Tomcat 源码解析一初识
为什么我想研究Tomcat源码,我们现在都用的是SpringBoot开发项目,而SpringBoot对错Tomcat集成,导致现在基本上看不到Tomcat的身影了,但是Tomcat不存在吗?只要我们用Java开发Web项目,而它又无处不在,我看了《Tomcat内核设计剖析》 , 《Tomcat与Java Web开发技术详解(第3版)》,《How Tomcat Works 》,都让我觉得意由未尽, 你说他不好嘛,其实理论也讲得非常好了,你说他好嘛,感觉意由未尽,看完之后,过几天后,感觉又忘记了, 《How Tomcat Works 》这本书呢?也非常好,让你知道Tomcat 中的代码为什么这样写,就是版本老了一些,因为我们基本上用的都是Tomcat7 以上了,而这本书讲的是Tomcat4 ,Tomcat5 相关的东西,感觉他讲的和Tomcat 7 ,8 源码中的对应不上,我个人最喜欢的还是《Spring源码深度解析》这本书的写作方式,通过举例子,再深入源码研究, 这本书我觉得即使有不足之处,但也不影响我对这本书的喜欢,为什么我说有不足之处呢?因为在讲Bean的扫描的时候,他只讲了传统的xml解析并读取的方式,这作为写作来说,肯定是很好写的,因为其中用了大量的设置模式,但并不实用,我们现在都是基于注解的方式去注册Bean,在《Spring源码深度解析》书中并没有讲解到,但是如果要讲注解注册Bean,一定要去理解ASM的实现机制,去理解字节码的结构,才能理解这些注解是怎样读取出来的,其中代码中用了大量的递归,源码分析想通过书面清晰准确的表达出来还是非常不容易的,可能也是我对《Spring源码深度解析》这本书的一些遗憾的地方吧,但是这本书的写作方式,确实我再喜欢不过,今天我们分析Tomcat源码,也用这种方式来分析,希望你有所收获 。
1. Tomcat 的启动与关闭
我们在服务器环境下启动tomcat的情况比较多,因此,我们就分析linux环境下tomcat 的启动脚本和关闭脚本
tomcat 的启动,我们用两种方式,第一种方式,直接运行startup脚本,在看脚本之前,我们先了解一下下面的 参数在脚本中的含义。
- -a : 如果 file 存在则为真。
- -b : 如果 file 存在且是一个块特殊文件则为真。
- -c : 如果 file 存在且是一个字特殊文件则为真。
- -d : filename 如果filename为目录,则为真
- -e : filename 如果filename存在,则为真
- -f : filename 如果filename为常规文件,则为真
- -g : 如果 file 存在且已经设置了SGID则为真。
- -h : filename 如果文件是软链接,则为真
- -k : 如果 file 存在且已经设置了粘制位则为真。
- -n : “STRING” 的长度为非零
- -p : 如果 file 存在且是一个名字管道(F如果O)则为真。
- -o OPTIONNAME : 如果 shell选项 “OPTIONNAME” 开启则为真。
- -r : filename 如果 filename 可读,则为真
- -s : filename r如果文件长度不为0,则为真
- -t : 如果文件描述符 FD 打开且指向一个终端则为真。
- -u : 如果 file 存在且设置了SUID (set user ID)则为真。
- -w : filename 如果 filename 可写,则为真
- -x : filename 如果 filename 可执行,则为真
- -z : “STRING” 的长度为零则为真。
- -L : filename 如果 filename 为符号链接 ,则为真
- -O : 如果 file 存在且属有效用户ID则为真。
- -G : 如果 file 存在且属有效用户组则为真。
- -N : 如果 file 存在 and has been mod如果ied since it was last read则为真。
- -S : 如果 FILE 存在且是一个套接字则为真。
- -eq 等于
- -ne 不等于
- -gt 大于
- -ge 大于等于
- -lt 小于
- -le 小于等于
- [ FILE1 -nt FILE2 ] : filename1 -nt filename2 如果filename1 比filename2 新,则为真
- [ FILE1 -ot FILE2 ] : filename1 -ot filename2 如果filename1 比filename2 旧,则为真
- [ FILE1 -ef FILE2 ]: 如果 FILE1 和 FILE2 指向相同的设备和节点号则为真。
- [ -n STRING ] or [ STRING ] “STRING” 的长度为非零 non-zero则为真。
- [ STRING1 == STRING2 ] 如果2个字符串相同。 “=” may be used instead of “==” for strict POSIX compliance则为真。
- [ STRING1 != STRING2 ] 如果字符串不相等则为真。
- [ STRING1 < STRING2 ] 如果 “STRING1” sorts before “STRING2” lexicographically in the current locale则为真。
- [ STRING1 > STRING2 ] 如果 “STRING1” sorts after “STRING2” lexicographically in the current locale则为真。
- $$ : Shell本身的PID(ProcessID),对于 Shell 脚本,就是这些脚本所在的进程 ID。
- $!:Shell最后运行的后台Process的PID
- $?:最后运行的命令的结束代码(返回值),上个命令的退出状态,或函数的返回值
- $-:使用Set命令设定的Flag一览
- $:所有参数列表。如"$“用「”」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
- $@:所有参数列表。如"$@“用「”」括起来的情况、以"$1" “ 2 " … " 2" … " 2"…"n” 的形式输出所有参数。传给脚本的所有参数的列表
- $#:是传给脚本的参数个数
- $0:脚本本身的名字
- $0~$n:添加到Shell的各参数值。$1是第1参数、$2是第2参数…。
先来看startup.sh 脚本
os400=false
case "`uname`" in # 当前操作系统是不是os400开头的,如果是,则将os400变量设置为true
OS400*) os400=true;;
esac
# resolve links - $0 may be a softlink
# 如果startup 后面不接任何参数,PRG = startup.sh文件名
PRG="$0"
# 判断startup.sh 文件是不是软链接,如果是软链接,则递归找到真实的文件名
while [ -h "$PRG" ] ; do
ls=`ls -ld "$PRG"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '/.*' > /dev/null; then
PRG="$link"
else
# dirname 命名的作用是获取文件的目录,如dirname /a/b/c.txt ,则结果为/a/b
PRG=`dirname "$PRG"`/"$link"
fi
done
// 如果 $PRG startup.sh,则dirname "$PRG"命令结果为startup.sh文件所在目录
PRGDIR=`dirname "$PRG"`
EXECUTABLE=catalina.sh
# Check that target executable exists
if $os400; then
# -x will Only work on the os400 if the files are:
# 1. owned by the user
# 2. owned by the PRIMARY group of the user
# this will not work if the user belongs in secondary groups
eval
else
# 检查catalina.sh文件是否存在,并且可执行,如果不可执行,或不存在,则打印提示
if [ ! -x "$PRGDIR"/"$EXECUTABLE" ]; then
echo "Cannot find $PRGDIR/$EXECUTABLE"
echo "The file is absent or does not have execute permission"
echo "This file is needed to run this program"
exit 1
fi
fi
# 执行tomcat_home/bin/catalina.sh start "$@" 命令
exec "$PRGDIR"/"$EXECUTABLE" start "$@"
其实上面的代码看上去很麻烦,但理解也还是很简单的,先看当前startup.sh 是不是一个软链接,如果是软链接,则直到其真实文件路径,在startup.sh文件相同的目录下,肯定有一个catalina.sh,如果catalina.sh文件存在并且可执行,则执行catalina.sh start 命令。
既然将文件执行指向了catalina.sh,那我们就进入catalina.sh文件中,看做了哪些事情 。
cygwin=false
darwin=false
os400=false
hpux=false
# 显示系统内核名称,如果以HP-UX开头,则hpux为true
case "`uname`" in
CYGWIN*) cygwin=true;;
Darwin*) darwin=true;;
OS400*) os400=true;;
HP-UX*) hpux=true;;
esac
# resolve links - $0 may be a softlink
# 如果catalina.sh是软链接文件,找到其真实文件
PRG="$0"
while [ -h "$PRG" ]; do
ls=`ls -ld "$PRG"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '/.*' > /dev/null; then
PRG="$link"
else
PRG=`dirname "$PRG"`/"$link"
fi
done
# Get standard environment variables
# 获得catalina.sh文件所在目录
PRGDIR=`dirname "$PRG"`
# Only set CATALINA_HOME if not already set
# 如果CATALINA_HOME的长度为0,则设置catalina.sh文件所在目录为CATALINA_HOME
[ -z "$CATALINA_HOME" ] && CATALINA_HOME=`cd "$PRGDIR/.." >/dev/null; pwd`
# Copy CATALINA_BASE from CATALINA_HOME if not already set ,
#如果 CATALINA_BASE长度为0,则设置CATALINA_BASE为CATALINA_HOME
[ -z "$CATALINA_BASE" ] && CATALINA_BASE="$CATALINA_HOME"
# Ensure that any user defined CLASSPATH variables are not used on startup,
# but allow them to be specified in setenv.sh, in rare case when it is needed.
CLASSPATH=
# 如果$CATALINA_BASE/bin/setenv.sh 文件可读,则执行$CATALINA_BASE/bin/setenv.sh
if [ -r "$CATALINA_BASE/bin/setenv.sh" ]; then
. "$CATALINA_BASE/bin/setenv.sh"
# 否则$CATALINA_HOME/bin/setenv.sh为可读文件,则执行它
elif [ -r "$CATALINA_HOME/bin/setenv.sh" ]; then
. "$CATALINA_HOME/bin/setenv.sh"
fi
# For Cygwin, ensure paths are in UNIX format before anything is touched
if $cygwin; then
[ -n "$JAVA_HOME" ] && JAVA_HOME=`cygpath --unix "$JAVA_HOME"`
[ -n "$JRE_HOME" ] && JRE_HOME=`cygpath --unix "$JRE_HOME"`
[ -n "$CATALINA_HOME" ] && CATALINA_HOME=`cygpath --unix "$CATALINA_HOME"`
[ -n "$CATALINA_BASE" ] && CATALINA_BASE=`cygpath --unix "$CATALINA_BASE"`
[ -n "$CLASSPATH" ] && CLASSPATH=`cygpath --path --unix "$CLASSPATH"`
fi
# Ensure that neither CATALINA_HOME nor CATALINA_BASE contains a colon
# as this is used as the separator in the classpath and Java provides no
# mechanism for escaping if the same character appears in the path.
case $CATALINA_HOME in
*:*) echo "Using CATALINA_HOME: $CATALINA_HOME";
echo "Unable to start as CATALINA_HOME contains a colon (:) character";
exit 1;
esac
case $CATALINA_BASE in
*:*) echo "Using CATALINA_BASE: $CATALINA_BASE";
echo "Unable to start as CATALINA_BASE contains a colon (:) character";
exit 1;
esac
#如果CATALINA_HOME或CATALINA_BASE路径中有冒号,则给出提示并退出
# For OS400
if $os400; then
# Set job priority to standard for interactive (interactive - 6) by using
# the interactive priority - 6, the helper threads that respond to requests
# will be running at the same priority as interactive jobs.
COMMAND='chgjob job('$JOBNAME') runpty(6)'
system $COMMAND
# Enable multi threading
export QIBM_MULTI_THREADED=Y
fi
# Get standard Java environment variables
if $os400; then
# -r will Only work on the os400 if the files are:
# 1. owned by the user
# 2. owned by the PRIMARY group of the user
# this will not work if the user belongs in secondary groups
. "$CATALINA_HOME"/bin/setclasspath.sh
else
# 调用setclasspath脚本,设置JAVA_HOME,JRE_HOME,JAVA_PATH,JAVA_ENDORSED_DIRS,_RUNJAVA等
if [ -r "$CATALINA_HOME"/bin/setclasspath.sh ]; then
. "$CATALINA_HOME"/bin/setclasspath.sh
else
如果没有setclasspath.sh,则打印提示
echo "Cannot find $CATALINA_HOME/bin/setclasspath.sh"
echo "This file is needed to run this program"
exit 1
fi
fi
# Add on extra jar files to CLASSPATH
if [ ! -z "$CLASSPATH" ] ; then
CLASSPATH="$CLASSPATH":
fi
# 重新设置classpath
CLASSPATH="$CLASSPATH""$CATALINA_HOME"/bin/bootstrap.jar
# 设置日志输出文件
if [ -z "$CATALINA_OUT" ] ; then
CATALINA_OUT="$CATALINA_BASE"/logs/catalina.out
fi
# 设置临时目录
if [ -z "$CATALINA_TMPDIR" ] ; then
# Define the java.io.tmpdir to use for Catalina
CATALINA_TMPDIR="$CATALINA_BASE"/temp
fi
# Add tomcat-juli.jar to classpath
# tomcat-juli.jar can be over-ridden per instance
# CATALINA_BASE/bin/tomcat-juli.jar可读,则加入到classpath中
if [ -r "$CATALINA_BASE/bin/tomcat-juli.jar" ] ; then
CLASSPATH=$CLASSPATH:$CATALINA_BASE/bin/tomcat-juli.jar
else
CLASSPATH=$CLASSPATH:$CATALINA_HOME/bin/tomcat-juli.jar
fi
# Bugzilla 37848: When no TTY is available, don't output to console
have_tty=0
if [ -t 0 ]; then
have_tty=1
fi
# For Cygwin, switch paths to Windows format before running java
if $cygwin; then
JAVA_HOME=`cygpath --absolute --windows "$JAVA_HOME"`
JRE_HOME=`cygpath --absolute --windows "$JRE_HOME"`
CATALINA_HOME=`cygpath --absolute --windows "$CATALINA_HOME"`
CATALINA_BASE=`cygpath --absolute --windows "$CATALINA_BASE"`
CATALINA_TMPDIR=`cygpath --absolute --windows "$CATALINA_TMPDIR"`
CLASSPATH=`cygpath --path --windows "$CLASSPATH"`
[ -n "$JAVA_ENDORSED_DIRS" ] && JAVA_ENDORSED_DIRS=`cygpath --path --windows "$JAVA_ENDORSED_DIRS"`
fi
if [ -z "$JSSE_OPTS" ] ; then
JSSE_OPTS="-Djdk.tls.ephemeralDHKeySize=2048"
fi
# 设置JAVA_OPTS
JAVA_OPTS="$JAVA_OPTS $JSSE_OPTS"
# Set juli LogManager config file if it is present and an override has not been issued
# 如果日志文件没有配置,并且 CATALINA_BASE/conf/logging.properties可读,则
# 设置java.util.logging.config.file为CATALINA_BASE/conf/logging.properties
if [ -z "$LOGGING_CONFIG" ]; then
if [ -r "$CATALINA_BASE"/conf/logging.properties ]; then
LOGGING_CONFIG="-Djava.util.logging.config.file=$CATALINA_BASE/conf/logging.properties"
else
# Bugzilla 45585
LOGGING_CONFIG="-Dnop"
fi
fi
# 设置日志管理器
if [ -z "$LOGGING_MANAGER" ]; then
LOGGING_MANAGER="-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager"
fi
# Set UMASK unless it has been overridden
# 掩码默认为0027 ,掩码和chmod是相反的
# umask 命令允许你设定文件创建时的缺省模式,对应每一类用户(文件属主、同组用户、其他用户)存在一个
# 相应的umask值中的数字。对于文件来说,这一数字的最 大值分别是6。系统不允
# 许你在创建一个文本文件时就赋予它执行权限,必须在创建后用chmod命令增加这
# 一权限。目录则允许设置执行权限,这样针对目录来 说,umask中各个数字最大可以到7。
# 该命令的一般形式为:
# umask nnn
# 其中nnn为umask置000-777。
# 如 其中umask值为002:
# 文件的最大权限 rwx rwx rwx (777)
# umask值为002 --- --- -w-
# 目录权限 rwx rwx r-x (775) 这就是目录创建缺省权限
# 文件权限 rw- rw- r-- (664) 这就是文件创建缺省权限
if [ -z "$UMASK" ]; then
UMASK="0027"
fi
umask $UMASK
# Java 9 no longer supports the java.endorsed.dirs
# system property. Only try to use it if
# JAVA_ENDORSED_DIRS was explicitly set
# or CATALINA_HOME/endorsed exists.
ENDORSED_PROP=ignore.endorsed.dirs
if [ -n "$JAVA_ENDORSED_DIRS" ]; then
ENDORSED_PROP=java.endorsed.dirs
fi
if [ -d "$CATALINA_HOME/endorsed" ]; then
ENDORSED_PROP=java.endorsed.dirs
fi
# Make the umask available when using the org.apache.catalina.security.SecurityListener
JAVA_OPTS="$JAVA_OPTS -Dorg.apache.catalina.security.SecurityListener.UMASK=`umask`"
Tomcat 是否后台启动
if [ -z "$USE_NOHUP" ]; then
if $hpux; then
USE_NOHUP="true"
else
USE_NOHUP="false"
fi
fi
unset _NOHUP
if [ "$USE_NOHUP" = "true" ]; then
_NOHUP="nohup"
fi
# Add the JAVA 9 specific start-up parameters required by Tomcat
JDK_JAVA_OPTIONS="$JDK_JAVA_OPTIONS --add-opens=java.base/java.lang=ALL-UNNAMED"
JDK_JAVA_OPTIONS="$JDK_JAVA_OPTIONS --add-opens=java.base/java.io=ALL-UNNAMED"
JDK_JAVA_OPTIONS="$JDK_JAVA_OPTIONS --add-opens=java.rmi/sun.rmi.transport=ALL-UNNAMED"
export JDK_JAVA_OPTIONS
# ----- Execute The Requested Command -----------------------------------------
# Bugzilla 37848: only output this if we have a TTY
if [ $have_tty -eq 1 ]; then
echo "Using CATALINA_BASE: $CATALINA_BASE"
echo "Using CATALINA_HOME: $CATALINA_HOME"
echo "Using CATALINA_TMPDIR: $CATALINA_TMPDIR"
if [ "$1" = "debug" ] ; then
echo "Using JAVA_HOME: $JAVA_HOME"
else
echo "Using JRE_HOME: $JRE_HOME"
fi
echo "Using CLASSPATH: $CLASSPATH"
if [ ! -z "$CATALINA_PID" ]; then
echo "Using CATALINA_PID: $CATALINA_PID"
fi
fi
if [ "$1" = "jpda" ] ; then
if [ -z "$JPDA_TRANSPORT" ]; then
JPDA_TRANSPORT="dt_socket"
fi
if [ -z "$JPDA_ADDRESS" ]; then
JPDA_ADDRESS="localhost:8000"
fi
if [ -z "$JPDA_SUSPEND" ]; then
JPDA_SUSPEND="n"
fi
if [ -z "$JPDA_OPTS" ]; then
JPDA_OPTS="-agentlib:jdwp=transport=$JPDA_TRANSPORT,address=$JPDA_ADDRESS,server=y,suspend=$JPDA_SUSPEND"
fi
CATALINA_OPTS="$JPDA_OPTS $CATALINA_OPTS"
shift
fi
if [ "$1" = "debug" ] ; then
if $os400; then
echo "Debug command not available on OS400"
exit 1
else
shift
if [ "$1" = "-security" ] ; then
if [ $have_tty -eq 1 ]; then
echo "Using Security Manager"
fi
shift
exec "$_RUNJDB" "$LOGGING_CONFIG" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-D$ENDORSED_PROP="$JAVA_ENDORSED_DIRS" \
-classpath "$CLASSPATH" \
-sourcepath "$CATALINA_HOME"/../../java \
-Djava.security.manager \
-Djava.security.policy=="$CATALINA_BASE"/conf/catalina.policy \
-Dcatalina.base="$CATALINA_BASE" \
-Dcatalina.home="$CATALINA_HOME" \
-Djava.io.tmpdir="$CATALINA_TMPDIR" \
org.apache.catalina.startup.Bootstrap "$@" start
else
exec "$_RUNJDB" "$LOGGING_CONFIG" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-D$ENDORSED_PROP="$JAVA_ENDORSED_DIRS" \
-classpath "$CLASSPATH" \
-sourcepath "$CATALINA_HOME"/../../java \
-Dcatalina.base="$CATALINA_BASE" \
-Dcatalina.home="$CATALINA_HOME" \
-Djava.io.tmpdir="$CATALINA_TMPDIR" \
org.apache.catalina.startup.Bootstrap "$@" start
fi
fi
elif [ "$1" = "run" ]; then
shift
if [ "$1" = "-security" ] ; then
if [ $have_tty -eq 1 ]; then
echo "Using Security Manager"
fi
shift
eval exec "\"$_RUNJAVA\"" "\"$LOGGING_CONFIG\"" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-D$ENDORSED_PROP="\"$JAVA_ENDORSED_DIRS\"" \
-classpath "\"$CLASSPATH\"" \
-Djava.security.manager \
-Djava.security.policy=="\"$CATALINA_BASE/conf/catalina.policy\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap "$@" start
else
eval exec "\"$_RUNJAVA\"" "\"$LOGGING_CONFIG\"" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-D$ENDORSED_PROP="\"$JAVA_ENDORSED_DIRS\"" \
-classpath "\"$CLASSPATH\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap "$@" start
fi
# 如果catalina.sh后面的第一个参数是start ,则进入下面代码
elif [ "$1" = "start" ] ; then
if [ ! -z "$CATALINA_PID" ]; then #
if [ -f "$CATALINA_PID" ]; then
if [ -s "$CATALINA_PID" ]; then
# 如果CATALINA_PID不为空,并且CATALINA_PID是一个常规文件,并且文件长度不为0
echo "Existing PID file found during start."
# 如果CATALINA_PID文件可读
if [ -r "$CATALINA_PID" ]; then
# 读取CATALINA_PID文件的内容
PID=`cat "$CATALINA_PID"`
ps -p $PID >/dev/null 2>&1
# 如果在启动过程中发现pid文件存在,并且pid对应的进程还是启动的,
# 则打印出pid进行对应的相关信息,提示用户去删除pid相关文件
if [ $? -eq 0 ] ; then
echo "Tomcat appears to still be running with PID $PID. Start aborted."
echo "If the following process is not a Tomcat process, remove the PID file and try again:"
ps -f -p $PID
exit 1
else
# 如果CATALINA_PID文件中记录的pid对应的进程不存在了,则直接删除CATALINA_PID文件
echo "Removing/clearing stale PID file."
rm -f "$CATALINA_PID" >/dev/null 2>&1
# $?上一个命令的返回值,1 表示执行失败,0 表示执行成功
if [ $? != 0 ]; then
# 如果删除文件失败,则看CATALINA_PID文件是否可写,如果可写,则清空掉CATALINA_PID文件的内容
if [ -w "$CATALINA_PID" ]; then
cat /dev/null > "$CATALINA_PID"
else
# 如果CATALINA_PID既不能删除,也不能写,则提示下面内容
echo "Unable to remove or clear stale PID file. Start aborted."
exit 1
fi
fi
fi
else
# 如果CATALINA_PID文件不能读,则提示下面内容
echo "Unable to read PID file. Start aborted."
exit 1
fi
else
# CATALINA_PID 文件长度为0 ,则直接删除掉CATALINA_PID文件即可
rm -f "$CATALINA_PID" >/dev/null 2>&1
if [ $? != 0 ]; then
# 如果CATALINA_PID文件删除失败,并且还不可写,则提示下面内容
if [ ! -w "$CATALINA_PID" ]; then
echo "Unable to remove or write to empty PID file. Start aborted."
exit 1
fi
fi
fi
fi
fi
# catalina.sh start aa bb cc dd 的第一个参数是start ,因此调用shift 指令,参数后移
# catalina.sh aa bb cc dd ,如果参数中带有-security
shift
touch "$CATALINA_OUT"
if [ "$1" = "-security" ] ; then
if [ $have_tty -eq 1 ]; then
echo "Using Security Manager"
fi
# 移除掉-security参数
shift
eval $_NOHUP "\"$_RUNJAVA\"" "\"$LOGGING_CONFIG\"" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-D$ENDORSED_PROP="\"$JAVA_ENDORSED_DIRS\"" \
-classpath "\"$CLASSPATH\"" \
-Djava.security.manager \
-Djava.security.policy=="\"$CATALINA_BASE/conf/catalina.policy\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
# 将剩下的参数作为Bootstrap类的启动参数
org.apache.catalina.startup.Bootstrap "$@" start \
>> "$CATALINA_OUT" 2>&1 "&"
else
eval $_NOHUP "\"$_RUNJAVA\"" "\"$LOGGING_CONFIG\"" $LOGGING_MANAGER $JAVA_OPTS $CATALINA_OPTS \
-D$ENDORSED_PROP="\"$JAVA_ENDORSED_DIRS\"" \
-classpath "\"$CLASSPATH\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap "$@" start \
>> "$CATALINA_OUT" 2>&1 "&"
fi
# 将上述执行结果pid 存入到CATALINA_PID文件中
if [ ! -z "$CATALINA_PID" ]; then
echo $! > "$CATALINA_PID"
fi
# 打印tomcat 启动成功
echo "Tomcat started."
# 如果执行的是 catalina.sh stop 命令
elif [ "$1" = "stop" ] ; then
# 将stop命令从参数中移除掉
shift
# 默认stop 尝试5秒
SLEEP=5
if [ ! -z "$1" ]; then
echo $1 | grep "[^0-9]" >/dev/null 2>&1
# 如果stop参数后是一个数字 ,则将该值设置到SLEEP 中,并且将参数下标右移1
if [ $? -gt 0 ]; then
SLEEP=$1
shift
fi
fi
# 如果输入的命令是 catalina.sh stop 5 -force 或 catalina.sh stop -force
FORCE=0
if [ "$1" = "-force" ]; then
# 参数下标右移,并且FORCE = 1
shift
FORCE=1
fi
if [ ! -z "$CATALINA_PID" ]; then
if [ -f "$CATALINA_PID" ]; then
if [ -s "$CATALINA_PID" ]; then
# 如果 CATALINA_PID 文件size大于0,并且CATALINA_PID为常规文件,
# kill -0 pid 不发送任何信号,但是系统会进行错误检查。所以经常用来检查一个进程是否存在,存在返回0;不存在返回1
# 如果pid 不存在,或者没有权限去停止,则给出下面提示
kill -0 `cat "$CATALINA_PID"` >/dev/null 2>&1
if [ $? -gt 0 ]; then
echo "PID file found but either no matching process was found or the current user does not have permission to stop the process. Stop aborted."
exit 1
fi
else
echo "PID file is empty and has been ignored."
fi
# 如果CATALINA_PID是一个特殊文件,给出下面提示
else
echo "\$CATALINA_PID was set but the specified file does not exist. Is Tomcat running? Stop aborted."
exit 1
fi
fi
# 向Bootstrap类发送stop 命令
eval "\"$_RUNJAVA\"" $LOGGING_MANAGER $JAVA_OPTS \
-D$ENDORSED_PROP="\"$JAVA_ENDORSED_DIRS\"" \
-classpath "\"$CLASSPATH\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap "$@" stop
# stop failed. Shutdown port disabled? Try a normal kill.
if [ $? != 0 ]; then
if [ ! -z "$CATALINA_PID" ]; then
# 如果停止失败,但CATALINA_PID文件存在,则给出下面提示
echo "The stop command failed. Attempting to signal the process to stop through OS signal."
# 调用kill -15 温柔的杀死进程
kill -15 `cat "$CATALINA_PID"` >/dev/null 2>&1
fi
fi
if [ ! -z "$CATALINA_PID" ]; then
if [ -f "$CATALINA_PID" ]; then
while [ $SLEEP -ge 0 ]; do
# 如果睡眠时间大于0,并且CATALINA_PID的文件大小大于零,并且是一个常规文件
kill -0 `cat "$CATALINA_PID"` >/dev/null 2>&1
# 如果$? > 0,则 CATALINA_PID文件内的进程id ,目前不存在
if [ $? -gt 0 ]; then
# 因为pid进程已经不存在了,尝试删除CATALINA_PID文件
rm -f "$CATALINA_PID" >/dev/null 2>&1
if [ $? != 0 ]; then
# 如果删除CATALINA_PID文件失败,而CATALINA_PID文件有写权限,则
if [ -w "$CATALINA_PID" ]; then
# 将空字符串写入到CATALINA_PID文件中
cat /dev/null > "$CATALINA_PID"
# If Tomcat has stopped don't try and force a stop with an empty PID file
FORCE=0
else
# 如果CATALINA_PID文件是不可写的,则给出下面提示
echo "The PID file could not be removed or cleared."
fi
fi
# 只要pid进程在系统中不存在,则一定会打印出tomcat 已经停止,并且退出循环
echo "Tomcat stopped."
break
fi
# 如果睡眠时间大于0 ,则先睡眠一秒
if [ $SLEEP -gt 0 ]; then
sleep 1
fi
# SLEEP默认值是5,如果SLEEP仍然大于0
if [ $SLEEP -eq 0 ]; then
echo "Tomcat did not stop in time."
if [ $FORCE -eq 0 ]; then
echo "PID file was not removed."
fi
echo "To aid diagnostics a thread dump has been written to standard out."
# kill -3可以打印进程各个线程的堆栈信息,kill -3 pid 后文件的保存路径为:/proc/${pid}/cwd,文件名为:antBuilderOutput.log
# 如果是让进程自己执行退出离场程序就使用 kill 命令,这样进程可以自己执行一些清理动作然后退出。如果进程卡死,你需要记录当时的事故现场,
# 那么应该用 kill -3 来记录事故现场的信息然后退出。如果你什么也不需要,就是要杀死一个进程那么就是用 kill -9 命令,很暴力的杀死它。
kill -3 `cat "$CATALINA_PID"`
fi
# SLEEP 变量减1
SLEEP=`expr $SLEEP - 1 `
done
fi
fi
KILL_SLEEP_INTERVAL=5
if [ $FORCE -eq 1 ]; then # 如果命令中有-force
# 如果CATALINA_PID所在文件名为空,提出下面内容
if [ -z "$CATALINA_PID" ]; then
echo "Kill failed: \$CATALINA_PID not set"
else
# 如果CATALINA_PID文件是一个常规文件
if [ -f "$CATALINA_PID" ]; then
# 获取pid
PID=`cat "$CATALINA_PID"`
echo "Killing Tomcat with the PID: $PID"
# 使用kill -9 杀死pid进程
# kill -9代表的信号是SIGKILL,表示进程被终止,需要立即退出,强制杀死该进程,这个信号不能被捕获也不能被忽略
kill -9 $PID
while [ $KILL_SLEEP_INTERVAL -ge 0 ]; do
# 查看pid进程是否被杀死了,如果被杀死,则执行结果 $? == 0 ,否则 $? 大于0
kill -0 `cat "$CATALINA_PID"` >/dev/null 2>&1
if [ $? -gt 0 ]; then
# 如果pid进程已经被杀死了,则删除CATALINA_PID文件
rm -f "$CATALINA_PID" >/dev/null 2>&1
if [ $? != 0 ]; then
# 如果删除失败,并且CATALINA_PID文件是可写的,将空字符串写入到CATALINA_PID文件中
if [ -w "$CATALINA_PID" ]; then
cat /dev/null > "$CATALINA_PID"
else
# 如果CATALINA_PID文件没有写权限,则提示下面内容
echo "The PID file could not be removed."
fi
fi
# 如果被杀死了,则提示tomcat 进程已经被杀死
echo "The Tomcat process has been killed."
break
fi
# 如果KILL_SLEEP_INTERVAL变量仍然大于0,则睡眠1秒
if [ $KILL_SLEEP_INTERVAL -gt 0 ]; then
sleep 1
fi
# KILL_SLEEP_INTERVAL 变量减1 ,如果KILL_SLEEP_INTERVAL大于0,则继续循环
# 按道理kill -9 命令是能立即杀死进程的,但为什么这里要做一个循环呢?即使是立即杀死,在pid进程彻底消亡过程中
# 也是需要时间的,因此这里等了5秒钟,目的就是为了保证CATALINA_PID文件的内容被清除掉,方便下次启动
KILL_SLEEP_INTERVAL=`expr $KILL_SLEEP_INTERVAL - 1 `
done
# 如果等了5秒,进程还没有消亡,提示下面内容,需要命令调用者自己去做处理了
if [ $KILL_SLEEP_INTERVAL -lt 0 ]; then
echo "Tomcat has not been killed completely yet. The process might be waiting on some system call or might be UNINTERRUPTIBLE."
fi
fi
fi
fi
elif [ "$1" = "configtest" ] ; then
eval "\"$_RUNJAVA\"" $LOGGING_MANAGER $JAVA_OPTS \
-D$ENDORSED_PROP="\"$JAVA_ENDORSED_DIRS\"" \
-classpath "\"$CLASSPATH\"" \
-Dcatalina.base="\"$CATALINA_BASE\"" \
-Dcatalina.home="\"$CATALINA_HOME\"" \
-Djava.io.tmpdir="\"$CATALINA_TMPDIR\"" \
org.apache.catalina.startup.Bootstrap configtest
result=$?
if [ $result -ne 0 ]; then
echo "Configuration error detected!"
fi
exit $result
elif [ "$1" = "version" ] ; then
"$_RUNJAVA" \
-classpath "$CATALINA_HOME/lib/catalina.jar" \
org.apache.catalina.util.ServerInfo
else
echo "Usage: catalina.sh ( commands ... )"
echo "commands:"
if $os400; then
echo " debug Start Catalina in a debugger (not available on OS400)"
echo " debug -security Debug Catalina with a security manager (not available on OS400)"
else
echo " debug Start Catalina in a debugger"
echo " debug -security Debug Catalina with a security manager"
fi
echo " jpda start Start Catalina under JPDA debugger"
echo " run Start Catalina in the current window"
echo " run -security Start in the current window with security manager"
echo " start Start Catalina in a separate window"
echo " start -security Start in a separate window with security manager"
echo " stop Stop Catalina, waiting up to 5 seconds for the process to end"
echo " stop n Stop Catalina, waiting up to n seconds for the process to end"
echo " stop -force Stop Catalina, wait up to 5 seconds and then use kill -KILL if still running"
echo " stop n -force Stop Catalina, wait up to n seconds and then use kill -KILL if still running"
echo " configtest Run a basic syntax check on server.xml - check exit code for result"
echo " version What version of tomcat are you running?"
echo "Note: Waiting for the process to end and use of the -force option require that \$CATALINA_PID is defined"
exit 1
fi
linux ps命令详解(unix风格)
- -a 与任何用户标识和终端相关的进程
- -e 所有进程(包括守护进程)
- -p pid 与指定PID相关的进程
- -u userid 与指定用户标识userid相关的进程
- -ef 显示所有用户进程,完整输出
- -a 显示所有非守护进程
- -t 仅显示所有守护进程
我们分析了Tomcat 的start 和 stop 脚本,run命令和start大同小异,只是start命令比run 命令多考虑了CATALINA_PID文件的存在性以及文件内容pid在当前操作系统中是否存活。 但最终都是启动org.apache.catalina.startup.Bootstrap 类,并将命令行中剩余的参数作为Bootstrap类的main方法的参数传入。 当然在启动过程中考虑到-security 参数的使用,如果使用了-security参数,则在启动过程中环境变量中加入
-Djava.security.manager
-Djava.security.policy==“”$CATALINA_BASE/conf/catalina.policy""
两个参数 。
接下来,看stop 命令做的事情 , 先向org.apache.catalina.startup.Bootstrap类中传入stop 命令,如果向Bootstrap类中传入stop 参数后不生效,调用kill -15 这是告诉进程你需要被关闭,请自行停止运行并退出,进程可以清理缓存自行结束,也可以拒绝结束。之后偿试5秒钟,如果进程已经关闭了, 则清除 CATALINA_PID文件的内容,如果进程仍然没有关闭,并且在stop 命令中加了-force ,则用kill -9 命令来杀死进程,并且再次偿试5秒钟的时间去清除CATALINA_PID文件内容,如果5秒后,进程仍然没有被关闭,则提示Tomcat has not been killed completely yet. The process might be waiting on some system call or might be UNINTERRUPTIBLE.
我相信,读者读到这里,对tomcat的启动和停止脚本已经有了深入理解,读好的代码,如读唐诗宋词,意境深远,意味深长。
既然将所有的矛头都指向了Bootstrap类,那我们进入 org.apache.catalina.startup.Bootstrap类的main方法分析 。
public static void main(String args[]) {
if (daemon == null) {
// Don't set daemon until init() has completed
Bootstrap bootstrap = new Bootstrap();
try {
bootstrap.init(); // catalinaaemon
} catch (Throwable t) {
handleThrowable(t);
t.printStackTrace();
return;
}
daemon = bootstrap;
} else {
// When running as a service the call to stop will be on a new
// thread so make sure the correct class loader is used to prevent
// a range of class not found exceptions.
Thread.currentThread().setContextClassLoader(daemon.catalinaLoader);
}
try {
String command = "start";
if (args.length > 0) {
command = args[args.length - 1];
}
if (command.equals("startd")) {
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
} else if (command.equals("stopd")) {
args[args.length - 1] = "stop";
daemon.stop();
} else if (command.equals("start")) {
daemon.setAwait(true); // 设置阻塞标志
daemon.load(args); // 解析server.xml,初始化Catalina
daemon.start();
if (null == daemon.getServer()) {
System.exit(1);
}
} else if (command.equals("stop")) {
daemon.stopServer(args);
} else if (command.equals("configtest")) {
daemon.load(args);
if (null == daemon.getServer()) {
System.exit(1);
}
System.exit(0);
} else {
log.warn("Bootstrap: command \"" + command + "\" does not exist.");
}
} catch (Throwable t) {
// Unwrap the Exception for clearer error reporting
if (t instanceof InvocationTargetException &&
t.getCause() != null) {
t = t.getCause();
}
handleThrowable(t);
t.printStackTrace();
System.exit(1);
}
}
我们先来看Tomcat初始化做了哪些事情。
/**
* Initialize daemon.
* 主要初始化类加载器,在Tomcat的设计中,使用了很多自定义的类加载器,包括Tomcat自己本身的类会由CommonClassLoader来加载,每个wabapp由特定的类加载器来加载
*/
public void init()
throws Exception
{
// Set Catalina path
// catalina.home表示安装目录
// catalina.base表示工作目录
setCatalinaHome();
setCatalinaBase();
// 初始化commonLoader、catalinaLoader、sharedLoader
// 其中catalinaLoader、sharedLoader默认其实就是commonLoader
initClassLoaders();
// 设置线程的所使用的类加载器,默认情况下就是commonLoader
Thread.currentThread().setContextClassLoader(catalinaLoader);
// 如果开启了SecurityManager,那么则要提前加载一些类
SecurityClassLoad.securityClassLoad(catalinaLoader);
// Load our startup class and call its process() method
// 加载Catalina类,并生成instance
if (log.isDebugEnabled())
log.debug("Loading startup class");
Class startupClass =
catalinaLoader.loadClass
("org.apache.catalina.startup.Catalina");
Object startupInstance = startupClass.newInstance();
// Set the shared extensions class loader
// 设置Catalina实例的父级类加载器为sharedLoader(默认情况下就是commonLoader)
if (log.isDebugEnabled())
log.debug("Setting startup class properties");
String methodName = "setParentClassLoader";
Class paramTypes[] = new Class[1];
paramTypes[0] = Class.forName("java.lang.ClassLoader");
Object paramValues[] = new Object[1];
paramValues[0] = sharedLoader;
Method method =
startupInstance.getClass().getMethod(methodName, paramTypes);
method.invoke(startupInstance, paramValues);
catalinaDaemon = startupInstance;
}
我们看加粗代码的意图Thread.currentThread().setContextClassLoader(catalinaLoader);
前面提到的Tomcat 会创建Common类加载器,Catalina类加载器和共享类加载器三个类加载器供自己使用, 这三个其实是同一个类加载器对象 , Tomcat 在创建类加载器后马上将其设置成当前类加载器,即Thread.currentThread().setContextClassLoader(CatalinaLoader) , 这里主要是为了避免后面加载类时加载不成功,下面将举一个典型的例子说明如何利用URLClassLoader 加载指定Jar 包,并且解析由此引起的加载失败问题。
首先,定义一个提供服务接口,并且打包成TestInterface.jar
public interface TestInterface {
public String display();
}
其次创建一个名为TestClassLoader 的类,它的实现TestInterface.jar 包里面的TestInterface 接口,路径为com.test ,该类包含一个display方法,将这个类编译并打包成test.jar 包,放在D 盘目录下。
public class TestClassLoader implements TestInterFace{
public String display(){
return “I can load this class and execute the method .”;
}
}
最后利用URLClassLoader 加载并运行TestClassLoader 类的display方法,创建一个测试类,如下图所示 。
public class Test{
public static void main (String [] args ) throw Exception{
URL url = new URL(“file:D/test.jar”);
URLClassLoader myClassLoader = new URL(new URL[]{url});
Class myClass = myClassLoader.loadClass(“com.test.TestClassLoader”);
TestInterface testClassLoader = (TestInterface)myClass.newInstance();
System.out.println(testclassLoader.display());
}
}
测试类的main方法中首先用URLClassLoader 指定加载test.jar ,然后再将com.test.TestClassLoader 类加载到内存中,最后用newInstance 方法生成一个TestClassLoader 实例,即可调用它的display方法 。 运行这个测试类,能够达到预期的效果,输出 “I can load this class and execute the method” ,语句 ,看起来一切都那么顺其自然,但当你把TestInterface.jar 包移植到Web 应用中时,竟然抛出了java.lang.ClassNotFoundException:com.test.TestInterface异常,报错的位置正是代码中加粗的语句 , 怎么会抛出找不到的这个类异常呢?要明白为什么会报这样的错,需要搞清楚这几点 。
- 在Java 中,我们用完全匹配类名来标识一个类,即用包名和类名,而在JVM 中,一个类由完全匹配的类名和一个类加载器的实例ID 作为唯一的标识,也就是说,同一个虚拟机可以有两个包名,类名都相同的类,只要它由两个不同的类加载器加载,而在各自的类加载器中的类实例也是不同的,并且不能互相转换。
- 在类加载器加载某个类时,一般会在类中引用,继承,扩展其他类,于是类加载器查找这些引用类也是一层一层的往父类加载器中查找的,最后查看自己,如果找不到,将会报出找不到此类的错误,也就是说,只会向上查找引用类,而不会往下从子类中加载器中查找。
- 每个运行中的线程都有一个成员ContextClassLoader,用来在运行时动态的载入其他类,在没有显式的声明由哪个类加载器加载类(例如在程序中直接新建一个类)时,默认由当前线程类加载器加载,即络运行到需要加载新类时,即自己的类加载器对其进行加载 。 系统默认的ContextClassLoader是系统类加载器, 所以一般而言,Java 程序在执行时可以使用JVM 自带的类 $JAVA_HOME/jre/lib/ext中的类和$CLASSPATH/中的类。
也解了以上三点,再对前面的加载时抛出找不到类异常进行分析 。
- 当测试类运行命令时,之所以能正常的运行是因为,运行时当前线程类加载器是系统类加载器,TestInterface接口类自然由它加载,URLClassLoader 的默认父类加载器也是系统类加载器。由双亲委派机制得知,最后TestClassLoader 由系统类加载器加载,那么接口与类都由同一个类加载器加载,自然也就能找到类与接口并且进行转化。
- 当测试类转移到Web 项目中时,假如将代码移到Servlet 里面,将直接报错,指出无法运行其中运行时当前线程类加载器是WebApp类加载器,而WebApp 类加载器在交给系统类加载器试图加载无果后,自己尝试加载类, 所以TestInterface 接口由WebApp类加载加载,同样 , URLClassLoader 的父类加载器为系统类加载器,它负责加载TestClassLoader 类,于是,问题来了,两个不同的类加载器分别加载两个类, 而且WebApp 类加载器又是由系统类加载器的子孙类加载器, 因为TestClassLoader 类扩展了Interface接口,所以当URLClassLoader 加载TestClassLoader 时找不到WebApp类加载器中的TestInterface 接口类, 即抛出java.lang.ClassNotFoundException:com.test.TestInterface 异常。
针对上面的错误 , 有两种解决方法 。
即因为两个类加载器被加载而导致找不到类,那么最简单的解决方法就是使这两个类统一由一个类加载器来加载,即在加载testclassloader.jar 时用当前线程类加载器加载,只须稍微的修改代码。
URLClassLoader myClassLoader = new URLClassLoader(new URL[]{} ,Thread.currentThread().getContextClassLoader());
重点是加粗部分,即在创建URLClassLoader对象时将当前类加载器作为父类的加载器传入,WebAPP 当前线程类加载器是WebAppClassLoader ,那么当加载testclassloader.jar 时,将优先交给WebAppClassLoader 加载,这样就保证了两个类在同一个类加载器中,不会再报找不到异常类。
- URLClassLoader 如果不设置父类加载器,它的默认父类加载器为系统类加载器,于是testclassloader.jar 将由系统类加载器加载,为了能在系统类加载器中找到TestInterface接口类,必须使用TestInterface接口类由系统类加载器父类加载器以上的类加载器加载,对于扩展类加载器,可以将testclassloader.jar 复制到$JAVA_HOME/jre/lib/ext 目录下,保证了由URLClassLoader 加载的类的引用类能从扩展类加载器中找到,问题同样得到了解决 。
讨论了这么多,回归到Tomcat中的Thread.currentThread().setContextClassLoader(catalinaLoader),上面讨论了典型的类加载器错误在Tomcat 中同样存在 ,因此Tomcat 正是通过设置了线程上下文类加载器来解决的,在Tomcat 中类加载器同样存在以下三种情况。
- Tomcat 7 默认由Common ClassLoader 类加载器加载
- CommonLoader 的父类加载器是系统类加载器。
- 当前线程类加载器是系统类加载器。
如图13.5 所示 ,先看默认的情况,ContextClassLoader 被赋为系统类加载器,系统类加载器看不见Common 类加载器加载的类,即如果在过程中引用就会报找不到类的错误,所以启动Tomcat 的过程中肯定会报错,接着看改进后的情况,把ContextClassLoader 赋为Common 类加载器,此时,Tomcat 在启动过程中如果用到了$CATALINA_BASE/lib 或$CATALINA_HOME/lib中的类,就不会报错了,同时,它也能看到系统类加载器及其父类加载器所有的加载类,简单的说,解决方法就是把Common 类加载器设置为线程上下文类加载器。
为了避免类加载错误,应该尽早设置线程上下文类加载器,所以在Tomcat 中启动初始化就马上设置,即初始化时马上通过Thread.currentThread().setContextClassLoader(catalinaLoader)设置线程上下文类加载器,此后线程运行默认由Common类加载器载入类。
接着看设置catalinaHome帮我们做了哪些事情。
private void setCatalinaHome() {
// 如果catalina.home已经设置好了,直接返回
if (System.getProperty(Globals.CATALINA_HOME_PROP) != null)
return;
File bootstrapJar = new File(System.getProperty("user.dir"), "bootstrap.jar");
if (bootstrapJar.exists()) {
//如果工作目录下存在bootstrap.jar文件
try {
// 如果user.dir = /Users/quyixiao/gitlab/tomcat,并且/Users/quyixiao/gitlab/tomcat/bootstrap.jar文件存在
// 此时设置 catalina.home为 /Users/quyixiao/gitlab
System.setProperty(Globals.CATALINA_HOME_PROP,
(new File(System.getProperty("user.dir"), ".."))
.getCanonicalPath());
} catch (Exception e) {
// 如果抛出异常,则设置 catalina.home 为user.dir=/Users/quyixiao/gitlab/tomcat
System.setProperty(Globals.CATALINA_HOME_PROP, System.getProperty("user.dir"));
}
} else {
//设置catalina.home 为user.dir 工作目录
System.setProperty(Globals.CATALINA_HOME_PROP, System.getProperty("user.dir"));
}
}
其实在设置catalina.home的原理也很简单,首先看catalina.home是否已经设置,如果没有设置,则看工作目录下是否有bootstrap.jar文件,如果有,则设置工作目录的上一级目录为catalina.home,否则,默认设置 user.dir 为catalina.home。catalina.base 的设置原理和catalina.home原理相似,如果catalina.home存在,则设置catalina.base 为catalina.home,如果不存在,则默认设置catalina.base 为工作目录。
接下来,我们先来了解一下Java的类加载器。
Java 的设计初衷主要是面向嵌入式领域,对于自定义的一些类, 考虑使用按需加载原则,即在程序使用时才加载类, 节省内存消耗,这时即可通过类加载器来动态加载 。
如果平时只做Web 开发,那应该很少会跟类加载器打交道,但如果想深入学习Tomcat 的构架,那它是必不可少的, 所谓类加载器,就是用于加载Java 类到Java 虚拟机中的组件,它负责读取Java 字节码,并转换成java.lang.Class类的一个实例,使字节码.class 文件得以运行,一般类加载器负责根据一个指定的类找到对应的字节码,然后根据这些字节码定义一个Java 类。 另外,它还可以加载资源,包括图像文件和配置文件 。
类加载器在实际使用中给我们带来的好处是,它可以使Java 类动态的加载到JVM 中并运行,即可以在程序运行时再加载类,提供了很灵活的动态加载方式,例如 Applect ,从远程服务器下载字节码到客户端再动态的加载到JVM 中便可以运行。
在Java体系中,可以将系统分为三种类型加载器。
- 启动类加载器(BootStrap ClassLoader) : 加载对象是Java 核心库,把一些核心的Java 类加载进JVM 中,这个加载器使用原生代码(C / C++) 实现,并不是继承 java.lang.ClassLoader,它是所有其他类加载器的最终父类加载器,负责加载
/jre/lib目录下的JVM指定的类库,其他属于JVM 整个的一部分,JVM 一启动就将这些指定的类加载到内存中,避免以后过多的I/O 操作,提高系统的运行效率,启动类加载器无法被Java 程序直接使用。 - 扩展类加载器(Extension ClassLoader) : 加载的对象为Java的扩展库,即加载
/jre/lib/ext 目录里面的类,这个类由启动类加载器加载,但因为启动类加载器并非用Java实现,已经脱离了Java 体系,所以如果尝试调用扩展类加载器的getParent()方法获取父类加载器会得到 null , 然而,它的父类加载器是启动类加载器。 - 应用程序类加载器(Application ClassLoader) ,也叫系统类类加载器(System ClassLoader) , 它负责加载用户类路径(CLASSPATH)指定的类库,如果程序没有自定义类加载器, 就是默认的应用程序类加载器, 但它的父类加载类被设置成了扩展类加载器,如果要使用这个类加载器,可以通过ClassLoader.getSystemClassLoader() 获取。
假如想自己写一个类加载器,那么只需要继承java.lang.ClassLoader 类即可, 可以用图 13.1来清楚的表示出各种类加载器的关系,启动类加载器是最根本的类加载器,其不存在父类加载器,扩展类加载器由启动类加载器加载,所以它的父类加载器是启动类加载器,应用程序类加载器也由启动类加载器加载,但它的父类加载器指向扩展类加载器,而其他用户自定义的类加载器由应用程序类加载器加载。
由此可以看出,越重要的类加载器就越早被JVM 载入, 这是考虑到安全性问题,因为先被加载的类加载器会充当一下个类加载器的父类加载器,在双亲委派模型机制下,就能确保安全性,双亲委派模型会在类加载器加载类时首先委托给父类加载器加载,除非父类加载器不能加载才自己加载 。
这种模型要求,除了顶层的启动类加载器外,其他的类加载器都要有自己的父类加载器,假如有一个类要加载进来,一个类加载器并不会马上尝试自己将其加载,而是委派给父类加载器加载 , 父类加载器收到后又尝试委派给其父类加载器加载 ,以此类推,直到委派给启动类加载器加载 ,这样一层一层的往上委派,只有当父类加载器反馈给自己没法完成这个类加载时,子加载器才会尝试自己加载,通过这个机制,保证了Java 应用所使用的都是同一个版本的Java 核心库的类, 同时这个机制也保证了安全性,试想,如果应用程序类加载器想要加载一个有破坏性的java.lang.System类,双亲委派模型会一层一层的向上委派,最终委派给启动类加载器,而启动类加载器检查到缓存中已经有了这个类加载器,并不会再加载这个有破坏性的System类。
另外,类加载器还拥有全盘负责机制,即当一个类加载器加载一个类时,这个类所依赖的,引用的其他所有的类都由这个类加载器加载,除非在程序中显示的指定另外一个类加载器加载 。
在Java 中,我们用完全匹配的类来标识一个类,即用包名和类名,而在JVM 中,一个类由完全匹配类名和一个类加载器实例ID 作为唯一的标识,也就是说,同一个虚拟机可以有两个包名 , 类名相同的类,只要它们由两个不同的类加载器加载,当我们在Java 中说两个类是否相等时,必须在针对同一个类加载器加载的前提下才有意义,否则,就算是同样的字节码由不同的类加载器加载,这两个类也不是相等的,这种特征为我们提供了隔离机制,在Tomcat 服务器中它是非常有用的。
了解了JVM 的类加载器的各种机制后,看看一个类是怎样被类加载器载入进来的,如图1.32 所示 ,要加载一个类,类加载器先判断已经加载过(加载过的类会缓存在内存中),如果缓存中存在此类,则直接返回这个类,否则,获取父类的加载器,如果父类加载器为null, 则由启动类加载器载入并返回Class,如果父类加载器不为null,则由父类加载器载入,载入成功就返回Class ,载入失败则根据类路径查找Class 文件,找到就加载此Class文件并返回Class,找不到就抛出ClassNotFundException 。
类加载器属于JVM 级别的设计,我们很多的时候基本不会与它打交道,假如你想深入了解Tomcat 内核或设计开发的构架和中间伯,那么你必须熟悉加载器相关的机制,在现实的设计中,根据实际情况利用类加载器可以提供类库在隔离及共享,保证软件不同级别的逻辑分割程序不会互相影响,提供更好的安全性。
自定义类加载器
一般的场景中使用Java 默认的类加载器即可,但有时为了达到某种目的,又不得不实现自己的类加载器,例如为了使类库互相隔离,为了实现热部署重加载功能,这时就需要自己定义类加载器,每个类加载器加载各自的资源,以此达到资源隔离的效果,在对资源的加载上可以沿用双亲委派机制,也可以打破双亲委派机制 。
- 沿用双亲委派机制自定义类加载器很简单,只须继承ClassLoader 类并重写findClass 该当即可,下面给出一个例子。
public class Test {
public Test() {
System.out.println(this.getClass().getClassLoader().toString());
}
public static void main(String[] args) {
System.out.println("===============");
}
}
定义一个TomcatClassLoader类(它继承ClassLoader),重写了findClass方法,此方法要做的事情就是读取Test.class 字节流并传入父类的defineClass方法,然后,就可以通过自定义类加载器TomcatClassLoader 对Test.class 进行加载了,完成加载后输出 “TomcatLoader”。
public class TomcatClassLoader extends ClassLoader {
private String name;
public TomcatClassLoader(ClassLoader parent, String name) {
super(parent);
this.name = name;
}
@Override
public String toString() {
return this.name;
}
@Override
protected Class findClass(String name) throws ClassNotFoundException {
InputStream is = null;
byte [] data = null;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try {
is = new FileInputStream(new File("/Users/quyixiao/github/pitpat-server/pitpat-admin/target/classes/com/test/xxx/Test.class"));
int c = 0 ;
while ( -1 != (c = is.read())){
baos.write(c);
}
data = baos.toByteArray();
}catch (Exception e ){
e.printStackTrace();
}finally {
try {
is.close();
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return this.defineClass(name,data,0 ,data.length);
}
public static void main(String[] args) {
TomcatClassLoader loader = new TomcatClassLoader(TomcatClassLoader.class.getClassLoader() , "TomcatClassLoader");
Class clazz ;
try {
clazz = loader.loadClass("com.test.xxx.Test");
Object object =clazz.newInstance();
}catch (Exception e){
e.printStackTrace();
}
}
}
2) 打破双亲委派机制则不仅要继承ClassLoader类,还要重写loadClass和findClass方法,下面给出一个例子。
定义Test类。
public class Test {
public Test() {
System.out.println(this.getClass().getClassLoader().toString());
}
public static void main(String[] args) {
System.out.println("===============");
}
}
重新定义一个继承ClassLoader 的TomcatClassLoaderN 类,这个类与前面的TomcatClassLoader 类很相似,但它除了重写findClass 方法外,还重写了loadClass方法,默认的loadClass 方法实现了双亲委派机制的逻辑,即会先让父类加载器加载,当无法加载时,才由自己加载器去加载,这里为了破坏双亲委派机制必须重写loadClass方法,即这里先尝试交由System类加载器加载,加载失败才会由自己加载,它并没有优先交给父类加载器,这就打破了双亲委派机制 。
public class TomcatClassLoaderN extends ClassLoader {
private String name;
public TomcatClassLoaderN(ClassLoader parent, String name) {
super(parent);
this.name = name;
}
@Override
public String toString() {
return this.name;
}
@Override
public Class loadClass(String name) throws ClassNotFoundException {
Class clazz = null;
ClassLoader system = getSystemClassLoader();
try {
clazz = system.loadClass(name);
} catch (Exception e) {
e.printStackTrace();
}
if (clazz != null) {
return clazz;
}
clazz = findClass(name);
return clazz;
}
@Override
protected Class findClass(String name) throws ClassNotFoundException {
InputStream is = null;
byte[] data = null;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try {
is = new FileInputStream(new File("/Users/quyixiao/github/pitpat-server/pitpat-admin/target/classes/com/test/xxx/Test.class"));
int c = 0;
while (-1 != (c = is.read())) {
baos.write(c);
}
data = baos.toByteArray();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
is.close();
baos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return this.defineClass(name, data, 0, data.length);
}
public static void main(String[] args) {
TomcatClassLoaderN loader = new TomcatClassLoaderN(TomcatClassLoaderN.class.getClassLoader(), "TomcatLoaderN");
Class clazz;
try {
clazz = loader.loadClass("com.luban.classloadtest.Test");
Object o = clazz.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果输出 :
sun.misc.Launcher$AppClassLoader@18b4aac2
Tomcat 中的类加载器
Tomcat 拥有不同的自定义类加载器,以实现各种资源库的控制 , 一般来说,Tomcat 主要用类加载器解决以下4个问题。
- 同一个Web 服务器里,各个Web 项目之间各自使用的Java 类库要互相隔离 。
- 同一个Web 服务器里,各个Web项目之间可以提供共享的Java 类库。
- 为了使服务器不受Web 项目的影响,应该使用服务器类库与应用程序类库互相独立 。
- 对于支持JSP的Web 服务器,应该支持热插拔(HotSwap)功能 。
对于以上的几个问题,如果单独使用一个类加载器明显是达不到效果的,必须根据具体的情况使用若干个自定义加载器。
下面来看看Tomcat 的类加载器是怎样定义的,如图13.3 所示,启动类加载器,扩展类加载器,应用程序类加载器这三个类加载器属于JDK 级别的加载器。它们是唯一的,我们一般不会对其做任何更改,接下来,则是Tomcat的类加载器,在Tomcat 中,最重要的一个类加载器是Common类加载器,它的父类加载器是应用程序类加载器,负责加载$CATALINA_BASE/lib ,$CATALINA_HOME/lib两个目录下的所有.class 文件和.jar文件,而下面的虚线框的两个类加载器主要用在Tomcat5 版本中这两个类加载器实例默认与常见的类加载器实例不同,Common 类加载器是它们的父类加载器,而在Tomcat 7 版本中,这两个实例变量也存在,是catalina.properties配置文件没有对server.loader 和share.loader 两项进行配置,所以在程序里这两个类加载器实例就被赋值为Common 类加载器实例,即一个Tomcat 7 版本的实例其实就只有Common 类加载器实例。
首先创建一个Common 类加载器,再把Common 类加载器作为参数传进createClassLoader方法里,这个方法里面根据catalina.properties中的server.loader 和share.loader 属性是否为空判断是否另外创建新的类加载器,如果属性为空,则把常见的类加载器直接赋值给Catalina类加载器和共享类加载器,如果默认配置满足不了你的需求,可以通过修改catalina.properties 配置文件满足需求 。
从图13.3 中的WebApp ClassLoader 来看,就大概知道它主要的加载Web 应用程序,它的父类加载器是Common 类加载器 ,Tomcat 中一般会有多个WebApp 类加载器实例,每个类加载器负责加载一个Web 程序 。
对照这样的一个类加载器结构,看看上面需要解决的问题是否解决 。由于每个Web 应用项目都有自己的WebApp 类加载器,很多的使用多个 Web 应用项目都有自己的WebApp 类加载器,很好的使用了Web 应用程序之间的互相隔离且能通过创建新的WebApp 类加载器达到热部署。这种类加载器的结构能使有效的Tomcat 不受Web 应用程序影响 ,而Common类加载器在存在使用多个Web应用程序能够互相共享类库。
private void initClassLoaders() {
try {
// CommonClassLoader是一个公共的类加载器,默认加载${catalina.base}/lib,${catalina.base}/lib/*.jar,${catalina.home}/lib,${catalina.home}/lib/*.jar下的class
// 虽然这个地方parent是null,实际上是appclassloader
commonLoader = createClassLoader("common", null);
// System.out.println("commonLoader的父类加载器===="+commonLoader.getParent());
if( commonLoader == null ) {
// no config file, default to this loader - we might be in a 'single' env.
commonLoader=this.getClass().getClassLoader();
}
// 下面这个两个类加载器默认情况下就是commonLoader
catalinaLoader = createClassLoader("server", commonLoader);
sharedLoader = createClassLoader("shared", commonLoader);
} catch (Throwable t) {
handleThrowable(t);
log.error("Class loader creation threw exception", t);
System.exit(1);
}
}
前面提到过Tomcat 会创建Common类加载器,Catalina类加载器和共享类加载器三个类加载器供自己使用,这三个其实是同一个类加载器对象,Tomcat 在创建类加载器后马上就将其设置成当前线程类加载器,即Thread.currentThread().setContenxtClassLoader(CatalinaLoader) , 这里主要是为了避免后面加载时加载不成功,下面列举一个典型的例子说明如何利用URLClassLoader 加载指定的Jar 包,并且解析由此引起的加载失败问题。
创建ClassLoader的时候,传入父classLoader 。 接着看代码 。
private ClassLoader createClassLoader(String name, ClassLoader parent)
throws Exception {
// 到catalina.properties找common.loader 或 server.loader 或 shared.loader 配置
String value = CatalinaProperties.getProperty(name + ".loader");
if ((value == null) || (value.equals("")))
return parent;
// 如果 common.loader 中配置了\${}或\${${}},则从环境变量中找到具体的属性值,并替换它
value = replace(value);
List repositories = new ArrayList();
StringTokenizer tokenizer = new StringTokenizer(value, ",");
while (tokenizer.hasMoreElements()) {
String repository = tokenizer.nextToken().trim();
if (repository.length() == 0) {
continue;
}
// Check for a JAR URL repository
try {
// 从URL上获取Jar包资源
@SuppressWarnings("unused")
URL url = new URL(repository);
repositories.add( new Repository(repository, RepositoryType.URL));
continue;
} catch (MalformedURLException e) {
// Ignore
}
// Local repository
if (repository.endsWith("*.jar")) {
// 表示目录下所有的jar包资源
repository = repository.substring
(0, repository.length() - "*.jar".length());
repositories.add(
new Repository(repository, RepositoryType.GLOB));
} else if (repository.endsWith(".jar")) {
// 表示目录下当个的jar包资源
repositories.add(
new Repository(repository, RepositoryType.JAR));
} else {
// 表示目录下所有资源,包括jar包、class文件、其他类型资源
repositories.add(
new Repository(repository, RepositoryType.DIR));
}
}
// 基于类仓库类创建一个ClassLoader
return ClassLoaderFactory.createClassLoader(repositories, parent);
}
根据catalina.properties的配置内容,分为以*.jar ,.jar ,或者目录三种情况来处理。现在,下面我们看看这三种情况处理的代码 。
13.4 类加载器工厂 -ClassLoaderFactory
Java 虚拟机利用加载器将类载入内存的过程中,类加载器需要做很多事情,例如 ,读取字节数组,验证,解析初始化等。而Java提供了URLClassLoader 类能方便的将Jar ,Class或网络资源加载到内存中,Tomcat 中则用一个工厂类ClassLoaderFactory 把创建的类加载的细节进行封装,通过它可以很方便的创建自定义类加载器。
如图13.4 所示 , 利用createClassLoader 方法并传入资源路径和父类的加载器即可创建一个自定义类加载器,此类加载器负责加载传入的所有资源 。

ClassLoaderFactory 有个内部类Repository ,它就是表示资源的类,资源的类型用一个RepositoryType枚举表示 。
public static enum RepositoryType {DIR,GLOB,JAR ,URL };
每个类型代表的意思如下 :
- DIR : 表示整个目录下的资源 , 包括所有的Class,Jar 包及其他类型的资源 。
- GLOB : 表示整个目录下的所有Jar 包资源 , 仅仅是.jar 后缀的资源 。
- JAR: 表示单个 Jar 包资源
- URL: 表示从URL上获取的Jar 包资源 。
public static ClassLoader createClassLoader(Listrepositories, final ClassLoader parent) throws Exception { if (log.isDebugEnabled()) log.debug("Creating new class loader"); // Construct the "class path" for this class loader Set set = new LinkedHashSet (); if (repositories != null) { for (Repository repository : repositories) { if (repository.getType() == RepositoryType.URL) { URL url = buildClassLoaderUrl(repository.getLocation()); if (log.isDebugEnabled()) log.debug(" Including URL " + url); set.add(url); // 如果是一个目录 } else if (repository.getType() == RepositoryType.DIR) { File directory = new File(repository.getLocation()); directory = directory.getCanonicalFile(); if (!validateFile(directory, RepositoryType.DIR)) { continue; } // 将目录构成一个URL URL url = buildClassLoaderUrl(directory); if (log.isDebugEnabled()) log.debug(" Including directory " + url); set.add(url); } else if (repository.getType() == RepositoryType.JAR) { //以 .jar 结尾 File file=new File(repository.getLocation()); file = file.getCanonicalFile(); if (!validateFile(file, RepositoryType.JAR)) { continue; } // 以 jar 包构成一个 URL URL url = buildClassLoaderUrl(file); if (log.isDebugEnabled()) log.debug(" Including jar file " + url); set.add(url); } else if (repository.getType() == RepositoryType.GLOB) { // 以*.jar 结尾 File directory=new File(repository.getLocation()); directory = directory.getCanonicalFile(); if (!validateFile(directory, RepositoryType.GLOB)) { continue; } if (log.isDebugEnabled()) log.debug(" Including directory glob " + directory.getAbsolutePath()); String filenames[] = directory.list(); if (filenames == null) { continue; } // 遍历目录下的所有文件 for (int j = 0; j < filenames.length; j++) { String filename = filenames[j].toLowerCase(Locale.ENGLISH); if (!filename.endsWith(".jar")) continue; File file = new File(directory, filenames[j]); file = file.getCanonicalFile(); // 如果不以.jar文件结尾,过滤掉 if (!validateFile(file, RepositoryType.JAR)) { continue; } if (log.isDebugEnabled()) log.debug(" Including glob jar file " + file.getAbsolutePath()); URL url = buildClassLoaderUrl(file); set.add(url); } } } } // Construct the class loader itself final URL[] array = set.toArray(new URL[set.size()]); if (log.isDebugEnabled()) for (int i = 0; i < array.length; i++) { log.debug(" location " + i + " is " + array[i]); } return AccessController.doPrivileged( new PrivilegedAction () { @Override public URLClassLoader run() { if (parent == null) // URLClassLoader是一个可以从指定目录或网络地址加载class的一个类加载器 return new URLClassLoader(array); else return new URLClassLoader(array, parent); } }); } private static URL buildClassLoaderUrl(File file) throws MalformedURLException { String fileUrlString = file.toURI().toString(); fileUrlString = fileUrlString.replaceAll("!/", "%21/"); return new URL(fileUrlString); }
通过上面的介绍,读者已经对ClassLoaderFactory 类有所了解,下面用一个简单的例子展示Tomcat中的常见类加载器是如何利用ClassLoaderFactory 工厂类来创建的,代码如下 :
List
repositorys.add(new Repository(“$catalina.home}/lib”,RepositoryType.DIR));
repositorys.add(new Repository(“$catalina.home}/lib”,RepositoryType.GLOB);
repositorys.add(new Repository(“$catalina.base}/lib”,RepositoryType.DIR));
repositorys.add(new Repository(“]$catalina.base}/lib”,RepositoryType.GLOB);
ClassLoaderParent = null;
ClassLoader commonLoader = ClassLoaderFactory.createClassLoader(repositories, parent);
到此Common 类加载器创建完毕,其中,${catalina.home} 与 ${catalina.base} 表示变量 ,它的值分别是Tomcat的安装目录与Tomcat 的工作目录,Parent 为父类加载器,如果它设置为null,ClassLoaderFactory 创建时会使用默认的父类加载器,即系统类加载器,总结起来,只需要以下的几步就能完成一个类加载器的创建,首先, 把要加载的资源 加载到一个列表中,其次确定父类的加载器,默认就设置为null, 最后,把这些作为参数传入ClassLoaderFactory工厂类。
如果我们不确定要加载的资源是网络上的还是本地上的,那么可以用以下的方式进行处理。
try {
URL url = new URL("路径 ");
repositories.add(new Repository("路径 ",RepositoryType.URL));
}catch( MalformedURLException e ){
}
这种方式处理得比较巧妙,URL 在实例化时可以检查到这个路径有效性,假如为本地资源或者网上不存在的路径资源 ,那么将抛出异常,不会把路径添加到资源列表中。
ClassLoaderFactory 工厂类最终将资源转换成URL[] 数组,因为ClassLoaderFactory 生成的类加载器继承于URLClassLoader 的,而URLClassLoader 的构造函数只支持URL[] 数组,从Repository 类转换成URL[] 数组可分为以下几种情况 。
- 若为RepositoryType.URL 类型的资源 , 则直接新建一个URL 实例并把它添加到URL[] 数组即可 。
- 若为RepositoryType.DIR 类型的资源,则要把File类型转化为URL 类型,由于URL 类用于网络,带有明显的协议,于是把本地文件的协议设定为file,即处理为new URL(“file:/D:/test”); 未尾 的 “/” ,切记要加上,它表示D 盘test 整个目录下的所有资源,最后,把 这个URL 实例添加到URL[] 数组中。
- 若为RepositoryType.JAR 类型的资源,则与处理RepositoryType.Dir 类型的资源类似 , 本地文件协议为file , 处理为new URL(“file:/D:/test/test.jar”) ,然后把这个URL 实例添加到URL[]数组中。
- 若为RepositoryType.GLOB 类型的资源,则找到某个目录下的所有文件,然后逐个判断是不是.jar 后缀结尾的,如果是,则与处理RepositoryType.JAR 类型的资源一样进行转换,再将URL 实例添加到URL[] 数组中,如果不是以.jar 结尾,则直接忽略 。
我相信经过上面这段代码的分析,你对Tomcat类加载器这一块代码已经有了深入理解,接下来,我们来看init()方法后面的代码 。
// Load our startup class and call its process() method
// 加载Catalina类,并生成instance
if (log.isDebugEnabled())
log.debug("Loading startup class");
Class startupClass =
catalinaLoader.loadClass
("org.apache.catalina.startup.Catalina");
Object startupInstance = startupClass.newInstance();
// Set the shared extensions class loader
// 设置Catalina实例的父级类加载器为sharedLoader(默认情况下就是commonLoader)
if (log.isDebugEnabled())
log.debug("Setting startup class properties");
String methodName = "setParentClassLoader";
Class paramTypes[] = new Class[1];
paramTypes[0] = Class.forName("java.lang.ClassLoader");
Object paramValues[] = new Object[1];
paramValues[0] = sharedLoader;
Method method =
startupInstance.getClass().getMethod(methodName, paramTypes);
method.invoke(startupInstance, paramValues);
catalinaDaemon = startupInstance;
其实这段代码的原理也很简单,通过反射创建org.apache.catalina.startup.Catalina对象,设置Catalina实例的父级类加载器为sharedLoader(默认情况下就是commonLoader)。
我们继续接着看Bootstrap的main 方法后面的代码 。
try {
String command = "start";
// 在Tomcat 启动停止脚本中,默认最后一个参数为命令(如stop ,start ),因此这里取最后一个参数
if (args.length > 0) {
command = args[args.length - 1];
}
if (command.equals("startd")) {
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
} else if (command.equals("stopd")) {
args[args.length - 1] = "stop";
daemon.stop();
} else if (command.equals("start")) {
daemon.setAwait(true); // 设置阻塞标志
daemon.load(args); // 解析server.xml,初始化Catalina
daemon.start();
if (null == daemon.getServer()) {
System.exit(1);
}
} else if (command.equals("stop")) {
daemon.stopServer(args);
} else if (command.equals("configtest")) {
daemon.load(args);
if (null == daemon.getServer()) {
System.exit(1);
}
System.exit(0);
} else {
log.warn("Bootstrap: command \"" + command + "\" does not exist.");
}
} catch (Throwable t) {
// Unwrap the Exception for clearer error reporting
if (t instanceof InvocationTargetException &&
t.getCause() != null) {
t = t.getCause();
}
handleThrowable(t);
t.printStackTrace();
System.exit(1);
}
我们先分析tomcat的启动,所以着重看加粗这一块的代码。先看daemon.setAwait(true); 这一行代码,我们从Bootstrap的main 方法就知道,daemon即为Bootstrap对象,而setAwait方法,即调用Bootstrap的setAwait方法,进入代码 。
public void setAwait(boolean await)
throws Exception {
Class paramTypes[] = new Class[1];
paramTypes[0] = Boolean.TYPE;
Object paramValues[] = new Object[1];
paramValues[0] = Boolean.valueOf(await);
Method method =
catalinaDaemon.getClass().getMethod("setAwait", paramTypes);
method.invoke(catalinaDaemon, paramValues);
}
在之前的分析中,我们知道catalinaDaemon即为Catalina对象,因此setAwait()方法实际上是调用了Catalina的setAwait方法,将Catalina对象属性await设置为true。
我们继续看load()方法。
private void load(String[] arguments)
throws Exception {
String methodName = "load";
Object param[];
Class paramTypes[];
if (arguments==null || arguments.length==0) {
paramTypes = null;
param = null;
} else {
paramTypes = new Class[1];
paramTypes[0] = arguments.getClass();
param = new Object[1];
param[0] = arguments;
}
Method method =
catalinaDaemon.getClass().getMethod(methodName, paramTypes);
if (log.isDebugEnabled())
log.debug("Calling startup class " + method);
method.invoke(catalinaDaemon, param);
}
关于load方法的实现,其实原理也很简单,实际上也是通过反射调用了Catalina的load()方法,分为两种情况,有参数和无参数,接下来,我们进入Catalina中看load()方法帮我们做了哪些事情,不过我们先看有参的load()方法 。
public void load(String args[]) {
try {
if (arguments(args)) {
load();
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
// 解析命令行输入的参数,所以我们能从这里知道命令行里能添加哪些参数
protected boolean arguments(String args[]) {
boolean isConfig = false;
if (args.length < 1) {
usage();
return (false);
}
for (int i = 0; i < args.length; i++) {
if (isConfig) {
configFile = args[i];
isConfig = false;
} else if (args[i].equals("-config")) {
isConfig = true;
} else if (args[i].equals("-nonaming")) {
setUseNaming( false );
} else if (args[i].equals("-help")) {
usage();
return (false);
} else if (args[i].equals("start")) {
starting = true;
stopping = false;
} else if (args[i].equals("configtest")) {
starting = true;
stopping = false;
} else if (args[i].equals("stop")) {
starting = false;
stopping = true;
} else {
usage();
return (false);
}
}
return (true);
}
从上述方法中可以看出 ,带参数的load()方法最终还是会调没有带参数的load()方法 ,而在此之前,却调用了arguments()方法,解析参数,例如 start 命令,则会将starting设置为true , stopping设置为false 。如果命令是-help ,则会调用usage()方法,而usage()方法打印出命令行参数的使用,默认也是调用usage()方法。
System.out.println
(“usage: java org.apache.catalina.startup.Catalina”
+ " [ -config {pathname} ]"
+ " [ -nonaming ] "
+ " { -help | start | stop }");
接下来看Catalina中无参的load()方法帮我们做了哪些事情 。
public void load() {
if (loaded) {
return;
}
loaded = true;
long t1 = System.nanoTime();
// 如果catalinaHome和catalinaBase是相对路径,那么在这里会转化为绝对路径
initDirs();
// Before digester - it may be needed
initNaming();
// Create and execute our Digester
// 初始化server.xml文件解析器
Digester digester = createStartDigester();
InputSource inputSource = null;
InputStream inputStream = null;
File file = null;
try {
// 先从文件系统获取server.xml
try {
file = configFile(); // 获取catalina.base目录下的conf/server.xml文件
inputStream = new FileInputStream(file);
inputSource = new InputSource(file.toURI().toURL().toString());
} catch (Exception e) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("catalina.configFail", file), e);
}
}
// 如果文件系统没有,则从classloader中获取server.xml
if (inputStream == null) {
try {
inputStream = getClass().getClassLoader()
.getResourceAsStream(getConfigFile());
inputSource = new InputSource
(getClass().getClassLoader()
.getResource(getConfigFile()).toString());
} catch (Exception e) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("catalina.configFail",
getConfigFile()), e);
}
}
}
// This should be included in catalina.jar
// Alternative: don't bother with xml, just create it manually.
// 如果没找到server.xml,那么则从classloader中找server-embed.xml
if( inputStream==null ) {
try {
inputStream = getClass().getClassLoader()
.getResourceAsStream("server-embed.xml");
inputSource = new InputSource
(getClass().getClassLoader()
.getResource("server-embed.xml").toString());
} catch (Exception e) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("catalina.configFail",
"server-embed.xml"), e);
}
}
}
// 如果没找到server.xml或server-embed.xml,那么告警
// 如果文件存在,判断文件没有可读权限
if (inputStream == null || inputSource == null) {
if (file == null) {
log.warn(sm.getString("catalina.configFail",
getConfigFile() + "] or [server-embed.xml]"));
} else {
log.warn(sm.getString("catalina.configFail",
file.getAbsolutePath()));
if (file.exists() && !file.canRead()) {
log.warn("Permissions incorrect, read permission is not allowed on the file.");
}
}
return;
}
try {
// 解析server.xml或server-embed.xml文件
inputSource.setByteStream(inputStream);
digester.push(this);
// 比较重要的一行代码,当digester已经建立好xml标签之间的关系后,这里就开始解析xml 了
digester.parse(inputSource);
} catch (SAXParseException spe) {
log.warn("Catalina.start using " + getConfigFile() + ": " +
spe.getMessage());
return;
} catch (Exception e) {
log.warn("Catalina.start using " + getConfigFile() + ": " , e);
return;
}
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
// Ignore
}
}
}
// 解析完server.xml或server-embed.xml后,将catalina设置到StandardServer中
getServer().setCatalina(this);
// Stream redirection
// 把System.out和System.err替换成SystemLogHandler对象
initStreams();
// Start the new server
// 解析完配置文件,开始初始化Server,而从初始化Server开始,就包括了一系列的子组件的初始化
try {
getServer().init();
} catch (LifecycleException e) {
if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) {
throw new java.lang.Error(e);
} else {
log.error("Catalina.start", e);
}
}
long t2 = System.nanoTime();
if(log.isInfoEnabled()) {
log.info("Initialization processed in " + ((t2 - t1) / 1000000) + " ms");
}
}
如果catalinaHome和catalinaBase是相对路径,那么在这里会转化为绝对路径,我们看其具体实现。
protected void initDirs() {
String catalinaHome = System.getProperty(Globals.CATALINA_HOME_PROP);
if (catalinaHome == null) {
// Backwards compatibility patch for J2EE RI 1.3
String j2eeHome = System.getProperty("com.sun.enterprise.home");
if (j2eeHome != null) {
catalinaHome=System.getProperty("com.sun.enterprise.home");
} else if (System.getProperty(Globals.CATALINA_BASE_PROP) != null) {
catalinaHome = System.getProperty(Globals.CATALINA_BASE_PROP);
}
}
// last resort - for minimal/embedded cases.
// 如果环境变量中catalina.home为空,则设置catalina.home为工作目录
if(catalinaHome==null) {
catalinaHome=System.getProperty("user.dir");
}
if (catalinaHome != null) {
File home = new File(catalinaHome);
// 如果是相对路径,则转化为绝对路径
if (!home.isAbsolute()) {
try {
catalinaHome = home.getCanonicalPath();
} catch (IOException e) {
catalinaHome = home.getAbsolutePath();
}
}
System.setProperty(Globals.CATALINA_HOME_PROP, catalinaHome);
}
if (System.getProperty(Globals.CATALINA_BASE_PROP) == null) {
// 如果环境变量中catalina.base为空,则设置catalina.base为catalinaHome
// 此时catalinaHome 已经是绝对路径了
System.setProperty(Globals.CATALINA_BASE_PROP,catalinaHome);
} else {
String catalinaBase = System.getProperty(Globals.CATALINA_BASE_PROP);
File base = new File(catalinaBase);
// 如果环境变量中catalina.base依然为相对路径,则转化为绝对路径
if (!base.isAbsolute()) {
try {
catalinaBase = base.getCanonicalPath();
} catch (IOException e) {
catalinaBase = base.getAbsolutePath();
}
}
// 重新设置catalina.base的路径
System.setProperty(Globals.CATALINA_BASE_PROP, catalinaBase);
}
// 如果临时目录不存在,或不是一个目录,则打印异常
String temp = System.getProperty("java.io.tmpdir");
if (temp == null || (!(new File(temp)).exists())
|| (!(new File(temp)).isDirectory())) {
log.error(sm.getString("embedded.notmp", temp));
}
}
其实initDirs()方法写了一大堆,但是实现原理还是很简单的,就是判断catalina.home在环境变量中是否存在,如果不存在设置当前工作目录为catalina.home,而catalina.base也是相同的套路,最后判断一下java.io.tmpdir是否存在并且是一个目录,否则打印一下错误信息。
protected void initNaming() {
// 默认情况下 useNaming = true
if (!useNaming) {
log.info( "Catalina naming disabled");
System.setProperty("catalina.useNaming", "false");
} else {
System.setProperty("catalina.useNaming", "true");
String value = "org.apache.naming";
String oldValue =
System.getProperty("java.naming.factory.url.pkgs");
if (oldValue != null) {
value = value + ":" + oldValue;
}
System.setProperty("java.naming.factory.url.pkgs", value);
if( log.isDebugEnabled() ) {
log.debug("Setting naming prefix=" + value);
}
value = System.getProperty
("java.naming.factory.initial");
if (value == null) {
System.setProperty
("java.naming.factory.initial",
"org.apache.naming.java.javaURLContextFactory");
} else {
log.debug( "INITIAL_CONTEXT_FACTORY already set " + value );
}
}
}
initNaming()主要设置catalina.useNaming的值,有什么用呢?我们在后续的博客中分析Tomcat 集成JNDI 再来分析 。
Digester的创建及使用
我们回到lCatalina的load方法,继续看Digester的创建代码 。
/**
* Create and configure the Digester we will be using for startup.
*/
protected Digester createStartDigester() {
long t1=System.currentTimeMillis();
// Initialize the digester
Digester digester = new Digester();
digester.setValidating(false);
digester.setRulesValidation(true);
Map, List> fakeAttributes = new HashMap, List>();
List objectAttrs = new ArrayList();
objectAttrs.add("className");
fakeAttributes.put(Object.class, objectAttrs);
// Ignore attribute added by Eclipse for its internal tracking
List contextAttrs = new ArrayList();
contextAttrs.add("source");
fakeAttributes.put(StandardContext.class, contextAttrs);
digester.setFakeAttributes(fakeAttributes);
digester.setUseContextClassLoader(true);
// Configure the actions we will be using
// 将节点,解析为一个org.apache.catalina.core.StandardServer对象,如果配置了className属性,则会解析对应的类对象。
digester.addObjectCreate("Server",
"org.apache.catalina.core.StandardServer",
"className");
// 将节点中的属性,使用StandardServer对象对应的set方法进行属性初始化
digester.addSetProperties("Server");
// 将节点对应的对象,调用节点的父节点对象的setServer(org.apache.catalina.Server params)方法,Server的父对象为this,后面会设置,也就Catalina对象。
digester.addSetNext("Server",
"setServer",
"org.apache.catalina.Server");
digester.addObjectCreate("Server/GlobalNamingResources",
"org.apache.catalina.deploy.NamingResources");
digester.addSetProperties("Server/GlobalNamingResources");
digester.addSetNext("Server/GlobalNamingResources",
"setGlobalNamingResources",
"org.apache.catalina.deploy.NamingResources");
// 对于Server/Listener节点,比如配置对于的实现类。
digester.addObjectCreate("Server/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Listener");
digester.addSetNext("Server/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
digester.addObjectCreate("Server/Service",
"org.apache.catalina.core.StandardService",
"className");
digester.addSetProperties("Server/Service");
digester.addSetNext("Server/Service",
"addService",
"org.apache.catalina.Service");
digester.addObjectCreate("Server/Service/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Listener");
digester.addSetNext("Server/Service/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
//Executor
digester.addObjectCreate("Server/Service/Executor",
"org.apache.catalina.core.StandardThreadExecutor",
"className");
digester.addSetProperties("Server/Service/Executor");
digester.addSetNext("Server/Service/Executor",
"addExecutor",
"org.apache.catalina.Executor");
// 创建Connector对象,在里面会初始化executor
digester.addRule("Server/Service/Connector",
new ConnectorCreateRule());
// 根据Connector节点的属性,调用set方法进行初始化,除开executor属性。
digester.addRule("Server/Service/Connector",
new SetAllPropertiesRule(new String[]{"executor"}));
// 将Connector对象通过调用Service.addConnector方法添加到Service中去,addConnector方法并不是简单的实现,还有其他逻辑,后面在详细的介绍。
digester.addSetNext("Server/Service/Connector",
"addConnector",
"org.apache.catalina.connector.Connector");
digester.addObjectCreate("Server/Service/Connector/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Connector/Listener");
digester.addSetNext("Server/Service/Connector/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
// Add RuleSets for nested elements
// addRuleSet方法实现也不复杂,就是调用NamingRuleSet、EngineRuleSet这些类的addRuleInstances方法
digester.addRuleSet(new NamingRuleSet("Server/GlobalNamingResources/"));
digester.addRuleSet(new EngineRuleSet("Server/Service/"));
digester.addRuleSet(new HostRuleSet("Server/Service/Engine/"));
digester.addRuleSet(new ContextRuleSet("Server/Service/Engine/Host/"));
addClusterRuleSet(digester, "Server/Service/Engine/Host/Cluster/");
digester.addRuleSet(new NamingRuleSet("Server/Service/Engine/Host/Context/"));
// When the 'engine' is found, set the parentClassLoader.
// 在解析Engine节点的时候,设置parentClassLoader为Catalina.class的类加载器, parentClassLoader为sharedClassLoader
digester.addRule("Server/Service/Engine",
new SetParentClassLoaderRule(parentClassLoader)); // shareClassLoader
addClusterRuleSet(digester, "Server/Service/Engine/Cluster/");
long t2=System.currentTimeMillis();
if (log.isDebugEnabled()) {
log.debug("Digester for server.xml created " + ( t2-t1 ));
}
return (digester);
}
上面写了那么多,但是什么意思呢?我们先来看addObjectCreate方法。
public void addObjectCreate(String pattern, String className, String attributeName) {
addRule(pattern, new ObjectCreateRule(className, attributeName));
}
public void addRule(String pattern, Rule rule) {
rule.setDigester(this);
getRules().add(pattern, rule);
}
从上面来看, 看不出什么东西,只知道以字符串如Server为key , ObjectCreateRule为值加入到规则中,不急继续看,addSetProperties和SetNextRule的实现。
public void addSetProperties(String pattern) {
addRule(pattern, new SetPropertiesRule());
}
public void addSetNext(String pattern, String methodName, String paramType) {
addRule(pattern, new SetNextRule(methodName, paramType));
}
如果addSetProperties的参数为Server, 我们可能还是无法理解addSetProperties()的功能是将

发现一个共同的特点,他们都实现了Rule接口,或多或少的实现了start方法和end方法,实现这个方法有何用呢?
匹配模式确定了何时触发处理操作,而处理
匹配模式确定了何时触发了处理操作,而处理规则定义了模式匹配的具体操作,处理规则需要实现接口org.apache.commons.digester.Rule ,该接口定义了模式匹配触发事件方法 。
1.begin() : 当读取到匹配节点的开始部分时调用,会将该节点的所有属性作为参数传入
2. body() : 当读取匹配节点的内容时调用,注意指的并不是子节点,而是嵌入内容的普通文本。
3. end() : 当读取到匹配节点的结束部分时调用,如果存在子节点,只有当子节点处理完毕后该方法才被调用 。
4. finish(): 当整个parse()方法完成时调用,多用于清除临时数据和缓存数据 。
我们可以通过Digester类的addRule()方法为某个匹配模式指定的处理规则,同时可以根据需要实现自己的规则,针对大多数的常见场景,Digester为我们提供了默认的处理规则实现类。 如表3-2所示 (注意Tomcat 并未包含表中的列出的所有规则类)。
表3-2 Digester 默认支持的处理规则
| 规则类 | 描述 |
|---|---|
| ObjectCreateRule | 当begin()方法调用时,该规则会将指定的Java类实例化,并将其放入对象栈,具体的Java类可由该规则的构造方法传入,也可以通过当前处理XML节点的某个属性指定,属性名称通过构造方法传入, 当end()方法调用时,该规则创建的对象将从栈中取出 |
| FactoryCreateRule | 是ObjectCreateRule规则的一个变体,用于处理Java类无默认构造方法的情况,或者需要在Digester处理该对象之前执行某些操作的情况 |
| SetPropertiesRule | 当begin()方法调用时,Digester使用标准的Java Bean属性操作方式 (setter) 将当前XML节点的属性值设置到栈顶部的对象中(Java Bean 属性名与XML 节点属性名匹配 ) |
| SetPropertyRule | 当begin()方法调用时,Digester会设置栈顶部对象指定属性的值,其中属性名和属性值分别通过XML 节点的两个属性指定 |
| SetNextRule | 当end()方法调用时,Digester会找到位于栈顶对象之后的对象调用指定的方法,同时将栈顶部对象作为参数传入,用于设置父对象的子对象,以在栈对象之间建立父子关系,从而形成对象树 |
| SetTopRule | 与SetNextRule对应,当end()方法调用时,Digester会找到位于栈顶部的对象,调用其指定的方法,同时将位于顶部对象之后的对象作为参数传入,用于设置当前对象的父对象 |
| CallMethodRule | 该规则用于在end() 方法调用时执行栈顶问对象的某个方法,参数值由CallParamRule获取 |
| CallParamRule | 该规则与CallMethodRule配合使用,作为其子节点的处理规则创建方法参数,参数值可取自某个特殊的属性,也可以取向节点的内容 |
| NodeCreateRule | 用于将XML文档树的一部分转换为DOM节点,并放入栈 |
public class Department {
private String name;
private String code;
private Map extension = new HashMap<>();
private List users = new ArrayList<>();
public void addUser(User user){
users.add(user);
}
public void putExtension(String name,String value){
this.extension.put(name,value);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public Map getExtension() {
return extension;
}
public void setExtension(Map extension) {
this.extension = extension;
}
public List getUsers() {
return users;
}
public void setUsers(List users) {
this.users = users;
}
}
public class User {
private String name;
private String code ;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
Department对象包含name和code简单属性,以及一个User的列表 ,一个表扩展属性的Map ,可以通过addUser()方法添加user 对象,通过putExtension() 方法添加扩展属性,User 对象包含name 和 code 两个简单的属性。
我们要转换的XML文件内容如下(test.xml)
director joke
从XML文件内容可以看出 , Department对象包含了两个User对象和一个名为director的扩展属性,我们可以编写如下代码完成XML 的解析 。
Digester digester = new Digester();
digester.setValidating(false);
digester.setRulesValidation(true);
// 匹配department节点时,创建Department对象
digester.addObjectCreate("department", Department.class);
// 匹配department节点时,设置对象的属性
digester.addSetProperties("department");
// 匹配department/user节点时,创建User对象
digester.addObjectCreate("department/user",User.class);
// 匹配department/user节点时,设置对象属性
digester.addSetProperties("department/user");
// 匹配department/user节点,调用Department对象的addUser
digester.addSetNext("department/user","addUser");
// 匹配department/extension节点时,调用Department对象的putExtension方法
digester.addCallMethod("department/extension","putExtension",2);
// 调用方法的第一个参数为节点department/extension/property-name的内容
digester.addCallParam("department/extension/property-name",0);
// 调用方法的第二个参数为节点 department/extension/property-value的内容
digester.addCallParam("department/extension/property-value",1);
try {
Department department = (Department) digester.parse(new File("/Users/quyixiao/gitlab/tomcat/java/com/luban/digesterx/test.xml"));
System.out.println(department);
} catch (Exception e) {
e.printStackTrace();
}
我们创建了一个Digester对象,并且为其添加匹配模式以及对应的处理规则,由于Digester已经提供了常见处理规则的工厂方法,因此,直接调用相关的方法即可,整个处理过程都不需要手动维护对象属性和对象间的关系,不需要解析XML Dom
我觉得Digester框架在解析xml上有独到的见解,因此我将Digester源码抽取出来 ,方便将来,如果我们自己要去写中间件的时候使用,Digester框架源码如下 。
https://github.com/quyixiao/digester
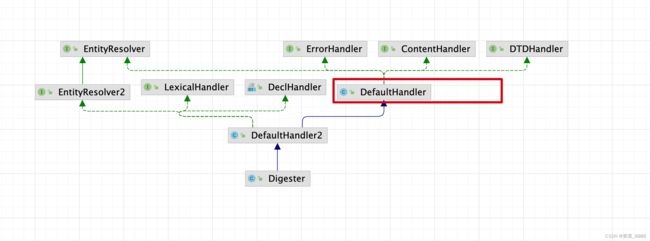
看到了Digester实现了org.xml.sax.helpers.DefaultHandler,证明最终xml由Digester来解析。
@Override
public void startElement(String namespaceURI, String localName, String qName, Attributes list)
throws SAXException {
boolean debug = log.isDebugEnabled();
if(debug){
saxLog.info("startElement(" + namespaceURI + "," + localName + "," + qName + ")");
}
// Parse system properties
// 将${xxx} 替换成系统中的环境变量
list = updateAttributes(list);
// Save the body text accumulated for our surrounding element
bodyTexts.push(bodyText);
bodyText = new StringBuilder();
// the actual element name is either in localName or qName, depending
// on whether the parser is namespace aware
String name = localName;
if ((name == null) || (name.length() < 1)) {
name = qName;
}
// Compute the current matching rule
StringBuilder sb = new StringBuilder(match);
if (match.length() > 0) {
sb.append('/');
}
sb.append(name);
match = sb.toString();
if (debug) {
log.debug(" New match='" + match + "'");
}
// Fire "begin" events for all relevant rules
// 获取规则,如解析节点,则会获得ObjectCreateRule和SetPropertiesRule及SetNextRule解析器规则
List rules = getRules().match(namespaceURI, match);
matches.push(rules);
if ((rules != null) && (rules.size() > 0)) {
for (int i = 0; i < rules.size(); i++) {
try {
Rule rule = rules.get(i);
if (debug) {
log.debug(" Fire begin() for " + rule);
}
// 调用规则的begin方法
rule.begin(namespaceURI, name, list);
} catch (Exception e) {
log.error("Begin event threw exception", e);
throw createSAXException(e);
} catch (Error e) {
log.error("Begin event threw error", e);
throw e;
}
}
} else {
if (debug) {
log.debug(" No rules found matching '" + match + "'.");
}
}
}
接着分别看ObjectCreateRule和SetPropertiesRule及SetNextRule的begin方法做了哪些事情 。先看ObjectCreateRule的begin方法 。
@Override
public void begin(String namespace, String name, Attributes attributes)
throws Exception {
// Identify the name of the class to instantiate
String realClassName = className;
if (attributeName != null) {
String value = attributes.getValue(attributeName);
if (value != null) {
realClassName = value;
}
}
if (digester.log.isDebugEnabled()) {
digester.log.debug("[ObjectCreateRule]{" + digester.match +
"}New " + realClassName);
}
if (realClassName == null) {
throw new NullPointerException("No class name specified for " +
namespace + " " + name);
}
// Instantiate the new object and push it on the context stack
Class clazz = digester.getClassLoader().loadClass(realClassName);
Object instance = clazz.newInstance();
digester.push(instance);
}
果然,ObjectCreateRule对象的功能和他的名字一样,先用digester.getClassLoader()加载类,然后实例化它,最后放到digester的stack中。接着看SetPropertiesRule的begin方法 。
@Override
public void begin(String namespace, String theName, Attributes attributes)
throws Exception {
// Populate the corresponding properties of the top object
// 之前在调用ObjectCreateRule的begin方法将对象放入到操作数栈顶中,此时取出
Object top = digester.peek();
if (digester.log.isDebugEnabled()) {
if (top != null) {
digester.log.debug("[SetPropertiesRule]{" + digester.match +
"} Set " + top.getClass().getName() +
" properties");
} else {
digester.log.debug("[SetPropertiesRule]{" + digester.match +
"} Set NULL properties");
}
}
// set up variables for custom names mappings
int attNamesLength = 0;
if (attributeNames != null) {
attNamesLength = attributeNames.length;
}
int propNamesLength = 0;
if (propertyNames != null) {
propNamesLength = propertyNames.length;
}
for (int i = 0; i < attributes.getLength(); i++) {
String name = attributes.getLocalName(i);
if ("".equals(name)) {
name = attributes.getQName(i);
}
String value = attributes.getValue(i);
// we'll now check for custom mappings
// 给开发者提供了自定义支持
for (int n = 0; n// set this to value from list
name = propertyNames[n];
} else {
// set name to null
// we'll check for this later
name = null;
}
break;
}
}
if (digester.log.isDebugEnabled()) {
digester.log.debug("[SetPropertiesRule]{" + digester.match +
"} Setting property '" + name + "' to '" +
value + "'");
}
if (!digester.isFakeAttribute(top, name)
// 利用反射调用setXXX方法向给top 对象的属性中设置值
&& !IntrospectionUtils.setProperty(top, name, value)
&& digester.getRulesValidation()) {
digester.log.warn("[SetPropertiesRule]{" + digester.match +
"} Setting property '" + name + "' to '" +
value + "' did not find a matching property.");
}
}
}

我们依然以
public void begin(String namespace, String name, Attributes attributes)
throws Exception {
begin(attributes);
}
@Deprecated
public void begin(Attributes attributes) throws Exception {
// The default implementation does nothing
}
发现SetNextRule的begin方法只是一个空实现,什么也没有做,接下来,我们来分析,当解析到结束标签时,Tomcat 又帮我们做了哪些事情呢?
@Override
public void endElement(String namespaceURI, String localName, String qName)
throws SAXException {
boolean debug = log.isDebugEnabled();
if (debug) {
if (saxLog.isDebugEnabled()) {
saxLog.debug("endElement(" + namespaceURI + "," + localName + "," + qName + ")");
}
log.debug(" match='" + match + "'");
log.debug(" bodyText='" + bodyText + "'");
}
// Parse system properties
// 将body中的${} 用系统环境变量替换掉
bodyText = updateBodyText(bodyText);
// the actual element name is either in localName or qName, depending
// on whether the parser is namespace aware
String name = localName;
if ((name == null) || (name.length() < 1)) {
name = qName;
}
// Fire "body" events for all relevant rules
// 出于性能考虑,此时并不像startElement一样,从cache中取,而是从stack中弹出即可
List rules = matches.pop();
if ((rules != null) && (rules.size() > 0)) {
String bodyText = this.bodyText.toString().intern();
for (int i = 0; i < rules.size(); i++) {
try {
Rule rule = rules.get(i);
if (debug) {
log.debug(" Fire body() for " + rule);
}
// 如果元素中有body 根据不同的规则,做不同的处理
rule.body(namespaceURI, name, bodyText);
} catch (Exception e) {
log.error("Body event threw exception", e);
throw createSAXException(e);
} catch (Error e) {
log.error("Body event threw error", e);
throw e;
}
}
} else {
if (debug) {
log.debug(" No rules found matching '" + match + "'.");
}
if (rulesValidation) {
log.warn(" No rules found matching '" + match + "'.");
}
}
// Recover the body text from the surrounding element
bodyText = bodyTexts.pop();
// Fire "end" events for all relevant rules in reverse order
// 这里需要注意的一点是end 方法的执行顺序和begin方法的执行顺序刚好相反 。
// 【注意】 Server标签的 begin方法的执行顺序分别是ObjectCreateRule和SetPropertiesRule及SetNextRule
// 那么end 方法的执行顺序即为SetNextRule,SetPropertiesRule , ObjectCreateRule
if (rules != null) {
for (int i = 0; i < rules.size(); i++) {
int j = (rules.size() - i) - 1;
try {
Rule rule = rules.get(j);
if (debug) {
log.debug(" Fire end() for " + rule);
}
rule.end(namespaceURI, name);
} catch (Exception e) {
log.error("End event threw exception", e);
throw createSAXException(e);
} catch (Error e) {
log.error("End event threw error", e);
throw e;
}
}
}
// Recover the previous match expression
int slash = match.lastIndexOf('/');
if (slash >= 0) {
match = match.substring(0, slash);
} else {
match = "";
}
}
因为end方法的执行顺序刚好相反,我们先来看SetNextRule的end方法 。
@Override
public void end(String namespace, String name) throws Exception {
// Identify the objects to be used
// 弹出当前标签对象
Object child = digester.peek(0);
// 弹出当前标签的父亲标签对象
Object parent = digester.peek(1);
if (digester.log.isDebugEnabled()) {
if (parent == null) {
digester.log.debug("[SetNextRule]{" + digester.match +
"} Call [NULL PARENT]." +
methodName + "(" + child + ")");
} else {
digester.log.debug("[SetNextRule]{" + digester.match +
"} Call " + parent.getClass().getName() + "." +
methodName + "(" + child + ")");
}
}
// 通过反射调用父亲标签类的setXXX方法,将当前标签的对象设置到父亲标签所在类中
IntrospectionUtils.callMethod1(parent, methodName,
child, paramType, digester.getClassLoader());
}
我们继续看SetPropertiesRule的end 方法,发现SetPropertiesRule并没有重写Rule的end方法,而Rule的end方法即是一个空实现。接着看ObjectCreateRule的end方法 。
@Override
public void end(String namespace, String name) throws Exception {
Object top = digester.pop();
if (digester.log.isDebugEnabled()) {
digester.log.debug("[ObjectCreateRule]{" + digester.match +
"} Pop " + top.getClass().getName());
}
}
ObjectCreateRule 的 end 方法的实现原理是不是很简单,直接将当前标签所对应的对象从栈中弹出即可 。此时我相信大家对Digester的套路有所理解了。

首先解析Server标签,通过ObjectCreateRule 创建org.apache.catalina.core.StandardServer对象,并且将其推入到栈中,然后通过SetPropertiesRule的begin方法将port以及shutdown属性通过反射设置到StandardServer对象属性中,解析GlobalNamingResources标签时,创建org.apache.catalina.deploy.NamingResources对象,并且将GlobalNamingResources对象推入到栈中,解析Resource标签,创建org.apache.catalina.deploy.ContextResource对象,并将ContextResource对象推入到栈中,并将name,auth , type , description 这些参数通过反射设置到ContextResource对象中,再通过SetNextRule的end方法,通过反射调用addResource方法将ContextResource对象添加到NamingResources的resources属性中,在ObjectCreateRule的end 方法中将ContextResource从栈中弹出,而NamingResources对象则被反射调用setGlobalNamingResources添加到StandardServer对象的globalNamingResources属性中,同样也被ObjectCreateRule的end方法将NamingResources对象从栈中弹出 ,最终解析完其他标签后,StandardServer也被从栈中弹出,这只是最简单也是最基本的套路,我相信大家肯定看明白了。
假如,有相同的父亲标签的子标识,也重复的写addObjectCreate(),addSetProperties(),addSetNext()方法不?显然不是,我们接下来看另外一种实现方式 。
digester.addRuleSet(new EngineRuleSet(“Server/Service/”));
先来看看addRuleSet()方法的实现。
public void addRuleSet(RuleSet ruleSet) {
String oldNamespaceURI = getRuleNamespaceURI();
// 如果ruleSet设置了namespaceURI,此时用新的namespaceURI
String newNamespaceURI = ruleSet.getNamespaceURI();
if (log.isDebugEnabled()) {
if (newNamespaceURI == null) {
log.debug("addRuleSet() with no namespace URI");
} else {
log.debug("addRuleSet() with namespace URI " + newNamespaceURI);
}
}
setRuleNamespaceURI(newNamespaceURI);
ruleSet.addRuleInstances(this);
// 恢复之前的namespaceURI
setRuleNamespaceURI(oldNamespaceURI);
}
重要的方法,就是上面加粗的代码。那这一行代码做了哪些事情呢?我们以EngineRuleSet为例来看。
@Override
public void addRuleInstances(Digester digester) {
// prefix是Server/Service/
// 创建StandardEngine
digester.addObjectCreate(prefix + "Engine",
"org.apache.catalina.core.StandardEngine",
"className");
// set方式初始化属性
digester.addSetProperties(prefix + "Engine");
digester.addRule(prefix + "Engine",
new LifecycleListenerRule
("org.apache.catalina.startup.EngineConfig",
"engineConfigClass"));
// 将StandardEngine通过调用Service的setContainer方法设置进Service中
digester.addSetNext(prefix + "Engine",
"setContainer",
"org.apache.catalina.Container");
//Cluster configuration start
digester.addObjectCreate(prefix + "Engine/Cluster",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Engine/Cluster");
digester.addSetNext(prefix + "Engine/Cluster",
"setCluster",
"org.apache.catalina.Cluster");
//Cluster configuration end
digester.addObjectCreate(prefix + "Engine/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Engine/Listener");
digester.addSetNext(prefix + "Engine/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
digester.addRuleSet(new RealmRuleSet(prefix + "Engine/"));
// Valve也必须指定className
digester.addObjectCreate(prefix + "Engine/Valve",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Engine/Valve");
digester.addSetNext(prefix + "Engine/Valve",
"addValve",
"org.apache.catalina.Valve");
}
大家发现没有,依然是相同的套路,addObjectCreate(),addSetProperties(),addRule()方法 。只是有一个特点,他们有相同的前缀Server/Service/,这里就不再缀述了,既然如此,那整个Tomcat 的server.xml 的结构是怎样子的呢? 请看下面。
addParentMethod方法表示调用父类的xxx方法将自身对象加入到父类中, paramType表示 xxx方法的参数类型。我们先对server.xml文件的结构有一个大体的认识,在后面的博客中,我们再来逐一分析 。
public Object parse(InputSource input) throws IOException, SAXException {
configure();
getXMLReader().parse(input);
return root;
}
public XMLReader getXMLReader() throws SAXException {
if (reader == null) {
reader = getParser().getXMLReader();
}
reader.setDTDHandler(this);
// 这里的this 表示Degister自身
reader.setContentHandler(this);
if (entityResolver == null) {
reader.setEntityResolver(this);
} else {
reader.setEntityResolver(entityResolver);
}
reader.setProperty("http://xml.org/sax/properties/lexical-handler", this);
reader.setErrorHandler(this);
return reader;
}
parse方法的原理很简单,指定xml 处理器为Digester 本身 ,如果没有reader,则创建一个SAXParser解析器。
最终会解析成为以StandardServer为根节点的一棵树。形成这样一棵树有什么用途呢?
像Tomcat 这么大的系统,必然需要对生命周期进行统一管理 , 那么Tomcat 是怎样管理自己的生命周期的呢? 本章将对Tomcat 的生命周期进行介绍 。
生命周期统一接口-Lifecycle 。
Tomcat的架构设计是清晰的,模块化的,它拥有很多的组件,假如在启动Tomcat时一个一个的组件启动,它不仅麻烦而且容易遗漏组件,还会对后面的动态组件扩展带来麻烦 , 对于这个问题,Tomcat 的设计者提供了一个解决方案,用Lifecycle管理启动,停止 ,关闭。
Tomcat 内部架构中各个核心组件有包含与被包含的关系,例如 , Server 包含Service , Service 包含Container 和Connector ,往下一层一层的包含,Tomcat 就是以容器的方式来组织整个系统的构架,就像数据结构的树, 树的根结点没有父亲节点,其他节点有且仅有一个父亲节点,每个父亲节点有零个或多个子节点,对于此,可以通过父容器启动它的子容器,这样只要启动容器,即可把其他的容器都启动,达到统一启动,停止,关闭的效果 。
作为统一的接口,Lifecycle把所有的启动,停止,关闭,生命周期相关的方法都组织在一起,就可以很方便的管理Tomcat各个容器组件的生命周期,下面是Lifecycle 接口的详细定义 。
public interface Lifecycle {
public static final String BEFORE_INIT_EVENT = "before_init";
public static final String AFTER_INIT_EVENT = "after_init";
public static final String START_EVENT = "start";
public static final String BEFORE_START_EVENT = "before_start";
public static final String AFTER_START_EVENT = "after_start";
public static final String STOP_EVENT = "stop";
public static final String BEFORE_STOP_EVENT = "before_stop";
public static final String AFTER_STOP_EVENT = "after_stop";
public static final String AFTER_DESTROY_EVENT = "after_destroy";
public static final String BEFORE_DESTROY_EVENT = "before_destroy";
public static final String PERIODIC_EVENT = "periodic";
public static final String CONFIGURE_START_EVENT = "configure_start";
public static final String CONFIGURE_STOP_EVENT = "configure_stop";
public void addLifecycleListener(LifecycleListener listener);
public LifecycleListener[] findLifecycleListeners();
public void removeLifecycleListener(LifecycleListener listener);
public void init() throws LifecycleException;
public void start() throws LifecycleException;
public void stop() throws LifecycleException;
public void destroy() throws LifecycleException;
public LifecycleState getState();
public String getStateName();
public interface SingleUse {
}
}
从上面可以看出,Lifecycle其实就是定义了一些状态常量和几个方法,这里主要看init ,start , stop ,三个方法,所以需要被生命周期管理的容器都要实现这个接口,并且各自被父容器相应的方法调用,例如,在初始化阶段,根据容器Server组件会调用init()方法,而在init()方法这里会调用它的子容器Service 组件和init方法,以此类推。
生命周期的状态转化
Tomcat的初始化到结束,期间必定会经历很多的其他的状态,每一个状态都标志着Tomcat 现在处于什么阶段,另外,事件的触发也通过这些状态来进行判定。
Lifecycle有个返回状态方法getState() ,返回的是LifecycleState枚举类型, 此枚举包含了生命周期的所有状态,供组件之间的转换使用, LifecycleState 类型的详细定义如下 :
public enum LifecycleState {
NEW(false, null),
INITIALIZING(false, Lifecycle.BEFORE_INIT_EVENT),
INITIALIZED(false, Lifecycle.AFTER_INIT_EVENT),
STARTING_PREP(false, Lifecycle.BEFORE_START_EVENT),
STARTING(true, Lifecycle.START_EVENT),
STARTED(true, Lifecycle.AFTER_START_EVENT),
STOPPING_PREP(true, Lifecycle.BEFORE_STOP_EVENT),
STOPPING(false, Lifecycle.STOP_EVENT),
STOPPED(false, Lifecycle.AFTER_STOP_EVENT),
DESTROYING(false, Lifecycle.BEFORE_DESTROY_EVENT),
DESTROYED(false, Lifecycle.AFTER_DESTROY_EVENT),
FAILED(false, null),
@Deprecated
MUST_STOP(true, null),
@Deprecated
MUST_DESTROY(false, null);
private final boolean available;
private final String lifecycleEvent;
private LifecycleState(boolean available, String lifecycleEvent) {
this.available = available;
this.lifecycleEvent = lifecycleEvent;
}
public boolean isAvailable() {
return available;
}
public String getLifecycleEvent() {
return lifecycleEvent;
}
}
上述常量从NEW 到DESTROYED 中间经历了生命周期的各个状态,这样就可以把整个生命周期划分为了多个阶段,每个阶段完成的每个阶段的任务 , 假如一个容器调用init() 后,状态的转化为NEW->INITIALIZING->INITIALIZED,其中 INITIALIZING->INITIALIZED是自动变化的,并不需要人为操作,接着调用start() ,状态则变化为INITIALIZED->STARTING_PREP -> STARTING_STARTED , 这个过程也是自动完成的, 接下来,如果调用Stop()方法,状态变化就是STARTED->STOPPING_PREP ->STOPPING-STOPPED。如果在生命周期的某个阶段发生了意外 ,则可能经历xx->DESTROYING->DESTROYED ,整个生命周期内状态的转化相对比较复杂,更多详细的转换情况下图11.1 所示 。
接下来,我们看StandServer的init()方法。
@Override
public final synchronized void init() throws LifecycleException {
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(Lifecycle.BEFORE_INIT_EVENT);
}
try {
// 初始化之前的事件 before_init
setStateInternal(LifecycleState.INITIALIZING, null, false);
// 初始化
initInternal();
// 初始化之后的事件处理 after_init
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(
sm.getString("lifecycleBase.initFail",toString()), t);
}
}
我们先看setStateInternal()方法帮我们做了哪些事情。
private synchronized void setStateInternal(LifecycleState state,
Object data, boolean check) throws LifecycleException {
if (log.isDebugEnabled()) {
log.debug(sm.getString("lifecycleBase.setState", this, state));
}
if (check) {
// Must have been triggered by one of the abstract methods (assume
// code in this class is correct)
// null is never a valid state
if (state == null) {
invalidTransition("null");
// Unreachable code - here to stop eclipse complaining about
// a possible NPE further down the method
return;
}
// Any method can transition to failed
// startInternal() permits STARTING_PREP to STARTING
// stopInternal() permits STOPPING_PREP to STOPPING and FAILED to
// STOPPING
if (!(state == LifecycleState.FAILED ||
(this.state == LifecycleState.STARTING_PREP &&
state == LifecycleState.STARTING) ||
(this.state == LifecycleState.STOPPING_PREP &&
state == LifecycleState.STOPPING) ||
(this.state == LifecycleState.FAILED &&
state == LifecycleState.STOPPING))) {
// No other transition permitted
invalidTransition(state.name());
}
}
this.state = state;
String lifecycleEvent = state.getLifecycleEvent();
if (lifecycleEvent != null) {
fireLifecycleEvent(lifecycleEvent, data);
}
}
protected void fireLifecycleEvent(String type, Object data) {
lifecycle.fireLifecycleEvent(type, data);
}
public void fireLifecycleEvent(String type, Object data) {
LifecycleEvent event = new LifecycleEvent(lifecycle, type, data);
LifecycleListener interested[] = listeners; // ContextCOnfig
for (int i = 0; i < interested.length; i++)
interested[i].lifecycleEvent(event);
}
生命周期的事件监听机制
如果我们面对这么多的状态之间的转换, 我们肯定会有这样的需求 , 我们希望在某某状态的事情发生之前和之后做点什么事情,Tomcat 在这里使用了事件监听器模式来实现这样的功能。 一般来说,事件监听器需要三个参考者。
- 事件对象,用于封装事件的信息,在事件监听器接口的统一方法中作为参数使用, 一般继承java.util.EventObject类。
- 事件源,触发事件的源头, 不同的事件源会触发不同的事件类型。
- 事件监听器,负责监听事件源发现的事件,更确切的说,应该是每当发生事件时, 事件源就会调用监听器统一方法去处理, 监听器一般实现了java.util.EventListener接口。
事件源提供注册事件监听器的方法 , 监听器一般实现java.util.EventListener接口。
事件源提供注册事件监听器的方法,维护多个事件监听器对象,同时可以向事件监听器对象发送事件对象,伴随着事件发生,相应的状态信息都封装在事件对象中,事件源将事件对象发给已经注册的所有事件监听器,这里其实就是调用事件监听器的统一方法,把事件对象作为参数传过去,接着会在这个统一的方法里根据事件对象做出相应的处理。
Tomcat 中的事件监听器也类似 , 如图11.2 所示 。 LifecycleEvent 类就是事件对象,继承了EventObject类,LifecycleListener 为事件监听器接口,里面只定义了一个方法的lifecycleEvent(LifecycleEvent event) ,很明显,LifecycleEvent 作为这个方法的参数,最后缺一个事件源,一般来说,组件和容器就是事件源,Tomcat 提供了一个辅助类LifecycleSupport ,用于帮助管理该组件或容器上的监听器,里面维护了一个监听器数组,并提供了注册,移除,触发监听器等方法 , 这样整个监听器框架就完成了, 假如,想要实现一个监听器功能,比如 XXXLifecycleListener ,只要扩展LifecycleListener 接口并重写里面的LifecycleEvent 方法,然后调用LifecycleSupport的addLifecycleListener 方法注册即可,后面,当发生某些事件时,就可以监听了。
上面这段代码中最重要的就是加粗这一行代码 interested[i].lifecycleEvent(event); ,遍历这个组件的所有监听器,并调用其lifecycleEvent方法。 而type 参数可能是before_init,after_init 或start 等等 。
我们以org.apache.catalina.startup.VersionLoggerListener 为例子,看其lifecycleEvent()方法做了哪些处理。
@Override
public void lifecycleEvent(LifecycleEvent event) {
if (Lifecycle.BEFORE_INIT_EVENT.equals(event.getType())) {
log();
}
}
private void log() {
log.info(sm.getString("versionLoggerListener.serverInfo.server.version",
ServerInfo.getServerInfo()));
log.info(sm.getString("versionLoggerListener.serverInfo.server.built",
ServerInfo.getServerBuilt()));
log.info(sm.getString("versionLoggerListener.serverInfo.server.number",
ServerInfo.getServerNumber()));
log.info(sm.getString("versionLoggerListener.os.name",
System.getProperty("os.name")));
log.info(sm.getString("versionLoggerListener.os.version",
System.getProperty("os.version")));
log.info(sm.getString("versionLoggerListener.os.arch",
System.getProperty("os.arch")));
log.info(sm.getString("versionLoggerListener.java.home",
System.getProperty("java.home")));
log.info(sm.getString("versionLoggerListener.vm.version",
System.getProperty("java.runtime.version")));
log.info(sm.getString("versionLoggerListener.vm.vendor",
System.getProperty("java.vm.vendor")));
log.info(sm.getString("versionLoggerListener.catalina.base",
System.getProperty("catalina.base")));
log.info(sm.getString("versionLoggerListener.catalina.home",
System.getProperty("catalina.home")));
if (logArgs) {
List args = ManagementFactory.getRuntimeMXBean().getInputArguments();
for (String arg : args) {
log.info(sm.getString("versionLoggerListener.arg", arg));
}
}
if (logEnv) {
SortedMap sortedMap = new TreeMap(System.getenv());
for (Map.Entry e : sortedMap.entrySet()) {
log.info(sm.getString("versionLoggerListener.env", e.getKey(), e.getValue()));
}
}
if (logProps) {
SortedMap sortedMap = new TreeMap();
for (Map.Entry e : System.getProperties().entrySet()) {
sortedMap.put(String.valueOf(e.getKey()), String.valueOf(e.getValue()));
}
for (Map.Entry e : sortedMap.entrySet()) {
log.info(sm.getString("versionLoggerListener.prop", e.getKey(), e.getValue()));
}
}
}
而同理,setStateInternal(LifecycleState.INITIALIZED, null, false);的实现原理一样,这里就不再赘述 。
上面提到了自己实现事件监听器,那我们自己写一个事件监听器试试 。
- 创建事件监听器
public class MyTestLifecycleListener implements LifecycleListener {
private static final Log log = LogFactory.getLog(VersionLoggerListener.class);
@Override
public void lifecycleEvent(LifecycleEvent event) {
log.info("MyTestLifecycleListener type = " + event.getType() + ", data = " + event.getData());
}
}
-
在server.xml 文件中添加事件监听器。
-
启动tomcat

我们可以根据当前处于不同的状态做相应的处理。
接下来,我们来看StandardServer的initInternal的实现逻辑 。
@Override
protected void initInternal() throws LifecycleException {
super.initInternal(); // 将StandardServer实例注册到jmx
// Register global String cache
// Note although the cache is global, if there are multiple Servers
// present in the JVM (may happen when embedding) then the same cache
// will be registered under multiple names
// 每个Server下都有一个全局的StringCache
onameStringCache = register(new StringCache(), "type=StringCache");
// Register the MBeanFactory
// MBeanFactory是JMX中用来管理Server的一个对象,通过MBeanFactory可以创建、移除Connector、Host等待
MBeanFactory factory = new MBeanFactory();
factory.setContainer(this);
onameMBeanFactory = register(factory, "type=MBeanFactory");
// Register the naming resources
globalNamingResources.init();
// Populate the extension validator with JARs from common and shared
// class loaders
// 将common和shared类加载器中的jar包中的清单文件添加到容器的清单文件资源池中
if (getCatalina() != null) {
ClassLoader cl = getCatalina().getParentClassLoader();
// Walk the class loader hierarchy. Stop at the system class loader.
// This will add the shared (if present) and common class loaders
while (cl != null && cl != ClassLoader.getSystemClassLoader()) {
if (cl instanceof URLClassLoader) {
URL[] urls = ((URLClassLoader) cl).getURLs();
for (URL url : urls) {
if (url.getProtocol().equals("file")) {
try {
File f = new File (url.toURI());
if (f.isFile() &&
f.getName().endsWith(".jar")) {
ExtensionValidator.addSystemResource(f);
}
} catch (URISyntaxException e) {
// Ignore
} catch (IOException e) {
// Ignore
}
}
}
}
cl = cl.getParent();
}
}
// Initialize our defined Services
// service初始化
for (int i = 0; i < services.length; i++) {
services[i].init();
}
}
接下来,我们来看StandardServer的initInternal的实现逻辑也很简单,直接调用所有配置了globalNamingResources的init()方法,以及配置的所有service标签的init()方法 ,我们再进一步,看service的init()方法做了哪些事情 。 进入StandardService的init()方法 ,发现StandardService并没有实现init()方法,而是使用了父类继承的init()方法 。 init(),然后又是走了setStateInternal() , initInternal() , setStateInternal()方法,之前分析过setStateInternal()方法,这里就不再赘述,进入StandardService的initInternal()方法 。
@Override
protected void initInternal() throws LifecycleException {
super.initInternal(); // 将StandardService注册到jmx中
// 将Service下的容器进行初始化,默认情况下是StandardEngine
if (container != null) {
container.init(); // 注意:这里是Engine,这个流程只会初始化StandardEngine,并没有去初始话Engine下的Host,那么Host是在哪初始化的呢?
// 实际上,对于Host容器,并不需要进行初始化
}
// Initialize any Executors
// 初始化线程池
// 可以在Service下配置定义executor,默认实现类为org.apache.catalina.core.StandardThreadExecutor
// 这个初始化只是走了一下生命周期的初始化流程,没有其他作用
for (Executor executor : findExecutors()) {
if (executor instanceof LifecycleMBeanBase) {
((LifecycleMBeanBase) executor).setDomain(getDomain());
}
executor.init();
}
// Initialize our defined Connectors
// 初始化连接器
// 为什么这里要同步,而上面的container和executor不同步?
synchronized (connectorsLock) {
for (Connector connector : connectors) {
try {
connector.init();
} catch (Exception e) {
String message = sm.getString(
"standardService.connector.initFailed", connector);
log.error(message, e);
if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE"))
throw new LifecycleException(message);
}
}
}
}
protected void initInternal() throws LifecycleException {
// If oname is not null then registration has already happened via
// preRegister().
if (oname == null) {
mserver = Registry.getRegistry(null, null).getMBeanServer();
oname = register(this, getObjectNameKeyProperties());
}
}
看到没有,先是container初始化,再是executor和connector初始化 。
接下来,我们来看Bootstrap的start()方法 。
start
public void start()
throws Exception {
if( catalinaDaemon==null ) init();
Method method = catalinaDaemon.getClass().getMethod("start", (Class [] )null);
method.invoke(catalinaDaemon, (Object [])null);
}
而启动,也是通过反射调用Catalina的start方法
public void start() {
if (getServer() == null) {
load();
}
if (getServer() == null) {
log.fatal("Cannot start server. Server instance is not configured.");
return;
}
long t1 = System.nanoTime();
// Start the new server
try {
getServer().start(); //
} catch (LifecycleException e) {
log.fatal(sm.getString("catalina.serverStartFail"), e);
try {
// 如果启动失败,则调用销毁方法
getServer().destroy();
} catch (LifecycleException e1) {
log.debug("destroy() failed for failed Server ", e1);
}
return;
}
long t2 = System.nanoTime();
if(log.isInfoEnabled()) {
log.info("Server startup in " + ((t2 - t1) / 1000000) + " ms");
}
// Register shutdown hook
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
// If JULI is being used, disable JULI's shutdown hook since
// shutdown hooks run in parallel and log messages may be lost
// if JULI's hook completes before the CatalinaShutdownHook()
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(
false);
}
}
// 是否需要阻塞,await标记是在通过Bootstrap类启动时设置为true的
if (await) { // true
await(); // 使用ServerSocket来监听shutdown命令来阻塞
stop(); // 如果阻塞被解开,那么开始停止流程
}
}
启动过程中,最重要的是加粗这一行代码。 接下来,我们进入start()方法 。
public final synchronized void start() throws LifecycleException {
// 如果容器已经启动,则不再调用启动过程,可能我们在命令行中调用两次start命令
if (LifecycleState.STARTING_PREP.equals(state) || LifecycleState.STARTING.equals(state) ||
LifecycleState.STARTED.equals(state)) {
if (log.isDebugEnabled()) {
Exception e = new LifecycleException();
log.debug(sm.getString("lifecycleBase.alreadyStarted", toString()), e);
} else if (log.isInfoEnabled()) {
log.info(sm.getString("lifecycleBase.alreadyStarted", toString()));
}
return;
}
// 如果还没有初始化,则先进行初始化
if (state.equals(LifecycleState.NEW)) {
init();
// 如果启动失败,调用stop销毁方法
} else if (state.equals(LifecycleState.FAILED)) {
stop();
// 如果当前状态既不是before_start, start, after_start,
// 也不是 after_init ,after_stop,
// 也就是当前状态为before_init, 或before_stop,如果容器正在初始化,或容器正在停止,但是还没有停止完全 , 则抛出异常
} else if (!state.equals(LifecycleState.INITIALIZED) &&
!state.equals(LifecycleState.STOPPED)) {
invalidTransition(Lifecycle.BEFORE_START_EVENT);
}
try {
// 发送启动前事件
setStateInternal(LifecycleState.STARTING_PREP, null, false);
startInternal();
// 如果启动失败,则销毁
if (state.equals(LifecycleState.FAILED)) {
// This is a 'controlled' failure. The component put itself into the
// FAILED state so call stop() to complete the clean-up.
stop();
// 如果启动失败,则抛出异常
} else if (!state.equals(LifecycleState.STARTING)) {
// Shouldn't be necessary but acts as a check that sub-classes are
// doing what they are supposed to.
invalidTransition(Lifecycle.AFTER_START_EVENT);
} else {
// 发出启动完成事件
setStateInternal(LifecycleState.STARTED, null, false);
}
} catch (Throwable t) {
// This is an 'uncontrolled' failure so put the component into the
// FAILED state and throw an exception.
ExceptionUtils.handleThrowable(t);
setStateInternal(LifecycleState.FAILED, null, false);
throw new LifecycleException(sm.getString("lifecycleBase.startFail", toString()), t);
}
}
上面的实现套路和init()方法一样, 都是从父组件向下调用,一级一级,最终达到整个容器初始化,启动,停止,销毁的效果 。
同样启动和步骤也是通过类似的调用机制实现统一的启动,统一的关闭,至此,我们对Tomcat 生命周期的统一初始化,启动,关闭机制有了比较清晰的认识。
其实Tomcat的整个启动和停止的过程,就像政府部分发布政策一样,先由中央发布,一级一级的向下传递,最终落实到乡镇,假如新增加一个乡镇,只需要将其并到他的上一级,并且设置相同的机构,那么中央下达的指令,依然会到达这个乡镇,和其他乡镇相同的反映机制,因此,Tomcat 也像一个宠大的组织机构,所有的子组件和父亲组件有一样的步调,当父组件init()时,子组件也init() , 父组件stop时,子组件也stop。
在这篇博客中,我们并没有具体去分析某个组件的具体功能,而是从宏观的角度去分析了一下Tomcat 初始化,启动,停止(实现套路一样)。希望对你有所帮助 。
补充:
tomcat 的github地址: https://github.com/quyixiao/tomcat
digester框架源码 : https://github.com/quyixiao/digester
手动将lib包加入到Libraries中,就可以启动Tomcat 了