活体检测论文研读六:Searching Central Difference Convolutional Networks for Face Anti-Spoofing
文章目录
- 论文简介
- 论文研读
-
- Introduction
- Related Work
- Methodology
-
- Central Difference Convolution
- CDCN
- CDCN++
- Experiments
-
- Datasets and Metrics
- Implementation Details
- Ablation Study
- Intra Testing
- Inter Testing
- Analysis and Visualization.
- Conclusions and Future Work
- Acknowledgment
- Appendix
-
- A. Derivation and Code of CDC
- B. Adaptive θ θ θ for CDC
- C. Cross-type Testing on SiW-M
- D. Feature Visualization
- 资源链接
论文简介
人脸反欺骗(Face Anti-Spoofing,FAS)中的大多数最先进的方法往往存在以下缺点:
1)都是通过设计专门的网络结构和堆叠卷积操作实现的,这种方法难以描述图像的细粒度信息,并且这样的方法容易受到环境变化的影响(如照明不同)
2)采用多帧输入的方式,实时性方面欠缺,难以部署到实时响应的环境当中
因此本文提出一种新的卷积操作——中心差分卷积(Central Difference Convolution,CDC),并基于这种卷积操作提出了一种新的frame-level人脸反欺骗结构。该方法能够通过汇总强度和梯度信息来捕获本质的细节信息(模式)。使用CDC构建的网络称为CDCN,与使用传统卷积操作构建的网络相比,CDCN能够提供更强大的建模能力。并且在经过专门的CDC搜索空间上,神经结构搜索(NAS)可用于发现更强大的网络结构(CDCN++),这种网络将其与多尺度注意力模块(MAFM)组装在一起可以进一步提高性能。实验结果表明:
1)本文的方法不仅在内部测试表现出优异的性能(OULU-NPU协议1取得了 0.2 % A C E R 0.2\% ACER 0.2%ACER)
2)在跨数据集测试中也具有很好的泛化性(尤其是从CASIA-MFSD到Replay-Attack的 6.5 % H T E R 6.5%HTER 6.5%HTER)
论文研读
Introduction
人脸识别已在许多交互式人工智能系统中广泛使用来提供便捷的操作体验。但是,存在的欺骗人脸限制了其可靠的部署。仅将打印的图像或视频呈现给生物识别传感器就可能使人脸识别系统做出错误的判断。经典的演示攻击案例包括视频重放攻击、打印攻击和3D面罩攻击。为了保证人脸识别的可靠性,人脸反欺骗方法对于检测这些攻击显得尤为重要
近年来,已经提出了几种基于手工特征和基于深度学习的方法进行呈现攻击检测(presentation attack detection,PAD)。一方面,经典的手工描述符(例如LBP)利用邻居之间的局部关系作为真假人脸的判别特征,对于描述详细的不变信息(例如颜色纹理,摩尔纹和噪声伪影等)具有鲁棒性。另一方面,由于堆叠具有非线性激活的卷积运算,卷积神经网络(CNN)具有很强的表征能力,可以区分真假人脸。但是,基于CNN的方法着重于更深层的语义特征,这些特征难以描述真假人脸之间详细的细粒度信息,并且其性能容易受到环境影响(如,不同的光照度)。如何将局部描述符与卷积运算集成以实现鲁棒的特征表示值得探讨
多数近期的使用深度学习的FAS方法通常基于图像分类任务的backbone,例如VGG、ResNet、以及DenseNet。这些网络通常使用二分类交叉熵损失函数进行监督训练,这很容易导致网络学到一些分散的信息(例如屏幕边框等)而难以归纳出本质的特征。为了解决这个问题,已经开发了利用伪深度图像作为辅助监督信号的FAS网路结构。但是,这些网络都是由专业人员精心设计的,对于FAS任务而言,这可能并不是最佳选择。因此,应考虑使用辅助的深度图监督来自动的发现最合适FAS任务的网络结构
大多数现有的最先进的FAS方法需要多个帧作为输入,以提取PAD的动态时空特征(例如运动和rPPG)。但是,长视频序列可能不适用于需要快速做出决定的特定部署条件。因此,尽管与video-level方法相比性能较差,但从可用性的角度来看, frame-level PAD方法还是有优势的。设计高性能的frame-level方法对于实际的FAS应用至关重要
基于以上讨论,我们提出了一种新颖的卷积算子,称为“中心差分卷积”(CDC),它擅长描述细粒度的不变信息。如下图所示,在各种环境中,CDC比传统的卷积操作更有可能提取出固有的欺骗模式(例如,晶格伪影)。此外,在专门设计的**CDC搜索空间**上,神经结构搜索(NAS)用于发现使用深度图监督的人脸反欺骗任务的出色frame-level网络

因此,本文主要包括以下贡献:
•设计了一种新颖的卷积算子,称为“中心差分卷积(CDC)”,由于它在各种环境中对不变细粒度具有出色的表征能力,因此它适合于FAS任务。在不引入任何额外参数的情况下,CDC可以取代传统卷积并在现有的神经网络中即插即用,从而形成具有更强大建模能力的中心差分卷积网络(CDCN)
•我们提出CDCN++,这是CDCN的扩展版本,它由搜索骨干网络和多尺度注意力融合模块(MAFM)组成,用于有效地聚合多级CDC特征
•据我们所知,这是第一种为FAS任务搜索神经结构的方法。与之前基于利用softmax作为监督NAS分类任务不同,我们在专门设计的CDC搜索空间上搜索适合深度图监督的FAS任务的frame-level网络
•我们提出的方法通过内部和跨数据集测试,在所有六个基准数据集上均达到了SOTA
Related Work
传统的人脸反欺骗方法通常从面部图像中提取手工制作的特征以捕获欺骗模式。一些经典的局部描述符,例如LBP,SIFT,SURF,HOG和DoG被用来提取frame-level特征,而video-level方法通常捕获如动态纹理,微动和眨眼等动态线索。最近,针对frame-level和video-level的人脸反欺骗,提出了一些基于深度学习的方法。对于frame-level方法,可以对预训练的CNN模型进行微调以提取二分类设置中的特征。相比之下,辅助的深度图监督FAS方法被引入以有效地学习更详细的信息。另一方面,几种video-level的CNN方法通过利用PAD的动态的时空或rPPG特征来实现人脸反欺骗。尽管达到了SOTA,但是基于video-level的深度学习方法仍需要长序列作为输入。此外,与传统的描述符相比,CNN容易过拟合,并且很难在未知的场景中得到很好的泛化
卷积运操作通常用于提取深度学习框架中的基本视觉特征。最近,已经提出了对传统卷积算子的扩展。在一个研究方向上,将经典的局部描述符(例如LBP和Gabor滤波器)考虑到卷积设计中。代表性的作品包括局部二进制卷积(Local Binary Convolution)和Gabor卷积(Gabor Convolution),它们分别是为节省计算成本和增强对空间变化的抵抗力而提出的。另一个研究方向是修改聚合的空间范围。两项相关的工作是空洞卷积(Dilated Convolution)和可变形卷积(Deformable Convolution)。但是,这些卷积运算符可能并不适合FAS任务,因为这些卷积操作对于不变的细粒度特征的表示能力有限
受到NAS的最新相关研究的激励,本文的重点是寻找高性能的深度图监督模型,而不是针对人脸反欺骗任务的二分类模型。现有NAS方法主要分为三类:
1)基于强化学习的方法;
2)基于进化算法的方;
3)基于梯度的方法
大多数NAS会在一个小型代理任务上搜索网络,然后将找到的结构转移到另一个大型目标任务。从计算机视觉应用的角度来看,已经开发出用于面部识别,动作识别,人员ReID,目标检测和分割任务的NAS。据我们所知,还没有人提出过基于NAS的方法来实现人脸反欺骗任务
为了克服上述缺点并填补空白,我们为深度图监督的FAS任务提出的新卷积算子,并在专门设计的搜索空间上搜索frame-level CNN
Methodology
在本节中,我们将首先介绍中心差分卷积,然后介绍用于人脸反欺骗的中心差分卷积网络(CDCN),最后介绍具有注意机制的搜索网络(CDCN++)
Central Difference Convolution
在现在深度学习框架中,特征图和卷积以3D形状(2D平面维度加上通道维度)表示。由于卷积运算在整个通道维度上保持不变,为简单起见,在本小节中,以2D描述卷积,3D扩展类推
由于2D空间卷积是CNN中用于视觉任务的基本操作,因此在这里我们将其表示为香草卷积(vanilla convolution)并简要介绍其原理。2D卷积中有两个主要步骤:
1)在输入特征图x上采样局部感受野区域 R \mathcal{R} R;
2)通过加权求和汇总采样值
因此,输出特征图 y y y可以表示为
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) y({p_0}) = \sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot x(} {p_0} + {p_n}) y(p0)=pn∈R∑w(pn)⋅x(p0+pn)
其中 p 0 p_0 p0表示输入和输出特征图上的当前位置, p n p_n pn是 R \mathcal{R} R中计算的位置。例如,用于 3 × 3 3×3 3×3卷积核和dilation=1的卷积运算的局部感受野区域为 R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , ⋅ ⋅ ⋅ , ( 0 , 1 ) , ( 1 , 1 ) } \mathcal{R}= \{(-1, -1), (-1,0), ···, (0,1), (1,1)\} R={(−1,−1),(−1,0),⋅⋅⋅,(0,1),(1,1)}
受到LBP的启发,LBP通过与中心之间的差异来将局部二值化。我们将这种差异引入到香草卷积当中以增强其表征和泛化能力。同样的,CDC也包含两个步骤,采样和聚合。采样步骤与香草卷积中的采样步骤类似,而聚合则不相同。如下图所示,CDC更喜欢汇总采样值的中心方向梯度。因此上述方程的CDC形式如下:

y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ ( x ( p 0 + p n ) − x ( p 0 ) ) y({p_0}) = \sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot (x(} {p_0} + {p_n})-x(p_0)) y(p0)=pn∈R∑w(pn)⋅(x(p0+pn)−x(p0))
当 p n = ( 0 , 0 ) p_n=(0,0) pn=(0,0)时,相对于中心位置 p 0 p_0 p0本身,梯度值始终等于零
对于人脸反欺骗任务, intensity-level语义信息和gradient-level详细消息对于区分活体和欺骗的面孔都是至关重要的,这表明将香草卷积与中心差分卷积相结合是提高鲁棒性建模的可行方式。因此,我们将中心差卷积归纳为
y ( p 0 ) = θ ⋅ ∑ p n ∈ R w ( p n ) ⋅ ( x ( p 0 + p n ) − x ( p 0 ) ) ⏟ central difference convolution + ( 1 − θ ) ⋅ ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) ⏟ vanilla convolution y({p_0}) = \theta \cdot \underbrace {\sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot (x(} {p_0} + {p_n}) - x({p_0}))}_{{\text{central difference convolution}}} + (1 - \theta ) \cdot \underbrace {\sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot x(} {p_0} + {p_n})}_{{\text{vanilla convolution}}} y(p0)=θ⋅central difference convolution pn∈R∑w(pn)⋅(x(p0+pn)−x(p0))+(1−θ)⋅vanilla convolution pn∈R∑w(pn)⋅x(p0+pn)
其中超参数 θ ∈ [ 0 , 1 ] θ∈[0,1] θ∈[0,1]权衡了intensity-level信息和gradient-level信息之间的贡献。 θ θ θ值越高意味中心差分梯度信息越重要。此后,我们将这种广义的中心差分卷积称为CDC(Central Difference Convolution)
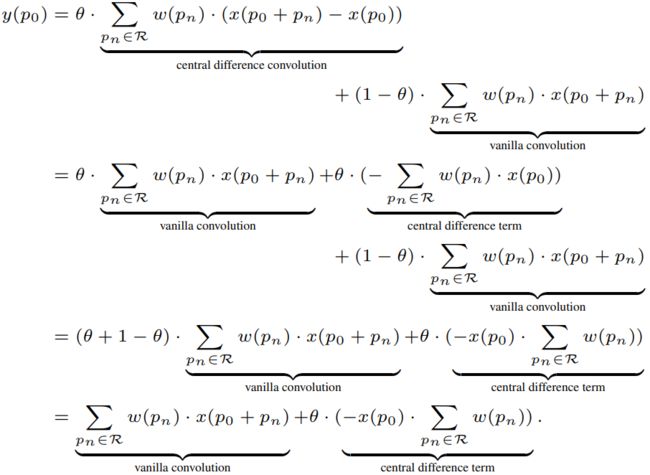
为了在目前的深度学习框架中实现CDC,我们将CDC卷积公式变形如下
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) ⏟ vanilla convolution + θ ⋅ ( − x ( p 0 ) ⋅ ∑ p n ∈ R w ( p n ) ) ⏟ central difference term y({p_0}) = \underbrace {\sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot x(} {p_0} + {p_n})}_{{\text{vanilla convolution}}} + \underbrace {\theta \cdot ( - x({p_0}) \cdot \sum\limits_{{p_n} \in \mathcal{R}} {w({p_n})} )}_{{\text{central difference term}}} y(p0)=vanilla convolution pn∈R∑w(pn)⋅x(p0+pn)+central difference term θ⋅(−x(p0)⋅pn∈R∑w(pn))
根据上述变形公式,可以通过PyTorch和TensorFlow中的几行代码轻松实现CDC,基于PyTorch的代码在附录A中显示
在这里,我们讨论CDC与香草卷积,LBP卷积和gabor卷积之间的关系,它们共享相似的设计理念,但着重点不同。在后面的消融研究中将显示CDC在人脸反欺骗任务中的优越性能
Relation to V anilla Convolution CDC是香草卷积的广义形式。从上面的公式可以发现,当设置 θ = 0 \theta=0 θ=0时,CDC就变成香草卷积形式,只聚集强度信息而不聚集梯度信息
Relation to Local Binary Convolution 局部二进制卷积(Local Binary Convolution,LBConv)专注于减少计算量,因此其建模能力受到限制。 CDC专注于无需增添其它任何参数来增强丰富的细节特征表征能力。另一方面,LBConv使用预定义的滤波器来描述局部特征关系,而CDC可以自动学习这些过滤器
Relation to Gabor Convolution Gabor卷积(Gabor convolution,GaborConv)致力于增强空间变换(即方向和比例变化)的表示能力,而CDC则更多地致力于表示各种环境中细粒度的鲁棒特征
CDCN
深度图监督的人脸反欺骗方法利用了真假人脸在3D形状中的区别,并为FAS模型提供了逐像素的详细信息以捕获欺骗线索。因此,本文建立了一个类似的深度图监控网络DepthNet作为基准。为了提取更多细粒度和鲁棒的特征以估计面部深度图,引入了CDC来形成中央差分卷积网络(CDCN)。注意到,对于所有CDC算子,当 θ = 0 θ = 0 θ=0时,DepthNet是提议的CDCN的特例。
CDCN的细节如下表所示。给定大小为 3 × 256 × 256 3 × 256 × 256 3×256×256的单个RGB人脸图像,提取多级(低级、中级和高级)融合特征来预测大小为 32 × 32 32 × 32 32×32的灰度人脸深度图。将 θ = 0.7 θ = 0.7 θ=0.7作为默认设置,关于θ的消融研究将在后面给出

对于损失函数,均方误差 L M S E \mathcal{L}_{MSE} LMSE用于像素监督。此外,为了FAS任务对细粒度监督的需求,对比深度损失(Contrastive Depth Loss,CDL) L C D L \mathcal{L}_{CDL} LCDL被认为有助于网络学习更详细的特征。所以整体损失 L o v e r a l l = L M S E + L C D L L_{overall}=\mathcal{L}_{MSE}+\mathcal{L}_{CDL} Loverall=LMSE+LCDL
CDCN++
从上表中可以看出,CDCN的体系结构被粗略地设计(例如,对于不同level简单地重复相同block),这对于人脸反欺骗任务可能是次优化的。我们提出了扩展版本CDCN++(如下图所示),它由基于NAS的backbone和具有选择性注意能力(selective attention capacity)的多尺度注意力融合模块(Multiscale Attention Fusion Module,MAFM)组成
我们的搜索算法是基于两种gradient-based的NAS方法,在这里,我们主要陈述了关于为FAS任务寻找backbone的新贡献
如下图(a)所示,目标是在三个levels(low-level、mid-level和high-level)中搜索cells,以形成用于FAS任务的backbone。受人类视觉系统中用于分层组织的专用神经元的启发,我们更喜欢自由地搜索这些更灵活和一般化的多级cells(即,具有各种结构的cells)。我们将这种配置命名为“Varied Cells”,并将研究其影响。与以前的工作不同,我们只采用最新输入cell的一个输出作为当前cell的输入
至于cell-level结构,下图(b)展示了每个cell都被表示为 N N N个节点(node) { x } i = 0 N − 1 \left\{ x \right\}_{i = 0}^{N - 1} {x}i=0N−1的有向无环图(directed acyclic graph,DAG),其中每个节点表示一个网络层。我们将操作空间表示为 O \mathcal{O} O,下图(c)中展示了八个设计的候选操作(None,skip-connect(捷径连接)和CDCs)。DAG的每条边 ( i , j ) (i,j) (i,j)代表从节点 x i x_i xi到节点 x j x_j xj的信息流,该信息流由结构参数 α ( i , j ) α^{(i,j)} α(i,j)加权的候选操作组成。特别地,每条边 ( i , j ) (i,j) (i,j)可以用一个函数 o ~ ( i , j ) {{\tilde o}^{(i,j)}} o~(i,j)来表示,其中 o ~ ( i , j ) ( x i ) = ∑ o ∈ O η o ( i , j ) ⋅ o ( x i ) {{\tilde o}^{(i,j)}}({x_i}) = \sum\nolimits_{o \in \mathcal{O}} {\eta _o^{(i,j)}} \cdot o({x_i}) o~(i,j)(xi)=∑o∈Oηo(i,j)⋅o(xi)。利用softmax函数将结构参数 α ( i , j ) α_{(i,j)} α(i,j)放宽为操作权重 o ∈ O o \in \mathcal{O} o∈O,即 η o ( i , j ) = exp ( α o ( i , j ) ) ∑ o ′ ∈ O exp ( α o ′ ( i , j ) ) \eta _o^{(i,j)} = \frac{{\exp (\alpha _o^{(i,j)})}}{{\sum\nolimits_{o' \in \mathcal{O}} {\exp (\alpha _{o'}^{(i,j)})} }} ηo(i,j)=∑o′∈Oexp(αo′(i,j))exp(αo(i,j))。中间节点可表示为 x j = ∑ i < j o ~ ( i , j ) ( x i ) {x_j} = \sum\nolimits_{i < j} {{{\tilde o}^{(i,j)}}({x_i})} xj=∑i<jo~(i,j)(xi),输出节点 x N − 1 x_{N-1} xN−1由所有中间节点 x N − 1 = ∑ 0 < i < N − 1 β i ( x i ) {x_{N - 1}} = \sum\nolimits_{0 < i < N - 1} {{\beta _i}({x_i})} xN−1=∑0<i<N−1βi(xi)的加权和表示。在这里,我们提出了一种节点注意策略来学习中间节点之间的重要性权重 β β β,即 β i = exp ( β i ′ ) ∑ 0 < j < N − 1 exp ( β j ′ ) {\beta _i} = \frac{{\exp ({\beta _i}^\prime )}}{{\sum\nolimits_{0 < j < N - 1} {\exp ({\beta _j}^\prime )} }} βi=∑0<j<N−1exp(βj′)exp(βi′),其中 β i {\beta _i} βi是中间节点 x i x_i xi的原始可学习权重 β i ′ {\beta _i}^\prime βi′的softmax输出

Architecture search space with CDC. (a) A network consists of three stacked cells with max pool layer while stem and head layers adopt CDC with 3×3 kernel and θ = 0.7. (b) A cell contains 6 nodes, including an input node, four intermediate nodes B1, B2, B3, B4 and an output node. © The edge between two nodes (except output node) denotes a possible operation. The operation space consists of eight candidates, where CDC_2_r means using two stacked CDC to increase channel number with ratio r first and then decrease back to the original channel size. The size of total search space is 3 × 8 ( 1 + 2 + 3 + 4 ) = 3 × 8 10 3 × 8^{(1+2+3+4)}= 3 × 8^{10} 3×8(1+2+3+4)=3×810
在搜索阶段, L t r a i n \mathcal{L}_{train} Ltrain和 L v a l \mathcal{L}_{val} Lval分别表示为训练损失和验证损失,它们都是基于深度监督损失 L o v e r a l l \mathcal{L}_{overall} Loverall。网络参数 w w w和结构参数 α α α通过以下bi-level优化问题来学习:
min L v a l ( w ∗ ( α ) , α ) , s . t . w ∗ ( α ) = arg min w L t r a i n ( w , α ) \min {\mathcal{L}_{val}}({w^*}(\alpha ),\alpha ),\\s.t.{\text{ }}{w^*}(\alpha ) = \arg \mathop {\min }\limits_w {\mathcal{L}_{train}}(w,\alpha ) minLval(w∗(α),α),s.t. w∗(α)=argwminLtrain(w,α)
在收敛之后,最终的分立架构通过以下方式导出:
1)设置 o ( i , j ) = arg max o ∈ O , o ≠ n o n e p o ( i , j ) {o^{(i,j)}} = \arg {\max _{o \in \mathcal{O},o \ne none}}p_o^{(i,j)} o(i,j)=argmaxo∈O,o=nonepo(i,j);
2)对于每个中间节点,选择一个具有最大 max o ∈ O , o ≠ n o n e p o ( i , j ) {\max _{o \in \mathcal{O},o \ne none}}p_o^{(i,j)} maxo∈O,o=nonepo(i,j)值的输入边;
3)对于每个输出节点,选择具有最大值 max 0 < i < N − 1 {\max _{0 < i < N - 1}} max0<i<N−1的输入中间节点(表示为“Node Attention”)作为输入。相比之下,选择最后一个中间节点作为输出节点更简单。我们将在后面比较这两种设置
MAFM虽然简单地融合low-mid-high levels特征可以提高搜索到的CDC结构的性能,但是仍然很难找到要关注的重要区域,这不利于学习更多的区分特征。受人类视觉系统选择性注意的启发,不同水平的神经元很可能在它们的感受野中有不同注意力的刺激。在这里,我们提出了一个多尺度注意力融合模块(MAFM),它能够通过空间注意力提炼和融合low-mid-high levels的CDC特征。
如下图所示,来自不同level的特征 F \mathcal{F} F通过与kernel size相关的感受野的空间注意力进行细化(即,在我们的例子下,high/semantic level应该的注意力应该具有小的kernel size,而low level的注意力应该具有大的kernel size),然后将它们连接在一起。精炼的特征 F ′ \mathcal{F'} F′可如下表示:
F ′ i = F i ⊙ ( σ ( C i ( [ A ( F i ) , M ( F i ) ] ) ) ) , i ∈ { l o w , m i d , h i g h } {{\mathcal{F}'}_i} = {\mathcal{F}_i} \odot (\sigma ({\mathcal{C}_i}([\mathcal{A}({\mathcal{F}_i}),\mathcal{M}({\mathcal{F}_i})]))),i \in \{ low,mid,high\} F′i=Fi⊙(σ(Ci([A(Fi),M(Fi)]))),i∈{low,mid,high}
其中 ⊙ \odot ⊙代表哈达玛积(Hadamard product)。 A \mathcal{A} A和 M \mathcal{M} M分别代表平均池化层和最大池化层。 σ σ σ表示sigmoid函数, C \mathcal{C} C代表卷积层。
C l o w \mathcal{C}_{low} Clow、 C m i d \mathcal{C}_{mid} Cmid、 C h i g h \mathcal{C}_{high} Chigh分别代表 7 × 7 7×7 7×7、 5 × 5 5×5 5×5和 3 × 3 3×3 3×3的香草卷积。这里没有选择CDC,因为CDC对全局语义的感知能力有限,而全局语义感知在空间注意力中至关重要。相应的消融研究在后面给出

Experiments
在这一部分,进行了大量的实验来证明我们方法的有效性。在下文中,我们将依次描述所采用的数据集和指标(Datasets and Metrics),实施细节(Implementation Details),结果和分析(Results and Analysis)
Datasets and Metrics
本文的实验共使用了六个数据集OULU-NPU,SiW,CASIA-MFSD,Replay-Attack,MSU-MFSD和SiW-M。OULU-NPU和SiW是高分辨率数据库,分别包含四个和三个协议用于内部测试来验证模型的泛化(例如,未知的照明和攻击介质)。CASIA-MFSD、Replay-Attack和MSU-MFSD包含低分辨率视频,其用于交叉测试。SiW-M是为针对未知攻击的跨类型测试而设计的,因为内部有丰富的种攻击类型(SiW-M拥有13种攻击类型)
在OULU-NPU和SiW数据集中,我们遵循其原始的协议和指标(protocols and metrics),即攻击呈现分类错误率(Attack Presentation Classification Error Rate,APCER)、真实呈现分类错误率(Bona Fide Presentation Classification Error Rate,BPCER)和ACER进行公平比较。CASIA-MFSD和Replay-Attack的交叉测试采用半总错误率(Half Total Error Rate,HTER)。AUC(Area Under Curve)用于CASIA-MFSD、Replay-Attack和MSU-MFSD内部数据集的跨类型测试。对于在SiW-M的跨类型型测试,则采用了APCER、BPCER、ACER和等差错率(Equal Error Rate,EER)
Implementation Details
本文采用PRNet来为真实活体人脸估计其3D形状并生成尺寸为 32 × 32 32×32 32×32的深度图。为了区分活体人脸和欺骗人脸,在训练阶段,我们将活体人脸的深度图归一化在 [ 0 , 1 ] [0,1] [0,1]范围内,同时将欺骗深度图设置为 0 0 0矩阵
我们提出的方法使用PyTorch实现。在训练阶段,我们采用Adam优化器,初始learning rate=1e-4,weight decay=5e-5。最多训练1300轮,其中每500个epoch学习率衰减一半。batch size设置为56,分布在8张1080Ti GPU上。在测试阶段,我们计算预测深度图的均值作为最终得分
我们采用部分通道连接和边归一化(edge normalization)。网络中的初始channel数为 { 32 , 64 , 128 , 128 , 128 , 64 , 1 } \{32,64,128,128,128,64,1\} {32,64,128,128,128,64,1}(如CDCN++图(a)所示),搜索后加倍。训练模型权重时,使用learning rate=1e-4和weight decay=5e-5的Adam优化器。结构参数使用learning rate=6e-4,weight decay=1e-3的Adam优化器训练。我们设置batch size=12的OULU-NPU的协议 1 1 1上搜索了60个eoch,其中架构参数在前10个epoch没有更新。整个进程在三张 1080 Ti 1080\text{Ti} 1080Ti上进行,共耗时一天
Ablation Study
在本小节中,所有消融研究均基于OULU-NPU的协议 1 1 1(训练集和测试集之间的不同的照明条件、环境和位置)进行,以探索我们提出的CDC,CDCN和CDCN++的细节
根据公式
y ( p 0 ) = θ ⋅ ∑ p n ∈ R w ( p n ) ⋅ ( x ( p 0 + p n ) − x ( p 0 ) ) ⏟ central difference convolution + ( 1 − θ ) ⋅ ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) ⏟ vanilla convolution y({p_0}) = \theta \cdot \underbrace {\sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot (x(} {p_0} + {p_n}) - x({p_0}))}_{{\text{central difference convolution}}} + (1 - \theta ) \cdot \underbrace {\sum\limits_{{p_n} \in \mathcal{R}} {w({p_n}) \cdot x(} {p_0} + {p_n})}_{{\text{vanilla convolution}}} y(p0)=θ⋅central difference convolution pn∈R∑w(pn)⋅(x(p0+pn)−x(p0))+(1−θ)⋅vanilla convolution pn∈R∑w(pn)⋅x(p0+pn)
θ θ θ控制着gradient-based的细节贡献,即 θ θ θ越高,包含的局部细节信息越多。如下图(a)所示,当 θ ⩾ 0.3 \theta \geqslant 0.3 θ⩾0.3时,CDC总是获得比香草卷积更好的性能( θ = 0 , A C E R = 3.8 % θ = 0,ACER=3.8\% θ=0,ACER=3.8%),表明基于中心差分的细粒度信息对FAS任务是有帮助的。因为在 θ = 0.7 θ = 0.7 θ=0.7时我们获得了最佳性能( A C E R = 1.0 ACER=1.0% ACER=1.0),所以我们将该设置用于以下实验。除了保持所有层的 θ θ θ不变,我们还探索了一种自适应CDC方法来学习每个层的 θ θ θ,如附录B所示
根据前面的讨论以及CDC和先前卷积之间的关系,我们认为,提出的CDC更适合于FAS任务,由于不同环境中的详细欺骗伪影应该由gradient-based不变特征来表示。下图(b)显示CDC大幅(超过 2 % A C E R 2\%ACER 2%ACER)优于其他卷积。有趣的是发现LBConv比香草卷积表现更好,说明局部梯度信息对于``FAS任务很重要**。**GaborConv`性能最差,因为它是为捕捉空间不变特征而设计的,这对人脸反欺骗任务没有帮助

下表显示了CDCN++中描述的两种NAS配置的消融研究。即变化的cell和node attention。与具有共享cell和最后一个中间节点作为输出节点的baseline`设置相比,这两种配置都可以提高搜索性能。其中有两点原因:
1)在更灵活的搜索约束下,NAS能够找到不同层次的专用cell,这与人类视觉系统更为相似;
2)将最后一个中间节点作为输出可能不是最优的,选择最重要的节点将更为合理

下图显示了由基于NAS的backbone和MAFM组成的CDCN++结构。很明显,来自多个level的cell差异很大,mid-level cell有更深的(四个CDC)层。下表显示了基于NAS的backbone和MAFM的消融研究。从最初的两行可以看出,具有直接多级融合(direct multi-level fusion)的基于NAS的backbone优于( 0.3 % A C E R 0.3\% ACER 0.3%ACER)不具有NAS的backbone,这表明了搜索结构的有效性。与此同时,具有MAFM的backbone比具有直接多级融合结构低 0.5 % A C E R 0.5\% ACER 0.5%ACER,这显示了MAFM的有效性。我们还分析了MAFM的卷积类型和kernel size,发现香草卷积更适合捕捉语义空间注意力。除此之外,对于低级和高级特性,注意力内核大小应该分别足够大( 7 × 7 7×7 7×7)和足够下小( 3 × 3 3×3 3×3)


Intra Testing
内部测试在OULU-NPU和SiW数据集上进行。我们严格遵循OULU-NPU的四项协议和SiW的三项协议进行评估。为了公平比较,包括STASN在内的所有用于比较的方法都是在没有额外数据集的情况下训练
如下表所示,我们提出CDCN++在所有 4 4 4个协议中均排名第一(分别为 0.2 % 0.2\% 0.2%、 1.3 % 1.3\% 1.3%、 1.8 % 1.8\% 1.8%和 5.0 % A C E R 5.0\%ACER 5.0%ACER),这表明所提出的方法在外部环境、攻击媒介和输入摄像机差异方面均能得到很好的泛化。与其他最先进的提取多帧动态特征的方法(Auxiliary、STASN、GRADIANT和FAS-TD)不同,我们的方法只需要frame-level输入,这适更易于现实部署。值得注意的是,CDCN++的基于NAS的backbone是可迁移的,并且在所有协议上都可以很好地推广,尽管它是在协议 1 1 1上是搜索的

下表比较了我们的方法与三种最先进的方法Auxiliary、STASN和FAS-TD在SiW数据集上的性能。从表中可以看出,我们的方法在所有三种协议中均表现最好,揭示了CDC对(1)面部姿势和表情的变化,(2)不同欺骗介质的变化,(3)交叉/未知呈现攻击的优异泛化性能

Inter Testing
为了进一步验证模型的泛化能力,我们分别进行了跨类型和跨数据集测试,以验证模型对未知呈现攻击和未知环境的泛化能力
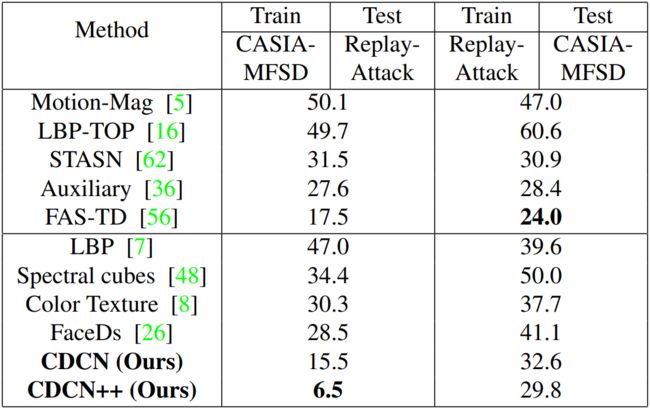
根据《An anomaly detection approach to face spoofing detection: A new formulation and evaluation protocol.》中提出的协议,我们使用CASIA-MFSD,Replay-Attack和MSU-MFSD在重放和打印攻击的内部数据集进行跨类型测试。如下表所示,我们提出的基于CDC的方法获得了最佳的整体性能(甚至优于基于零zero-shot学习的方法DTN ),这表明我们在未知攻击中始终具有良好的泛化能力。此外,我们还对最新的SiW-M数据集进行了交叉类型测试,在 13 13 13种攻击中取得了最佳的平均 A C E R ACER ACER ( 12.7 % 12.7\% 12.7%)和 E E R EER EER ( 11.9 % 11.9\% 11.9%)。详细结果参见附录三

在这个实验中,有两个跨数据集的测试协议。第一种是在CASIA-MFSD上训练,在Replay-Attack上测试,它被命名为protocol CR;第二种是交换训练数据集和测试数据集,命名为protocol RC。如下表所示,我们提出的CDCN++在protocol CR上有 6.5 6.5% 6.5的 H T E R HTER HTER,以令人信服的 11 11% 11的优势优于现有技术。对于protocol RC,我们也优于最先进的frame-level方法(见下表的下半部分)。通过在Auxiliary和FAS-TD中引入类似的时间动态特征,可能进一步提高性能
Analysis and Visualization.
在这一小节中,提供了两个视角来展示为什么CDC表现良好
OULU-NPU的Protocol-1用于遇到域转移时验证CDC的鲁棒性,即训练/开发和测试集之间的巨大照明差异。下图显示了使用普通卷积的网络在开发集(蓝色曲线)上具有更低 A C E R ACER ACER,而在测试集(灰色曲线)上具有高 A C E R ACER ACER,这表明普通卷积在可见域中容易过拟合,但是当光照变化时泛化性较差。相比之下,具有CDC的模型能够在开发(红色曲线)和测试集(黄色曲线)上实现更一致的性能,这表明CDC对域转移具有鲁棒性

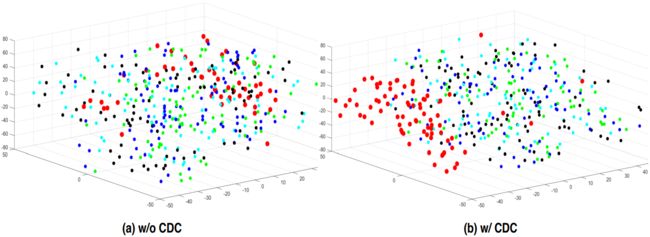
下图通过t-SNE展示了测试视频的多级融合特征在OULU-NPU协议 1 1 1上的分布。很明显,具有CDC的特征(下图(a))比具有普通卷积的特征(下图(b))呈现出更好的聚类行为,这证明了CDC区分活脸和欺骗脸的能力。特征图(不具有或具有CDC)和MAFM的注意力图的可视化可在附录D中找到
Conclusions and Future Work
本文提出了一种新的用于人脸反欺骗任务的算子——中心差分卷积(Central Difference Convolution,CDC)。基于CDC,设计了一种中心差分卷积网络(CDCN)。我们还提出了由搜索的CDC backbone和多尺度注意力融合模块(MAFM)组成的CDCN++结构。大量实验验证了所提方法的有效性。我们注意到CDC的研究仍处于早期阶段。未来的方向包括:
1)为每一层/通道设计上下文感知的自适应CDC;
2)探索其他属性(例如,域泛化(domain generalization))和在其他视觉任务上的适用性(例如,图像质量评估和人脸伪造检测(FaceForensics))
Acknowledgment
This work was supported by the Academy of Finland for project MiGA (grant 316765), ICT 2023 project (grant 328115), and Infotech Oulu. As well, the authors wish to acknowledge CSC IT Center for Science, Finland, for computational resources.
Appendix
A. Derivation and Code of CDC
下图展示了详细的CDC推导公式,并给出了CDC的PyTorch代码
import torch.nn as nn
import torch.nn.functional as F
class CDC(nn.Module):
def __init__(self, IC, OC, K=3, P=1, theta=0.7):
# IC, OC: in_channels, out_channels
# K, P: kernel_size, padding
# theta: hyperparameter in CDC
super(CDC, self).__init__()
self.vani = nn.Conv2d(IC, OC, kernel_size=K, padding=P)
self.theta = theta
def forward(self, x):
# x: input features with shape [N,C,H,W]
out_vanilla = self.vani(x)
kernel_diff = self.vani.weight.sum(2).sum(2)
kernel_diff = kernel_diff[:, :, None, None]
out_CD = F.conv2d(input=x, weight=kernel_diff, padding=0)
return out_vanilla - self.theta * out_CD
B. Adaptive θ θ θ for CDC
虽然人脸反欺骗任务可以手动测量最佳超参数 θ = 0.7 θ = 0.7 θ=0.7,但在将中心差分卷积(CDC)应用于其他数据集/任务时,寻找最合适的 θ θ θ仍然很麻烦。这里,我们将 θ θ θ视为每一层数据驱动的可学习权重。一个简单的实现是利用 S i g m o i d ( θ ) Sigmoid(θ) Sigmoid(θ)来保证输出范围在 [ 0 , 1 ] [0,1] [0,1]以内
如下图所示,可以发现有趣的是在低(第 2 2 2层至第 4 4 4层)和高(第 8 8 8层至第 10 10 10层)level中学习的权重值相对较小,而在中(第 5 5 5层至第 7 7 7层)level中学习的权重值较大。这表明中心差分梯度信息对于中层(mid-level)特征可能更重要。就性能比较而言,从下图(b)中可以看出,使用常数 θ = 0.7 θ = 0.7 θ=0.7的CDC,自适应CDC获得了可比拟的结果( 1.8 % 1.8\% 1.8%对 1.0 % A C E R 1.0\% ACER 1.0%ACER)

C. Cross-type Testing on SiW-M
在SiW-M数据集上遵循相同的交叉类型测试协议(13 attacks leave-one-out),我们将我们提出的方法与三个最近的人脸反欺骗方法进行比较,以验证未知道攻击的泛化能力。如下表所示,我们的CDCN++总体上实现了更好的 A C E R ACER ACER和 E E R EER EER,分别比以前的先进水平提高了 24 % 24\% 24%和 26 % 26\% 26%。具体来说,我们检测到几乎所有的“Impersonation”和“Partial Paper”攻击( E E R = 0 % EER=0\% EER=0%),而以前的方法在“Impersonation”攻击上表现不佳。很明显,我们大幅降低了掩模攻击(“HalfMask”、“SiliconeMask”、“TransparentMask”和“MannequinHead”)的 E E R EER EER和 A C E R ACER ACER ,这表明我们基于CDC的方法对3D非平面攻击得到了很好的泛化

D. Feature Visualization
MAFM的低层特征和相应的空间注意力图在下图中可视化。很明显,真实活体脸和欺骗脸的特征和注意力图都有很大的不同。
1)对于低级特征(参见下图第2和第3行),来自欺骗面部的神经激活在面部和背景区域之间似乎比来自活体面部的更均匀。值得注意的是,带有CDC的特性更有可能捕获详细的欺骗模式(例如,“Print1”中的晶格伪影和“Replay2”中的反射伪影);
2)对于MAFM的空间注意力图(见下图第4行),头发、面部和背景的所有区域对于活体面部具有相对较强的激活,而面部区域对于欺骗面部贡献较弱
资源链接
Searching Central Difference Convolutional Networks for Face Anti-Spoofing PDF
Searching Central Difference Convolutional Networks for Face Anti-Spoofing Code