Hive解决数据倾斜的各种优化方法
一、概念
数据处理中的数据倾斜:个人理解,在数据处理的MapReduce程序中,由于数据的特殊性,数据中存在大量相同key的数据,根据业务需求需要对这个key进行分区操作(group by/join)时,在map的partition阶段将大数据量的相同key的数据全部分配到同一个Reduce,导致Reduce的节点数据量分配极度不均衡的现象,称为数据倾斜。
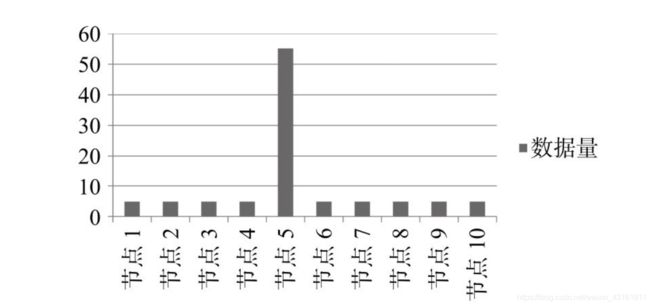
数据倾斜有哪些表现:
- 最直观的表现就是:Hive SQL运行得慢
- 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成,因为其处理的数据量和其他reduce差异过大。
- 单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多,最长时长远大于平均时长。
数据倾斜的原因:
- key分布不均匀
- 业务数据本身的特性
- 建表时考虑不周
- 某些SQL语句本身就有数据倾斜
二、数据倾斜优化方法分类
在实际Hive SQL开发的过程中,Hive SQL性能的问题上实际只有一小部分和数据倾斜相关。很多时候,Hive SQL运行得慢是由开发人员对于使用的数据了解不够以及一些不良的使用习惯引起的,我们可以确定一些关键点,看看是否能通过业务层面来避免写这中运行的特别慢的 hive sql,比如使用公共汇总层的数据代替公共明细层的数据。除此之外就需要真正的Hive优化技术了。
所以个人将优化方法分为以下三大类:
- 业务优化
- join无关的优化
- group by 引起的数据倾斜优化
- count distinct 优化
- join相关的优化
- mapjoin可以解决的join优化(即大表join小表)
- mapjoin无法解决的join优化(即大表join大表)
三、具体的优化方法
1.业务优化
很多时候,Hive SQL运行得慢是由开发人员对于使用的数据了解不够以及一些不良的使用习惯引起的。
开发人员需要确定以下几点。
- 需要计算的指标真的需要从数据仓库的公共明细层来自行汇总么?是不是数据公共层团队开发的公共汇总层已经可以满足自己的需求?对于大众的、KPI相关的指标等通常设计良好的数据仓库公共层肯定已经包含了,直接使用即可。
- 真的需要扫描这么多分区么?比如对于销售明细事务表来说,扫描一年的分区和扫描一周的分区所带来的计算、IO开销完全是两个量级,所耗费的时间肯定也是不同的。笔者并不是说不能扫描一年的分区,而是希望开发人员需要仔细考虑业务需求,尽量不浪费计算和存储资源,毕竟大数据也不是毫无代价的。
- 尽量不要使用select * from your_table这样的方式,用到哪些列就指定哪些列,如select col1, col2 from your_table。另外,where条件中也尽量添加过滤条件,以去掉无关的数据行,从而减少整个MapReduce任务中需要处理、分发的数据量。
- 输入文件不要是大量的小文件。Hive的默认Input Split是128MB(可配置),小文件可先合并成大文件。
在保证了上述几点之后,有的时候发现Hive SQL还是要运行很长时间,甚至运行不出来,这时就需要真正的Hive优化技术了。
2.join无关的优化
Hive SQL性能问题基本上大部分都和join相关,对于和join无关的问题主要有group by相关的倾斜和count distinct相关的优化。
1)group by 引起的数据倾斜优化
group by引起的倾斜主要是输入数据行按照group by列分布不均匀引起的。
比如,有个key值有100W个a,此时直接做分组的话,这100W个a将会分到同一个reduce中,这一个节点处理的数据远大于其他节点处理的数据,造成数据倾斜,跑不出数据。其原因就是有大量的key集中分配到了同一个reduce,那么我们的解决思路就是将这些key值打散,使起分散到多个reduce节点处理即可,达到负载均衡的效果。
实现原理:
在做group by 之前,我们给key=hello的数据做一次转换(加上0-9的随机数的前缀),变成0-hello,1-hello,2-hello...,此时做group by,数据将分散到多个reduce,然后再在上层查询中,将我们添加的随机数前缀去掉,使其变回a再做一次全局聚合即可,(对于大量不可删除的key值处理也是这个原理)。
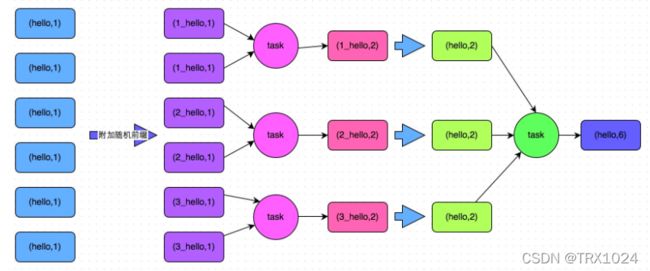
SQL实现方式伪代码:
-- 假设有表 tb_name(key_col,cnt)且已知由key_col=hello 造成数据倾斜
-- 原查询
select key_col,sum(cnt) as cnt from tb_name group by key_col;
-- 优化后
select
case when key_col like "%hello" then (伪代码:去除前缀) else key_col end as key_col,
sum(cnt) as cnt
from (
select
key_col,
sum(cnt) as cnt
from (
select
case when key_col="hello" then concat_ws("-",rand(),key_col) else key_col end as key_col,
cnt
from tb_name
) a
group by key_col
) res
group by case when key_col like "%hello" then (伪代码:去除前缀) else key_col end这样看起来操作会比较麻烦,有没有更简单的方法呢?其实Hive已经做了优化,我们只需要配置几个参数就行了。
对于group by引起的倾斜,优化措施非常简单,只需设置下面参数即可:
set hive.map.aggr = true
set hive.groupby.skewindata = true此时Hive在数据倾斜的时候会进行负载均衡,生成的查询计划会有两个MapReduce Job。
第一个MapReduce Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作并输出结果,这样处理的结果是相同的GroupBy Key有可能被分布到不同的Reduce中,从而达到负载均衡的目的;
第二个MapReduce Job 再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
2)count distinct优化
在Hive开发过程中,应该小心使用count distinct,因为很容易引起性能问题,比如下面的SQL:
select count(distinct user) from some_table;由于必须去重,因此Hive将会把Map阶段的输出全部分布到一个Reduce Task上,此时很容易引起性能问题。
对于这种情况,可以通过先group by再count的方式来优化,优化后的SQL如下
select count(*)
from
(select user from some_table group by user) a; 其原理为:利用group by去重,再统计group by的行数目(不过这种方式需要注意数据倾斜的问题)。
3.join相关的优化
1)mapjoin可以解决的join优化(即大表join小表)
背景:通常情况下,JOIN操作在Reduce阶段执行表连接。整个JOIN过程包含Map、Shuffle、Reduce三个阶段。MAPJOIN在Map阶段执行表连接,而非等到Reduce阶段才执行表连接。这样就节省了大量数据传输的时间以及系统资源,从而起到了优化作业的作用。在大表和一个或多个小表JOIN的场景下,MAPJOIN会将您指定的小表全部加载到执行JOIN操作的程序的内存中,因此指定的表仅能为小表。
以销售明细事实表为例来说明大表join小表的场景。
假如供应商会进行评级,比如(五星、四星、三星、两星、一星),此时业务人员希望能够分析各供应商星级的每天销售情况及其占比。
开发人员一般会写出如下SQL:
select
seller_star,
count(order_id) as order_cnt
from
(select order_id,seller_id from detail_table where dt=20210119) a
left join
(select seller_id,seller_star from dim_seller where dt=20210119) b
on a.seller_id = b.seller_id
group by b.seller_star但正如上述所言,现实世界的二八准则将导致订单集中在部分供应商上,而好的供应商的评级通常会更高,此时更加剧了数据倾斜的程度,如果不加以优化,上述SQL将会耗费很长时间,甚至运行不出结果。通常来说,供应商是有限的,比如上千家、上万家,数据量不会很大,而销售明细事实表比较大,这就是典型的大表join小表问题,可以通过mapjoin的方式来优化,只需添加mapjoin hint即可,优化后的SQL如下:
select /*+mapjoin(b)*/
seller_star,
count(order_id) as order_cnt
from
(select order_id,seller_id from detail_table where dt=20210119) a
left join
(select seller_id,seller_star from dim_seller where dt=20210119) b
on a.seller_id = b.seller_id
group by b.seller_star/*+mapjoin(b)*/即mapjoin hint,如果需要mapjoin多个表,则格式为/*+mapjoin(b, c, d)*/。Hive对于mapjoin是默认开启的,设置参数为:
set hive.auto.convert.join=true;mapjoin优化是在Map阶段进行join,而不是像通常那样在Reduce阶段按照join列进行分发后在每个Reduce任务节点上进行join,不需要分发也就没有倾斜的问题,相反Hive会将小表全量复制到每个Map任务节点(对于本例是dim_seller表,当然仅全量复制b表sql指定的列),然后每个Map任务节点执行lookup小表即可。
所以,小表不能太大,否则全量复制分发得不偿失,那么多小的表算作小表呢?这就涉及到一个阈值划分的问题,hive中通过参数hive.mapjoin.smalltable.filesize(版本不同,相应的参数不同)来确定小表的大小是否满足条件(默认25MB),实际中可以根据集群情况调整,但是一般最大不能超过1GB(太大的话Map任务所在的节点内存会撑爆,Hive会报错。另外需要注意的是,HDFS显示的文件大小是压缩后的大小,当实际加载到内存的时候,容量会增大很多,很多场景下可能会膨胀10倍)。
使用注意事项:
- 老版本的hive在join时,会要求将小表放在join的左边来触发mapjoin,但新版本的hive已经做了优化,小表在左在右已经没有区别了,可以使用explain打印出执行计划查看。
- 执行join操作,hive会自动对参与join的key做空值过滤,打印执行计划会有 " key(参与join的key字段) is not null "的操作。但非inner join的其他join操作不会做过滤。
2)mapjoin无法解决的join优化(即大表join大表)
有时 join 超时是因为某些 key 对应的数据太多,而相同 key 对应的数据都会发送到相同
的 reducer 上,从而导致内存不够。
a.空 key 过滤
此时我们应该仔细分析这些异常的 key,很多情况下,这些 key 对应的数据是异常数据,我们需要在 SQL 语句中进行过滤。如果 key 对应的字段为空,且是异常数据,应该在join前直接过滤掉。
实例:
-- 不过滤空 id
select n.* from tb_name n left join bigtable o on n.id = o.id;
-- 过滤空 id
select
n.*
from (
select
*
from tb_name
where id is not null
) n
left join bigtable o on n.id = o.id;适用场景:
- 非inner join
- 结果中,参与join的字段不需要null的情况
b.空 key 转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上(这里的处理方式其实跟前面的group by的优化类似,这做空 key 转换的优化演示)。
-- 空 key 转换前
select n.* from nullidtable n left join bigtable b on n.id = b.id;
-- 空 key 转换后
select n.* from nullidtable n full join bigtable o on
nvl(n.id,rand()) = o.id;