一文入门Python基础
Python基础
python中的输出函数
print()函数- 可以输出的内容
- 数字
- 字符串
- 含有运算符的表达式(会返回表达式计算的结果)
- 内容输出的目的地
- 显示器
- 文件
# 将数据输入文件中,注意点——所指的盘必须存在——使用file=fp fp = open('路径','模式') print('hello',file = fp) fp.close - 输出形式
- 换行
- 不换行
print('word','hh')
- 可以输出的内容
转义字符
为什么需要转义字符?
- 当字符串中包含反斜杠、单引号和双引号等有特殊用途的字符时,必须使用反斜杠对这些字符进行转义(转换一个含义)
- 反斜杠:\
- 单引号:’
- 双引号:"
- 当字符串中包含换行、回车,水平制表符或退格等无法直接表示的特殊字符时,也可以使用转义字符当字符串中包含换行.回车,水平制表符或退格等无法直接表示的特殊字符时,也可以使用转义字符
- 换行:\n
- 回车:\r
- 水平制表符:\t
- 退格:\b
变量的定义和使用
变量是内存中一个带标签的盒子
变量由三部分组成
- 标识:表示对象所存储的内存地址,使用内置函数id(obj)来获取
- 类型:表示的是对象的数据类型,使用内置函数type(obj)来获取
- 值:表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出
数据类型
-
常用类型
- 整数类型 -> int -> 98
- 浮点数类型 -> float -> 3.14
- 布尔类型 -> bool -> True Flase
- 字符串类型 -> str -> ‘ssss’
-
整数类型
- 可正 可负 可为0
- 十进制-默认
- 二进制-以0b开头
- 八进制-以0o开头
- 十六进制-以0x开头
-
浮点类型
- 由整数部分和小数部分组成
- 浮点数存储不精确
- 解决方案(导入decimal)
from decimal from Decimal print(Decimal('1.1')+Decimal('2.2'))
-
布尔类型
- 可转化为整数 True->1 False->0
-
字符串
- 可以用单引号’'双引号""三引号
- 单引号、双引号的字符串必须在同一行
- 三引号的字符串可以分布在连续多行 类似JavaScript的``
数据类型转换
- str()
- 将其他数据类型转成字符串
- 也可以用引号转换
- int()
- 将其他数据类型转成整数
- 文字类和小数类字符串无法转换为整数
- 浮点数转换为整数:抹零取整
- float()
- 将其他数据类型转化为浮点数
- 文字类型无法转化成整数
- 整数转浮点数:末尾补.0
注释
在代码中对代码的功能进行解释说明的标注性文字,可以提高代码的可读性
注释的内容会被Python解释器忽略·通常包括三种类型的注释
- 单行注释→以"#"开头,直到换行结束
- 多行注释→并没有单独的多行注释标记,将一对三引号之间的代码称为多行注释
- 中文编码声明注释→在文件并头加上中文声明注释,用以指定源码文件的编码格式
输入函数 input
input函数
- 作用->接收来自用户的输入
- 返回值类型->输入值的类型为str
- 值的存储->使用=对输入值进行存储
运算符
- 算数运算符
- 标准运算符 (±*/ //整除是一正一反向下取整)
- 取余运算符 (%)一正一反要遵循 余数=被除数-除数*商
- 幂运算符(**)
- 赋值运算符
- 支持链式赋值a=b=0 注意链式赋值时的变量们的地址会相同
- 支持参数赋值 += -= *=
- 支持系列解包赋值 a,b,c = 20,30,40
- 当内存中有相同的基础类型值时,会直接将该值的地址赋给新的变量,使得两个相同的值的变量地址相同。而引用类型的值会重新指向一个新的内存地址
- 比较运算符
- is 用于判断地址id是否相同 == 用于判断值是否相同
- 布尔运算符
- and
- not
- or
- 位运算符
- 位与 &
- 位或 |
- 左移位运算符<< -> 高位溢出舍弃,低位补0
- 右移位运算符>> -> 低位溢出舍弃,高位补0
优先级:** *///% ± <<>> & | ><>=<===!= and or =
对象的布尔值
python一切皆对象
- False
- 数值0
- None
- 空字符串
- 空列表[] list()
- 空元组() tuple()
- 空字典 {} dict()
- 空集合 set()
以上皆为false,其他对象的布尔值均为true
分支结构
if a>b:
a = b-2
elif a==b:
a = c
else:
if a==b:
print(1)
else:
条件表达式
语句 if 条件 else 语句
类似JavaScript的三元运算符
pass语句
该语句什么都不做,只是一个占位符,用在语法上需要语句的地方
常用于还没想好代码怎么写 先搭建语法结构
range()函数
range为一个内置函数
- 用于生成一个整数序列
- 创建range对象有三种方式
# 第一种创建方式 range(stop)
r = range(10)
print(r) # range(0,10)
print(list(r)) # [0,1,2,3,4,5,6,7,8.9]
# 第二种创建方式 range(start,stop)
r = range(1,10)
print(list(r)) # [1,2,3,4,5,6,7,8.9]
# 第三种创建方式 range(start,stop,step)
r = range(1,10,2)
print(list(r)) # [1,3,5,7,9]
- 返回值是一个对象
- range类型的优点:不管range对象表示的整数序列有多长,所有range对象占用的内存空间都是相同的,因为仅仅需要存储start,stop和step,只有当用到range对象时,才会去计算序列中的相关元素
- in与not in判断整数序列中是否存在(不存在)指定的整数
循环结构
while 条件:
执行体
for 自定义变量 in 可迭代对象:
循环体
else:
# 没有遇到break的时候会执行else
列表
- 变量可以存储一个元素,而列表是一个“大容器”可以存储N多个元素,程序可以方便地对这些数据进行整体操作
- 列表相当于其他语言中的数组
#创建列表的第一种方式 使用[]
lst = ['sss','fsdf']
#创建列表的第二方式,使用内置函数list()
lst = list(['ss','gg'])
列表的特点
- 列表元素按顺序有序排列
- 索引映射唯一数据
- 列表可以存储重复数据
- 任意数据类型混存
- 根据需要动态分配和回收内存
列表的查询操作
- 获取列表中指定元素的索引 index(‘元素’,‘起始位置’,‘终止位置’)
- 获取列表中的单个元素
- 判断指定元素在列表中是否存在
元素 in 列表名元素 not in 列表名 - 元素遍历
for 变量 in 列表名
列表的切片操作
lst = ['sss','fsdf']
lst['起始','结束','步长']
列表元素的增删改
- 增加
append()在列表末尾添加一个元素extend()在列表的末尾至少添加一个元素insert()在列表的任意位置添加一个元素- 切片 在列表的任意位置添加至少一个元素
- 删除
remove()一次删除一个元素,重复元素只删第一个,元素不存在就报错pop()删除一个指定索引上的元素- 切片 一次至少删除一个元素
clear()清空del删除列表
- 修改
- 为指定索引的元素赋予一个新值
- 为指定的切片赋予一个新值
列表的排序操作
- 调用sort()方法,列有中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse=True,进行降序排序
- 调用内置函数sorted(),可以指定reverse=True,进行降序排序,原列表不发生改变
列表生成式
lst = [i*i for i in range(1,10)]
字典
- Python内置的数据结构之一,与列表一样是一个可变序列
- 以键值对的方式存储数据,字典是一个无序的序列
- 字典的实现原理与查字典类似,查字典是先根据部首或拼音查立的页码,Python中的字典是根据key查找value所在的位置
字典的创建方式
# 第一种方法 花括号
scores = {'张三':100,'李四':98,'王五':45}
# 第二种方法 内置函数dict()
dict(name='jack',age=30)
字典元素的获取
# 方法一 []
scores['张三']
# 方法二 get()
scores.get('张三')
# 如果没有 则可以返回默认值
scores.get('hh',99)
- 取值与使用get()取值的区别
- 如果字典中不存在指定的key,抛出keyError异常
- get()方法取值,如果字典中不存在指定的key,并不会抛出KeyError而是返回None,可以通过参数设置默认的value,以便指定的key不存在时返回
字典常用操作
- key的判断
'张三' in scores
'hh' not in scores
- 删除
del scores['张三']
- 新增
scores['jack'] = 90
字典视图的三个方法
- keys() 获取字典中所有key
- values() 获取字典中的所有values
- items() 获取字典中所有key,value对
字典的遍历
for item in scores:
print(item)
字典的特点
- 字典中的所有元素都是一个 key-value对, key不允许重复, value可以重复
- 字典中的元素是无序的
- 字典中的key必须是不可变对象·字典也可以根据需要动态地伸缩
- 字典会浪费较大的内存,是一种使用空间换时间的数据结构
元组
Python内置的数据结构之一,是一个不可变序列
不可变序列 与 可变序列
- 不变可变序:字符串、元组(没有增、删、改的操作)
- 可变序列:列表、字典(可以增删改操作,对象地址不发生改变)
元组的创建
# 第一种 直接小括号
t = ('python','hello',90)
# 第二种 内置函数
t = tuple(('python','hello',90))
# 第三种 只包含一个元组的元素需要使用逗号和小括号
t = (10,)
为什么要将元组设计成不可变序列
- 在多任务环境下,同时操作对象时不需要加锁·因此,在程序中尽量使用不可变序列
- 注意事项:元组中存储的是对象的引用
- 如果元组中对象本身不可对象,则不能再引用其它对象
- 如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变
元组的遍历
元组是可迭代对象
for...in...
集合
- python语言提供的内置数据结构
- 与列表、字典一样都属于可变类型的序列
- 集合是没有value的字典
集合的创建方式
# 第一种 直接{}
s = { 'Python','hello',90 }
# 第二种 内置函数set()
s = set(range(6))
集合中的元素不允许重复,重复的会自动舍去
集合的相关操作
- 集合元素的判断操作
-in或not in - 集合元素的新增操作
- 调用add()方法,一次添中一个元素
- 调用update()方法至少添中一个元素
- 集合元素的删除操作
- 调用remove()方法,一次删除一个指定元素,如果指定的元素不存在抛KeyError
- 调用discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛异常
- 调用pop()方法,一次只删除一个任意元素
- 调用clear()方法,清空集合
集合间的关系
- 两个集合是否相等
-可以使用运算符==或!=进行判断 - 一个集合是否是另一个集合的子集
- 可以调用方法issubset()进行判断
- B是A的子集
- 一个集合是否是另一个集合的超集
- 可以调用方法issuperset()进行判断
- A是B的超集
- 两个集合是否没有交集
- 可以调用方法isdisjoint()进行判断
集合的数学关系
- 交集 s1 & s2
- 并集 s1.union(s2) s1|s2
- 差集 s1.difference(s2) s1-s2
- 对称差集 s1.symmetric_difference(s2) s1^s2
字符串
在Python种字符串是基本数据类型,是一个不可变的字符串序列
字符串的驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中, Python的驻留机制对相同的字符串只保留―份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
- 驻留机制的几种情况(交互模式)
- 字符串的长度为0或1时
- 符合标识符的字符串
- 字符串只在编译时进行驻留,而非运行时
- [-5,256]之间的整数数字
- sys中的intern方法强制2个字符串指向同一个对象
- PyCharm对字符串进行了优化处理
字符串的常用操作
-
查找
- index() 查找字符串substr第一次出现的位置,如果查找的子串不存在时,报错
- rindex() 查找字符串substr最后一次出现的位置,如果查找的子串不存在时,报错
- find() 查找子串substr第一次出现的位置,如果查找的子串不存在时,返回-1
- rfind() 查找子串substr最后一次出现的位置,如果查找的子串不存在时,返回-1
-
大小写转换
- upper() 把字符串中所有字符串都转化成大写字母
- lower() 把字符串中所有字符串都转化成小写字母
- swapcase() 把字符串中所有大写字母转成小写字母,把所有小写字母都转化成大写字母
- capitalize() 把第一个字符转化成大写,把其余字符转化为小写
- title() 把每一个单词的第一个字符转化为大写,把每个单词的剩余字符转化为小写
-
内容对齐
- center() 居中对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则则返回原字符串
- ljust() 左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于实际宽度则则返回原字符串
- rjust() 右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于实际宽度则则返回原字符串
- zfill() 右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身
-
劈分操作
- split()
- 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表
- 以通过参数sep指定劈分字符串是的劈分符
- 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独做为一部分
- rsplit()
- 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表
- 以通过参数sep指定劈分字符串是的劈分符
- 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独做为一部分
- split()
-
判断操作
- isidentifier() 判断指定的字符串是不是合法的标识符
- isspace() 判断指定的字符串是否全部由空白字符组成(回车、换行,水平制表符)
- isalpha() 判断指定的字符串是否全部由字母组成
- isdecimal() 判断指定字符串是否全部由十进制的数字组成
- isnumeric() 判断指定的字符串是否全部由数字组成
- isalnum() 判断指定字符串是否全部由字母和数字组成
-
其他操作
- replace() 第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数
- join() 将列表或元组中的字符串合并成一个字符串
-
字符串的比较操作
- 运算符:>,>=,<,<=,==,!=
- 比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
- 比较原理:两上字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符
-
字符串的切片
- 字符串是不可变类型
- 不具备增删改等操作
- 切片操作将产生新的对象
# [start:stop:step] 包括start不包括stop, 没有start和stop就是从0到最后一个元素 s = 'hello' s[1:5:1] - 字符串是不可变类型
-
格式化字符串
# 方式一 %
name = '张三'
age = 18
print('我叫%s' % (name))
# %10.3f 宽度为10,最多三位小数
# 方式二 {}
print('我叫{0},今年{1},我叫{0}'.format(name,age))
# {0:.3}表示第0个 一共三位数
# {0:10.3f} 宽度为10,最多三位小数
# 方法三 f模式
print(f'我叫{name},今年{age}')
- 字符串的编码转换
- 编码: 将字符串转换二维码数据(bytes)
- 解码:将bytes类型的数据转换成字符串类型
# 编码
s = '哈哈哈哈'
print(s.encode(encoding='GBK')) # 在GBK这种编码格中 一个中文占两个字节
print(s.encode(encoding='UTF-8')) # 在UTF-8这种编码格式中,一个中文占三个字节
# 解码
byte = s.encode(encoding='GBK')
print(byte.decode(encoding='GBK'))
# 编码和解码的格式一定要相同
函数
什么是函数? 函数是执行特定任和以完成特定功能的一段代码
为什么需要函数? 1、复用代码 2、隐藏实现细节 3、提高可维护性 4、提高可读性便于调试
函数的创建
def 函数名 ([输入参数]):
函数体
[return xxx]
def calc(a,b=10): # 默认参数
c = a+b
return c
resultA = calc(10,20) # 位置传参
resultB = calc(b=10,a=20) # 关键字传参
print(resultA,resultB)
函数参数传递的内存分析
def fun(arg1,arg2):
print(arg1)
print(arg2)
arg1 = 100
arg2.append(10)
print(arg1)
print(arg2)
n1 = 11
n2 = [22,33,44]
fun(n1,n2)
'''在函数调用过程中,进行参数的传递
如果是不可变对象,在函数体的修改不会影响实参的值arg1的修改为100,不会影响n1的值
如果是可变对象,在函数体的的修改会影响到实参的值arg2的修改,append(10),会影响到n2的值
'''
函数的返回值
- 如果函数没有返回值【函数执行完毕之后,不需要给调用处提供数据】return可以省略不写
- 函数的返回值,如果是1个,直接返回类型
- 函数的返回值,如果是多个,返回的结果为元组
可变参数
- 个数可变的位置参数
- 定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
- 使用*定义个数可变的位置形成
- 结果为一个元组
- 个数可变的关键字形参
- 定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
- 使用**定义个数可变的关键字形参
- 结果为一个字典
def calculate_sum(*arg,**kwargs):
s = 0
for i in args:
s += i
print(s)
for k , v in kwargs.items():
print(k,v)
变量作用域
- 局部变量
- 在函数内定义并使用的变量,只在函数内部有效,局部变量使用
global声明,这个变量就会就成全局变量
- 在函数内定义并使用的变量,只在函数内部有效,局部变量使用
- 全局变量
- 函数体外定义的变量,可作用于函数内外
递归函数
- 什么是递归函数
- 如果在一个函数的函数体内调用了该函数本身,这个函数就称为递归函数
- 递归的组成部分
- 递归调用与递归终止条件
- 递归的调用过程
- 每递归调用一次函数,都会在栈内存分配一个栈帧,
- 每执行完一次函数,都会释放相应的空间
- 递归的优缺点
- 缺点:占用内存多,效率低下
- 优点:思路和代码简单
def fib(n)
if n == 1:
return 1
elif n == 2:
return 1
else :
retrun fib(n-1)+fib(n-2)
Lambda表达式
Lambda表达式 又称为 匿名函数
- 程序只执行一次,不需要定义函数名
- 在某些函数中必须以函数作为参数,但函数本身十分简单而且只在一处使用
上述情况可用匿名函数
匿名函数的用法有点像js中的回调函数的箭头函数
高阶函数
map
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
f(x) = x * x
│
│
┌───┬───┬───┬───┼───┬───┬───┬───┐
│ │ │ │ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼
[ 1 2 3 4 5 6 7 8 9 ]
│ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼
[ 1 4 9 16 25 36 49 64 81 ]
现在,我们用Python代码实现:
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
list(r)
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
把这个list所有数字转为字符串
list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
reduce
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
from functools import reduce
def add(x, y):
return x + y
reduce(add, [1, 3, 5, 7, 9])
# 25
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
from functools import reduce
def fn(x, y):
return x * 10 + y
reduce(fn, [1, 3, 5, 7, 9])
错误与异常
常见的bug类型
- 粗心导致的语法错误
SyntaxError - 索引越界导致的
IndexError
python的异常处理机制
try...except
try:
xxx
except KeyError:
xxx
except ValueError:
xxx
except 语句主要有以下几种用法:
- 捕获所有异常:
except:
- 捕获指定异常:
except <异常名>:
- 捕获异常名 1 或异常名 2
except (异常名 1, 异常名 2):
- 捕获指定异常及其附加的数据
except <异常名> as <数据>:
- 捕获异常名 1 或者异常名 2 及异常的附加数据
except (异常名 1, 异常名 2) as <数据>:
try...except...else当没有异常时执行else中的代码
try...except...else...finallyfinally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源
常见的内建异常可以查询csdn或者书本P148-150
| 异常名 | 描述 |
|---|---|
| AttributeError | 调用不存在的方法引发的异常 |
| EOFError | 遇到文件末尾引发的异常 |
| ImportError | 导入模块出错引发的异常 |
| IndexError | 列表越界引发的异常 |
| IOError | I/O操作引发的异常,如打开文件出错等 |
| KeyError | 使用字典中不存在的关键字引发的异常 |
| NameError | 使用不存在的变量名引发的异常 |
| TabError | 语句块缩进不正确引发的异常 |
| ValueError | 搜索列表中不存在的值引发的异常 |
| ZeroDivisionError | 除数为0引发的异常 |
traceback模块
使用traceback模块打印异常信息
import traceback
try:
print(1/0)
except:
traceback.print_exc()
面向对象
类的创建
类的组成:
- 类属性
- 实例方法
- 静态方法
- 类方法
class Student:
native_place = '佛山' #类属性
def __init__(self,name,age,address): #name,age为实例属性
self.name = name
self.age = age
self.__address = address #定义私有方法
#实例方法
def info(self):
print('我叫'+self.name,'年龄是'+self.age)
#类方法
@classmethod
def cm(cls):
print('类方法')
#静态方法
@staticmethod
def sm():
print('静态方法')
在类之外定义的叫函数,在类之内定义的叫方法
对象实例的创建
但对象创建后,会重新开辟一个空间,这个实例对象空间有个类指针指向类对象
stud1 = Student('好好',20)
# 两种调用方法的方式
Student.info(stud1)
stud1.info()
类方法 类属性 静态方法
- 类属性:类中方法外的变量称为类属性,被该类的所有对象所共享
- 类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
- 静态方法:使用@staticmethod修饰的主法,使用类名直接访问的方法
动态绑定属性和方法
一个Student类可以创建N个Student类的实例对象。每个实体对象的属性值不同
stu = Student('张三',10)
stu.gender = '男' #动态绑定属性
def show():
print('lll')
stu.show = show #动态绑定方法
stu.show()
面向对象的三大特征
封装、继承、多态
封装
- 将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度。
- 在Python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前边使用两个“_”。
- 但是我们可以这样
_Student.__address访问被封装的属性
继承
- 提高代码的复用性
class Animal:
def __init__(self,name):
self.name = name
def play(self):
print('我是'+self.name)
class Dog(Animal):
pass
dog = Dog('旺财')
dog.play()
方法重写 与 调用父类
class Animal:
def __init__(self,name):
self.name = name
def play(self):
print('我是'+self.name)
class Dog(Animal):
#如果子类定义了构造方法,则父类的构造函数__init__不会被调用,需要在子类专门调用
def __init__(self,name):
super(Dog,self).__init__(name)
self.hh = name
def play(self):
print(1111)
dog = Dog('旺财')
dog.play()
Object类
- object类是所有类的父类,因此所有类都有object类的属性和方法。
- 内置函数dir()可以查看指定对象所有属性
- Object有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数str()经常用于print()方法,帮我们查看对象的信息,所以我们经常会对__str__()进行重写
多态
- 提高程序的可扩展性和可维护性
- 简单地说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法。
class Animal(object):
def eat(self):
print('动物会吃')
class Dog(Animal):
def eat(self):
print('狗吃骨头')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person(object):
def eat(self):
print('人吃动物')
def fun(animal):
animal.eat()
fun(Dog())
fun(Cat())
fun(Person())
静态语言实现多态的三个必要条件:
- 继承
- 方法重写
- 父类引用指向子类对象
特殊方法和特殊属性
特殊属性:
- dict:获得类对象或实例对象所绑定的所有属性和方法的字典
- class:输出对象所属的类
- bases:输出父类的元组
- base:输出最近的父元素
- mro:输出类的继承结构
- subclasses:子类的列表
特殊方法: - len():通过重写__len__()方法,让内置函数len()的参数可以是自定义类型
- add():通过重写__add__()方法,可使用自定义对象具有’+'功能
- new():用于创建对象
- init():对创建的对象进行初始化
类的浅拷贝和深拷贝
- 变量的赋值操作:只是形成两个变量,实际上还是指向同一个对象
- 浅拷贝:Python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
- 深拷贝:使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk = disk
# 变量的赋值
cpu1 = CPU()
cpu2 = cpu1
print(cpu1)
print(cpu2)#内存地址相同,赋值操作实际上和js数据存储堆栈中的栈相同
# 类的浅拷贝
disk = Disk()
computer = Computer(cpu1,disk)
import copy
computer2 = copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)# 只创建了一个和原来相同的实例对象空间,但内容的指针都没变。所以两者内容地址都相同,并没有额外创建新的内存空间
# 类的深拷贝
disk = Disk()
computer = Computer(cpu1,disk)
import copy
computer3 = copy.deepcopy(computer)#会把类似js的原型链上的所有元素都拷贝一份
模块
一个模块可以包含N多个函数
在Python中一个.py文件就是一个模块
创建模块:新建一个.py文件,名称尽量不要与Python自带的标准模块名称相同
导入模块
import 模块名称 [as 别名]
from 模块名称 import 函数/变量/类
以主程序的形式运行
在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__
if __name__ == '__main__':
pass #只有运行的是当前文件,而不是文件因为模块而被调用时,才能被调用的部分
Python中的包
包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
作用:
- 代码规范
- 避免模块名称冲突
包与目录的区别 - 包含__init__.py文件的目录称为包
- 目录里通常不包含__init__.py文件
包的导入 import 包名.模块名
标准库
Python官方提供了不少的包和模块
sys
import sys
# 识别操作系统
print(sys.platform)
# 处理命令行参数
print(sys.argv)
# 退出程序
sys.exit(0) # 0为正常退出,其他为异常
# 获取模块搜索路径
for path in sys.path:
print(path)
##我们可以像修改列表一样修改路径
sys.path.append('c:\\')
# 查找已导入的模块
print(sys.modules.keys())
print(sys.modules.values())
print(sys.modules['os'])
os
import os
# 获取当前文件所在目录
print(__file__)
print(os.path.dirname(__file__))
# 获取当前路径以及切换当前路径
print(os.getcwd()) ## 获取当前执行程序的路径
os.chdir("c:\\") ## 可以切换当前的路径
# 重命名文件
os.rename('a.text','b.text')## 会将a.text文件重命名为b.text
# 查看指定的路径是否存在
print(os.path.exists("c:\windows")) ## 存在则返回true
# 判断给出的路径是否是一个文件
print(os.path.isfile("c:\\windows\\system32"))
# 判断给出的路径是否是一个目录
print(os.path.isdir("c:\\windows\\system32"))
# 获取系统环境变量
for k,v in os.environ.items():
print(k,"=>",v)
# 创建单层目录
os.mkdir("d:\\01kuaixue")
# 创建多层目录
os.makedirs("d:\\01kuaixue\\02kuaixue")
math
import math
# 常量
math.pi
math.e
# 运算函数
math.ceil(1.7) # 2 向上取整
math.floor(1.7) # 1 向下取整
math.pow(15,5) # 指数运算
math.log(100,10) # math.log(数,底数) 对数运算
math.sqrt(4) # 平方根
math.sin(math.pi)
math.cos(math.pi)
math.tan(0)
math.degrees(math.pi) # 转角度
math.radians(90) # 转弧度
random
# 生产1-10的随机数
random.random()
# 生成指定范围的随机数
random.uniform(1,150)
# 生成一个指定范围内的整数
random.randint(1,50)
# 在给定序列中获取一个随机元素
seq1 = (1,5,2,111)
print(random.choice(seq1))
# 将一个列表中的元素打乱
random.shuffle(sqe1)
第三方包
在命令行窗口中操作
-
显示版本号和包路径
pip --version -
搜索想要的包
pip search 关键字 -
安装包
pip install 软件包名或者pip install 软件包==版本号 -
卸载包
pip uninstall 软件包
可以使用conda进行包管理,不使用pip。
文件与IO
打开文件,利用open()创建文件对象
file = open(filename[,mode,encoding]) # mode打开模式(通常为可读) encoding字符的编写模式 具体模式可自查
文件对象的常用方法
| 方法名 | 说明 |
|---|---|
| read([size]) | 从文件中读取size个字节或字符的内容返回。若省略size,则读取到文件末尾,即一次性读取文件所有内容 |
| readline() | 从文本文件中读取一行内容 |
| readlines() | 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表中返回 |
| write(str) | 将字符串str内容写入文件 |
| writelines(s_list) | 将字符串列表s_list写入文本文件,不添加换行符 |
| seek(offset[,whence]) | 把文件指针移动到新的位置,offset表示相对whence的位置。offset为正往结束方向移动,为负往开始方向移动。whence为0时,从文件头开始计算;为1时,从当前位置开始计算;为2时,从文件尾开始计算 |
| tell() | 返回文件指针当前的位置 |
| flush() | 把缓冲区的内容写入文件,但不关闭文件 |
| close() | 把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源 |
with语句 上下文管理器
with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
with open("/tmp/foo.txt") as file:
data = file.read()
具体with原理可看这个文章http://t.csdn.cn/KvT51
日期与时间
时间戳
时间戳,是一个能表示一份数据在某个特定时间之前已经存在、完整的、可验证的数据,通常是一个字符序列,唯一地标识某一刻的时间,是指格林尼治时间1970年01月01日00时00分00秒(即北京时间1970年01月01日08时00分00秒)至现在的总秒数。
通俗地说,时间戳是一个能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据,它的提出为用户提供了一份电子证据,以证明用户某些数据的产生时间。在实际应用上,它可以使用在包括在电子商务、金融活动的各个方面,尤其可以用来支撑公开密钥基础设置的“不可否认”服务。
时间戳是一个经加密形成的凭证文档,它包括三个部分:
(1)需加时间戳的文件的摘要(Digest);
(2)DTS(Decode Time Stamp,解码时间戳)收到文件的日期和时间;
(3)DTS的数字签名;
时间日期格式化符号
| 符号 | 含义 |
|---|---|
| %y | 两位数的年份表示(00~99) |
| %Y | 四位数的年份表示(0000~9999) |
| %m | 月份(01~12) |
| %d | 月内的一天(0~31) |
| %H | 24小时制小时数(0~23) |
| %I | 12小时制小时数(01~12) |
| %M | 分钟数(00~59) |
| %S | 秒(00~59) |
| %a | 本地简化的星期名称 |
| %A | 本地完整的星期名称 |
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001~366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00~53),星期天为一星期的开始 |
| %w | 星期(0~6),星期天为一星期的开始 |
| %W | 一年中的星期数(00~53),星期一为一星期的开始 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
| %Z | 当前时区的名称 |
time模块
time函数
time函数用于返回当前时间的时间戳(格林尼治时间1970年01月01日00时00分00秒起至现在的总秒数),time函数返回的是浮点数。例如:
import time
now = time.time()
print("当前的时间戳是: %f" %now)
localtime函数
localtime函数的作用是将时间戳格式化为本地时间,返回struct_time对象。localtime函数有一个参数用于接收时间戳,如果调用函数时不提供时间戳,localtime默认会使用当前时间戳。例如:
import time
print("当前时间",time.localtime())
print("0时间戳对应的时间",time.localtime(0))
mktime函数
mktime函数执行与gmtime、localtime函数相反的操作,它接收struct_time对象作为参数,返回用秒数表示时间的浮点数。mktime的参数可以是结构化的时间,也可以是完整的9位元组元素。例如:
import time
t = (2018,7,17,17,3,1,1,1,0)
secs = time.mktime(t)
print("time.mktime(t): %f"% secs)
print("time.mktime(time.localtime(secs)): %f"% time.mktime(time.localtime(secs)))
gmtime函数
gmtime函数能将一个时间戳转换为UTC时区(0时区)的struct_time,可选的参数sec表示从1970-1-1以来的秒数。gmtime函数的默认值为time.time(),函数返回time.struct_time类型的对象(struct_time是在time模块中定义的表示时间的对象)。例如:
import time
print("time.gmtime(): ",time.gmtime())
print("time.gmtime(0)",time.gmtime(0))
asctime函数
asctime函数接受时间元组并返回一个可读的形式为“Tue Jul 17 17:03:01 2018”(2018年7月17日周二17是03分01秒)的24个字符的字符串。asctime函数接收的参数可以是9个元素的元组,也可以是通过函数gmtime()或localtime()返回的时间值(struct_time类型)。例如:
import time
t = (2018,7,17,17,3,1,1,1,0)
print("time.asctime(t): ",time.asctime(t))
print("time.asctime(time.localtime()): ",time.asctime(time.localtime()))
ctime函数
ctime函数能把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者值为None时,进会默认time.time()为参数,它的作用相当于执行asctime(localtime(secs))。例如:
import time
print("time.ctime(): %s" % time.ctime())
print("time.ctime(0): %s" % time.ctime(0))
sleep函数
sleep函数推迟调用线程的运行,可通过参数secs指秒数,表示进程挂起的时间。例如:
import time
print("Start: %s" % time.ctime())
time.sleep(10)
print("End: %s" % time.ctime())
clock函数
clock函数以浮点数计算的秒数返回当前的CPU时间,用来衡量不同程序的耗时,比time.time()更有用。需要注意的是,在不同的系统上clock函数的含义不同。在Unix系统上,它返回的是进程时间,是用秒表示的浮点数(时间戳);而在Windows系统中,第一次调用时返回的是进程运行的实际时间,而之后的第二次调用返回的是自第一次调用以后到现在的运行时间。例如:
import time
def process():
time.sleep(10)
t0 = time.clock()
process()
print(time.clock() - t0,"seconds process time")
t0 = time.time()
process()
print(time.time() - t0,"seconds wall time")
strftime函数
strftime函数用于接收时间元组,并返回以可读字符串表示的当地时间,格式由参数format决定。例如:
import time
t = (2018,7,17,17,3,1,1,1,0)
t = time.mktime(t)
print(time.strftime("%b %d %y %H:%M:%S",time.gmtime(t)))
strptime函数
strptime函数能够根据指定的格式把一个时间字符串解析为时间元组(struct_time对象)。例如:
import time
struct_time = time.strptime("Jul 17 2018 09:03:01","%b %d %Y %H:%M:%S")
print("返回的元组:",struct_time)
datetime模块
datetime模块包含了日期和时间的所有信息,支持从0001年到9999年之间的日期。
datetime模块内定义了两个常量:datetiime.MINYEAR和datetime.MAXYEAR。
datetiime.MINYEAR的值是1,datetime.MAXYEAR的值是9999,这两个常量分别表示了datetime模块支持的最小年份和最大年份。
date对象
date对象表示在日历中的一个日期(包含年、月和日)。date对象的构造函数需要传入三个参数:year,month和day。其中year不能小于datetiime.MINYEAR,也不能大于datetiime.MINYEAR,month和day都需要是一个有效且真实存在的数字,任何一个参数超出了有效日期,程序都会抛出ValueError异常。例如:
| 函数 | 作用 |
|---|---|
| datetime.date(2018,7,1) | |
| datetime.date.today() | 返回当天日期 |
| datetime.date.weekday() | 返回当前星期数,星期一为0,星期二为1,依次类推 |
| datetime.date.isoweekday() | 返回当前星期数,星期一为1,星期二为2,依次类推 |
| datetime.date.isoformat() | 返回日期为ISO格式,即“YYYY-MM-DD”的字符串 |
| datetime.date.strftime() | 格式化输出日期 |
import datetime
date = datetime.date(2018,7,1)
print(date)
today = datetime.date.today()
print(today)
print(today.weekday())
print(today.isoweekday())
print(date.isoformat())
print(date.strftime("%Y-%m-%d"))
print(date.strftime("%y-%b-%d"))
time对象
time对象表示一天中的(本地)时间,与任何特定日期无关,并且可以通过tzinfo对象进行调整。time对象的构造函数接收时、分、秒、微妙、时区和信息等参数,并且所有参数都是可选的(默认不是0就是None)。例如:
import datetime
time1 = datetime.time()
print(time1)
time2 = datetime.time(hour=8,second=7)
print(time2)
time对象中有两个常量min和max,分别对应两个time实例来表示time支持的最大值和最小值,例如
import datetime
print(datetime.time.min)
print(datetime.time.max)
| 函数 | 作用 |
|---|---|
| datetime.time.isoformat() | 返回时间为ISO格式,即HH:MM:SS的字符串 |
| datetime.time.strftime() | 格式化输出时间 |
datetime对象
datetime对象是date和time的结合体,包括date与time的所有信息(常用的时间处理就是datetime)。datetime对象的参数的取值范围大date以及time对象一致,参数也是date对象和time对象的结合。例如:
import datetime
dt = datetime.datetime(year=2018,month=7,day=1,hour=16,second=10)
print(dt)
| 函数 | 作用 |
|---|---|
| datetime.datetime.today() | 返回一个表示本地时间的datetime对象,并且对应的tzinfo是None |
| datetime.datetime.now() | 返回一个表示本地时间的datetime对象,如果提供了参数tzinfo,则获取tzinfo参数所指时区的本地时间,如果不传递tzinfo则和today作用相同 |
| datetime.datetime.utcnow | 返回一个当前UTC时间的datetime对象 |
| datetime.datetime.fromtimestamp() | 根据时间戳创建一个datetime对象,可选参数tzinfo指定时区信息 |
| datetime.datetime.date() | 获取date对象 |
| datetime.datetime.time() | 获取time对象 |
| datetime.datetime.combine() | 根据date和time,创建一个datetime对象 |
| datetime.datetime.strftime() | 格式化输出日期时间 |
timedelta对象
timedelta表示的是两个日期或者时间的差,属性包含:日期、秒、微妙、毫秒、分钟、小时和星期。所有的属性都是可选的并且默认值是0。
import datetime
dt1 = datetime.datetime(2018,7,1,16,15,10)
dt2 = dt1 + datetime.timedelta(weeks=-2)
print(dt1)
print(dt2)
print(dt1 - dt2)
print(dt2 - dt1)
tzinfo对象
tzinfo是一个时区对象的抽象类,datetime和time对象使用它来提供可自定义的时间调整概念(例如:时区或者夏令时)
tzinfo类不能直接使用,但是可以使用datetime.timezone生成。datetime.timezone.utc实现了UTC时区的tzinfo实例,例如:
import datetime
utc_now1 = datetime.datetime.now(datetime.timezone.utc)
utc_now2 = datetime.datetime.utcnow()
print(utc_now1)
print(utc_now2)
datetime.timezone是tzinfo的子类,所以也可以使用datetime.timezone类来实现想要的时区信息。构造datetime.timezone对象时只需要传入和UTC时间相隔的timedalta对象即可,例如:
import datetime
china_timezone = datetime.timezone(datetime.timedelta(hours=8))
utc_timezone = datetime.timezone(datetime.timedelta(hours=0))
china_time = datetime.datetime.now(china_timezone)
utc_time = datetime.datetime.now(utc_timezone)
print(china_time)
print(utc_time)
calendar模块
calendar模块是一个和日历相关的模块,该模块主要用于输出某月的字符日历。
| 函数 | 作用 |
|---|---|
| calendar.isleap() | 判断是否为闰年 |
| calendar.leapdays() | 返回两个年份之间闰年的个数 |
| calendar.month() | 返回一个多行字符串格式的年月日历,两行标题,一周一行。每日宽度为w字符,每行的长度为7*w+6,l是每星期的行数,四个参数:theyear,themonth,w=0,l=0 |
| calendar.monthcalendar() | 返回一个整数的单层嵌套列表,每个子列表装载一个星期。该月之外的日期都为0,该月之内的日期设为该日的日期,从1开始 |
| calendar.monthrange() | 返回两个整数组成的元组,第一个整数表示该月的第一天是星期几,第二个整数表示该月的天数 |
| calendar.weekday() | 返回日期的星期码,从0(星期一)到6(星期日) |
| calendar.calendar() | 返回一个多行字符串格式的年历,3个月一行,间隔距离用参数c表示,默认值为6.每个宽度间隔为w参数,默认值为2.每行长度为21 * w + 18 + 2 * c。l是每星期的行数,默认值是1 |
多线程与并行
进程与线程介绍
这里基本就都是概念啦
进程的概念
进程(Process),是计算机中已运行程序的实体,曾经是分时系统的基本运作单位。在面向进程设计的系统(如早期的Unix、Linux2.4及更早的版本)中,进程是程序的基本执行实体;在面向线程设计的系统(如当代多数操作系统、Linux2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器。程序只是指令、数据及其组织形式的描述,进程才是程序(哪些指令和数据)的真正运行实例。
若干进程有可能与同一程序有关系,且每个进程皆可以同步(循序)或异步(平行)的方式独立运行。现代计算机系统可在同一段时间以进程的形式将多个程序加载到存储器中,并借由时间共享(或称时分复用)在一个处理器上表现出同时(平行性)运行的感觉。同样地,使用多线程技术(多线程即每一个线程都代表一个进程内的一个独立执行上下文)的操作系统或计算机体系结构,同样程序的平行线程可在多CPU主机或网络上真正同时运行(在不同的CPU上)。
线程的概念
线程(Thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。一个线程指的是进程中一个单一顺序的控制流,一个进程可以并发多个线程,每个线程并行执行不同的任务。线程在Unix System V及SunOS中也被称为轻量进程,但“轻量进程”更多值内核线程,而用户线程则被称为“线程”。
线程是独立调度和分派的基本单位,可以分为:(1)操作系统内核调度的内核线程,如Win32线程;(2)由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;(3)有内核与用户进程进行混合调度,如Windows 7线程。
同一进程中的多个线程将共享进程中的全部系统资源,如虚拟地址空间、文件描述符和信号处理等。但同一进程中的多个线程有各自的调用栈(Call Stack)、各自的寄存器环境(Register Context)、各自的线程本地存储(Thread-Local Storage)。
什么是多线程
多线程(Multithreading)是指在软件或硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,进而提升整体处理性能。具有这种能力的系统包括对称处理机、多核心处理器以及芯片级多处理或同事多线程处理器。
软件多线程是说即便处理器只能运行一个线程,操作系统也可以快递地在不同线程之间进行切换,由于时间间隔很小,给用户造成一种多个线程在同时运行的假象。这样的程序运行机制被称为软件多线程,比如微软的Windows和Linux系统就是在各个不同的执行绪间来回切换,被称为单人多任务作业系统。而DOS这类文字接口作业系统在一个时间只能处理一项工作,被视为单人单工作业系统。
Python与全局解释器锁
全局解释器锁(Global Interpreter Lock,简称GIL)是计算机程序设计语言解释器用于同步线程的工具,保证任何时刻仅有一个线程在执行。
首先要申名的是,全局解释器锁并不是Python语言的特性,全局解释器是为了实现Python解释器(主要是CPython,最流行的Python解释器)而引入的概念,并不是所有Python解释器都有全局解释器锁。Jython和IronPython没有全局解释器锁,可以完全利用多处理器系统。PyPy和CPython都有全局解释器锁。
CPython的线程是操作系统的原生线程,完全由操作系统调度线程的执行。一个CPython解释器进程内有一个主线程以及多个用户程序的执行线程。即使使用多核心CPU平台,由于全局解释器锁的存在,也将禁止多线程的并行执行,这样会损失许多多线程的性能。
在CPython中,**全局解释器锁是一个互斥锁,用于保护对Python对象的访问,防止多条线程同时执行Python字节码。**这种锁是必要的,主要是因为CPython的内存管理不是线程安全的。
在多线程环境中,CPython虚拟机按以下方式执行:
- 设置全局解释器锁;
- 切换到一个线程中去运行;
- 运行;
- 指定数量的字节码指令;
- 线程主动让出控制[可以调用time.sleep(0)];
- 把线程设置为睡眠状态;
- 解锁全局解释器锁;
- 再次重复以上所有步骤
在调用外部代码(如C/C++扩展函数)的时候,全局解释器锁将会被锁定,直到这个函数结束为止(因为这期间没有Python的字节码被运行,所以不会做线程切换)。
Python线程模块
Python标准库中关于线程的主要是_thread模块和threading模块。
_thread模块
标准库中的_thread模块作为低级别的模块存在,一般不建议直接使用,但在某些简单的场合也是可以使用的,因为_thread模块的使用方法十分简单。
标准库_thread模块的核心其实就是start_new_thread方法:
_thread.start_new_thread(function,args[,kwargs])
启动一个新线程并返回其标识符,线程使用参数列表args(必须是元组)执行函数,可选的kwargs参数指定关键字参数的字典。当函数返回时,线程将以静默方式退出。当函数以未处理的异常终止是,将打印堆栈跟踪,然后线程退出(但其他线程继续运行)。
import time
import datetime
import _thread
date_time_format = "%H:%M:%S"
def get_time_str():
now = datetime.datetime.now()
return datetime.datetime.strftime(now,date_time_format)
def thread_function(thread_id):
print("Thread %d\t start at %s" % (thread_id,get_time_str()))
print("Thread %d\t sleeping" % thread_id)
time.sleep(4)
print("Thread %d\t finish at %s" % (thread_id,get_time_str()))
def main():
print("Main thread start at %s" % get_time_str())
# 每隔一秒进入一个新的线程
for i in range(5):
_thread.start_new_thread(thread_function,(i,))
time.sleep(1)
time.sleep(6)
print("Main thread finish at %s" % get_time_str())
if __name__ == "__main__":
main()
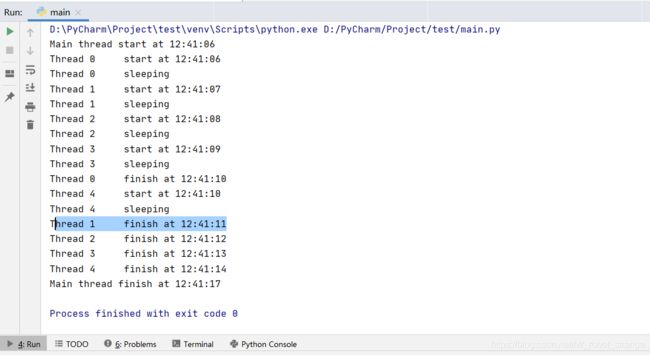
主线程过早或者过晚的退出都不是我们所期望的这时候就需要使用线程锁,主线程可以在其他线程执行完之后立即退出。
_thread.allocate_lock()方法返回一个Lock对象
| 方法 | 作用 |
|---|---|
| acquire | 用于无条件地获取锁定Lock对象,如果有必要,等待它被另一线程释放(一次只有一个线程可以获取锁定) |
| release | 用于释放锁,释放之前必须先锁定,可以不在同一线程中释放锁 |
| locked | 用于返回锁的装填,如果已被某个线程锁定,则返回True,否则返回False |
import time
import datetime
import _thread
date_time_format = "%H:%M:%S"
def get_time_str():
now = datetime.datetime.now()
return datetime.datetime.strftime(now,date_time_format)
def thread_function(thread_id,lock):
print("Thread %d\t start at %s" % (thread_id,get_time_str()))
print("Thread %d\t sleeping" % thread_id)
time.sleep(4)
print("Thread %d\t finish at %s" % (thread_id,get_time_str()))
lock.release()
def main():
print("Main thread start at %s" % get_time_str())
locks = []
for i in range(5):
lock = _thread.allocate_lock()
lock.acquire()
locks.append(lock)
for i in range(5):
_thread.start_new_thread(thread_function,(i,locks[i]))
time.sleep(1)
for i in range(5):
while locks[i].locked():
time.sleep(1)
print("Main thread finish at %s" % get_time_str())
if __name__ == "__main__":
main()
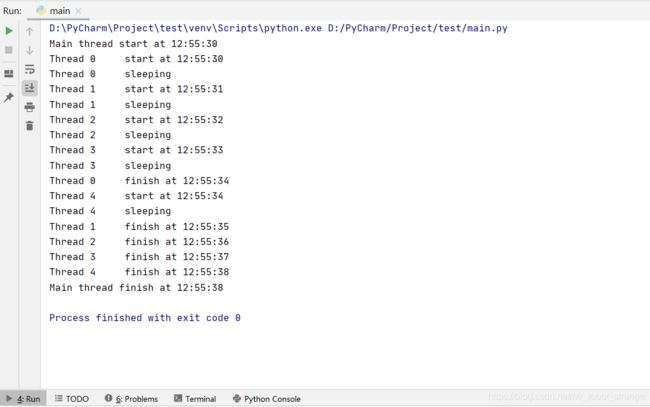
Threading.Thread
Python标准库不仅提供了_thread这样的底层线程模块,还提供了threading模块。threading模块不仅提供了面向对象的线程实现方式,还提供了各种有用的对象和方法方便我们创建和控制线程。
使用threading模块创建线程很方便,大部分操作都是围绕threading.Thread类来实现的。直接使用threading.Thread类也可以像_thread模块中的start_new_thread一样方便。
import time
import datetime
import threading
date_time_format = "%H:%M:%S"
def get_time_str():
now = datetime.datetime.now()
return datetime.datetime.strftime(now,date_time_format)
def thread_function(thread_id):
print("Thread %d\t start at %s" % (thread_id,get_time_str()))
print("Thread %d\t sleeping" % thread_id)
time.sleep(4)
print("Thread %d\t finish at %s" % (thread_id,get_time_str()))
def main():
print("Main thread start at %s" % get_time_str())
threads = []
#创建线程
for i in range(5):
thread = threading.Thread(target=thread_function,args=(i,))
threads.append(thread)
#启动线程
for i in range(5):
threads[i].start()
time.sleep(1)
#等待线程执行完毕
for i in range(5):
threads[i].join()
print("Main thread finish at %s" % get_time_str())
print("Main thread finish at %s" % get_time_str())
if __name__ == "__main__":
main()
从执行结果可以看出,使用threading.Thread可以实现和_thread模块ongoing的线程一样的效果,并且还不需要我们手动地操作线程锁。threading.Thread对象实例化之后不会立即执行线程,只会创建一个实例,之后需要调用start()方法,才真正地启动线程。最后调用join()方法来等待线程的结束,使用threading.Thread对象可以自动地帮助我们管理线程锁(创建锁、分配锁、获得锁、释放锁和检测锁等步骤)。
还有一个常见的方法就是可以从threading.Thread派生一个子类,在这个子类中调用父类的构造函数并实现run方法即可,例如:
import time
import datetime
import threading
date_time_format = "%H:%M:%S"
def get_time_str():
now = datetime.datetime.now()
return datetime.datetime.strftime(now,date_time_format)
class MyThread(threading.Thread):
def __init__(self,thread_id):
super(MyThread,self).__init__()
self.thread_id = thread_id
def run(self):
print("Thread %d\t start at %s" % (self.thread_id,get_time_str()))
print("Thread %d\t sleeping" % self.thread_id)
time.sleep(4)
print("Thread %d\t finish at %s" % (self.thread_id,get_time_str()))
def main():
print("Main thread start at %s" % get_time_str())
threads = []
#创建线程
for i in range(5):
thread = MyThread(i)
threads.append(thread)
#启动线程
for i in range(5):
threads[i].start()
time.sleep(1)
#等待线程执行完毕
for i in range(5):
threads[i].join()
print("Main thread finish at %s" % get_time_str())
if __name__ == "__main__":
main()
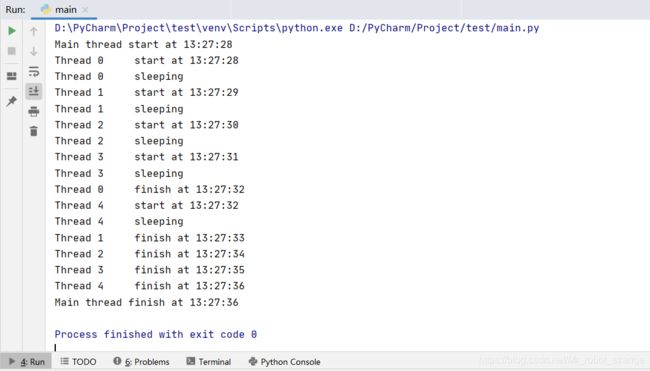
上述例子中,我们先定义了threading.Thread的子类MyThread。在MyThread子类的构造函数中一定要先调用父类的构造函数,然后要实现run方法。在创建线程之后我们就可以调用start方法来启动线程了,调用内部启动方法之后再调用我们实现的run方法(其实start方法创建线程调用的也是_thread.start_new_thread方法)。
线程同步
标准库threading中有Lock对象可以实现简单的线程同步(threading.Lock其实调用的就是_thread.allocate_lock对象)。多线程的优势在于可以同时运行多个任务,但是当线程需要处理同一个资源时,就需要考虑数据不同步的问题了。
import time
import threading
thread_lock = None
class MyThread(threading.Thread):
def __init__(self,thread_id):
super(MyThread,self).__init__()
self.thread_id = thread_id
def run(self):
#锁定
thread_lock.acquire()
for i in range(3):
print("Thread %d\t printing! times: %d" % (self.thread_id,i))
#释放
thread_lock.release()
time.sleep(1)
#锁定
thread_lock.acquire()
for i in range(3):
print("Thread %d\t printing! times: %d" % (self.thread_id, i))
# 释放
thread_lock.release()
def main():
print("Main thread start")
threads = []
#创建线程
for i in range(5):
thread = MyThread(i)
threads.append(thread)
#启动线程
for i in range(5):
threads[i].start()
#等待线程执行完毕
for i in range(5):
threads[i].join()
print("Main thread finish")
if __name__ == "__main__":
#获取锁
thread_lock = threading.Lock()
main()
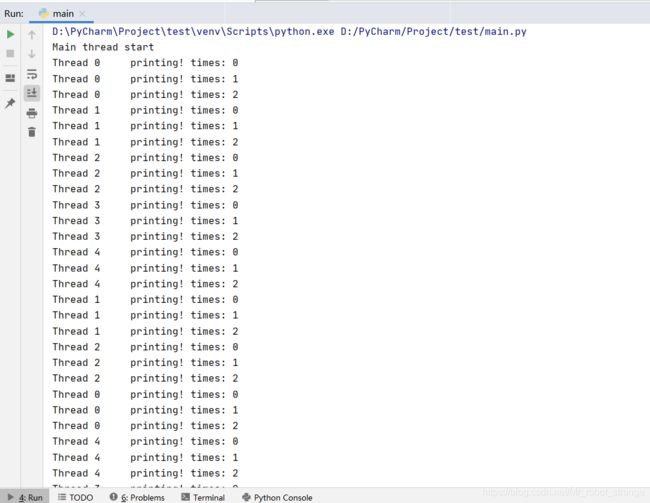
从执行结果中可以看到,加了锁之后的线程不再像之前的例子那么不可控制了,每次执行都会得到相同的结果,并且例子中的五个线程是同时在执行的。当子线程运行到thread_lock.acquire()的时候,程序胡判断thread_lock是否处于锁定转态,如果是锁定状态,线程就会在这一行阻塞,直到被释放为止。
队列
在线程之间传递、共享数据是常有的事情,我们可以使用共享变量来实现相应的功能。使用共享变量在线程之间传递信息或数据时需要我们手动控制锁(锁定、释放等),标准库提供了一个非常有用的Queue模块,可以帮助我们自动地控制锁,保证数据同步。
Python的Queue模块提供了一种适用于多线编程的先进先出(FIFO)实现,它可用于生产者和消费者之间线程安全地传递消息或其他数据,因此多个线程可以共用一个Queue实例。Queue的大小(元素的个数)可用来限制内存的使用。
Queue类实现了一个基本的先进先出容器,使用put()将元素添加到序列尾端,使用get()从队列尾部移除元素。
from queue import Queue
q = Queue()
for i in range(5):
q.put(i)
while not q.empty():
print(q.get())
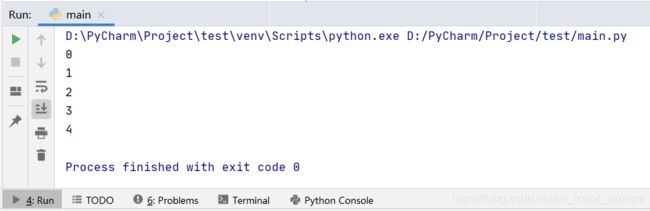
Queue模块并不是一定要使用多线程才能使用,这个例子使用单线程演示了元素以插入顺序从队列中移除。
import time
import threading
import queue
#创建工作队列并且限制队列的最大元素是10个
work_queue = queue.Queue(maxsize=10)
#创建结果队列并且限制队列的最大元素是10个
result_queue = queue.Queue(maxsize=10)
class WorkerThread(threading.Thread):
def __init__(self,thread_id):
super(WorkerThread, self).__init__()
self.thread_id = thread_id
def run(self):
while not work_queue.empty():
#从工作队列获取数据
work = work_queue.get()
#模拟工作耗时3秒
time.sleep(3)
out = "Thread %d\t received %s" % (self.thread_id,work)
#把结果放入结果队列
result_queue.put(out)
def main():
#工作队列放入数据
for i in range(10):
work_queue.put("message id %d" % i)
#开启两个工作线程
for i in range(2):
thread = WorkerThread(i)
thread.start()
#输出十个结果
for i in range(10):
result = result_queue.get()
print(result)
if __name__ == "__main__":
main()
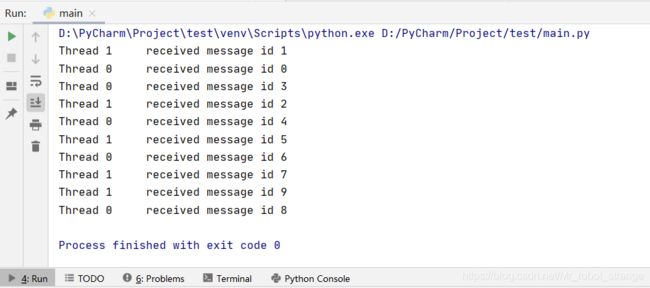
多线程使用Queue模块也不需要多余的锁操作,因为queue.Queue对象已经在执行方法的时候帮助我们自动调用threading.Lock来实现锁的使用了。标准库queue模块不止有Queue一种队列,还有LifoQueue和PriorityQueue等功能复杂的队列。
Python进程模块
os模块
调用system函数是最简单的创建进程的方式,函数只有一个参数,就是要执行的命令。
import os
#判断是否是windows
if os.name == "nt":
return_code = os.system("dir")
else:
return_code = os.system("ls")
#判断命令返回值是0,0代表运行成功
if return_code == 0:
print("Run success!")
else:
print("Something wrong!")
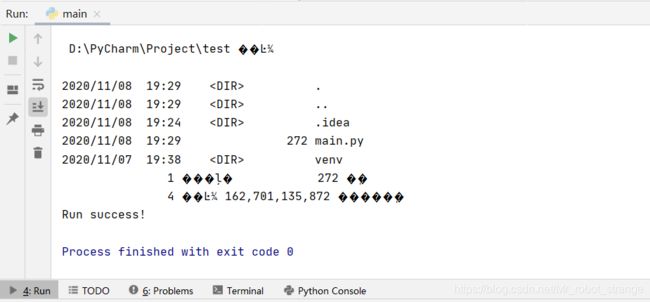
这个例子会根据不同的操作系统调用不同的命令,结果都是输出当前目录的文件和文件夹。os.ststem函数会返回调用的命令的返回值,0代表运行成功。
比os.system函数更复杂一点的是exec系列函数,os.exec系列函数一共有八个,它们的定义分别是:
os.execl(path,arg0,arg1,...)
os.execle(path,arg0,arg1,...env)
os.execlp(file,path,arg0,arg1,...)
os.execlpe(file,path,arg0,arg1,...,env)
os.execv(path,args)
os.execve(path,args,env)
os.execvp(file,args)
os.execvpe(file,args,env)
os.fork()函数调用系统API并创建子进程,但是fork函数在Windows上并不存在,在Linux和Mac可以成功使用。
import os
print("Main Process ID (%s)" % os.getpid())
pid = os.fork()
if pid == 0:
print("This is child process (%s) and main process is %s" % (os.getpid(),os.getppid()))
else:
print("Created a child process (%s)" % (pid,))
subprocess模块
标准库os中的system函数和exec系统函数虽然都可以调用外部命令(调用外部命令也是创建进程的一种方式),但是使用方式比较简单,而标准库的subprocess模块则提供了更多和调用外部命令相关的方法。
大部分subprocess模块调用外部命令的函数都使用类似的参数,其中args是必传的参数,其他都是可选参数:
- args:可以是字符串或者序列类型(如:list、tuple)。默认要执行的程序应该是序列的第一个字段,如果是单个字符串,它的解析依赖于平台。在Unix系统中,如果args是一个字符串,那么这个字符串会解释成被执行程序的名字或路径,然而这种情况只能用在不需要参数的程序上。
- bufsieze:指定缓冲。0表示无缓冲,1表示缓冲,其他的任何整数值表示缓冲大小,负数值表示使用系统默认缓冲,通常表示完全缓冲,默认值为0即没有缓冲。
- stdin,stdout,stderr:分别表示程序的标准输入、输出、错误句柄。
- preexec_fn:只在Unix平台有效,用于指定一个可执行对象,它将在子进程运行之前被调用。
- close_fds:在Windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出与错误管道,所以不能将close_fds设置为True,同时重定向子进程的标准输入、输出与错误。
- shell:默认值为False,声明了是否使用shell来执行程序;如果shell=True,它将args看做是一个字符串,而不是一个序列。在Unix系统中shell=True,shell默认使用/bin/sh。
- cwd:用于设置子进程的当前目录。当它不为None时,子进程在执行前,它的当前路径会被替换成cwd的值。这个路径并不会被添加到可执行程序的搜索路径中,所以cwd不能是相对路径。
- env:用于指定子进程的环境变量。如果env=None,子进程的环境变量将从父进程继承。当它不为None时,它是新进程的环境变量的映射,可以用它来代替当前进程的环境。
- universal_newlines:不同系统的换行符不同,文件对象stdout和stderr都被以文件的方式打开。
- startipinfo与creationflags只在Windows下生效,将被传递给底层的CreateProcess函数,用于设置子进程的一些属性,如主窗口的外观、进程的优先级等等。
- subprocess.call函数和os.system函数有点类似。subprocess.call函数接收参数运行命令并返回命令的退出码(退出码为0表示运行成功)。
import os
import subprocess
#判断是否是Windows
if os.name == "nt":
return_code = subprocess.call(["cwd","/C","dir"])
else:
return_code = subprocess.call(["ls","-l"])
if return_code == 0:
print("Run success!")
else:
print("Something wrong!")
subprocess.check_call方法和subprocess.call方法基本相同,只是如果执行的外部程序返回码不是0,就会抛出CalledProcessError异常(check_call其实就是再封装了一层call函数)。
import os
import subprocess
try:
# 判断是否是Windows
if os.name == "nt":
return_code = subprocess.check_call(["cwd", "/C", "dir"])
else:
return_code = subprocess.check_call(["ls", "-l"])
except subprocess.CalledProcessError as e:
print("Something wrong!",e)
if return_code == 0:
print("Run success!")
else:
print("Something wrong!")
subprocess.Popen对象提供了功能更丰富的方式来调用外部命令,subprocess.call和subprocess.check_call其实调用的都是Popen对象,再进行封装。
import os
import subprocess
if os.name == "nt":
ping = subprocess.Popen("ping -n 5 www.baidu.com",shell=True,stdout=subprocess.PIPE)
else:
ping = subprocess.Popen("ping -c 5 www.baidu.com",shell=True,stdout=subprocess.PIPE)
#等待命令执行完毕
ping.wait()
#打印外部命令的进程id
print(ping.pid)
#打印外部命令的返回码
print(ping.returncode)
#打印外部命令的输出内容
output = ping.stdout.read()
print(output)
multiprocessing.Process
标准库multiprocessing模块提供了和线程模块threading类似的API来实现多进程。multiprocess模块创建的是子进程而不是子线程,所以可以有效地避免全局解释器锁和有效地利用多核CPU的性能。
mulprocessing.Process对象和threading.Thread的使用方法大致一样,例如:
from multiprocessing import Process
import os
def info(title):
print(title)
print("module name: ",__name__)
print("parent process: ",os.getppid())
print("process id: ",os.getpid())
def f(name):
info("function f")
print("Hello",name)
if __name__ == "__main__":
info("main line")
p = Process(target=f,args=("人生苦短",))
p.start()
p.join()
使用target参数指定要执行的函数,使用args参数传递元组来作为函数的参数传递。
multiprocessing.Process使用起来和threading.Thread没什么区别,甚至也可以写一个子类从父类multiprocessing.Process派生并实现run方法。例如:
from multiprocessing import Process
import os
class MyProcess(Process):
def __init__(self):
super(MyProcess,self).__init__()
def run(self):
print("module name: ", __name__)
print("parent process: ", os.getppid())
print("process id: ", os.getpid())
def main():
processes = []
#创建进程
for i in range(5):
processes.append(MyProcess())
#启动进程
for i in range(5):
processes[i].start()
#等待进程结束
for i in range(5):
processes[i].join()
if __name__ == "__main__":
main()
注意:在Unix平台上,在某个进程终结之后,该进程需要被其父进程调用wait,否则进程将成为僵尸进程。所以,有必要对每个Process对象调用join()方法(实际上等同于wait)。
在multiprocessing模块中有个Queue对象,使用方法和多线程中的Queue对象一样,区别是多线程的Queue对象是线程安全的,无法在进程间通信,而multiprocessing.Queue是可以在进程间通信的。
使用multiprocessing.Queue可以帮助我们实现进程同步:
from multiprocessing import Process,Queue
import os
#创建队列
result_queue = Queue()
class MyProcess(Process):
def __init__(self,q):
super(MyProcess,self).__init__()
#获取队列
self.q = q
def run(self):
output = "module name %s\n" % __name__
output += "parent process: %d\n" % os.getppid()
output += "parent id: %d" % os.getpid()
self.q.put(output)
def main():
processes = []
#创建进程并把队列传递给进程
for i in range(5):
processes.append(MyProcess(result_queue))
#启动进程
for i in range(5):
processes[i].start()
#等待进程结束
for i in range(5):
processes[i].join()
while not result_queue.empty():
output = result_queue.get()
print(output)
if __name__ == "__main__":
main()
注意:线程之间可以共享变量,但是进程之间不会共享变量。所以在多进程使用Queue对象的时候,虽然multiprocessing.Queue的方法和quequ.Queue方法一模一样,但是在创建进程的时候需要把Queue对象传递给进程,这样才能正确地让主进程获取子进程的数据,否则主进程的Queue内一直都是空的。
进程池和线程池
进程池
在利用Python进行系统管理,特别是同时操作多个文件目录或者远程控制多台主机的时候,并行操作可以节省大量的时间。当被操作对象数目不打死,可以直接利用multiprocessing中的Process动态生成多个进程。十几个还好,但如果是上百个、上千个目标,手动限制进程数量便显得太过烦琐,这时候进程池(Pool)就可以发挥功效了。
Pool可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就可以创建一个新的进程来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。
import multiprocessing
import time
def process_func(process_id):
print("process id %d" %process_id)
time.sleep(3)
print("process id %d end" % process_id)
def main():
pool = multiprocessing.Pool(processes=3)
for i in range(10):
#向进程池中添加要执行的任务
pool.apply_async(process_func,args=(i,))
#先调用close关闭进程池,不能再有新任务被加入到进程池中
pool.close()
#join函数等待子进程结束
pool.join()
if __name__ == "__main__":
main()
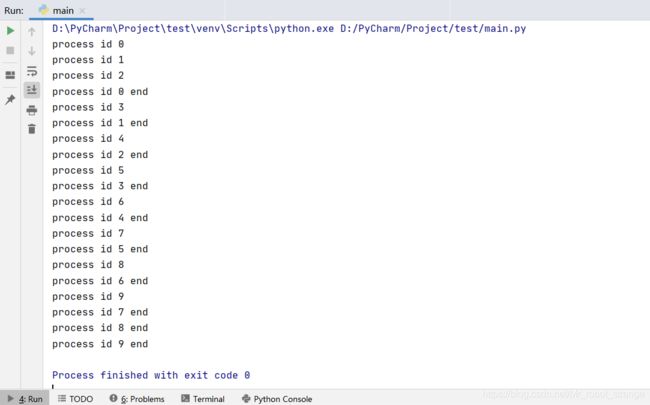
如果每次调用的都是同一个函数,还可以使用Pool的map函数。map方法的第一个参数是要执行的函数,第二个参数必须是可迭代对象。map方法会帮助我们迭代第二个参数,并把迭代出的元素作为参数分批传递给第一个要执行的函数并执行。例如:
import multiprocessing
import time
def process_func(process_id):
print("process id %d" %process_id)
time.sleep(3)
print("process id %d end" % process_id)
def main():
pool = multiprocessing.Pool(processes=3)
pool.map(process_func,range(10))
#先调用close关闭进程池,不能再有新任务被加入到进程池中
pool.close()
#join函数等待子进程结束
pool.join()
if __name__ == "__main__":
main()
线程池
multiprocessing模块中有个multiprocessing.dummy模块。multiprocessing.dummy模块复制了multiprocessing模块的API,只不过它提供的不再是适用于多进程的方法,而是应用在多线程上的方法。但多线程实现线程池的方法和多进程实现进程池的方法一模一样:
import multiprocessing.dummy
import time
def process_func(process_id):
print("process id %d" %process_id)
time.sleep(3)
print("process id %d end" % process_id)
def main():
pool = multiprocessing.dummy.Pool(processes=3)
for i in range(10):
#向线程池中添加要执行的任务
pool.apply_async(process_func,args=(i,))
#先调用close关闭进程池,不能再有新任务被加入到线程池中
pool.close()
#join函数等待子线程结束
pool.join()
if __name__ == "__main__":
main()
Pool的map的使用方法也是一样的:
import multiprocessing.dummy
import time
def process_func(process_id):
print("process id %d" %process_id)
time.sleep(3)
print("process id %d end" % process_id)
def main():
pool = multiprocessing.dummy.Pool(processes=3)
pool.map(process_func,range(10))
#先调用close关闭进程池,不能再有新任务被加入到线程池中
pool.close()
#join函数等待子线程结束
pool.join()
if __name__ == "__main__":
main()
邮件处理
发送电子邮件
SMTP发送电子邮件
Python标准库提供了smtplib模块,用于实现SMTP协议,发送邮件。标准库还提供了email模块帮助我们构造邮件格式。
SMTP(Simple Mail Transfer Protocol,即简单邮件传输协议),是一组由源地址到目的地址传送邮件的规则,用来控制信件的中转方式。
Python的smtplib提供了一种发送电子邮件的方便途径,它会SMTP协议进行了简单的封装。
Python创建SMTP对象的语法为:
smtpObj = smtplib.SMTP([host [,port [,local_hostname]]])
参数说明:
- host:SMTP服务器主机,是可选参数。可以指定主机的IP地址或者域名,如:smtp.exmail.qq.com;
- port:如果提供了host参数,就需要指定SMTP服务使用的端口号,一般情况下SMTP的端口号为25;
- local_hostname:如果SMTP在自己的本机上,则只需要指定服务器地址为localhost即可;
Python SMTP对象使用sendmail方法发送邮件,语法如下:
SMTP.sendmail(from_addr,to_addrs,msg[,mail_options,rcpt_options])
参数说明:
- from_addr:邮件发送地址;
- to_addr:字符串列表,邮件接收地址;
- msg:发送消息,一般使用字符串
预备工作:开启SMTP和POP3服务,获取授权码
使用QQ邮箱发送邮件需要开启SMTP服务和POP3服务,SMTP协议用于发送邮件,POP3协议用于接收邮件,授权码用于连接到服务器。
登录邮箱->设置->账户
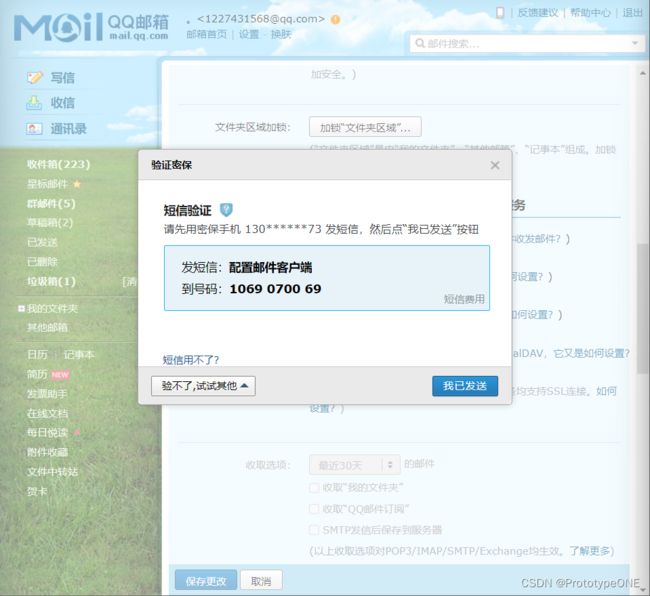
按要求发送短信验证,开启服务
开启服务之后就得到了授权码,此授权码不需要记,忘记了就关闭服务再开启服务即可
开启服务转态,如下
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#邮箱用户名
sender = "[email protected]"
#邮箱授权码
license = "ducdjgclcisahjdc"
#收件人
receicer = ["[email protected]","[email protected]"]
#邮件正文
message = MIMEText("赳赳老秦,共赴国难!","plain","utf-8")
#发件人显式的名字
message["From"] = Header("嬴师隰","utf-8")
#收件人显式的名字
message["To"] = Header("嬴渠梁","utf-8")
#邮件标题
message["Subject"] = "一统天下"
try:
smtp = smtplib.SMTP_SSL("smtp.qq.com",465)
#登录
smtp.login(sender,license)
#发送
smtp.sendmail(sender,receicer,message.as_string())
print("邮件已发送")
except smtplib.SMTPException as e:
print("Error! 发送失败",e)
发送HTML格式的电子邮件
发送HTML格式的邮件,只要在使用MIMEText函数构造邮件消息体的时候将第二个参数指定格式为“html”即可。
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#邮箱用户名
sender = "[email protected]"
#邮箱授权码
license = "ducdjgclcisahjdc"
#收件人
receicer = ["[email protected]","[email protected]"]
#邮件正文
mail_msg = """
秦孝公招贤令
昔我缪公自岐雍之间,修德行武。东平晋乱,以河为界。西霸戎翟,广地千里。天子致伯,诸侯毕贺,为后世开业,甚光美。
会往者历、躁、简公、出子子不宁,国家内忧,未遑外事,三晋夺我先君河西地,诸侯卑秦,丑莫大焉。
献公即位,镇抚边境,徙治栎阳,且欲东伐,复缪公之故地,修缪公之政令。寡人思念先君之意,常痛于心。宾客群臣有能出奇计强秦者,吾为尊官,与之分土。
"""
message = MIMEText(mail_msg,"html","utf-8")
#发件人显式的名字
message["From"] = Header("嬴渠梁","utf-8")
#收件人显式的名字
message["To"] = Header("六国士子","utf-8")
#邮件标题
message["Subject"] = "幕贤强秦"
try:
smtp = smtplib.SMTP_SSL("smtp.qq.com",465)
#登录
smtp.login(sender,license)
#发送
smtp.sendmail(sender,receicer,message.as_string())
print("邮件已发送")
except smtplib.SMTPException as e:
print("Error! 发送失败",e)
发送带附件的邮件
附件其实就是另一种格式的MIME,所以在构造邮件消息体的时候需要使用MIMEMultipart来构造复合类型的消息体,然后把文本和附件一个一个地加进去。
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
#邮箱用户名
sender = "[email protected]"
#邮箱授权码
license = "ducdjgclcisahjdc"
#收件人
receicer = ["[email protected]","[email protected]"]
#指定消息体使用复合类型
message = MIMEMultipart()
#邮件正文
mail_msg = """
秦孝公招贤令
昔我缪公自岐雍之间,修德行武。东平晋乱,以河为界。西霸戎翟,广地千里。天子致伯,诸侯毕贺,为后世开业,甚光美。
会往者历、躁、简公、出子子不宁,国家内忧,未遑外事,三晋夺我先君河西地,诸侯卑秦,丑莫大焉。
献公即位,镇抚边境,徙治栎阳,且欲东伐,复缪公之故地,修缪公之政令。寡人思念先君之意,常痛于心。宾客群臣有能出奇计强秦者,吾为尊官,与之分土。
"""
message.attach(MIMEText(mail_msg,"html","utf-8"))
#添加附件
attached_file = MIMEText(open(__file__,encoding="utf-8").read(),"base64","utf-8")
#指定附件的文件名可以和原先的不一样
attached_file["Content-Disposition"] = 'attachment;filename="main.py"'
message.attach(attached_file)
#发件人显式的名字
message["From"] = Header("嬴渠梁","utf-8")
#收件人显式的名字
message["To"] = Header("六国士子","utf-8")
#邮件标题
message["Subject"] = "一统天下"
try:
smtp = smtplib.SMTP_SSL("smtp.qq.com",465)
#登录
smtp.login(sender,license)
#发送
smtp.sendmail(sender,receicer,message.as_string())
print("邮件已发送")
except smtplib.SMTPException as e:
print("Error! 发送失败",e)
发送图片
我们都知道HTML网页可以嵌入诸如图片、视频等元素,自然在HTML格式的邮件中也可以嵌入这些内容,但是效果不好,因为大部分的邮件客户端和服务商都会屏蔽邮件正文的外部资源,像网页中的图片或者视频、音频等都是外部资源。
如果我们需要发送图片,只需把图片作为附件添加到邮件消息体中,然后在HTML格式的正文中使用src=cid:img1格式嵌入即可。
import smtplib
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.header import Header
#邮箱用户名
sender = "[email protected]"
#邮箱授权码
license = "ducdjgclcisahjdc"
#收件人
receicer = ["[email protected]","[email protected]"]
#指定消息体使用复合类型
message = MIMEMultipart("related")
#邮件正文
msg_content = MIMEMultipart("alternative")
mail_msg = """
秦孝公招贤令
昔我缪公自岐雍之间,修德行武。东平晋乱,以河为界。西霸戎翟,广地千里。天子致伯,诸侯毕贺,为后世开业,甚光美。
会往者历、躁、简公、出子子不宁,国家内忧,未遑外事,三晋夺我先君河西地,诸侯卑秦,丑莫大焉。
献公即位,镇抚边境,徙治栎阳,且欲东伐,复缪公之故地,修缪公之政令。寡人思念先君之意,常痛于心。宾客群臣有能出奇计强秦者,吾为尊官,与之分土。
"""
msg_content.attach(MIMEText(mail_msg,"html","utf-8"))
message.attach(msg_content)
#添加图片
with open("winterfall.jpg","rb") as f:
img1 = MIMEImage(f.read())
#定义资源的名字为img1
img1.add_header("Contend-ID","img1")
message.attach(img1)
#发件人显式的名字
message["From"] = Header("嬴渠梁","utf-8")
#收件人显式的名字
message["To"] = Header("六国士子","utf-8")
#邮件标题
message["Subject"] = "一统天下"
try:
smtp = smtplib.SMTP_SSL("smtp.qq.com",465)
#登录
smtp.login(sender,license)
#发送
smtp.sendmail(sender,receicer,message.as_string())
print("邮件已发送")
except smtplib.SMTPException as e:
print("Error! 发送失败",e)
接收电子邮件
接收邮件有两种常用的协议:POP3和IMAP协议
POP3协议:POP3协议(Post Office Protocol-Version 3,即邮局协议版本3)允许电子邮件客户端下载服务器上的邮件,但是在客户端的操作(如移动邮件、标记已读等)不会反馈到服务器上,比如通过客户端收取了邮箱中的3封邮件并移动到其它文件夹,邮件服务器上的这些邮件不会被同时移动。
IMAP协议:IMAP协议(Internet Mail Acess Protocol,即Internet邮件访问协议)提供Webmail与电子邮件客户端之间的双向通信,任何在客户端做的改变都会同步到服务器上。在客户端对邮件进行了操作,服务器上的邮件也会进行相应的操作。
同时,IMAP协议像POP3协议一样,提供了方便的邮件下载服务,让用户能够进行离线阅读。IMAP协议提供的摘要浏览功能可以让你在阅读完所有的邮件信息(到达时间、主题、发件人、大小等)后才作出是否下载的决定。此外,IMAP协议能更好地支持在多个不同设备上随时访问新邮件的功能。
使用POP3协议下载邮件
import poplib
from email.parser import Parser
#登录邮箱的用户名
username = "[email protected]"
#登录邮箱的密码
password = "ducdjgclcisahjdc"
#连接邮箱服务器
pop_server = poplib.POP3_SSL("pop.qq.com",995)
#打印出邮箱服务器的欢迎文字
print(pop_server.getwelcome().decode("utf-8"))
#登录邮箱服务器
pop_server.user(username)
pop_server.pass_(password)
#打印出当前账号的状态,第一个返回值为邮件数,第二个返回值为占用空间
print("Server stat",pop_server.stat())
#获取所有邮件列表
resp,mails,octets = pop_server.list()
print(mails)
#获取最新的一封邮件(序号最大的),邮件索引从1开始计数
index = len(mails)
resp,lines,octets = pop_server.retr(index)
msg_content = b'\r\n'.join(lines).decode("utf-8")
#解析出邮件
msg = Parser().parsestr(msg_content)
print(msg)
#可以根据邮件索引号直接从服务器删除邮件
pop_server.dele(index)
#关闭连接
pop_server.quit()
使用IMAP协议下载邮件
import imaplib
import email
#登录邮箱的用户名
username = "[email protected]"
#登录邮箱的密码
password = "ducdjgclcisahjdc"
#连接邮箱服务器
imap_server = imaplib.IMAP4_SSL("imap.qq.com",993)
#登录邮箱服务器
imap_server.login(username,password)
print("===============LOG===============")
imap_server.print_log()
print("=================================")
#获取邮箱目录
resp,data = imap_server.list()
print(data)
#选择默认收件箱并打印邮件数量
res,data = imap_server.select('INBOX')
print(res,data)
print(data[0])
#获取最新的一封邮件
typ,lines = imap_server.fetch(data[0],'(RFC822)')
#解析出邮件
msg = email.message_from_string(lines[0][1].decode("utf-8"))
#关闭连接
imap_server.close()
解析邮件
import poplib
from email.parser import Parser
from email.header import Header
from email.utils import parseaddr
#登录邮箱的用户名
username = "[email protected]"
#登录邮箱的密码
password = "ducdjgclcisahjdc"
#连接邮箱服务器
pop_server = poplib.POP3_SSL("pop.qq.com",995)
#打印出邮箱服务器的欢迎文字
print(pop_server.getwelcome().decode("utf-8"))
#登录邮箱服务器
pop_server.user(username)
pop_server.pass_(password)
#打印出当前账号的状态,第一个返回值为邮件数,第二个返回值为占用空间
print("Server stat",pop_server.stat())
#获取所有邮件列表
resp,mails,octets = pop_server.list()
print(mails)
#获取最新的一封邮件(序号最大的),邮件索引从1开始计数
index = len(mails)
resp,lines,octets = pop_server.retr(index)
msg_content = b'\r\n'.join(lines).decode("utf-8")
#解析出邮件
msg = Parser().parsestr(msg_content)
print(msg)
#可以根据邮件索引号直接从服务器删除邮件
pop_server.dele(index)
#关闭连接
pop_server.quit()
def decode_email(s):
if not s:
return ""
value,charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
#打印邮件的发送人、接收人和主题
mail_from = msg.get("From","")
hdr,mail_from_addr = parseaddr(mail_from)
mail_from_name = decode_email(hdr)
print("发件人",mail_from_name,mail_from_addr)
mail_to = msg.get("To","")
hdr,mail_to_addr = parseaddr(mail_to)
mail_to_name = decode_email(hdr)
print("收件人",mail_to_name,mail_from_addr)
subject = decode_email(msg.get("Subject",""))
print("主题","")
#递归解析邮件
def decode_mime(msg):
if msg.is_multipart():
parts = msg.get_payload()
for part in parts:
print(decode_mime(part))
else:
content_type = msg.get_content_type()
if content_type in ("text/plain","text/html"):
content = msg.get_payload(decode=True)
print(content)
else:
print("Attachement",content_type)
decode_mime(msg)
正则表达式
正则表达式是对字符串提取的一套规则,我们把这个规则用正则里面的特定语法表达出来,去匹配满足这个规则的字符串。正则表达式具有通用型,不仅python里面可以用,其他的语言也一样适用。
python中re模块提供了正则表达式的功能,常用的有四个方法(match、search、findall)都可以用于匹配字符串
match
匹配字符串
**re.match()必须从字符串开头匹配!**match方法尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。主要参数如下:
re.match(pattern, string)
# pattern 匹配的正则表达式
# string 要匹配的字符串
e.g.
import re
a = re.match('test','testasdtest')
print(a) #返回一个匹配对象
print(a.group()) #返回test,获取不到则报错
print(a.span()) #返回匹配结果的位置,左闭右开区间
print(re.match('test','atestasdtest')) #返回None
'''
打印出:
test
(0, 4)
None
'''
从例子中我们可以看出,re.match()方法返回一个匹配的对象,而不是匹配的内容。
如果需要返回内容则需要调用group()。通过调用span()可以获得匹配结果的位置。
而如果从起始位置开始没有匹配成功,即便其他部分包含需要匹配的内容,re.match()也会返回None。
单字符匹配
以下字符,都匹配单个字符数据。且开头(从字符串0位置开始)没匹配到,即使字符串其他部分包含需要匹配的内容,.match也会返回none
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符 |
| [] | 匹配[]中列举的字符 |
下面举一些例子让大家的了解简单
import re
'''
. 匹配任意一个字符:
使用几个点号就代表几个字符
'''
a = re.match('..','testasdtest')
print(a.group()) #输出te
b = re.match('ab.','testasdtest')
print(b) #返回none,因为表达式是以固定的ab开头然后跟上通配符. 所以必须要先匹配上ab才会往后进行匹配
'''
\d 匹配数字:
一个\d代表一个数字。开头没匹配到,即使字符串其他部分包含需要匹配的内容,.match也会返回none
'''
a = re.match('\d\d','23es12testasdtest')
print(a)
b = re.match('\d\d\d','23es12testasdtest')
print(b) #要求匹配三个数字,匹配不到返回none
c = re.match('\d','es12testasdtest')
print(c) #起始位置没有匹配成功,一样返回none
'''
\D 匹配非数字:
开头没匹配到,即使字符串其他部分包含需要匹配的内容,.match也会返回none
'''
a = re.match('\D','23es12testasdtest')
print(a) #开头为数字所以返回none
b = re.match('\D\D','*es12testasdtest')
print(b) #返回*e
'''
\s 匹配特殊字符,如空白,空格,tab等:
'''
print(re.match('\s',' 23es 12testasdtest')) #匹配空格
print(re.match('\s',' 23es 12testasdtest')) #匹配tab
print(re.match('\s','\r23es 12testasdtest')) #匹配\r换行
print(re.match('\s','23es 12testasdtest')) #返回none
'''
\S 匹配非空白
'''
print(re.match('\S',' 23es 12testasdtest')) #返回none
print(re.match('\S','\r23es 12testasdtest')) #none
print(re.match('\S','23es 12testasdtest'))
'''
\w 匹配单词、字符,如大小写字母,数字,_ 下划线
'''
print(re.match('\w','23es 12testasdtest')) #返回none
print(re.match('\w\w\w','aA_3es 12testasdtest')) #返回none
print(re.match('\w\w\w','\n12testasdtest')) #返回none
'''
\W 匹配非单词字符
'''
print(re.match('\W','23es 12testasdtest')) #返回none
print(re.match('\W',' 23es 12testasdtest')) #匹配空格
'''
[ ] 匹配[ ]中列举的字符
'''
print(re.match('12[234]','232s12testasdtest')) #因为开头的12没匹配上,所以直接返回none
print(re.match('12[234]','1232s12testasdtest')) #返回123
# [^2345] 不匹配2345中的任意一个
print(re.match('12[^234]','232s12testasdtest')) #因为开头的12没匹配上,所以直接返回none
print(re.match('12[^234]','1232s12testasdtest')) #返回none
print(re.match('12[^234]','1252s12testasdtest')) #返回125
# [a-z3-5] 匹配a-z或者3-5中的字符
print(re.match('12[1-3a-c]','1232b12testasdtest')) #123
print(re.match('12[1-3a-c]','12b2b12testasdtest')) #12b
print(re.match('12[1-3a-c]','12s2b12testasdtest')) #返回none
表示数量
像上面写的那些都是匹配单个字符,如果我们要匹配多个字符的话,只能重复写匹配符。这样显然是不人性化的,所以我们还需要学习表达数量的字符
| 字符 | 功能 |
|---|---|
| . | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
匹配边界
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
import re
'''
| 匹配左右任意一个表达式:
只要|两边任意一个表达式符合要求就行
'''
print(re.match(r'\d[1-9]|\D[a-z]','2233')) #匹配|两边任意一个表达式
print(re.match(r'\d[1-9]|\D[a-z]','as'))
'''
(ab) 将括号中字符作为一个分组:
()中的内容会作为一个元组字符装在元组中
'''
a = re.match(r'(.*)'
,'你好啊'
)
print(a.group()) #输出匹配的字符
print(a.groups()) #会将()中的内容会作为一个元组字符装在元组中
print('`````````````')
b = re.match(r'(.*)()'
,'你好啊'
)
print(b.groups()) #有两括号就分为两个元组元素
print(b.group(0)) #group中默认是0
print(b.group(1)) #你好啊
print(b.group(2)) #h1
'''
输出的结果
你好啊
('你好啊',)
`````````````
('你好啊', '')
你好啊
你好啊
'''
search
和match差不多用法,从字符串中进行搜索
import re
print(re.match(r'\d\d','123test123test'))
print(re.search(r'\d\d','123test123test'))
'''
输出结果
'''
findall
从字面意思上就可以看到,findall是寻找所有能匹配到的字符,并以列表的方式返回
import re
print(re.search(r'test','123test123test'))
print(re.findall(r'test','123test123test')) #以列表的方式返回
'''
输出结果
['test', 'test']
'''
re.s
indall中另外一个属性re.S
在字符串a中,包含换行符\n,在这种情况下
- 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
- 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
如下要寻找test.*123的数据,因为test和123在不同的行,如果没加re.s的话,他会在每一个进行匹配查找而不是将字符串作为一个整体进行查找
import re
a = """aaatestaa
aaaa123"""
print(re.findall(r'test.*123',a))
print(re.findall(r'test.*123',a,re.S))
'''
输出结果
[]
['testaa \naaaa123']
'''
sub
查找字符串中所有相匹配的数据进行替换
sub(要替换的数据,替换成什么,要替换的数据所在的数据)
import re
print(re.sub('php','python','php是世界上最好的语言——php'))
#输出 "python是世界上最好的语言——python"
split
对字符串进行分割,并返回一个列表
import re
s = "itcase,java:php-php3;html"
print(re.split(r",",s)) #以,号进行分割
print(re.split(r",|:|-|;",s)) #以,或者:或者-或者;进行分割
print(re.split(r",|:|-|%",s)) #找不到的分隔符就忽略
compile
re.compile(pattern[, flag])
compile 函数用于编译正则表达式,生成一个 Pattern 对象
其中,pattern 是一个字符串形式的正则表达式,flag 是一个可选参数,表示匹配模式,比如忽略大小写,多行模式等。
贪婪与非贪婪
python里的数量词默认是贪婪的,总是尝试尽可能的匹配更多的字符。python中使用?号关闭贪婪模式
import re
print(re.match(r"aa\d+","aa2323")) #会尽可能多的去匹配\d
print(re.match(r"aa\d+?","aa2323")) #尽可能少的去匹配\d
'''
输出结果
'''
import re
s = "this is a number 234-235-22-423"
# 1.贪婪模式
resule = re.match(r"(.+)(\d+-\d+-\d+-\d)",s) #我们本想数字和字母拆解成两个分组
print(resule.groups()) #('this is a number 23', '4-235-22-4')但我们发现输出的结果中23的数字竟然被弄到前面去了
#因为+它会尽可能多的进行匹配,\d,只需要一个4就能满足,所以前面就尽可能多的匹配
# 2.关闭贪婪模式
#在数量词后面加上 ?,进入非贪婪模式,尽可能少的进行匹配
result = re.match(r"(.+?)(\d+-\d+-\d+-\d)",s)
print(result.groups()) #('this is a number ', '234-235-22-4')
'''
输出结果:
('this is a number 23', '4-235-22-4')
('this is a number ', '234-235-22-4')
'''