改进YOLOv5系列:9.BoTNet Transformer结构的修改
YOLOAir:助力YOLO论文改进 、 不同数据集涨点、创新点改进

- YOLOAir项目:基于 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 本项目包含大量的改进方式,降低改进难度,改进点包含
Backbone、Neck、Head、注意力机制、IoU损失函数、NMS、Loss计算方式、自注意力机制、数据增强部分、激活函数等部分,详情可以关注 YOLOAir 的说明文档。 - 同时
附带各种改进点原理及对应的代码改进方式教程,用户可根据自身情况快速排列组合,在不同的数据集上实验, 应用组合写论文, 创造自己的毕业项目!
本篇是《BoTNet Transformer结构》的修改 演示
使用YOLOv5网络作为示范,可以无缝加入到 YOLOv7、YOLOX、YOLOR、YOLOv4、Scaled_YOLOv4、YOLOv3等一系列YOLO算法模块
文章目录
-
- YOLOAir:助力YOLO论文改进 、 不同数据集涨点、创新点改进
- BoTNet理论部分
- YOLOv5添加BoT的yaml配置文件修改
- common.py配置
- yolo.py配置修改
- 训练yolov5s_botnet.yaml模型
- 基于以上yolov5s_botnet.yaml文件继续修改
BoTNet理论部分
论文:Bottleneck Transformers for Visual Recognition
论文地址:arxiv
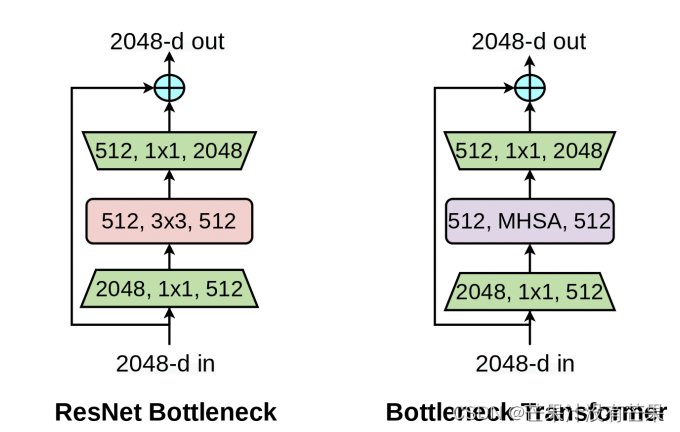
YOLOv5添加BoT的yaml配置文件修改
增加以下yolov5s_botnet.yaml文件
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args] # [c=channels,module,kernlsize,strides]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPPF, [1024,5]],
[-1, 3, BoT3, [1024]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium) [256, 256, 1, False]
[-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2]
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large) [512, 512, 1, False]
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
common.py配置
./models/common.py文件增加以下模块
class BottleneckTransformer(nn.Module):
# Transformer bottleneck
#expansion = 1
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None,expansion=1):
super(BottleneckTransformer, self).__init__()
c_=int(c2*expansion)
self.cv1 = Conv(c1, c_, 1,1)
#self.bn1 = nn.BatchNorm2d(c2)
if not mhsa:
self.cv2 = Conv(c_,c2, 3, 1)
else:
self.cv2 = nn.ModuleList()
self.cv2.append(MHSA(c2, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.cv2.append(nn.AvgPool2d(2, 2))
self.cv2 = nn.Sequential(*self.cv2)
self.shortcut = c1==c2
if stride != 1 or c1 != expansion*c2:
self.shortcut = nn.Sequential(
nn.Conv2d(c1, expansion*c2, kernel_size=1, stride=stride),
nn.BatchNorm2d(expansion*c2)
)
self.fc1 = nn.Linear(c2, c2)
def forward(self, x):
out=x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x))
return out
class BoT3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1,e=0.5,e2=1,w=20,h=20): # ch_in, ch_out, number, , expansion,w,h
super(BoT3, self).__init__()
c_ = int(c2*e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[BottleneckTransformer(c_ ,c_, stride=1, heads=4,mhsa=True,resolution=(w,h),expansion=e2) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
yolo.py配置修改
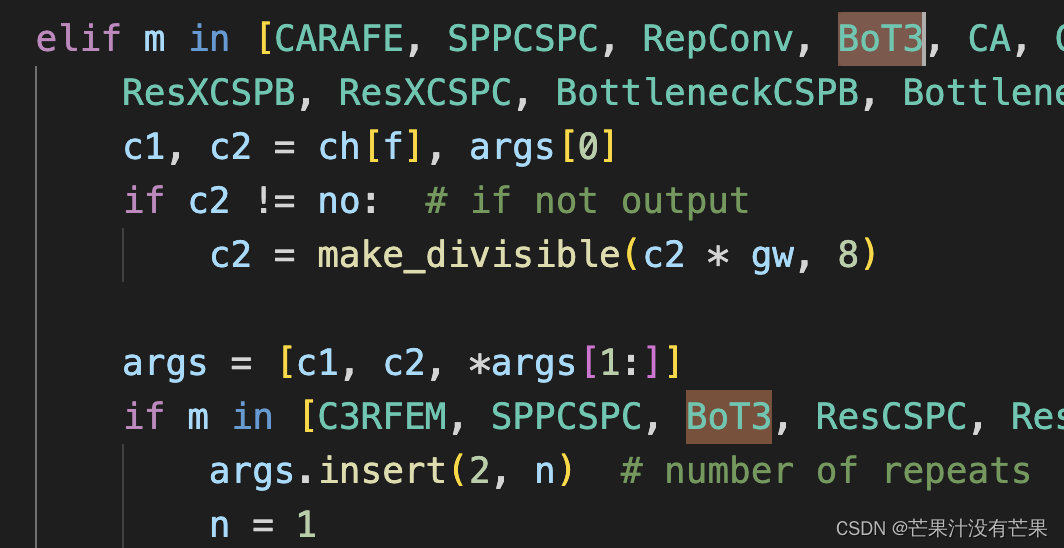
然后找到./models/yolo.py文件下里的parse_model函数,将加入的模块名BoT3加入进去
在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要增加
BoT3模块
参考示意图
训练yolov5s_botnet.yaml模型
python train.py --cfg yolov5s_botnet.yaml
基于以上yolov5s_botnet.yaml文件继续修改
关于yolov5s_botnet.yaml文件配置中的BoT3模块里面的self-attention模块,可以针对不同数据集自行再进行模块修改,原理一致