架构学习之AArch64内存模型
本文翻译自文档Learn the architecture_aarch64 memory model
1 Overview
本指导介绍Armv8-A中的内存模型。它开始于解释描述内存的属性来自哪里以及它们是如何被赋予给内存区域。然后它介绍有效的不同属性和memory order的基础。
这些信息对任何开发底层代码的开发者有用,像启动代码或驱动。特别是对管理或建立MMU的开发者相关。
在文档的最后,你可以检查下你学到的知识。你将学习到不同的内存类型和它们的关键不同点。你将能够对Normal和Device内存类型的内存order规则进行描述。并且你能够列出给定地址的内存属性。
2 什么是内存模型以及为什么需要它
内存模型是组织和定义内存行为的方式。当你在配置地址或地址区域是如何访问或使用的,它提供了一组结构体和一组规则用来遵守。
内存模型提供了将应用到地址的属性且定义与内存访问顺序相关的规则。
考虑一个简单系统的地址空间,如下图所示:\
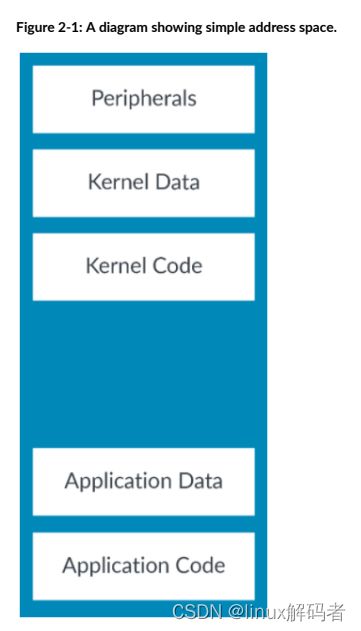
地址空间中的内存区域布局被称为地址映射。这里,映射包括:
- 内存和外设
- 在内存中的代码和数据
- OS的资源和用户应用的资源
处理器与外设交互的方式与处理器与内存交互不一样。通常你会缓存内存但你不会缓存外设。缓存是将内存中的信息的拷贝到一个位置,这被称为一个缓存。Cache更接近于core,因此对于core的访问更快。类似的,通常处理器会阻塞用户访问到内核资源。
下图描述了应用于内存区域的不同内存属性的地址映射:
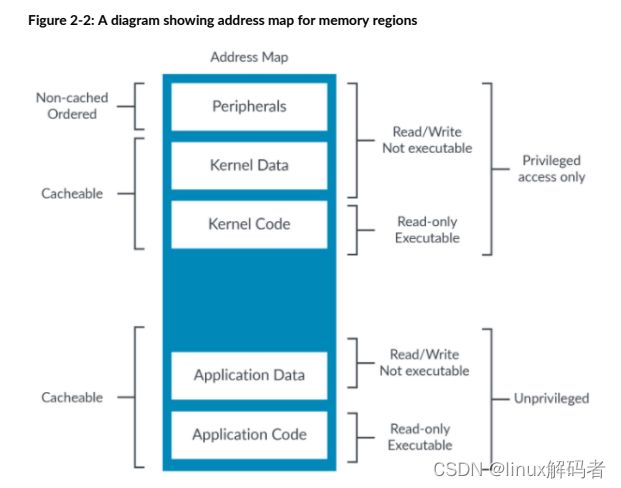
需要能够对处理器描述不同的属性,因此处理器合适的访问每个位置。
3 AArch64中描述内存
虚拟地址和物理地址之间的映射被定义在一组转换表中,通常被称为页表。对于虚拟地址的每个block或页,转换表提供了相对应的物理地址和访问该页的属性。
每个转换表项被称为block或页描述符。在大多数情况下,属性来自于这些描述符。
下图描述了一个block描述符的例子,它里面包含属性域:

重要的属性如下:
- SH:shareable属性
- AP:访问属性
- UXN和PXN:执行权限
记住这些属性,后面我们还会再分析它们。
Hierarchical属性
一些内存属性可以在更高级别的表中的table描述符中被指定。这就是hierarchical属性。这可以应用于访问权限,执行权限和物理地址空间。
如果这些位被设置,然后更低级别的表项也会被覆盖,如果这些位被清除,更低级别的表项也不会修改。使用PXNTable执行权限的例子如下:

对于Armv8.1-A,可以禁用设置访问权限和执行权限的支持,这些属性被使用table描述符中hierarchical属性。通过TCR_ELx寄存器进行控制。当禁用时,之前用于hierarchical控制的位可用于软件来作其他功能。
MMU禁用
总之,地址的属性来自于转换表。转换表位于内存中,被用于保存虚拟地址和物理地址的映射。该表也包含物理内存的属性。
可以通过MMU访问转换表。
如果MMU禁用时会发生什么呢?当在写复位后运行的代码时,这个问题对于地址非常重要。
当stage1 MMU被禁用时:
- 所有的数据访问都是Device_nGnRnE
- 所有获取的指令被当作cacheable
- 所有地址都有读写访问和执行权限
对于虚拟化覆盖的Exception level,当stage2被禁止时,stage1的属性不会修改。
4内存访问序
在Armv8-A指令组架构中,我们介绍了简单时序执行SSE。SSE是指令序的概念模型。内存访问序和指令序两者不同,但相关。理解两者的区别非常重要。
SSE描述了处理器执行指令的顺序。总之,现代处理器存在较长且复杂的流水线。这些流水线通常可以重排指令或并行的执行多个指令来实现最大的性能。SSE意味着处理器必须像在一个时刻只执行一条指令,以程序代码中的顺序。这意味着硬件的任何指令的重排或多个发送必须对软件不可见。
内存序是内存系统中内存访问的顺序。因为一些机制如write-buffer和cache,即使当指令顺序访问时,相关的内存访问访问可能不会顺序访问。这就是为什么即使处理器遵守SSE模型内存序仍十分重要。
5 内存类型
系统中没有被标记为fault的所有地址被赋予一个内存类型。内存类型是处理器是如何与地址区域交互的高层描述。在Armv8-A中存在两个内存类型:Normal内存和Device内存。
6 Normal内存
Normal内存类型用于内存的行为,包括RAM,Flash,或ROM。代码应该被放置于Normal内存的位置。
在系统中Normal内存为使用最广泛的内存,如下图所示:

访问顺序
通常计算机处理器以指令在程序中的位置顺序执行指令。事件以程序中指定的次数产生,且每次产生一个。这被称为简单时序执行模型SSE。大多数现代处理器可能会遵守该模型,但在现实中会进行一些优化来提升性能。我们这里将介绍一些优化。
当Normal内存被访问时不会有直接副作用。这意味着读该内存仅返回数据,而不会造成数据修改或直接触发另一个处理。因为这些原因,对于Normal内存,处理器可能:
- 访问合并。代码可能访问某个内存多次,或访问多个连续的内存。为了效率,允许处理器检测并合并这些访问到一个访问中。比如,如果软件写某个变量多次,处理器可能仅将最后一次写放到内存中。
- 预测访问。允许处理器读取Normal内存,而不专门需要软件进行请求。比如,处理器可能在软件请求数据之前通过模式识别预取数据,基于之前访问的模式。该技术通过预测行为来加速访问。
- 重排访问。内存系统中访问的顺序可能与软件发送的访问顺序并不相同。比如,处理器可能重排两个读以允许它产生一个更有效率的总线访问。访问同一个位置不能被重排但可以合并。考虑这些优化,允许处理器采用技术来加速性能和改进电源效率。这意味着Normal内存类型通常能够给出最优性能。
重排的限制
总之,Normal内存可以被重排。让我们来考虑三个内存访问的时序,两个store和一个load:

如果处理需要重排这些访问,可能会导致内存中出现错误的值,这是不允许的。
对于访问相同的byte,必须维持顺序。处理器需要检测危险并保证正常的期预期结果。
这并不意味着在这个例子中没有优化的可能。处理器可能合并两个store,将合并的store放入到内存系统中。它也可以检测到load操作来自于store指令写的byte,因此它返回新的值而不需要从内存中重读。
还有其他强制命令的情况,比如地址依赖。一个地址依赖为load或store使用之前load的结果作为地址。在这个代码例子中,第二个指令依赖于第一个指令的结果:

这个例子也呈现了一个地址依赖,第二个指令依赖于第一个指令结果。

当在两个内存访问时存在地址依赖时,处理器必须维持这个顺序。
该规则不应用于控制依赖。一个控制依赖为之前load的值用于作决定。下面代码显示了一个load后跟随Compare和Branch的Zero操作,它依赖于load的值:

存在在Normal内存之间访问或访问Normal和Device内存之间需要强制顺序的情况。可以通过barrier指令完成。
7 Device内存
Device内存类型用于描述外设。外设寄存器通常被提及为MMIO。这里我们可以看到在地址映射中被标记为Device。

通常Normal内存类型意味着访问时没有副作用。对于Device类型内存则相反。Devcie内存类型用于有副作用的内存。
比如,读取FIFO通常会导致它前进到下一个数据片。这意味着对FIFO的一些访问非常重要,因此处理器必须遵守程序指定的内容。
Device区域不会cacheable。这是你不太希望缓存对外设的访问。
预测数据访问也不允许对Device区域。处理器只有在架构访问时才访问这些位置。这意味着在架构上执行的指令可以访问这些区域。
指令不能放置于Device区域。我们建议Device区域通常被认为不可执行的。否则,处理器可能预取指令,这会导致对读敏感的设备如FIFO出问题。
设备的子类
这里有四个Device子类,它们有不同的限制。这些子类为:
- Device_GRE
- Device_nGRE
- Device_nGnRE
- Device_nGnRnE
Device后面的字母代表着属性的联合:
- G=Gathering指定访问是否可以合并。可以将对相同位置的多个访问合并到一次访问或合并多个小的访问合并成一个大的访问。
- R=Re-ordering指定对相同的外设的访问是否可以重排。当重排被允许时,如Normal类型一样存在相同的限制。
- E=Early Write Acknowlegement决定何时写被认为完成。如果允许E,一旦该访问被其他观察者看到该访问被认为完成,其实它没有到目的地。比如,一旦写在总线上到达write buffer上,该写变成可见。当不允许E时,写必须到达目的地。
这里有两个例子:
- Device_GRE。它允许合并,重排,以及早期写响应。
- Device_nGnRnE。它不允许合并,不允许重排,不允许早期写响应。
我们已经知道重排是如何工作的,但我们没有介绍合并或早期写响应。Gathering允许对相同的位置内存访问被合并到单个总线事务,优化了访问。早期写响应表明内存系统中的buffer在总线上任何点都可以发送写响应。
对于每种类型处理需要处理不同么?
内存类型描述了对某个内存一组允许的行为。例如Device类型,下图表明允许的行为:
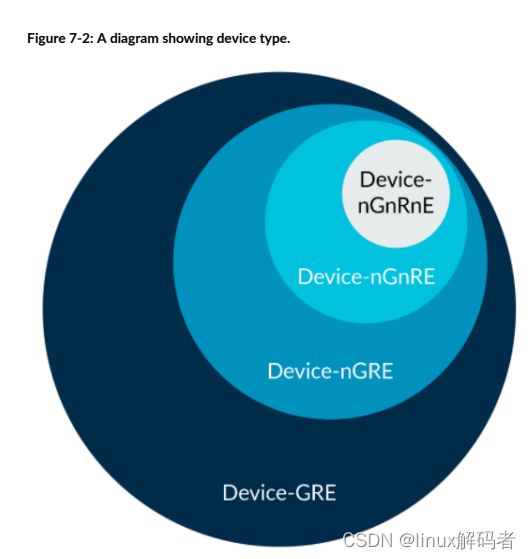
你可以看到Device_nGnRnE为限制最多的子类,也具有最少允许的行为。Device_GRE为限制最少的子类,因此有最多允许的行为。
特别是,Device_nGnRnE允许的所有行为也可以被Device_GRE允许。比如,对于Device_GRE内存,使用Gathering并不是需求,它是被允许的。因此,允许处理器将Device_GRE当作Device_nGnRnE。
对于ARM Cortex-A处理器,这个例子比较极端且不太可能发生。但是处理器不去区分所有的类型和子类型也是常见的,比如将Device_GRE和Device_nGRE当作相同。如果类型或子类通常有更多限制,这是被允许的。
8 描述内存类型
内存类型不直接编码进转换表项。相反,转换表项中的index域用来从MAIR_ELx(内存属性间接寄存器)从选择表项。

选择的域决定了内存类型和cacheability信息。
为什么寄存器使用index,而不是将内存类型直接编码入转换表项中?因为转换表项中的位数受限制。它要求8位来编码内存类型,但仅用3位来编码MAIR_ELx的index。它允许架构有效的使用表项中更少位。
9 Cacheability和shareability属性
标记为Normal的内存也有cacheability和shareability属性。这些属性控制该内存是否可以被缓存。如果内存被缓存,这些属性控制哪个其他agent需要查看内存的一致性拷贝。它也允许复杂的配置,这超过了本文档的范围。
你可以了解更多cacheability和shareability。
10 权限属性
AP访问权限属性控制是否内存可以读或写,以及需要什么特权级。下表呈示了AP位的设置:

如果访问破坏指定的权限,比如对只读区域进行写,会产生异常(也称为权限fault)。
特权级访问非特权数据
标准的权限模型为一个更高特权entity可以访问属于更低特权entity的任何内容。另一种方法解释,OS可以看到应用分配的所有资源。比如,hypervisor可以看到分配给虚拟机的所有资源。这是因为执行在更高异常级别意味着特权级别也更高。
但是,这也并不是总是可取的。恶意的应用可能尝试代表OS访问数据,而这些数据它本不应该看到。这就要求OS在系统调用检查指针。
ARM架构提供了多种控制让这更简单。首先,存在PSTATE.PAN(Privileged Access Never)位。当该位被设置时,从EL1到非特权区域的load和store将产生异常(权限fault),如下图所示:

PAN允许对非特权数据的意外访问被trap。比如,OS发出访问认为目的地是特权的。实际上,目的地是非特权的。这意味着OS的期望与实际是不一致的。它的产生可能是由于编程错误,或系统中攻击。无论哪种情况,PAN允许在错误产生之前捕获该访问,并保证安全操作。
有时OS需要访问非特性区域,比如,写应用的buffer。为了支持它,指令组提供了LDTR和STTR指令。
LDTR和STTR为非特权load和store。即使被EL1或EL2的OS执行,根据EL0权限对其进行检查。因为存在明确的非权限访问,它们不会被PAN阻塞,如下图所示:

这允许OS能够区分试图访问特权数据的访问和被期望访问非特权数据的访问。它也允许硬件使用该信息检查访问。
执行权限
除了访问权限,也还有执行权限。这些属性让你指定指令不能从地址获取指令:
- UXN。User Execute Never
- PXN。Privileged Execute Never
存在Execute Never位。这意味着设置该位将使内存不可执行。
存在分开的特权和非特权位,因为应用代码需要在EL0执行,但不会在内核权限EL1/EL2执行,如下图所示:

架构也在SCTLR_ELx提供控制位将所有可写地址非执行。
EL0内存的写权限在EL1不会被执行。
11 访问标志
你可以使用AF访问标志来跟踪转换表所指向的区域是否被访问。你可以设置AF标志:
- AF=0表示该区域没有被访问
- AF=1表示该区域被访问
AF标志对操作系统非常有用,因为你可以使用它来区分哪个页当前没有被使用且可以将其page-out。
更新AF位
当AF位被使用时,创建转换表时会初始化清AF位。当一个页被访问时,它的AF位被设置。软件可以分析转换表检查AF位是否被设置或清除。AF=0的页没有被访问,是被paged-out的更好的选择。
在访问时有两种方式来设置AF位:
- 软件更新:访问页会导致一个同步异常(Access Flag Fault)。在异常处理中,软件负责对相关软件表中的AF位进行设置;
- 硬件更新:访问页会导致硬件自动设置AF位而不需要产生异常。该行为在Armv8.1-A中被使能和添加。
dirty状态
Armv8.1-A引入了处理器管理block页或page页的dirty状态的能力。Dirty状态记录该block或page页是否被写。这非常有用,因为如果block或page页被paged-out,dirty状态告诉管理软件RAM的内容是否需要写入到存储设备中。
比如,让我们考虑一个text文件。初始化时文件从disk加载到RAM中。当后面它被从内存中移除时,OS需要知道RAM中的内容是否比disk中的内容更新。如果RAM中的内容更新,disk中的内容需要被更新。如果不是,RAM中的内容可以放弃。
当使能管理dirty状态时,软件初始化时创建访问权限为只读的转换表项且设置DBM位。如果该页被写,硬件自动更新访问权限为读写。
设置DBM位为1会修改访问权限位(AP[2]和S2AP[1])的功能,因此它们记录dirty状态替换记录访问权限。这意味着当DBM位被设置为1时,访问权限位不会导致访问fault。
12 对齐和大小端
本节介绍对齐和大小端。
对齐
如果地址为element大小的多倍,该访问是对齐的。
对于LDR和STR指令,element大小为访问的大小。比如,一个LDRH指令加载一个16位值,必须来自一个16位倍数的地址,才能被当作对齐。
LDP和STP指令load和store一组element。为了对齐,地址必须为element大小的倍数,而不是两个element的联合大小。比如
LDP X0, X1, [X2]
例子中加载两个64位值,因此总共128位。X2的地址需要为64位的倍数,这被称为对齐。
相同的规则也被应用于vector load和store。
当地址不为element大小的倍数,访问为不对齐。不对齐的访问允许访问normal内存,但不允许访问Device区域。对Device区域的不对齐访问将触发异常(alignment fault)。
对Normal区域不对齐的访问可以通过设置SCTLR_ELx.A被捕捉。如果该位被设置,对Normal区域的不对齐访问也会产生对齐错误。
大小端
在Armv8-A中,获取的指令通常被当作小端。
对于数据访问,由实现决定是否小端和大端被支持。如果仅其中一个被支持,由实现决定哪个被支持。
对于支持大端和小端的处理器,大小端对每个exception level配置。
Arm Cortex-A处理器即支持大端也支持小端。
13 内存别名和不匹配内存类型
当物理地址空间的一个给定位置有多个虚拟地址,这称为别名。
属性是基于虚拟地址的。这是因为属性来自于转换表。当一个物理位置存在多个别名,虚拟别名有兼容的属性非常重要。我们描述兼容如下:
- 相同的内存类型,对于Device类型有相同的子类
- 对于Normal内存,相同的cacheability和shareability
如果属性不兼容,内存访问可能不会像你期望的那样,它会影响性能。
下图描述了别名的两个例子。内存A的两个别名存在兼容的属性。这是推荐的方法。内存B的两个别名的属性不兼容,它会影响到一致性和性能。

Arm强烈推荐软件不要将不兼容的属性赋予相同位置的不同别名。
14 stage1和stage2属性的联合
当使用虚拟化时,一个虚拟地址会经历转换的两个stage。一个stage是由OS控制,一个stage是由hypervisor控制。两者都包含属性,它们是如何联合的?
下图呈示了一个例子,stage1中一块内存被标记为Device,但相对应的stage2中被标记为Normal。它的最终结果类型是什么?
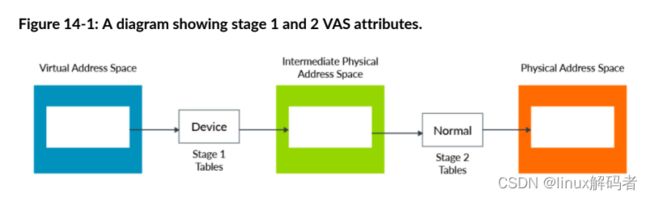
在Arm架构中,默认使用受限最多的类型。在这个例子中,Device类型比Normal类型更受限。因此最终的类型为Device。
对于类型和cacheability,额外的控制HCR_EL2.FWB允许这个行为被覆盖。当FWB被设置,stage2可以覆盖stage1类型和cacheability设置,而不是使用联合行为。
错误处理
让我们来看下图中两个例子:
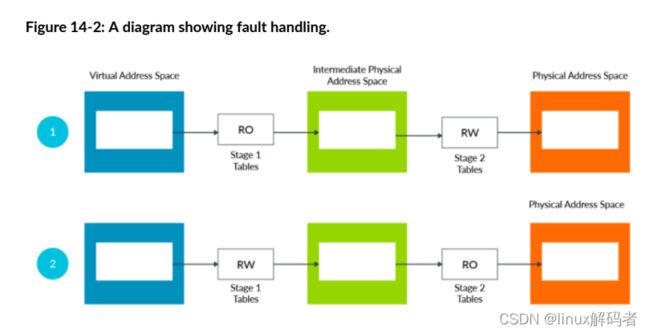
在上面两个例子中,最终属性为RO即只读。如果软件想写该位置,错误permission fault将会产生。但在第一个例子中会产生stage1 fault,而第二个例子中会产生stage2 fault。在这个例子中,stage1的错误会走到EL1的OS,但stage2的错误会走到EL2并由hypervisor处理。
最后,我们看个stage1和stage2属性相同的例子:

这里,最后的属性是RO。但是如果软件想写这个内存,stage1和stage2错误会产生么?答案是stage1会产生。如果stage1和stage2产生不同错误类型,这个答案也是一样。Stage1错误通常会优先于stage2的错误。