深度学习笔记(四)(1)卷积神经网络
深度学习笔记(四)(1)卷积神经网络
返回目录
终于到了。。。。
1.1 计算机视觉(Computer vision)
图象识别、目标检测、风格迁移。
但在应用计算机视觉时要面临一个挑战,就是数据的输入可能会非常大。
1.2 边缘检测示例(Edge detection example)

filter为过滤器,同时也被叫做核。这里的*为元素的乘法,输出的用绿格子框柱的地方,就是左上蓝色部分卷积后相加的值。
过滤器可以做垂直检测的原因:从左到右是从明到暗的变化,所以可以用来提取边缘线,就是明亮变化程度较大的线。卷积运算提供了一个方便的方法来发现图像中的垂直边缘。
1.3 更多边缘检测内容(More edge detection)

分别为竖直检测和水平检测。

这个图表示了,相同的过滤器对不同的图象卷积造成的结果,第二个图象被翻转了,就是说,过滤器可以感受区分明暗的变化。
不一定非要用上面的过滤器,也可以把过滤器中的数值当做参数,并且在之后你可以学习使用反向传播算法,其目标就是去理解这9 个参数。这种将这 9 个数字当成参数的思想,已经成为计算机视觉中最为有效的思想之一,它可以检测出45°或70°或73°,甚至是任何角度的边缘。我们会发现神经网络可以学习一些低级的特征,例如这些边缘的特征。
1.4 Padding
输出的维度
如果我们有一个 × 的图像,用 × 的过滤器做卷积,那么输出的维度就是( − + 1) × ( − + 1)。
这样的缺点:第一个缺点是每次做卷积操作,你的图像就会缩小。第二个缺点是那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息,为了解决这些问题,你可以在卷积操作之前填充这幅图像。
这里画的这种情况,填充后 = 2。

至于选择填充多少像素,通常有两个选择,分别叫做 Valid 卷积和 Same 卷积。
Valid 卷积意味着不填充,此时:如果你有一个 × 的图像,用一个 × 的过滤器卷积,它将会给你一个( − + 1) × ( − + 1)维的输出。
而对于Same卷积,如果你有一个 × 的图像,用个像素填充边缘,输出的大小就是这样的( + 2 − + 1) × ( + 2 − + 1)。
如果你想让 + 2 − + 1 = 的话,使得输出和输入大小相等,如果你用这个等式求解,那么 = ( − 1)/2。所以当是一个奇数的时候,只要选择相应的填充尺寸,你就能确保得到和输入相同尺寸的输出。
习惯上,计算机视觉中,通常是奇数,其中一个可能是,如果是一个偶数,那么你只能使用一些不对称填充。第二个原因是当你有一个奇数维过滤器,比如 3×3 或者 5×5 的,它就有一个中心点。
1.5 卷积步长(Strided convolutions)
s=2:

细节:如果输出的商不是整数:在这种情况下,我们向下
取整。⌊ ⌋这是向下取整的符号,这也叫做对进行地板除(floor),这意味着向下取整到最近的整数。这个原则实现的方式是,你只在蓝框完全包括在图像或填充完的图像内部时,才对它进行运算。如果有任意一个蓝框移动到了外面,那你就不要进行相乘操作,这是一个惯例。

一般的把过滤器进行一个镜像,然后做卷积操作,这叫做互相关。在深度学习文献中,按照惯例,我们将这(不进行翻转操作)叫做卷积操作。
1.6 三维卷积(Convolutions over volumes)
按照计算机视觉的惯例,当你的输入有特定的高宽和通道数时,你的过滤器可以有不同的高,不同的宽,但是必须一样的通道数。理论上,我们的过滤器只关注红色通道,或者只关注绿色或者蓝色通道也是可行的。
若想同时使用多个过滤器,可以先试用一个过滤器得到一个f * f * 1,再使用一个过滤器得到f * f * 1,然后堆成一个f * f * 2的。
我们总结一下维度,如果你有一个 × × (通道数)的输入图像,在这个例子中就是 6×6×3,这里的就是通道数目,然后卷积上一个 × × ,这个例子中是 3×3×3,按照惯例,这个(前一个)和这个(后一个)必须数值相同。然后你就得到了( − + 1)× ( − + 1) × ′,这里′其实就是下一层的通道数,它就是你用的过滤器的个数,在我们的例子中,那就是 4×4×2。我写下这个假设时,用的步幅为 1,并且没有 padding。如果你用了不同的步幅或者 padding,那么这个 − + 1数值会变化,正如前面的视频演示的那样。
通道数()来表示最后一个维度,在文献里大家也把它叫做 3 维立方体的深度。
1.7 单层卷积网络(One layer of a convolutional network)
何构建卷积神经网络的卷积层。

上面有提到过,这个图的意思就是用黄色代表的过滤器与橙色代表的过滤器分别进行卷积,然后如图,对第一个获得的结果加上一个实数b1,用python 的广播机制来加给每一个元素,对第二个获得的结果加上一个实数b2,用python的广播机制来加给每一个元素,然后得到的结果应用非线性激活函数 ReLU;这时通过计算,从 6×6×3 的输入推导出一个 4×4×2 矩阵,它是卷积神经网络的一层,把它映射到标准神经网络中四个卷积层中的某一层或者一个非卷积神经网络中。
例子中使用了俩个过滤器,得到了4 * 4 * 2,。但如果我们用了 10 个过滤器,而不是 2 个,我们最后会得到一个 4×4×10 维度的输出图像,因为我们选取了其中 10 个特征映射,而不仅仅是 2 个,将它们堆叠在一起,形成一个4×4×10 的输出图像,也就是[1]。

最后总结一下用于描述卷积神经网络中的一层的各种标记。

这个图非常的抽象,但是说的很全。。。

最后补充:
此过滤器中通道的数量必须与输入中通道的![因此,输出通道数量就是输入通道数量,所以过滤器维度等于[] × [] × [−1]。](https://img-blog.csdnimg.cn/20200703155319294.png)

1.8 简 单 卷 积 网 络 示 例 ( A simple convolution network example)

下面写的从图都能看出来
第一个图表示输入是39 * 39 * 3的图片,使用3 * 3的valid卷积,有10个过滤器,所以输出就是37 * 37 * 10,是根据下面公式算出来的。
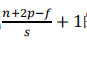
然后第二个卷积层也是如此,过滤器是5 * 5的20个,故f=5,然后这时选择s=2,p=0的same卷积,得到了17 * 17 * 20的图象,他也是激活值a的维度。
对于最后一层,假设过滤器还是 5×5,步幅为 2,即[2] = 5,[3] = 2,计算过程我跳过了,最后输出为 7×7×40,假设使用了 40 个过滤器。padding 为 0,40 个过滤器,最后结果为 7×7×40。
到此这张39 * 39 *3的图象输入完毕了,为图像提取了 7 * 7 * 40个特征,计算出来就是1960个特征,然后对该卷积进行处理,可以将其平滑或展开成 1960 个单元。平滑处理后可以输出一个向量,其填充内容是 logistic 回归单元还是 softmax 回归单元,完全取决
于我们是想识图片上有没有猫,还是想识别种不同对象中的一种,用^表示最终神经网络的预测输出。明确一点,最后这一步是处理所有数字,即全部的 1960 个数字,把它们展开成一个很长的向量。为了预测最终的输出结果,我们把这个长向量填充到 softmax回归函数中。
本节课的要点是,随着神经网络的不断加深,通常开始时的图像也要更大一些,初始值为 39×39,高度和宽度会在一段时间内保持一致,然后随着网络深度的加深而逐渐减小。
一个典型的卷积神经网络通常有三层,一个是卷积层,我们常常用 Conv 来标注。
还有两种常见类型的层,一个是池化层,我们称之为 POOL。最后一个是全连接层,用 FC 表示。
1.9 池化层(Pooling layers)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高
所提取特征的鲁棒性。

对最大池化功能的直观理解,你可以把这个 4×4 输入看作是某些特征的集合,也许
不是,数字大代表可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边
缘,一只眼睛,或是大家害怕遇到的 CAP 特征。
一个有趣的特点:它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了和,它就是一个固定运算,梯度下降无需改变任何值。
前面提到的计算卷积的输出图像的大小公式在这里也适用。
示例,输入是一个 5×5 的矩阵。我们采用最大池化法,它的过滤器参数为 3×3,即 = 3,步幅为 1, = 1,输出矩阵是 3×3。之前讲的计算卷积层输出大小的公式同样适用于最大池化,即+2− + 1。

一般来说,如果输入是 5×5×,输出就是 3×3×,个通道中每个通道都单独执行最大池化计算,以上就是最大池化算法。
另一种池化:平均池化(不常用)
目前来说,最大池化比平均池化更常用。但也有例外,就是深度很深的神经网络,你可
以用平均池化来分解规模为 7×7×1000 的网络的表示层,在整个空间内求平均值,得到
1×1×1000,一会我们看个例子。但在神经网络中,最大池化要比平均池化用得更多。

如图,结果为相应的方块值的平均值。
总结

1.10 卷 积 神 经 网 络 示 例 ( Convolutional neural network example)
构建一个神经网络去识别数字7,这个网络模型和经典网络 LeNet-5 非常相似。
卷积有两种分类,这与所谓层的划分存在一致性。一类卷积是一个卷积层和一个池化层一起作为一层,这就是神经网络的 Layer1。另一类卷积是把卷积层作为一层,而池化层单独作为一层。这里,我们把 CONV1和 POOL1 共同作为一个卷积,并标记为 Layer1。
从图分析,输入是一个32 * 32 * 3的图象,经过5 * 5 * 3的6个过滤器,步长为1,CONV1为28 * 28 * 6,然后进行maxpool,用2 * 2 * 6的,步长设置为2,这时得到14 *14 *6的pool1层(看上面的计算公式),然后同理一直到pool2输出为5 * 5 * 16的特征,把他化为向量的形式有400个元素,可以把平整化结果想象成这样的一个神经元集合,然后利用这 400 个单元构建下一层。下一层含有 120 个单元,这就是我们第一个全连接层,标记为 FC3。这 400 个单元与 120 个单元紧密相连,这就是全连接层。它很像我们在第一和第二门课中讲过的单神经网络层,这是一个标准的神经网络。它的权重矩阵为[3],维度为 120×400。这就是所谓的“全连接”,因为这 400 个单元与这 120 个单元的每一项连接,还有一个偏差参数。最后输出 120 个维度,因为有 120 个输出。然后我们对这个 120 个单元再添加一个全连接层,这层更小,假设它含有 84 个单元,标记为 FC4。最后,用这 84 个单元填充一个 softmax 单元。如果我们想通过手写数字识别来识别手写 0-9 这 10 个数字,这个 softmax 就会有 10 个输出。
对于这个介绍的典型的卷积神经网络,关于选定超级参数,。常规做法是,尽量不要自己设置超参数,而是查看文献中别人采用了哪些超参数,选一个在别人任务中效果很好的架构,那么它也有可能适用于你自己的应用程序。
总结:
随着层数增加,高度和宽度都会减小,而通道数量会增加,从 3 到 6 到 16 不断增加,然后得到一个全连接层。
在神经网络中,另一种常见模式就是一个或多个卷积后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个 softmax。这是神经网
络的另一种常见模式。
神经网络的激活值形状,激活值大小和参数数量。
注意:
第一,池化层和最大池化层没有参数;
第二,卷积层的参数相对较少,前面课上我们提到过,其实许多参数都存在于神经网络的全连接层。
观察可发现,随着神经网络的加深,激活值尺寸会逐渐变小,如果激活值尺寸下降太快,也会影响神经网络性能。
1.11 为什么使用卷积?(Why convolutions?)
卷积层的两个主要优势在于参数共享和稀疏连接

参数少的原因:
1.参数共享。观察发现,特征检测如垂直边缘检测如果适用于图片的某个区域,那么
它也可能适用于图片的其他区域。(意思就是说这一个过滤器在不停的找全图片的边缘特征嘛)
2.使用稀疏连接。
神经网络可以通过这两种机制减少参数,以便我们用更小的训练集来训练它,从而预防
过度拟合。你们也可能听过,卷积神经网络善于捕捉平移不变。

根据我的经验,找到整合基本构造模块最好方法就是大量阅读别人的案例。------吴老师
根据我的经验,找到整合基本构造模块最好方法就是大量阅读别人的案例。------吴老师
根据我的经验,找到整合基本构造模块最好方法就是大量阅读别人的案例。------吴老师
返回目录