一、java多线程编程
在java中,如果要实现多线程,就必须依靠线程主体类,而java.lang.Thread是java中负责多线程操作类,只需继承Thread类,就能成为线程主体类,为满足一些特殊要求,也可以通过实现Runnable接口或者Callable接口来完成定义。
具体方式如下:
1.继承Thread类,重写run方法(无返回值)
2.实现Runnable接口,重写run方法(无返回值)
3.实现Callable接口,重写call方法(有返回值且可以抛出异常) 重点:注意多线程操作数据的一致性,悲观锁和乐观锁的使用。
转化线程池的使用:
配置参数:
corePoolSize:线程池维护线程的最小数量。
maximumPoolSize:线程池维护线程的最大数量。
keepAliveTime:空闲线程的存活时间。
TimeUnit unit:时间单位,现有纳秒,微秒,毫秒,秒枚举值。
BlockingQueue workQueue:持有等待执行的任务队列。
RejectedExecutionHandler handler:用来拒绝一个任务的执行,有两种情况会发生这种情况。
一是在execute方法中若addIfUnderMaximumPoolSize(command)为false,即线程池已经饱和;
二是在execute方法中, 发现runState!=RUNNING || poolSize == 0,即已经shutdown,就调用ensureQueuedTaskHandled(Runnable command),在该方法中有可能调用reject。 ThreadPoolExecutor池子的处理流程如下:
当池子大小小于corePoolSize就新建线程,并处理请求。
当池子大小等于corePoolSize,把请求放入workQueue中,池子里的空闲线程就去从workQueue中取任务并处理。
当workQueue放不下新入的任务时,新建线程入池,并处理请求,如果池子大小撑到了maximumPoolSize就用RejectedExecutionHandler来做拒绝处理。
另外,当池子的线程数大于corePoolSize的时候,多余的线程会等待keepAliveTime长的时间,如果无请求可处理就自行销毁。其会优先创建 CorePoolSize 线程, 当继续增加线程时,先放入Queue中,当 CorePoolSiz 和 Queue 都满的时候,就增加创建新线程,当线程达到MaxPoolSize的时候,就会抛出错 误 org.springframework.core.task.TaskRejectedException
另外MaxPoolSize的设定如果比系统支持的线程数还要大时,会抛出java.lang.OutOfMemoryError: unable to create new native thread 异常。
Reject策略预定义有四种:
ThreadPoolExecutor.AbortPolicy策略,是默认的策略,处理程序遭到拒绝将抛出运行时 RejectedExecutionException。
ThreadPoolExecutor.CallerRunsPolicy策略 ,调用者的线程会执行该任务,如果执行器已关闭,则丢弃。
ThreadPoolExecutor.DiscardPolicy策略,不能执行的任务将被丢弃。
ThreadPoolExecutor.DiscardOldestPolicy策略,如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)。spring线程池和jdk线程池的区别:
spring的包装了一下jdk,其实底层都是jdk的线程池。
Spring的线程池是为spring自己使用线程的部件而写的。 使得spring组件不依赖Java的并行库而只依赖自己简化的线程相关的封装。
1、什么是线程和进程
进程:进程是指在系统中正在运行的一个应用程序,程序一旦运行就是进程。
特点:
1、每个进程可以包括多个线程
2、每个进程都有自己独立的内存空间,而其内部的线程可以共享这些内存空间,进程上下文切换的开销比较大,不同进程之间不共享内存
线程:线程是进程的一个子集,一个线程就是一个指令流的执行,线程按照一定的顺序把这些指令流交给CPU执行,就是线程的执行。
2、什么是同步执行和异步执行
以调用方的角度讲,如果需要等待结果返回才能继续运行的话就是同步,如果不需要等待就是异步。
3、Java中实现多线程有几种方法?
(1)继承 Thread类
定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。 创建Thread子类的实例,即创建了线程对象。
调用线程对象的start()方法来启动该线程。(2)实现runable接口
定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
调用线程对象的start()方法来启动该线程。4、sleep和yield的区别?
调用 sleep 会让当前线程从 Running 进入 Timed Waiting 状态(阻塞)
调用 yield 会让当前线程从 Running 进入 Runnable 就绪状态,然后调度执行其它线程
二、消息队列
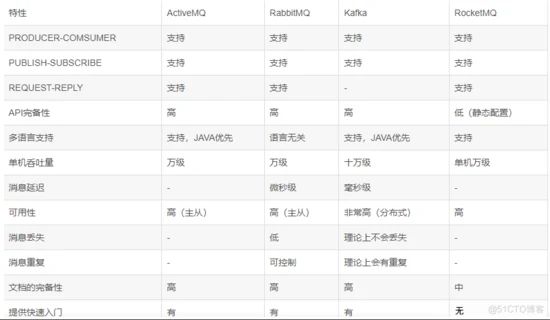
常见的MQ:kafka、activemq、rabbitmq、rocketmq
(1)消息队列有什么优点和缺点:
优点:解耦、异步、削峰
缺点:系统可用性降低、系统复杂性提高、数据一致性问题
(2)如何保证消息不被重复消费
保证消息消费的幂等性。
写数据时,先根据主键查一下这条数据是否存在,如果已经存在则 update;
数据库的唯一键约束也可以保证不会重复插入多条,因为重复插入多条只会报错,不会导致数据库中出现脏数据;
如果是写 redis,就没有问题,因为 set 操作是天然幂等性的。(3)RabbitMQ的5大核心概念
Connection(连接)、Channel(信道)、Exchange(交换机)、Queue(队列)、Virtual host(虚拟主机)。
Connection(连接):每个producer(生产者)或者consumer(消费者)要通过RabbitMQ发送与消费消息,首先就要与RabbitMQ建立连接,这个连接就是Connection。Connection是一个TCP长连接。
Channel(信道):Channel是在Connection的基础上建立的虚拟连接,RabbitMQ中大部分的操作都是使用Channel完成的,比如:声明Queue、声明Exchange、发布消息、消费消息等。
每个线程在访问RabbitMQ时都要建立一个Connection这样的TCP连接,对于操作系统来说,建立和销毁TCP连接是非常大的开销,在系统访问流量高峰时,会严重影响系统性能。Channel就是为了解决这种问题,通常情况下,每个线程创建单独的Channel进行通讯,每个Channel都有自己的channel id帮助Broker和客户端识别Channel,所以Channel之间是完全隔离的。
Virtual host(虚拟主机):Virtual host是一个虚拟主机的概念,一个Broker中可以有多个Virtual host,每个Virtual host都有一套自己的Exchange和Queue,同一个Virtual host中的Exchange和Queue不能重名,不同的Virtual host中的Exchange和Queue名字可以一样。这样,不同的用户在访问同一个RabbitMQ Broker时,可以创建自己单独的Virtual host,然后在自己的Virtual host中创建Exchange和Queue,很好地做到了不同用户之间相互隔离的效果。
Queue(队列):Queue是一个用来存放消息的队列,生产者发送的消息会被放到Queue中,消费者消费消息时也是从Queue中取走消息。
Exchange(交换机):Exchange是一个比较重要的概念,它是消息到达RabbitMQ的第一站,主要负责根据不同的分发规则将消息分发到不同的Queue,供订阅了相关Queue的消费者消费到指定的消息。
三、java类加载
在java中数据类型分为基本数据类型和引用数据类型。基本数据类型由 虚拟机 预先定义,引用数据类型则需要进行类的加载。
按照java虚拟机规范,从class文件到加载进入内存中的类,再到类卸载出内存为止,整个 生命周期 如下:
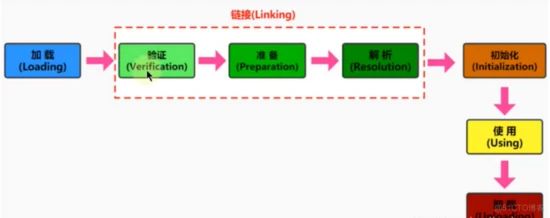
将java类的字节码文件加载到机器内存中,并在内存中构建出java类的原型
a、加载类时,java虚拟机加载步骤
通过类的全名,获取类的二进制数据流
解析类的二进制数据流为方法区内的数据结构
创建java.lang.Class类的实例,作为方法区这个类的各种数据的访入口b、类模型和Class实例的位置
类模型存储在方法区
class文件加载到元空间后,会在堆中创建一个Class对象,用来封装类位于方法区内的数据结构。每一个类都对应一个Class对象Class类的构造方法是私有的,只有jvm可以建
c、数组类的加载
数组类本身并不是由类加载器负责创建,而是由jvm在运行时根据需要直接创建的,但是数组的元素类型仍然需要依靠类加载器去创建。创建步骤如下:
如果数组的元素类型是引用类型,那么遵循定义的加载过程递归加载和创建数组A的元素类型
jvm使用指定的元素类型和数组维度类创建新的数组类。四、Linux操作系统常用命令
------------------目录操作命令:mkdir、rmdir、cd、pwd
mkdir:创建目录
rmdir:删除目录(只能删除空目录)
cd:切换当前目录(改变当前目录)
pwd:显示当前目录的路径
-----------------文件操作命令:cat、touch、more、less、head、tail、cp、mv、rm、diff、grep
cat:显示文件,还可以连接两个或多个文件,形成新的文件
touch:修改文件的访问时间,如果文件不存在,则可以创建该文件
more:分屏显示文件内容,只可向下翻屏
less:分屏显示文件内容,可上下分屏
head:查看文件头部内容,默认前10行
tail:查看文件尾部内容,默认后10行
cp:复制文件或目录
mv:移动文件或目录,还可以重命名
rm:删除一个目录中的一个或多个文件
diff:逐行比较两个文本文件,列出其不同之处
grep:查找文件内容,可以使用正则表达式
------------------日期操作命令:date、cal;
date:可以用来显示或设定系统的日期与时间
cal:用于用于 显示 当前或者指定日期的公历
-------------------重定向命令:>、>>、<、<<;
>:表示每次只写入最新的数据,原有数据不保留,重定向,覆盖原有内容
>>:在原有数据的基础上进行追加,原有数据会保留
<:输入重定向
<<:读取命令行输入,直到遇到输入行为指定的结束标识字符串
-------------------帮助命令:man、info;
man :对命令的详细解释信息
info:比man更加详细得到的信息更多
------------------清屏命令:clear;
clear:该命令作用单一,就是清屏
------------------切换用户命令:su;
su:用于切换当前用户身份到其他用户身份,或者以指定用户的身份执行命令或程序
-------------------查看当前用户命令:whoami;
whoami:显示的是当前用户下的用户名
who am i:显示的是登录时的用户名
who:显示当前真正登录系统中的用户(不会显示那些用su命令切换用户的登录者)
--------------------信息回显命令:echo
echo:是在显示器上显示一段文字,一般起到一个提示的作用五、存储过程存储过程的优缺点
优点:
通过把处理封装在容易使用的单元中,简化复杂的操作;
简化对变动的管理;
通常存储过程有助于提高应用程序的性能;
存储过程有助于减少应用程序和数据库服务器之间的流量,因为应用程序不必发送多个冗长的 SQL 语句,而只用发送存储过程的名称和参数;
存储的程序对任何应用程序都是可重用的和透明的。
存储的程序是安全的。缺点:
如果使用大量存储过程,那么使用这些存储过程的每个连接的内存使用量将会大大增加。
存储过程的构造使得开发具有复杂业务逻辑的存储过程变得更加困难;
很难调试存储过程。只有少数数据库管理系统允许您调试存储过程。
开发和维护存储过程并不容易。创建示例:
-- 创建存储过程
create procedure mypro(in a int,in b int,out sum int)
begin
set sum = a+b;
end;调用示例:
call mypro(1,2,@s);-- 调用存储过程
select @s;-- 显示过程输出结果语法解析:
create procedure 用来创建过程; mypro 用来定义过程名称; (in a int,in b int,out sum int)表示过程的参数,其中 in 表示输入参数,out 表示输出参数。类似于 Java 定义方法时的形参和返回值; begin 与 end 表示过程主体的开始和结束,相当于 Java 定义方法的一对大括号; call 用来调用过程,@s 是用来接收过程输出参数的变量。
六、SpringCloud常用组件
Eureka(服务注册):服务启动的时候,服务上的Eureka客户端会把自身注册到Eureka服务端,并且可以通过Eureka服务端知道其他注册的服务
Ribbon(负载均衡):服务间发起请求的时候,服务消费者方基于Ribbon服务做到负载均衡,从服务提供者存储的多台机器中选择一台,如果一个服务只在一台机器上面,那就用不到Ribbon选择机器了,如果有多台机器,那就需要使用Ribbon选择之后再去使用
Feign(远程调用):Feign使用的时候会集成Ribbon,Ribbon去Eureka服务端中找到服务提供者的所在的服务器信息,然后根据随机策略选择一个,拼接Url地址后发起请求
Hystrix(熔断降级):发起的请求是通过Hystrix的线程池去访问服务,不同的服务通过不同的线程池,实现了不同的服务调度隔离,如果服务出现故障,通过服务熔断,避免服务雪崩的问题 ,并且通过服务降级,保证可以手动实现服务正常功能
Zuul(网关):如果前端调用后台系统,统一走zull网关进入,通过zull网关转发请求给对应的服务但现在常用组合:SpringCloud Alibaba
注册中心:SpringCloud Alibaba Nacos(替代原生Eureka)
配置中心:SpringCloud Alibaba Nacos (替代原生Eureka)
负载均衡:SpringCloud Ribbon(原生提供)—— OpenFeign中已经整合,无需显示引用
声明式HTTP客户端:SpringCloud OpenFeign ——调用远程服务
七、webservice和restful区别
webservice底层是SOAP协议,核心是面向活动,有严格的规范和标准,包括安全,事务等方面。restful是一种架构风格,其核心是面向资源,遵循CRUD原则,这个原则对于资源只需要4种行为,分别是:创建,获取,更新和删除,并且这些资源执行的操作时通过HTTP协议规定的。
使用webservice还是restful就需要考虑资源本身的 ,看资源本身是那种简单的类似增删改查的业务操作,还是那种比较复杂,如转账,事务处理等。
其次是看是否有严格的规范和标准的,而且有多个业务系统集成和开发的时候,使用SOAP协议就比较优势,如果是简单的数据操作,无事务处理,开发和调用比较简单的话使用REST架构风格比较有优势,较为复杂的面向活动的服务,使用restful意义不大。
八、restful风格与驼峰命名法
restful风格:
Restful是一种设计风格。对于我们Web开发人员来说。就是使用一个url地址表示一个唯一的资源。然后把原来的请求参数加入到请求资源地址中。然后原来请求的增,删,改,查操作。改为使用HTTP协议中请求方式GET、POST、PUT、DELETE表示。
基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
restful风格中请求方式GET、POST、PUT、DELETE分别表示查、增、改、删。分别表示如下:
GET请求 对应 查询
http://ip:port/工程名/book/1 HTTP请求GET 表示要查询id为1的图书
http://ip:port/工程名/book HTTP请求GET 表示查询全部的图书
POST请求 对应 添加
http://ip:port/工程名/book HTTP请求POST 表示要添加一个图书
PUT请求 对应 修改
http://ip:port/工程名/book/1 HTTP请求PUT 表示要修改id为1的图书信息
DELETE请求 对应 删除
http://ip:port/工程名/book/1 HTTP请求DELETE 表示要删除id为1的图书信息驼峰命名法 : 第一个单词以小写字母开始;从第二个单词开始以后的每个单词的首字母都采用大写字母。如myName、myLastName
九、webservice接口开发
简单的说WebService是一个SOA(面向服务的编程)的架构,它是不依赖于语言,不依赖于平台,可以实现不同的语言(通过 xml 描述)间的相互调用,通过Internet进行基于Http协议的网络应用间的交互。
依据Web Service规范实施的应用之间, 无论它们所使用的语言、 平台或内部协议是什么, 都可以相互交换数据。Web Service是自描述、 自包含的可用网络模块, 可以执行具体的业务功能。
soapwebService三要素:
SOAP用来描述传递信息的格式SOAP即简单对象访问协议(Simple ObjectAccess Protocol),它是用于交换XML(标准通用标记语言下的一个子集)编码信息的轻量级协议。
WSDL 用来描述如何访问具体的接口Web Service描述语言WSDL就是用机器能阅读的方式提供的一个正式描述文档而基于XML(标准通用标记语言下的一个子集)的语言,用于描述Web Service及其函数、参数和返回值。由于是基于XML的,因此WSDL既是机器可阅读的,又是人可阅读的。
UDDI用来管理,分发,查询webServiceUDDI 的目的是为电子商务创建标准;UDDI是一套基于Web的、分布式的、为Web Service提供的、信息注册中心的实现标准规范,同时也包含一组使企业能将自身提供的Web Service注册,以使别的企业可以发现的访问协议的实现标准。