基于机器学习的UEBA在账号异常检测中的应用
UEBA
UEBA是一种采用高级数据分析方法、面向用户和实体网络行为,进行异常检测和调查的技术,也是安全智能分析切入点。
- U:表示用户(User),UEBA不是一般的安全分析,而是以分析用户活动为首要任务和目的的系统;
- E:表示实体(Entity),UEBA不仅仅分析用户,还分析主机、设备、应用等等实体对象,它本质上是用户+实体分析;
- B:表示行为(Behavior),指UEBA重点聚焦于行为和活动,主要任务是发现有意思的和恶意的行为,不是分析对象的角色、属性和参数,当然分析对象活动需要这些数据,而且是关键的上下文数据;
- A:表示分析(Analytics),高级分析(不是简单的规则匹配)能力是UEBA的基因,高级分析技术不一定是机器学习,但不是使用硬编码规则、阈值和平均值。

UEBA——面向用户与实体行为的检测分析技术,目前在国际上的发展趋势已日益清晰,且已实现大规模的商业化。AI用于网络安全领域的用户实体异常行为分析还是近些年事情,早在2014年Gartner就在发布用户行为分析(UBA)市场界定中认为异常行为分析是智能安全分析的突破口。近年来,国外UEBA技术发展迅速,2018年RSA大会上展示的系统也都不谋而合的采用了统计与机器学习等技术来检测异常行为,更 多UEBA相关概念参考《用户实体行为分析技术(UEBA)》。
UEBA的核心点
1.跨越SIEM/ROC产品,UEBA产品考虑更多的数据源。
从网络设备、系统、应用、数据库和用户处收集数据,有更多的数据,是其成功的条件之一。
2.数据驱动,但并不是单纯依靠数据驱动。一般都是数据驱动+专家驱动的混合系统。
单纯的数据驱动的问题:
1.在学习之处很难拿到十分完善的数据,每当有新的数据源都需要重新进行学习,对于工程化来说是一场灾难
2.增加features很难做到快速部署
3.机器学习的到的结果是黑盒,不能解释说明,因此用户很难直接根据机器学习的结果直接进行响应和判别
3.并不是单纯的依靠机器学习,而是机器学习和统计学习相结合。
异常主要来源于两个方面:
1.统计特征。例如用户访问文件夹数量异常、是否第一词访问某个较敏感的文件夹等
2.可以输出确信度很高的机器学习结果。如DGA域名机器学习检测结果
异常并不会直接给用户告警,而是作为下一步机器学习的元数据features,根据这些features再利用及机器学习模型快速确定不同features对应的风险值,风险值大于一定的阈值才会进行告警。
4.必须针对特定的应用场景才能起到很好的效果
UEBA分析方法
一些UEBA解决方案依靠传统方法来识别可疑活动。这些可以包括手动定义的规则,安全事件与已知攻击模式之间的关联。传统技术的局限性在于它们仅与安全管理员定义的规则一样好,并且无法适应新型威胁或系统行为。
先进的分析是UEBA工具的标志,它涉及多种现代技术,即使在没有已知模式的情况下也可以帮助识别异常行为:
- 有监督的机器学习–已知良好行为和不良行为的集合被输入到系统中。该工具学习分析新行为并确定它是否类似于已知的良好或已知的不良行为集。
- 贝叶斯网络–可以结合监督的机器学习和规则来创建行为配置文件。
- 无监督学习–系统学习正常行为,并能够检测和警告异常行为。它无法分辨出异常行为是好是坏,仅是它偏离了正常行为。
- 强化/半监督机器学习–一种混合模型,其基础是无监督学习,并且实际的警报解决方案被反馈到系统中,以允许对该模型进行精细调整并降低信噪比。
- 深度学习–启用虚拟警报分类和调查。该系统训练代表安全警报及其分类结果的数据集,执行功能的自我识别,并能够预测新的安全警报集的分类结果。
传统的分析技术是确定性的,在某种意义上,如果某些条件为真,则会生成警报,如果不是,则系统假定“一切都很好”。上面列出的高级分析方法的不同之处在于它们是启发式的。他们计算风险分数,这是事件表示异常事件或安全事件的概率。当风险分数超过特定阈值时,系统将创建安全警报。
在实际使用过程中,无监督学习识别出的未知威胁还可以结合人工标注,安全专家定期针对少量异常行为进行标记,通过有监督学习,利用Active Learning算法,允许用户进行有限标注,通过CNN(卷积神经元网络)训练少量样本模型,进而通过模型串接,修正原有算法分析结果,最终算法可以更贴合企业业务场景、提升算法准确率。
两种异常行为分析的方式
1.建立异常行为模型
针对特定种类的攻击行为,根据人工经验构建一攻击行为指标,基于行为指标简历机器学习模型,从而识别异常行为。
缺陷:需要对攻击有充分的理解
2.建立正常行为模型
针对波保护对象进行实体行为进行”画像”,建立一套对实体行为刻画的指标,基于这些指标简历及机器学习模型,通过数据与正常的模式的偏离程度来识别异常
注意点:
1、监视列表Watchlist
没必要评分的组或者部门就不评分,特殊白名单账号移除监视列表。
2、分析Analytics
举个例子:用户在星期一上午 9 点登录。该用户的风险评分为 10。风险评分范围从 1 到 100,其中 100 是最极端的风险级别。当该用户每天早上 9 点重复登录时,他的风险评分从 10 到 9 再到 8,因为他表现出一致的行为。但是,当他在午夜登录时,他的风险评分会上升,因为这是该用户的异常行为。考虑到他的所有其他在线活动——他通常访问的应用程序、他处理的文件、他发送电子邮件的人、他的同龄人在做什么等——分析可以开始描绘该用户的这项活动的风险有多大。分析从每个用户和实体的多个来源获取访问和活动数据馈送,并根据行为为每个人实时生成风险评分。
3、上下文context
风险评分与丰富的上下文相结合是成功预测安全分析的先决条件。安全团队需要能够检查访问模式和行为,使他们能够查看可能同时发生在不同位置的多组活动之间的重要关系。这就是数据科学和机器学习的价值所在。组织需要知道谁、什么、在哪里以及为什么,而且他们必须几乎实时地知道。机器学习克服了在大量不同和断开的数据源之间建立链接的挑战。
4、时间序列分析 Time series analysis
指在数据中使用时间相关性的回归算法。用户操作是否越界——在某个小时或某个时间范围内?将该信息与 K-means 算法的结果相结合,该算法查看目标机器组,您可以获得用于确定用户在下班时间工作的上下文,例如系统更新。
分析引擎的优化
在分析引擎的优化上,无论选择的是深度学习、强化学习还是其它学习,都少了从“势”到“态”的凌驾,只有从“态”到“势”的亦步亦趋,其中少了许多试探性的刺激—选择—调整。为实现对分析引擎的优化和系统的最大化利用还需要让人更多的参与到系统的训练中,并尽可能的多分配决策的任务给人完成,以增加人对系统的信任度。
参考莫凡的《基于机器学习的用户实体行为分析技术在账号异常检测中的应用》进行分析:
1、基础特征提取
第1 类维度是用户与用户之间行为基线的对比。基于大部分用户行为是正常的原则,通过用户
与用户之间的行为基线对比,可以发现偏离集群基线的少数用户。
 图1 用户账号24 小时在线概率密度分布
图1 用户账号24 小时在线概率密度分布
第2 类维度是用户组与用户组之间行为基线的对比。一般而言,在企业内部处于同一个部门相似
岗位的员工应该有类似的行为基线,不同部门之间如技术部门与销售部门工作上有较大差异,反映在网络行为和终端行为上肯定会有较大不同。
偏离度的计算公式如下:

式中,Di 代表第i 个用户的偏离度;di 代表第i 个用户与类簇中心距离;dmean 代表同组用户与类
簇中心的平均距离。
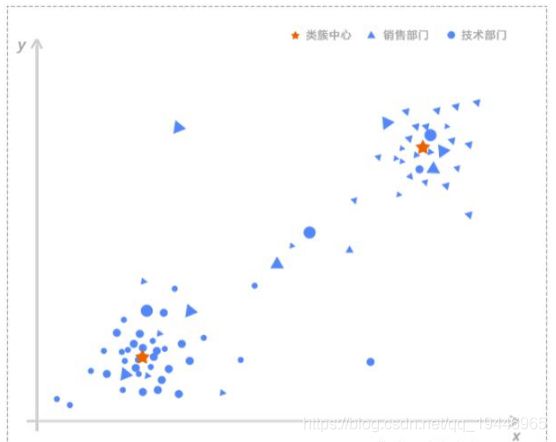 图2 用户组聚类结果
图2 用户组聚类结果
第3 类维度是基于用户自身行为基线对比的离散数据特征提取。通过学习大量的历史行为数据建
立正常的用户基线后,可以对偏离历史基线的用户行为提取异常特征。
第4 类维度是基于用户自身行为基线对比的连续数据特征提取。通过学习用户的连续数据的行
为基线,可以对偏离历史基线的用户行为提取异常特征。
 图3 时序异常检测
图3 时序异常检测
2、基于集成学习的异常用户检测
获取特征后,即能使用机器学习算法检测异常用户。异常检测算法众多,它们的期望尽管都是尽可能分离出正常数据与异常数据,但其原理各不相同。针对不同的数据源,很难保证哪一类算法能够取得最优的结果。
采用孤立森林、One Class SVM 以及局部异常因子3 种算法的集成来全面识别和评价最可能影响系统的各种异常用户。利用这3 种算法进行异常检测,可以分别得到所有用户的异常打分。对3 种算法结果进行加权归一,便可以得到最终的针对所有用户的异常打分排名。
整个UEBA 的核心系统框架如图4 所示。
 图4 UEBA 核心系统框架
图4 UEBA 核心系统框架
每个算法都会对用户i 计算一个独立的异常分值。孤立森林、One Class SVM、局部异常因子3 种算法的几个分别记为S1、S2、S3,其对应的权重分别为P1、P2、P3,则最终的异常评分Score 为:

3、结果分析
表1 为排名前20 的异常用户分值及部分特征值。
用户446983413 异常排名居首,对其异常特征进行排查,发现存在账号爆破、异地登录、端口扫描、从OA 系统下载文件以及传输流量过大等异常,最终安全运维人员确定为因VPN 账号被爆破导致的敏感信息泄露事件。它在时间轴上的发生顺序如
图5 所示。
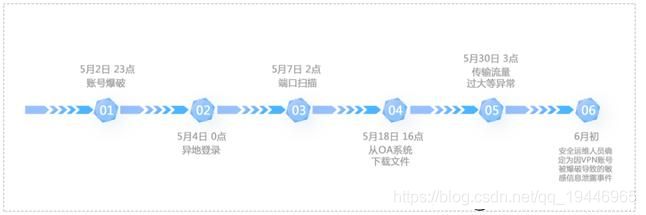 图5 用户446983413 相关事件时间轴
图5 用户446983413 相关事件时间轴
参考:
- http://222.198.130.40:81/Qikan/Article/Detail?id=7101810386&from=Qikan_Search_Index
- https://netsecurity.51cto.com/art/202005/616455.htm
- https://anchorety.github.io/2019/08/01/UEBA/
-
https://www.venustech.com.cn/new_type/cpdt/20181129/21343.html
-
https://www.secrss.com/articles/31002
-
http://www.tyrsafe.com/a/975.html
-
http://www.caict.ac.cn/kxyj/qwfb/ztbg/202006/P020200619441768543756.pdf
-
https://www.skyguard.com.cn/pdf/%E4%BB%A5%E4%BA%BA%E4%B8%BA%E4%B8%AD%E5%BF%83%E7%9A%84%E6%95%B0%E6%8D%AE%E9%98%B2%E6%8A%A4%E7%99%BD%E7%9A%AE%E4%B9%A6.pdf
-
https://blog.nowcoder.net/n/35c1f1094f084a088ca02f1264ecca14
-
https://www.codenong.com/cs106035987/