百度飞桨目标检测教程二:RCNN系列论文解析
百度飞桨目标检测教程二:RCNN系列论文解析
Anchor-based 两阶段目标检测算法 RCNN系列论文解析
涉及论文:RCNN FastRCNN FasterRCNN FPN CascadeRCNN LibraRCNN
RCNN
ppt1
总述:两阶段算法,先提取框,后进行分类
候选框提取 特征提取 分类器

RCNN
Rich feature hierarchies for accurate object detection and semantic segmentation
2014 CVPR
引用次数:14501
作者:Ross Girshick UC Berkeley, USA
联系方式:Email: [email protected]
代码复现:http://www.cs.berkeley.edu/rbg/rcnn
RCNN的主要改动,特征提取步骤用CNN提取特征
selective search提取2000个候选区域
每个候选区域被warp到网络要求的输入大小,应用卷及网络得到输出,作为这个候选区域的特征。
使用这些特征训练多个SVM分类器进行分类任务,每个SVM分类器只能预测一个类别
使用这些特征训练线性回归器来对区域进行调整
优势:精度大大提升
弊端:
训练量大,每一个候选区域都要通过CNN计算特征
Selective Search是传统方法,提取的区域的质量不够好
特征提取,SVM分类器,线性回归器都是分模块独立训练,没有联合起来系统性优化,训练耗时长。
FastRCNN
ppt1
Fast RCNN
Fast r-cnn
2015 ICCV
引用次数:11289
作者:Ross Girshick Microsoft Research, USA
联系方式:Email: [email protected]
论文复现:https://github.com/rbgirshick/fast-rcnn
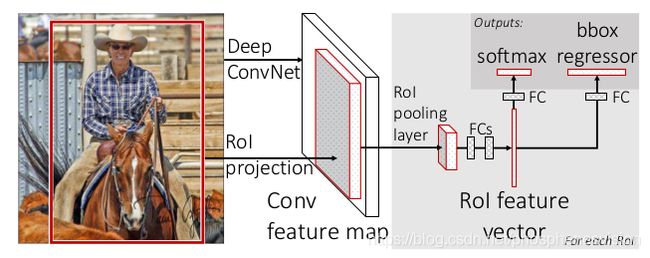
主要的思想:简化RCNN中的计算复杂度
图像输入至卷积网络得到特征图,再用SS的方法去提取候选区域,这样候选区域就可以共享特征图了,减小了计算量。
warp被RoI Pooling替换:SS提取的候选区域大小是不同的,RCNN是缩放至某一个固定的尺寸,可能会导致信息的损失,FastRCNN是用RoI Pooling。
RoI Pooling
SPPNet 首先提出来的。
每个区域分成若干小块,每个小块得到该区域的最大值。然后就经过FC层得到了每个候选区域的特征。
多个svm分类器被替换为一个softmax分类器,实现了分类分支和回归分支的联合训练。
优势:训练耗时减小,预测耗时减小
弊端:依然用到了SS的方法,整个网络预测耗时是2.3秒钟,而用候选区域提取SS的方法就要耗时1.98秒,因此SS算法需要改进。
FasterRCNN
ppt1
Faster RCNN
[Faster r-cnn: Towards real-time object detection with region proposal networks](https://xueshu.lanfanshu.cn/scholar_url?url=http%3A%2F%2Fpapers.nips.cc%2Fpaper%2F5638-faster-r-cnn-towards-real-time-object-detection-with-region-proposal-networks&hl=zh-CN&sa=T&ct=res&cd=0&d=16436232259506318906&ei=tvpGX8aYOoi8yQS8x6SABg&scisig=AAGBfm0ngVC1c3WkUMCAr4eitilAIB_AnQ&nossl=1&ws=1855x932&at=Faster r-cnn%3A Towards real-time object detection with region proposal networks)
2015 NIPS
引用次数:21049
作者:Shaoqing Ren Microsoft Research, China
联系方式:Email: [email protected]
代码复现:https://github.com/ShaoqingRen/faster_rcnn
核心思想:RPN网络替代SS用于提取候选区域

首先通过backbone得到特征图,原来直接用SS的方法在这个输出特征图上面得到候选区域,现在用RPN来代替,
RPN工作原理,提前在每一个像素点都生成预设大小的anchor框,经过卷积网络运算生成两个分支,第一个分支预测anchor框是否有东西,只要有东西就行,不关心是个什么东西,第二个分支是一个框的预测值,表示生成的anchor距离真实框有多远,然后做NMS处理,这样就生成了候选区域,再去对候选区域做RoI Pooling,分类分支,回归分支预测等等等等,和FastRCNN就一样了。
Anchor(锚框)
特征图上每个点作为中心点,生成多个大小比例不同的边界框,这些框成为Anchor。
ppt2
RPN的网络结构
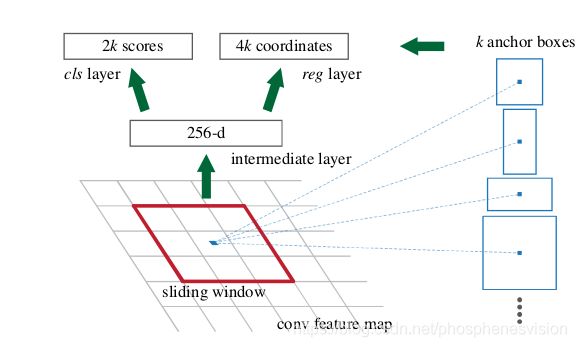
输入是前面backbone提取出来的特征图1 * 512 * 60 * 40
经过一个3 * 3的same卷积得到特征图1 * 256 * 60 * 40
再是两个分支
第一个,分类分支,是一个1 * 1的卷积,分类分支得到结果为1 * 2k * 60 * 40,k就是预设锚框的个数,这里k=9,2是用来预测正负的。
第二个,回归分支,也是一个1 * 1的卷积,回归分支得到结果为1 * 4k * 60 * 40,k就是预设锚框的个数,这里k=9,4是用来预测这个锚框与真实框的四条边的距离。
最终这两个分支结合,取正的锚框作为提取的候选区域放到下面的网络卷积中。
ppt3
RPN如何训练?
分类分支的标记:正样本是与某一个真实框IoU最大的anchor或与任意真实框IoU>0.7的anchor,负样本是与所有真实框IoU<0.3的anchor。这样的结果是,每一个真实框必有大于等于一个anchor与之对应,而对于每一个anchor而言,不保证有真实框与之对应,可能有可能没有。实际操作正负样本的数量非常多,需要采样,共采样256个样本,从正样本中随机采样,采样个数不超过128个,从负样本中随机采样,补齐这256个样本。正样本监督信息设为1,负样本设为0。
回归分支的标记:表示锚框到真实框的偏移量有多远,学习的参数 [ t x ∗ , t y ∗ , t w ∗ , t h ∗ ] [t_x^*,t_y^*,t_w^*,t_h^*] [tx∗,ty∗,tw∗,th∗]为使用公式来表示的
t x ∗ = ( x ∗ − x a ) / w a , t y ∗ = ( y ∗ − y a ) / h a , t w ∗ = l o g ( w ∗ / w a ) , t h ∗ = l o g ( h ∗ / h a ) t_x^* = (x^∗ − x_a )/w_a , t^∗_y = (y^∗ − y _a )/h_a , \\ t^∗_w = log(w^∗ /w_a ), t^∗_h = log(h^∗ /h_a ) tx∗=(x∗−xa)/wa,ty∗=(y∗−ya)/ha,tw∗=log(w∗/wa),th∗=log(h∗/ha)
带上标星号的表示是真实框的参数,带下标a的表示锚框的参数。
RPN的损失函数?
分类分支 L c l s L_{cls} Lcls用二值交叉熵Binary Cross Entropy,回归分支 L r e g L_{reg} Lreg用Smooth L1 Loss。
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L(\{p_i \}, \{t_i \}) = \frac{1}{N_{cls}}\sum_iL_{cls} (p_i , p^∗_i ) + \lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg} (t_i , t^∗_i ) L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
带上标星号的表示是真实框的参数,不带上标星号的表示预测出来的参数。回归分支有一个 p i ∗ p_i^* pi∗表示真实值的正负,要么是1,要么是0,换句话说,回归分支只考虑正样本,负样本由于前面 p i ∗ = 0 p_i^*=0 pi∗=0的作用被直接置零了。
Smooth L1 Loss
L r e g ( t , t ∗ ) = ∑ j ∈ { x , y , w , h } s m o o t h L 1 ( t j − t j ∗ ) L_{reg} (t , t^∗ ) = \sum_{j\in\{x,y,w,h\}}smooth_{L_1}(t_j - t^∗_j) Lreg(t,t∗)=j∈{x,y,w,h}∑smoothL1(tj−tj∗)s m o o t h L 1 ( x ) = { 0.5 x 2 ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e smooth_{L_1}(x) = \begin{cases} 0.5x^2 & |x| < 1 \\ |x|-0.5 & otherwise \end{cases} smoothL1(x)={0.5x2∣x∣−0.5∣x∣<1otherwise
d s m o o t h L 1 d x = { x ∣ x ∣ < 1 ± 1 o t h e r w i s e \frac{d smooth_{L_1}}{dx} = \begin{cases} x & |x| < 1 \\ \pm1 & otherwise \end{cases} dxdsmoothL1={x±1∣x∣<1otherwise
采用该损失函数的原因:预测框与监督信息差别过大时,梯度值不至于过大,预测框与监督信息差别很小时,梯度值足够小。
ppt4
如何将两个分支的内容结合起来生成候选区域
将回归分支信息与分类分支对应起来,再与anchor结合起来
全部归一化至图像区域内
面积太小的过滤掉
得分太小的过滤掉
NMS把相近的候选区域过滤掉
再次把得分小的过滤掉
ppt5
RoI Pooling
SPPNet 首先提出来的。
每个区域分成若干小块,每个小块得到该区域的最大值。然后就经过FC层得到了每个候选区域的特征。
问题与不足,长宽不可以整除,需要取整操作,因此,划分的区域的大小不一样,可能会产生误差,改进算法RoI Align,双线性差值法替代取整操作。
BBox Head训练与RPN训练差不多
损失函数由两部分组成,分类分支用softmax交叉熵Softmax Cross Entropy,回归分支 L r e g L_{reg} Lreg用Smooth L1 Loss。
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L(\{p_i \}, \{t_i \}) = \frac{1}{N_{cls}}\sum_iL_{cls} (p_i , p^∗_i ) + \lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg} (t_i , t^∗_i ) L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
总体的损失函数
L t o t a l = L r p n + L b o x h e a d L_{total} = L_{rpn}+L_{boxhead} Ltotal=Lrpn+Lboxhead
Faster RCNN的预测速度
| Network | Speed(second) |
|---|---|
| RCNN | 49 |
| SPPNet | 4.3 |
| FastRCNN | 2.3 |
| FasterRCNN | 0.2 |
ppt6
综上所述,总结Faster RCNN
首先图片经过backbone提取出特征图,特征图输入到RPN网络,为特征图的每一个像素分配预先设定的N个anchor,经过3 * 3卷积和两个1 * 1卷积分支,得到每一个像素的每一个anchor的二值正负和与真实框的偏移量,最终是一个解码过程,选择score比较高的anchor和二值正负,偏移量进行结合作为候选区域输入到下面的网络,这就是第一个阶段。
第二个阶段,把上面输入过来的候选区域继续通过RoI Align搞成统一大小的特征图,再经过两个分支分别预测该候选区域的类别class head分支和该候选区域与真实框的偏移bbox head分支。
所以RPN相当于是对图像做了一次粗略分类,只分类除了二值正负和粗略的偏移量,后面的网络是精细分类,分类80个类别和精细的偏移量。
FPN
ppt1
FPN
Feature pyramid networks for object detection
2017 CVPR
引用次数:4646
作者:Tsung-Yi Lin Facebook AI Research (FAIR) && Cornell University and Cornell Tech, USA
联系方式:Website: https://vision.cornell.edu/se3/people/tsung-yi-lin/
论文复现:https://github.com/jwyang/fpn.pytorch
期望解决的事情:期望网络可以具有多尺度检测的能力,既可以检测比较大的物体,也可以检测比较小的物体。大物体用深层的网络预测,小物体用浅层的网络预测。

本论文的主要思想,原来的FasterRCNN从Backbone输出的特征图只有一个,而FPN则用了五个尺度的特征图{P2, P3, P4, P5, P6}预测不同大小的物体,P6就是P5下采样得到的,在图中没有标示出来,后面YOLOv3也是这种思想。
RoI = 感兴趣区域 = Proposal = 候选区域
ppt2
添加了这个FPN层后网络的变化,需要怎么改

Anchor的变化,原来只是在一张特征图上聚类anchor,现在聚类不同大小的anchor分别匹配到不同的特征图上面。
RPN网络的变化,原来是输入一张特征图,经过3 * 3卷积,再通过两个1 * 1卷积得到分类分支和回归分支,现在是要输入多张特征图,值得注意的是,虽然输入了五张特征图,但是并不是训练五个单独的RPN网络,还是训练一个RPN网络,这些卷积参数,五个特征图是共享的。这五个特征图得到的RoI也就是候选区域进行合并,根据它们的score进行排序,只取前2000个候选区域进入到下面的运算中。
RoI Align的变化:原来是RoI在特征图上进行特征抽取的过程,并且通过双线性插值的方法去除了坐标点取整的过程。现在是把上一步提取的候选区域分配到自己对应的层级上面,分配到的层级k为
k = k 0 + log 2 ( w h / 224 ) k = k_0 + \log_2(\sqrt{wh}/224) k=k0+log2(wh/224)
k为分配的层级,k0为基准层,wh为候选区域的尺寸
CascadeRCNN
ppt1
Cascade RCNN
Cascade r-cnn: Delving into high quality object detection
2018 CVPR
引用次数:682
作者:Zhaowei Cai UC San Diego, USA
联系方式:Email: [email protected]
代码复现:https://github.com/zhaoweicai/cascade-rcnn
主要思想:对IoU的分析与改进。
Faster RCNN中,第一个是训练标注的时候,所有的anchor与真实框做匹配,IoU大于0.7为正样本,小于0.3为负样本;第二个是做Roi Align的时候,RPN提取的候选区域与真实框需要继续做匹配,IoU大于0.5为正样本,小于0.5为负样本。

本论文针对于第二个阶段做Roi Align的时候,
如果单纯提高这一阶段的阈值,效果会大幅下降,原因是
提高阈值,正样本的数量减少,训练过拟合。
输入的候选区域与设定的IoU阈值不匹配。
因此分析这个IoU阈值的选取,左边这个图是说这三条线分别代表阈值选取的不同值
右边这个图的这三条线分别代表输入图像的IoU的值。
注意左边和右边三条线代表的是不一样的。
ppt2
Cascade RCNN的原理
三种备选方案。

-
将head网络中的bbox得到的偏移量与输入的RoI解码得到一个新的边界框,作为下一个阶段RoI Align的输入,重新训练一个head网络,一共循环三次。
-
结构与第一个类似,只是这三次循环中的三个head网络的权重是相同的。但是这个方案是不可以的,因为三次循环中的RoI的质量实在逐渐提高的,如果用相同的head网络权重去预测的话,就不能满足不同阶段的RoI变换。
-
第三种是同样的一个RoI,设置不同的IoU阈值,引出三个预测分支。问题在于输入的IoU的分布是不均匀的,低质量的RoI比较多,因此只有低质量的那个分支效果比较好,其余两个分支很容易出现过拟合现象。
综上所述,选择的是第一种备选方案。但是比较费事。因为毕竟head部分比原来增加了三倍。
预测的时候是把第三个head网络中的偏移量作为偏移量的输出,种类的置信度是三个head网络的平均。
LibraRCNN
ppt1
Libra RCNN
Libra r-cnn: Towards balanced learning for object detection
2019 CVPR
引用次数:136
作者:Jiangmiao Pang Zhejiang University, China
联系方式:Email: [email protected]
代码复现:https://github.com/OceanPang/Libra_R-CNN
分析RCNN的不平衡问题。
特征层面:由backbone提取出来的不同尺度的特征图如何被充分利用
采样层面:FPN提取的候选区域在输入到后续的head网络时进行的采样是否具有代表性
目标层面:设计的损失函数能否很好引导检测器收敛
一个一个来分析
第一个特征层面,对FPN结构做一个平衡

将FPN采样的特征图统一到C4的尺度上面,再通过求平均值的方法融合所有特征图,使用non-local的结构对融合特征进一步加强。将加强后的特征图与原始各个层级的特征图加和,得到新的FPN网络结构的输出。
non local
普通的卷积核一般只有3 * 3或者5 * 5或者其他的,感受野比较小,只能看到local的一些信息,non-local的方法就是把卷积操作的感受野做一个加强操作。
第二个采样层面,新的采样策略
通常会预设样本个数x个,然后从IoU阈值大于0.5采样正样本,数量不超过x/2,再把小于0.5采样为负样本,补齐x个样本数。问题,正样本中的类别出现失衡,负样本中IoU分配出现失衡,大部分IoU集中在小于0.5的范围。
新的做法,正样本采样策略,提前计算好每个类别需要采样的个数,按照类别进行采样。负样本采样策略,再对这些负样本的IoU设置一个阈值,比如是0.1,这时候负样本就有了两个区间,0-0.1和0.1-0.5,首先对0.1-0.5的区间进行采样,分成N个桶,比如分成两个桶,0.1-0.3是一个桶,0.3-0.5是一个桶,计算好分别在这两个桶内各自采样的个数,这样就能均匀采样了,如果采样的个数不够预设的个数的话就用0-0.1那个区间补齐;剩下对0-0.1那个区间进行采样的时候就采用随机采样。
ppt2
第三个损失层面
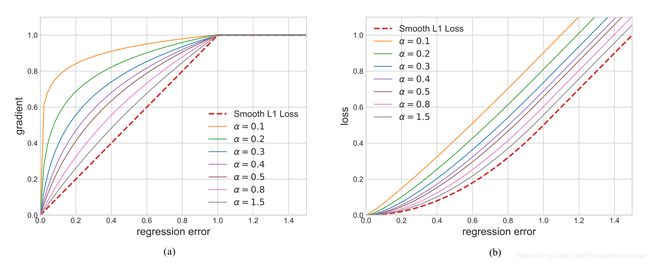
只改回归分支的损失函数
原来的Smooth L1 Loss从梯度来看,梯度较大的样本的梯度为1, 梯度较小的样本的梯度很小,这两个梯度差距较大,学习能力就不相同,因此引入了Balanced L1 Loss
L b ( x ) = { α b ( b ∣ x ∣ + 1 ) ln ( b ∣ x ∣ + 1 ) − α ∣ x ∣ ∣ x ∣ < 1 γ ∣ x ∣ + C o t h e r w i s e L_b(x) = \begin{cases} \frac{\alpha}{b}(b|x| + 1) \ln(b|x| + 1) - \alpha|x| & |x| < 1 \\ \gamma|x| + C & otherwise \end{cases} Lb(x)={bα(b∣x∣+1)ln(b∣x∣+1)−α∣x∣γ∣x∣+C∣x∣<1otherwise
Other Optimization Method
ppt1
优化策略分享

CIoU Loss,考虑物体间中心点距离和长宽比,更形象的表示IoU。