机器学习-常见聚类算法K-means,模糊c-均值,谱聚类 DBSCAN算法等
聚类算法:
聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。
聚类(Cluster)分析是由若干模式(Pattern)组成的,通常,模式是一个度量(Measurement)的向量,或者是多维空间中的一个点。
聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。
俗话说:“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。所谓类,通俗地说,就是指相似元素的集合。
聚类分析起源于分类学,在古老的分类学中,人们主要依靠经验和专业知识来实现分类,很少利用数学工具进行定量的分类。随着人类科学技术的发展,对分类的要求越来越高,以致有时仅凭经验和专业知识难以确切地进行分类,于是人们逐渐地把数学工具引用到了分类学中,形成了数值分类学,之后又将多元分析的技术引入到数值分类学形成了聚类分析。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
常见聚类算法:
1.原型聚类:K-means , KNN , LVQ
2.密度聚类:DBSCAN
3.层次聚类: AGNES
4.模糊聚类:高斯混合模型
5.谱聚类
1 K-means聚类算法(K均值算法)
定义: 通过把样本分离成 n 个具有相同方差的类的方式来聚集数据,最小化称为 惯量(inertia) 或 簇内平方和(within-cluster sum-of-squares)的标准(criterion)。该算法需要指定簇的数量K。
算法:采用贪心策略通过迭代优化来近似求解

优点:速度快,简单
缺点:1.适合聚类球状类簇,不能发现一些混合度较高,非球状类簇
2.需指定簇个数
3.算法结果不稳定,最终结果跟初始点选择相关,容易陷入局部最优
4.对噪声或离群点比较敏感:无法区分出哪些是噪声或者离群点,只能给每个数据点都判断出一个类别来,这样会导致样本质心偏移,导致误判或者聚类紧密程度降低。
kmeans算法结果易受初始点影响
由于kmeans算法结果易受初始点影响,得到的结果是局部最优,为次,我们可以运行n次kmeans算法,每次运行的初始点均为随机生成。然后在n次运行结果中,选取目标函数(代价函数)最小的聚类结果。
聚类数量k如何确定?
通常在数据集有多少个聚类是不清楚的。对于低维的数据,对其可视化,我们可以通过肉眼观察到有多少个聚类,但这样并不准确,而且大部分数据也无法可视化显示。方法1:我们可以通过构建一个代价函数与聚类数量k的关系图,如下图所示,横坐标是聚类数量,每个聚类数量对应的代价函数J均是n次运行的最优结果。观察下图,代价函数随聚类数量增大而减小,但并不是说聚类数量越多越好,比如:对于m个样本,m个聚类的代价函数自然是0,但这样根本不合理。观察下图,代价函数在没有到拐点之前下降很快,拐点之后下降变缓,我们就可以考虑选择这个拐点对应的数量作为聚类数量,这是一种较为合理的方法,但受限于能否得到一个清晰的拐点,如右下图所示,

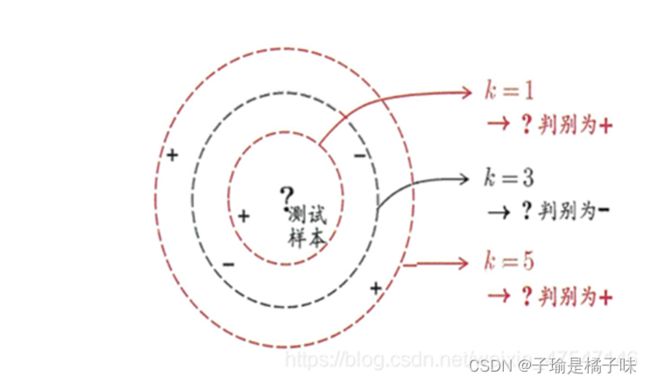
2 KNN聚类算法
算距离:给定待分类样本,计算它与已分类样本中的每个样本的距离;
找邻居:圈定与待分类样本距离最近的K个已分类样本,作为待分类样本的近邻;
做分类:根据这K个近邻中的大部分样本所属的类别来决定待分类样本该属于哪个分类;
3 DBSCAN
聚类原则:聚类距离簇边界最近的点
算法流程:
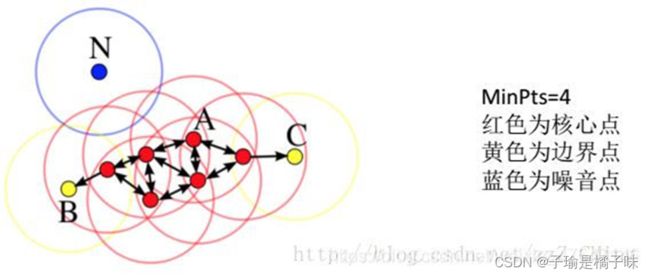
核心点:核心点的半径范围内的样本个数≥最少点数
边界点:边界点的半径范围内的样本个数小于最少点数大于0
噪声点:噪声 点的半径范围的样本个数为0
DBSCAN 算法有两个参数:半径 eps 和密度阈值 MinPts,具体步骤为:
- 1、以每一个数据点 xi 为圆心,以 eps 为半径画一个圆圈。这个圆圈被称为 xi 的 eps 邻域
- 2、对这个圆圈内包含的点进行计数。如果一个圆圈里面的点的数目超过了密度阈值 MinPts,那么将该圆圈的圆心记为核心点,又称核心对象。如果某个点的 eps 邻域内点的个数小于密度阈值但是落在核心点的邻域内,则称该点为边界点。既不是核心点也不是边界点的点,就是噪声点。
3、核心点 xi 的 eps 邻域内的所有的点,都是 xi 的直接密度直达。如果 xj 由 xi 密度直达,xk 由 xj 密度直达。。。xn 由 xk 密度直达,那么,xn 由 xi 密度可达。这个性质说明了由密度直达的传递性,可以推导出密度可达。
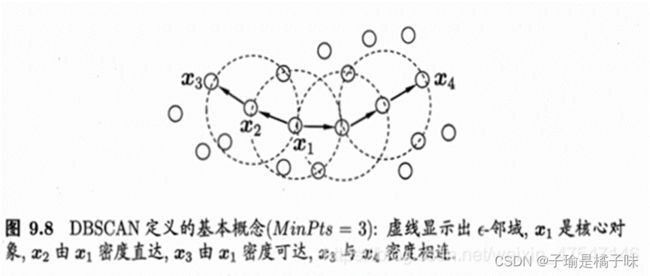
4、如果对于 xk,使 xi 和 xj 都可以由 xk 密度可达,那么,就称 xi 和 xj 密度相连。将密度相连的点连接在一起,就形成了我们的聚类簇。


4 AGNES
算法流程:
(1) 将每个对象看作一类,计算两两之间的最小距离;
(2) 将距离最小的两个类合并成一个新类;
(3) 重新计算新类与所有类之间的距离;
(4) 重复(2)、(3),直到所有类最后合并成一类

5 谱聚类算法
谱聚类是基于谱图理论基础上的一种聚类方法,与传统的聚类方法相比:
1. 具有在任意形状的样本空间上聚类并且收敛于全局最优解的优点。
2. 通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据进行聚类的目的;
其本质是将聚类问题转换为图的最优划分问题,是一种点对聚类算法。
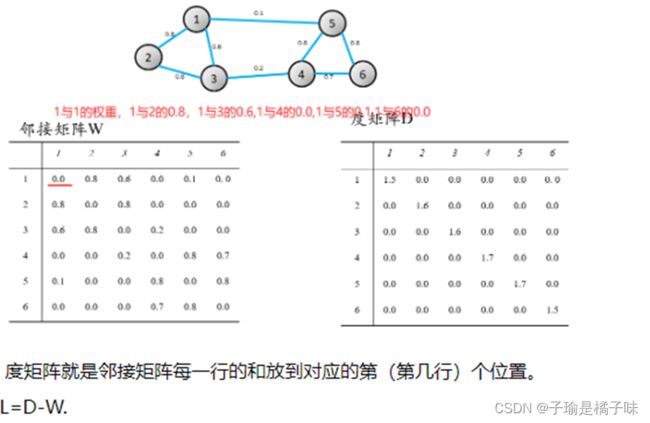
谱聚类算法将数据集中的每个对象看做图的顶点V,将顶点间的相似度量化为相应顶点连接边E的权值w,这样就构成了一-个基于相似度的无向加权图G(V,E),于是聚类问题就转换为图的划分问题。
基于图的最优划分规则就是子图内的相似度最大,子图间的相似度最小。其中,V代表所有样本的集




6 模糊聚类算法
模糊c均值聚类原理
模糊c-均值聚类算法 fuzzy c-means algorithm ( FCM)在众多模糊聚类算法中,模糊C-均值( FCM) 算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。给每个样本赋予属于每个簇的隶属度函数,通过隶属度值大小来将样本归类。
模糊c均值聚类主要有三个关键参数,固定数量的集群、每个群集一个质心、每个数据点属于最接近质心对应的簇。
(1)目标函数
模糊c均值聚类通过最小化目标函数来得到聚类中心。目标函数本质上是各个点到各个类的欧式距离的和(误差的平方和)。聚类的过程就是最小化目标函数的过程,通过反复的迭代运算,逐步降低目标函数的误差值,当目标函数收敛时,可得到最终的聚类结果。
下面是目标函数:

其中,m为聚类的簇数(类数),N 为样本数,C 为聚类中心数。cj 表示第 j 个聚类中心,和样本特征维数相同,xi 表示第 i 个样本,uij 表示样本 xi 对聚类中心 cj 的隶属度(即 xi 属于 cj 的概率)。||∗|| 可以是任意表示数据相似性(距离)的度量,最常见的就是欧几里得范数(又称欧氏范数,L2范数,欧氏距离):
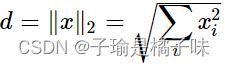
(2)隶属度矩阵Uij和簇中心Cij
隶属度矩阵应当是 N∗C 的矩阵,隶属度矩阵表示的是每个样本点属于每个类的程度。对于单个样本xi,它对于每个簇的隶属度之和为1。对于每个样本点在哪个类的隶属度最大归为哪个类。越接近于1表示隶属度越高,反之越低。
求每组的聚类中心ci,使得目标函数最小(因为目标函数与欧几里德距离有关,目标函数达到最小时,欧式距离最短,相似度最高),这保证了组内相似度最高,组间相似度最低的聚类原则。

(3)终止条件
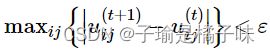
上图为终止条件,其中 t 是迭代步数,ε 是一个很小的常数表示误差阈值。也就是说迭代地更新 uij 和 cj 直到前后两次隶属度最大变化值不超过误差阈值。即继续迭代下去,隶属程度也不会发生较大的变化,认为隶属度不变了,已经达到比较优(局部最优或全局最优)状态了。这个过程最终收敛于 Jm 的局部极小值点或鞍点。
模糊c均值聚类算法步骤
(1)选择聚类中心数C,选择合适的聚类簇数m,初始化由隶属度函数确定的矩阵U0(随机值[0,1]之间初始化);
(2)计算聚类的中心值Cj;
(3)计算新的隶属度矩阵Uj
(4)比较Uj和U(j+1),如果两者的变化小于某个阈值,则停止算法,否则转向(2)。