(self, dim=512,kernel_size=3):
super().__init__()
self.dim=dim
self.kernel_size=kernel_size
self.key_embed=nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,padding=kernel_size//2,groups=4,bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed=nn.Sequential(
nn.Conv2d(dim,dim,1,bias=False),
nn.BatchNorm2d(dim)
)
factor=4
self.attention_embed=nn.Sequential(
nn.Conv2d(2*dim,2*dim//factor,1,bias=False),
nn.BatchNorm2d(2*dim//factor),
nn.ReLU(),
nn.Conv2d(2*dim//factor,kernel_size*kernel_size*dim,1)
)
def forward(self, x):
bs,c,h,w=x.shape
k1=self.key_embed(x) #bs,c,h,w
v=self.value_embed(x).view(bs,c,-1) #bs,c,h,w
y=torch.cat([k1,x],dim=1) #bs,2c,h,w
att=self.attention_embed(y) #bs,c*k*k,h,w
att=att.reshape(bs,c,self.kernel_size*self.kernel_size,h,w)
att=att.mean(2,keepdim=False).view(bs,c,-1) #bs,c,h*w
k2=F.softmax(att,dim=-1)*v
k2=k2.view(bs,c,h,w)
return k1+k2
yolo.py配置修改
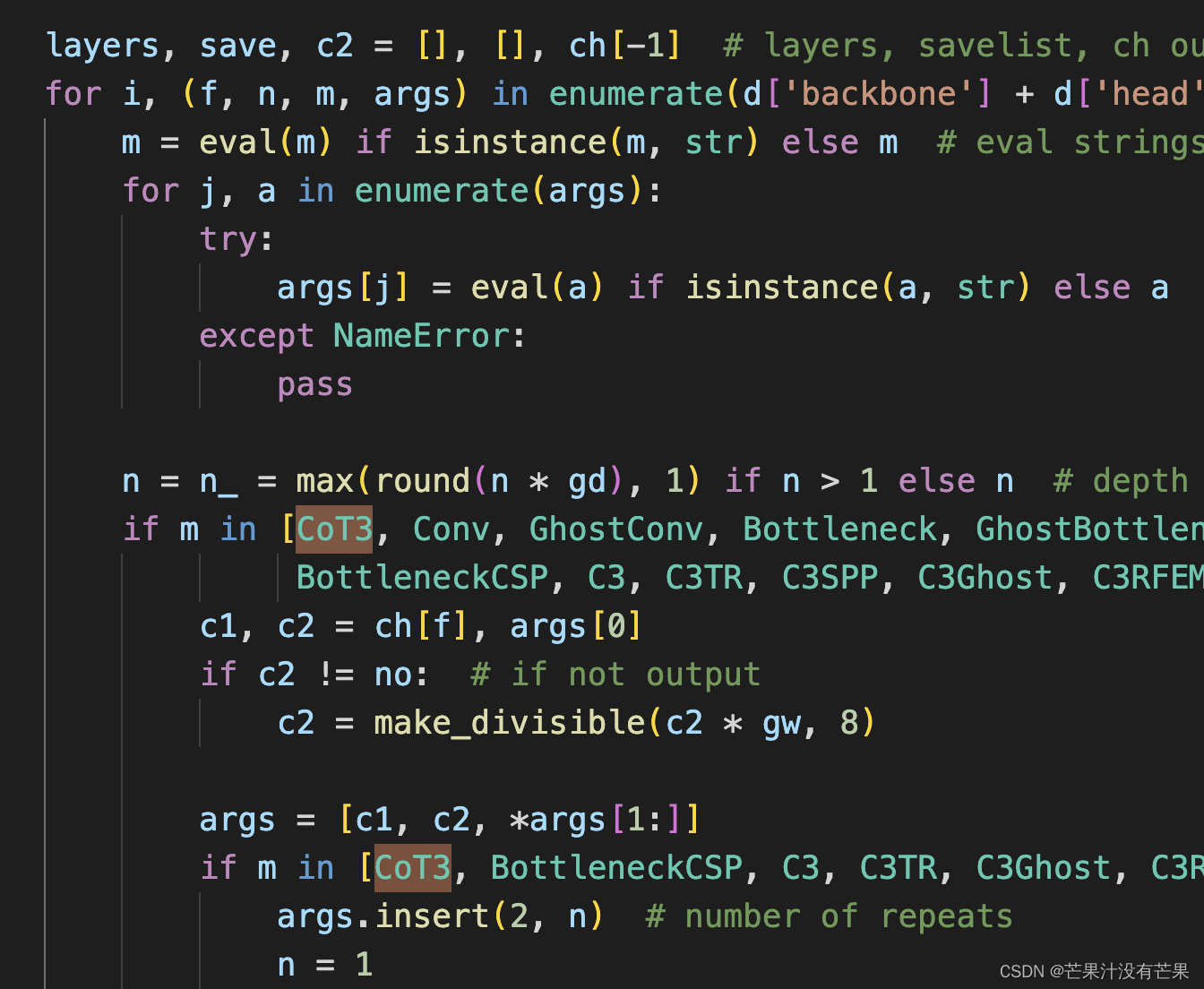
然后找到./models/yolo.py文件下里的parse_model函数,将加入的模块名CoT3加入进去
在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要增加
MobileOne模块
参考示意图
训练yolov5s_cotnet.yaml模型
python train.py --cfg yolov5s_cotnet.yaml
基于以上yolov5s_cotnet.yaml文件继续修改
关于yolov5s_cotnet.yaml文件配置中的CoT3模块里面的self-attention模块,可以针对不同数据集自行再进行模块修改,原理一致