1.问题描述
中文分词 (Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
而对于中文分词也有很多种算法,基本算法主要分为基于词典的方法、基于统计的方法和基于规则的方法。
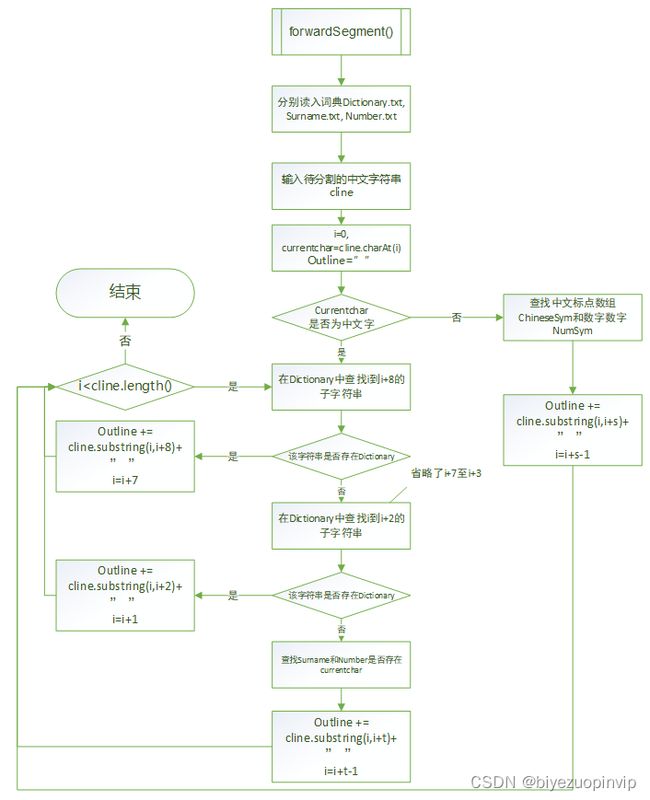
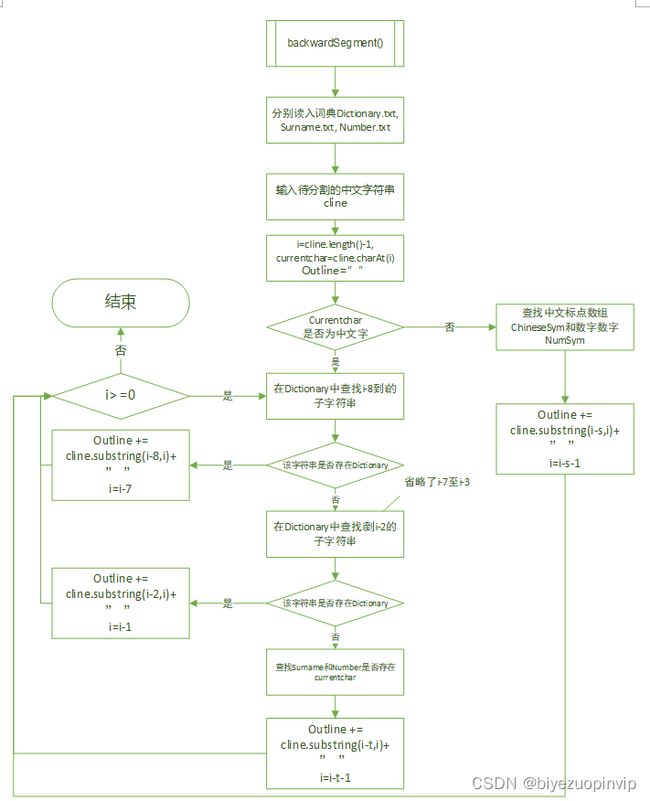
基于词典的方法是指按照一定策略将待分析的汉字串与一个“大机器词典”中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。按照扫描方向的不同包括正向匹配和逆向匹配,按照长度的不同分为最大匹配和最小匹配。在基于词典的方法中,我们采用了正向最大匹配和逆向最大匹配的方法进行分词。
而基于统计的分词方法,没有词典,主要思想是在上下文中,相邻的字同时出现的次数越多,就越可能构成一个词,因此字与字相邻出现的概率或频率能较好的反映词的可信度。主要的统计模型包括N元文法模型(N-gram),隐马尔科夫模型(Hidden Markov Model, HMM)。在基于统计的分词方法中,我们使用了隐马尔科夫模型来进行分词。
基于规则的方法,主要思想就是通过模拟人对句子的理解,达到识别词的效果,基本思想是语义分析,句法分析,利用句法信息和语义信息对文本进行分词。自动推理,并完成对未登录词的补充是其优点。但是这种方法现在发展还不成熟,需要继续发展和研究。
因此在我们的中文分词系统中,采用了基于词典的方法:正向最大匹配和逆向最大匹配,以及基于统计的方法中的隐马尔科夫(HMM)模型。
2.相关工作
现如今已经有很多的开源中分分词系统,而且效果都还不错。下面介绍几种比较常见的中文分词项目。
SCWS,Hightman开发的一套基于词频词典的机械中文分词引擎,它能将一整段的汉字基本正确的切分成词。采用的是采集的词频词典,并辅以一定的专有名称,人名,地名,数字年代等规则识别来达到基本分词,经小范围测试大概准确率在 90% ~ 95% 之间,已能基本满足一些小型搜索引擎、关键字提取等场合运用。45Kb左右的文本切词时间是0.026秒,大概是1.5MB文本/秒,支持PHP4和PHP 5。
ICTCLAS,这是最早的中文开源分词项目之一,ICTCLAS在国内973专家组组织的评测中活动获得了第一名,在第一届国际中文处理研究机构SigHan组织的评测中都获得了多项第一名。ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M。ICTCLAS全部采用C/C++编写,支持Linux、FreeBSD及Windows系列操作系统,支持C/C++、C#、Delphi、Java等主流的开发语言。
HTTPCWS,是一款基于HTTP协议的开源中文分词系统,目前仅支持Linux系统。HTTPCWS 使用“ICTCLAS 3.0 2009共享版中文分词算法”的API进行分词处理,得出分词结果。HTTPCWS 将取代之前的 PHPCWS 中文分词扩展。
3.系统框架和算法设计
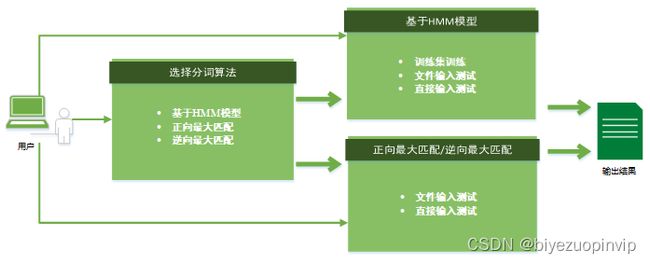
3.1系统整体框架
系统主要包括选择分词算法和进行数据的测试。首先需要选择进行分词的算法,包括基于HMM模型的分词算法,正向最大匹配分词算法和逆向最大匹配分词算法。选择了分词算法之后即可进行分词操作。
若选择的是基于HMM模型的分词算法,需要先进行训练集的训练,得到训练的统计数据,然后再进行数据测试。数据测试包括了文件输入测试,进行大规模数据的测试,也包括了直接输入测试,测试一句话或多句话进行简单测试。
对于正向最大匹配和逆向最大匹配则不需要进行训练集的训练,因为其是基于词典的方法,需要词典,而词典我们已经事先载入程序中了。正向最大匹配和逆向最大匹配也包括了文件输入测试和直接输入测试。
系统的整体框架如图3-1所示。
部分代码如下:
package mainframe;
import hmm.hmmmain.hmmmain;
import java.awt.Font;
import java.awt.Graphics;
import java.awt.GridLayout;
import java.awt.Image;
import java.awt.Toolkit;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.StringTokenizer;
import java.util.Timer;
import java.util.TimerTask;
import javax.swing.ButtonGroup;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFileChooser;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JRadioButton;
import javax.swing.JScrollPane;
import javax.swing.JTabbedPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.border.EtchedBorder;
import javax.swing.border.TitledBorder;
import lexicon.Segment;
@SuppressWarnings("serial")
public class CWS_frame extends JFrame{
//定义组件
JLabel label_title=new JLabel("CWJT中文分词系统");
JPanel algorithm_select_panel;
JRadioButton algorithm_jrb_hmm;
JRadioButton algorithm_jrb_zhengxiang;
JRadioButton algorithm_jrb_nixiang;
ButtonGroup bg_algorithm;
JLabel label_showalgorithm=new JLabel("你选择的算法是: 基于HMM模型");
JPanel input_panel;
JTabbedPane hmm_tabbe=new JTabbedPane();
JPanel hmm_tabbe_pane_train=new JPanel();
JPanel hmm_tabbe_pane_fileinput=new JPanel();
JPanel hmm_tabbe_pane_input=new JPanel();
JLabel label_train_title = new JLabel("选择训练集");
static JTextField jTextField_train=new JTextField();
JButton scan_train=new JButton("浏览文件");
JButton train_start=new JButton("点击训练");
JLabel label_test_title = new JLabel("选择测试集");
JLabel label_result_title = new JLabel("结果集存储目录");
JButton scan_test=new JButton("浏览文件");
JButton scan_result=new JButton("浏览目录");
JButton test_start = new JButton("开始分词");
static JTextField jTextField_test=new JTextField();
static JTextField jTextField_result=new JTextField();
JLabel label_inputdata = new JLabel("输入测试数据:");
JTextArea textarea_input = new JTextArea();
JLabel label_outputdata = new JLabel("输出结果:");
JTextArea textarea_ouptput = new JTextArea();
JButton seg_start = new JButton("开始分词");
static JLabel label_wait ;
JLabel label_train_wait;
//定义一个定时器
Timer wait_time = null, seg_threadtime=null;
static int count_dot=0;
Timer train_wait_time=null,train_time=null;
int train_count_dot = 0;
//设置滚动条用于装短信内容文本域,使其产生滚动条效果
JScrollPane scrollPane;
JScrollPane outscrollPane;
static JPanel main_panel;
//构造函数
public CWS_frame(){
setTitle("中文分词系统");
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setResizable(false);
int width=550;
int height=500;
setSize(width,height);
//设置窗体在屏幕出现的位置
setLocation(400, 100);
//设置title
int label_title_x=200;
int label_title_y=25;
int label_title_width=250;
int label_title_height=30;
int label_train_x=60;
int label_train_y=50;
int label_train_width=80;
int label_train_height=25;
int label_test_x=50;
int label_test_y=40;
int label_test_width=100;
int label_test_height=25;
int label_result_x=50;
int label_result_y=70;
int label_result_width=100;
int label_result_height=25;
int JTextField_train_x=140;
int JTextField_train_y=50;
int JTextField_train_width=150;
int JTextField_train_height=25;
int JTextField_test_x=150;
int JTextField_test_y=40;
int JTextField_test_width=150;
int JTextField_test_height=25;
int JTextField_result_x=150;
int JTextField_result_y=70;
int JTextField_result_width=150;
int JTextField_result_height=25;
int alg_select_x=40;
int alg_select_y=60;
int alg_select_width=450;
int alg_select_height=80;
int label_showalg_x=180;
int label_showalg_y=140;
int label_showalg_width=200;
int label_showalg_height=20;
int input_x=40;
int input_y=170;
int input_width=450;
int input_height=250;
int scan_train_x=300;
int scan_train_y=50;
int scan_train_width=80;
int scan_train_height=23;
int train_start_x=180;
int train_start_y=110;
int train_start_width=90;
int train_start_height=25;
int test_start_x=180;
int test_start_y=130;
int test_start_width=90;
int test_start_height=25;
int scan_test_x=310;
int scan_test_y=40;
int scan_test_width=80;
int scan_test_height=23;
int scan_result_x=310;
int scan_result_y=70;
int scan_result_width=80;
int scan_result_height=23;
int label_inputdata_x=20;
int label_inputdata_y=10;
int label_inputdata_width=100;
int label_inputdata_height=20;
int textarea_input_x=20;
int textarea_input_y=30;
int textarea_input_width=180;
int textarea_input_height=120;
int label_outputdata_x=230;
int label_outputdata_y=10;
int label_outputdata_width=100;
int label_outputdata_height=20;
int textarea_output_x=230;
int textarea_output_y=30;
int textarea_output_width=180;
int textarea_output_height=120;
int seg_start_x=180;
int seg_start_y=160;
int seg_start_width=90;
int seg_start_height=25;
int label_wait_x=170;
int label_wait_y=160;
int label_wait_width=120;
int label_wait_height=25;
int label_train_wait_x=170;
int label_train_wait_y=150;
int label_train_wait_width=120;
int label_train_wait_height=25;
main_panel=new JPanel();
//main_panel.setLayout(new FlowLayout(FlowLayout.CENTER,10,10));
main_panel.setLayout(null);
algorithm_select_panel=new JPanel();
algorithm_select_panel.setBorder(new TitledBorder(new EtchedBorder(), "选择分词算法"));
bg_algorithm=new ButtonGroup();
algorithm_jrb_hmm=new JRadioButton("基于HMM模型");
algorithm_jrb_zhengxiang=new JRadioButton("正向最大匹配");
algorithm_jrb_nixiang=new JRadioButton("逆向最大匹配");
algorithm_jrb_hmm.setSelected(true);
bg_algorithm.add(algorithm_jrb_hmm);
bg_algorithm.add(algorithm_jrb_zhengxiang);
bg_algorithm.add(algorithm_jrb_nixiang);
input_panel=new JPanel();
//input_panel.setLayout(null);
input_panel.setLayout(new GridLayout(1, 1));
input_panel.setBorder(new TitledBorder(new EtchedBorder(), "输入数据"));
scrollPane=new JScrollPane(textarea_input);
outscrollPane=new JScrollPane(textarea_ouptput);
textarea_ouptput.setEnabled(false);
hmm_tabbe_pane_train.setLayout(null);
hmm_tabbe_pane_fileinput.setLayout(null);
hmm_tabbe_pane_input.setLayout(null);
hmm_tabbe.addTab("使用训练集训练", hmm_tabbe_pane_train);
hmm_tabbe.addTab("文件输入测试集", hmm_tabbe_pane_fileinput);
hmm_tabbe.addTab("直接输入测试数据", hmm_tabbe_pane_input);
//hmm_tabbe.setTabPlacement(LEFT_ALIGNMENT);
label_title.setFont(new Font("",Font.BOLD,15));
label_wait = new JLabel("");
label_train_wait=new JLabel("");
//定位
label_title.setBounds(label_title_x, label_title_y, label_title_width, label_title_height);
algorithm_select_panel.setBounds(alg_select_x, alg_select_y, alg_select_width, alg_select_height);
label_showalgorithm.setBounds(label_showalg_x, label_showalg_y, label_showalg_width, label_showalg_height);
input_panel.setBounds(input_x, input_y, input_width, input_height);
//algorithm_jrb_hmm.setLocation(alg_hmm_x, alg_hmm_y);
// algorithm_jrb_hmm.setBounds(alg_hmm_x, alg_hmm_y, alg_hmm_width, alg_hmm_height);
// algorithm_jrb_zhengxiang.setBounds(alg_zhengxiang_x, alg_zhengxiang_y, alg_zhengxiang_width, alg_zhengxiang_height);
label_train_title.setBounds(label_train_x, label_train_y, label_train_width, label_train_height);
label_test_title.setBounds(label_test_x, label_test_y, label_test_width, label_test_height);
label_result_title.setBounds(label_result_x, label_result_y, label_result_width, label_result_height);
jTextField_train.setBounds(JTextField_train_x, JTextField_train_y, JTextField_train_width, JTextField_train_height);
jTextField_test.setBounds(JTextField_test_x, JTextField_test_y, JTextField_test_width, JTextField_test_height);
jTextField_result.setBounds(JTextField_result_x, JTextField_result_y, JTextField_result_width, JTextField_result_height);
scan_train.setBounds(scan_train_x, scan_train_y, scan_train_width, scan_train_height);
train_start.setBounds(train_start_x, train_start_y, train_start_width, train_start_height);
scan_result.setBounds(scan_result_x, scan_result_y, scan_result_width, scan_result_height);
scan_test.setBounds(scan_test_x, scan_test_y, scan_test_width, scan_test_height);
test_start.setBounds(test_start_x, test_start_y, test_start_width, test_start_height);
label_inputdata.setBounds(label_inputdata_x, label_inputdata_y, label_inputdata_width, label_inputdata_height);
scrollPane.setBounds(textarea_input_x, textarea_input_y, textarea_input_width, textarea_input_height);
label_outputdata.setBounds(label_outputdata_x, label_outputdata_y, label_outputdata_width, label_outputdata_height);
outscrollPane.setBounds(textarea_output_x, textarea_output_y, textarea_output_width, textarea_output_height);
seg_start.setBounds(seg_start_x, seg_start_y, seg_start_width, seg_start_height);
label_wait.setBounds(label_wait_x, label_wait_y, label_wait_width, label_wait_height);
label_train_wait.setBounds(label_train_wait_x, label_train_wait_y, label_train_wait_width, label_train_wait_height);
//将组件加入到容器中
main_panel.add(label_title);
main_panel.add(algorithm_select_panel);
main_panel.add(input_panel);
algorithm_select_panel.add(algorithm_jrb_hmm);
algorithm_select_panel.add(algorithm_jrb_zhengxiang);
algorithm_select_panel.add(algorithm_jrb_nixiang);
input_panel.add(hmm_tabbe);
hmm_tabbe_pane_train.add(label_train_title);
hmm_tabbe_pane_train.add(jTextField_train);
hmm_tabbe_pane_train.add(scan_train);
hmm_tabbe_pane_train.add(train_start);
hmm_tabbe_pane_train.add(label_train_wait);
hmm_tabbe_pane_fileinput.add(label_test_title);
hmm_tabbe_pane_fileinput.add(label_result_title);
hmm_tabbe_pane_fileinput.add(test_start);
hmm_tabbe_pane_fileinput.add(scan_test);
hmm_tabbe_pane_fileinput.add(scan_result);
hmm_tabbe_pane_fileinput.add(jTextField_test);
hmm_tabbe_pane_fileinput.add(jTextField_result);
hmm_tabbe_pane_fileinput.add(label_wait);
hmm_tabbe_pane_input.add(label_inputdata);
hmm_tabbe_pane_input.add(scrollPane);
hmm_tabbe_pane_input.add(label_outputdata);
hmm_tabbe_pane_input.add(outscrollPane);
hmm_tabbe_pane_input.add(seg_start);
main_panel.add(label_showalgorithm);
//将容器加入到窗体中
add(main_panel);
/* wait_time = new Timer(500,new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
if(count_dot==0)
label_wait.setText("正在分词,请稍等");
else if(count_dot==1)
label_wait.setText("正在分词,请稍等.");
else if(count_dot==2)
label_wait.setText("正在分词,请稍等. .");
else if(count_dot==3)
label_wait.setText("正在分词,请稍等. . .");
JOptionPane.showMessageDialog(null,
"test","提示",
JOptionPane.INFORMATION_MESSAGE);
//count_dot=(count_dot+1)%4;
// System.out.println(count_dot);
}
});*/
algorithm_jrb_hmm.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
if(algorithm_jrb_hmm.isSelected()){
label_showalgorithm.setText("你选择的算法是: 基于HMM模型");
hmm_tabbe.removeAll();
hmm_tabbe.addTab("使用训练集训练", hmm_tabbe_pane_train);
hmm_tabbe.addTab("文件输入测试集", hmm_tabbe_pane_fileinput);
hmm_tabbe.addTab("直接输入测试数据", hmm_tabbe_pane_input);
hmm_tabbe.revalidate();
hmm_tabbe.repaint();
}
if(algorithm_jrb_zhengxiang.isSelected()){
label_showalgorithm.setText("你选择的算法是: 正向最大匹配");
}
if(algorithm_jrb_nixiang.isSelected()){
label_showalgorithm.setText("你选择的算法是: 逆向最大匹配");
}
}
});
algorithm_jrb_zhengxiang.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
if(algorithm_jrb_hmm.isSelected()){
label_showalgorithm.setText("你选择的算法是: 基于HMM模型");
}
if(algorithm_jrb_zhengxiang.isSelected()){
label_showalgorithm.setText("你选择的算法是: 正向最大匹配");
hmm_tabbe.removeAll();
//hmm_tabbe.addTab("使用训练集训练", hmm_tabbe_pane_train);
hmm_tabbe.addTab("文件输入测试集", hmm_tabbe_pane_fileinput);
hmm_tabbe.addTab("直接输入测试数据", hmm_tabbe_pane_input);
hmm_tabbe.revalidate();
hmm_tabbe.repaint();
}
if(algorithm_jrb_nixiang.isSelected()){
label_showalgorithm.setText("你选择的算法是: 逆向最大匹配");
}
}
});
algorithm_jrb_nixiang.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
if(algorithm_jrb_hmm.isSelected()){
label_showalgorithm.setText("你选择的算法是: 基于HMM模型");
}
if(algorithm_jrb_zhengxiang.isSelected()){
label_showalgorithm.setText("你选择的算法是: 正向最大匹配");
}
if(algorithm_jrb_nixiang.isSelected()){
label_showalgorithm.setText("你选择的算法是: 逆向最大匹配");
hmm_tabbe.removeAll();
//hmm_tabbe.addTab("使用训练集训练", hmm_tabbe_pane_train);
hmm_tabbe.addTab("文件输入测试集", hmm_tabbe_pane_fileinput);
hmm_tabbe.addTab("直接输入测试数据", hmm_tabbe_pane_input);
hmm_tabbe.revalidate();
hmm_tabbe.repaint();
}
}
});
//输入hmm模型的训练集文件进行训练
scan_train.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
File dicFile = openFile();
if(dicFile == null)
return;
jTextField_train.setText(dicFile.getAbsolutePath());
//写要执行的操作
//loadDic(dicFile);
return;
}
});
//输入测试集文件
scan_test.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
File dicFile = openFile();
if(dicFile == null)
return;
jTextField_test.setText(dicFile.getAbsolutePath());
}
});
//输入存储结果集目录
scan_result.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
File dicDir = openDir();
if(dicDir == null)
return;
jTextField_result.setText(dicDir.getAbsolutePath());
}
});
//点击通过选择输入文件进行分词的按钮,通过载入测试集文件进行大规模数据的分词
test_start.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
String temp_test_str = jTextField_test.getText();
if(temp_test_str.equals("")){
JOptionPane.showMessageDialog(null,
"请选择测试集文件!","提示",
JOptionPane.INFORMATION_MESSAGE);
return ;
}
String temp_result_str = jTextField_result.getText();
if(temp_result_str.equals("")){
JOptionPane.showMessageDialog(null,
"请选择存储结果集目录!","提示",
JOptionPane.INFORMATION_MESSAGE);
return ;
}
count_dot = 0;
//有两种定义定时器的方法,分别在不同的java包内
//定义等待提示的定时器
wait_time=new Timer(true);
TimerTask task=new TimerTask() {
@Override
public void run() {
// TODO Auto-generated method stub
label_wait.setText(wait_seg());
// System.out.println(wait_seg());
}
};
wait_time.schedule(task, 0, 1000);
//再定义个定时器,相当于再开一个线程
seg_threadtime = new Timer(true);
TimerTask task2 = new TimerTask() {
@Override
public void run() {
// TODO Auto-generated method stub
//进行分词
Segmentation();
}
};
seg_threadtime.schedule(task2, 0);
}
});
//通过直接输入数据进行分词
seg_start.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
String jtextarea_str = textarea_input.getText();
if(jtextarea_str.equals("")){
JOptionPane.showMessageDialog(null,
"请输入要测试的数据!","提示",
JOptionPane.INFORMATION_MESSAGE);
return ;
}
if(algorithm_jrb_zhengxiang.isSelected()||algorithm_jrb_nixiang.isSelected()){
//token,没有指定分隔符默认情况下是空格换行等
StringTokenizer tokens = new StringTokenizer(jtextarea_str);
//创建分词类的对象
Segment seg=new Segment();
String output_str="";
while(tokens.hasMoreElements()){
//System.out.println(tokens.nextToken());
String temp_str=tokens.nextToken();
String temp_seg="";
//如果选中的是最大正向匹配
if(algorithm_jrb_zhengxiang.isSelected()){
temp_seg=seg.forwardSegment(temp_str);
}
//如果选中的是最大逆向匹配
if(algorithm_jrb_nixiang.isSelected()){
temp_seg=seg.backwardSegment(temp_str);
}
output_str += temp_seg;
output_str += "\n";
}
textarea_ouptput.setText(output_str);
}
//使用hmm模型进行分词
if(algorithm_jrb_hmm.isSelected()){
// String jtextarea_str = textarea_input.getText();
//System.out.println(testfile);
String output="";
hmmmain hmmmodel = new hmmmain();
output = hmmmodel.Inputtest(jtextarea_str);
textarea_ouptput.setText(output);
}
}
});
//hmm模型训练
train_start.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
// TODO Auto-generated method stub
String temp_train_str = jTextField_train.getText();
if(temp_train_str.equals("")){
JOptionPane.showMessageDialog(null,
"请选择训练集文件!","提示",
JOptionPane.INFORMATION_MESSAGE);
return ;
}
train_count_dot = 0;
//定义等待提示的定时器
train_wait_time=new Timer(true);
TimerTask task=new TimerTask() {
@Override
public void run() {
// TODO Auto-generated method stub
label_train_wait.setText(train_wait());
// System.out.println(wait_seg());
}
};
train_wait_time.schedule(task, 0, 500);
//再定义个定时器,相当于再开一个线程
train_time = new Timer(true);
TimerTask task2 = new TimerTask() {
@Override
public void run() {
// TODO Auto-generated method stub
//进行训练
hmmmain hmmmodel = new hmmmain();
String train_str = jTextField_train.getText();
hmmmodel.Trainset(train_str);
JOptionPane.showMessageDialog(null,
"训练结束,可进行分词","提示",
JOptionPane.INFORMATION_MESSAGE);
label_train_wait.setText("");
train_wait_time.cancel();
}
};
train_time.schedule(task2, 0);
return ;
}
});
}
//同步
public static synchronized String wait_seg(){
String show_wait = "";
if(count_dot==0)
show_wait = "正在分词,请稍等";
// label_wait.setText("正在分词,请稍等");
else if(count_dot==1)
show_wait = "正在分词,请稍等.";
// label_wait.setText("正在分词,请稍等.");
else if(count_dot==2)
show_wait = "正在分词,请稍等. .";
// label_wait.setText("正在分词,请稍等. .");
else if(count_dot==3)
show_wait = "正在分词,请稍等. . .";
// label_wait.setText("正在分词,请稍等. . .");
count_dot = (count_dot+1)%4;
// System.out.println(count_dot);
return show_wait;
//repaint();
//revalidate();
// JOptionPane.showMessageDialog(null,
// "test","提示",
// JOptionPane.INFORMATION_MESSAGE);
}
public synchronized String train_wait(){
String show_wait = "";
if(train_count_dot==0)
show_wait = "正在训练,请稍等";
else if(train_count_dot==1)
show_wait = "正在训练,请稍等.";
else if(train_count_dot==2)
show_wait = "正在训练,请稍等. .";
else if(train_count_dot==3)
show_wait = "正在训练,请稍等. . .";
train_count_dot = (train_count_dot+1)%4;
return show_wait;
}
//通过输入测试集文件进行大规模数据的分词
private void Segmentation(){
if(algorithm_jrb_zhengxiang.isSelected()||algorithm_jrb_nixiang.isSelected()){
//创建分词类的对象
Segment seg=new Segment();
InputStreamReader inputdata;
BufferedReader in;
String str;
String testfile=jTextField_test.getText();
System.out.println(testfile);
String resultdir=jTextField_result.getText();
try {
inputdata = new InputStreamReader (new FileInputStream(testfile),"UTF-8");
in = new BufferedReader(inputdata);
FileOutputStream out = null;
resultdir += "\\CWS_truth_utf8";
out = new FileOutputStream(new File(resultdir));
while((str=in.readLine())!= null){
String temp_seg="";
if(algorithm_jrb_zhengxiang.isSelected()){
temp_seg=seg.forwardSegment(str);
}
if(algorithm_jrb_nixiang.isSelected()){
temp_seg=seg.backwardSegment(str);
}
out.write(temp_seg.getBytes("UTF-8"));
out.write("\r\n".getBytes("UTF-8"));
}
//关闭定时器
// wait_time.stop();
inputdata.close();
out.close();
JOptionPane.showMessageDialog(null,
"分词结束,请在"+resultdir+"查找","提示",
JOptionPane.INFORMATION_MESSAGE);
} catch (UnsupportedEncodingException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
//使用hmm模型进行分词
if(algorithm_jrb_hmm.isSelected()){
String testfile=jTextField_test.getText();
//System.out.println(testfile);
String resultdir=jTextField_result.getText();
resultdir += "\\CWS_truth_utf8";
hmmmain hmmmodel = new hmmmain();
hmmmodel.Testset(testfile, resultdir);
JOptionPane.showMessageDialog(null,
"分词结束,请在"+resultdir+"查找","提示",
JOptionPane.INFORMATION_MESSAGE);
}
//
label_wait.setText("");
wait_time.cancel();
}
//打开文件(数据、词典或者语料库)
private File openFile(){
JFileChooser chooser = new JFileChooser();//文件选择对话框
int ret = chooser.showOpenDialog(this);
if (ret != JFileChooser.APPROVE_OPTION) {
return null;
}
File f = chooser.getSelectedFile();
if (f.isFile() && f.canRead())
{
return f;
}
else
{
JOptionPane.showMessageDialog(this,
"Could not open file: " + f,
"Error opening file",
JOptionPane.ERROR_MESSAGE);
return null;
}
}
//打开目录
private File openDir(){
JFileChooser parseDir = new JFileChooser();
parseDir.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY);
int ret = parseDir.showOpenDialog(this);
if(ret !=JFileChooser.APPROVE_OPTION)
return null;
File f=parseDir.getSelectedFile();
if(f.exists())
return f;
else{
JOptionPane.showMessageDialog(this,
"Could not open directory: " + f,
"Error opening directory",
JOptionPane.ERROR_MESSAGE);
return null;
}
}
//重写JPanel容器添加背景图片
class MainPanel extends JPanel{
ImageIcon background = new ImageIcon("images\\backimg.jpg");//加载图片
Image im=Toolkit.getDefaultToolkit().getImage("images\\backimg.jpg");
public void paintComponent(Graphics g) {
g.drawImage(im, 0, 0, this);
}
}
}
效果图展示

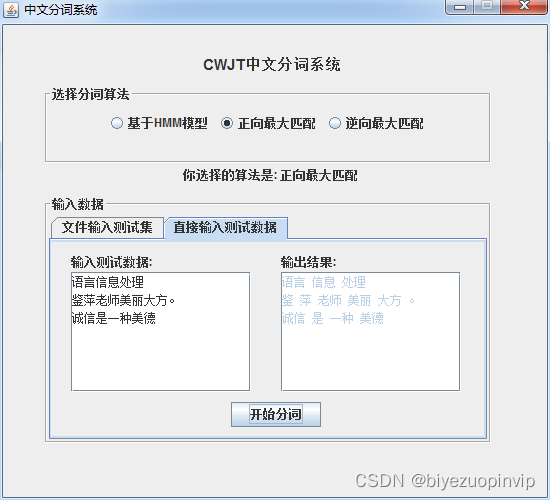




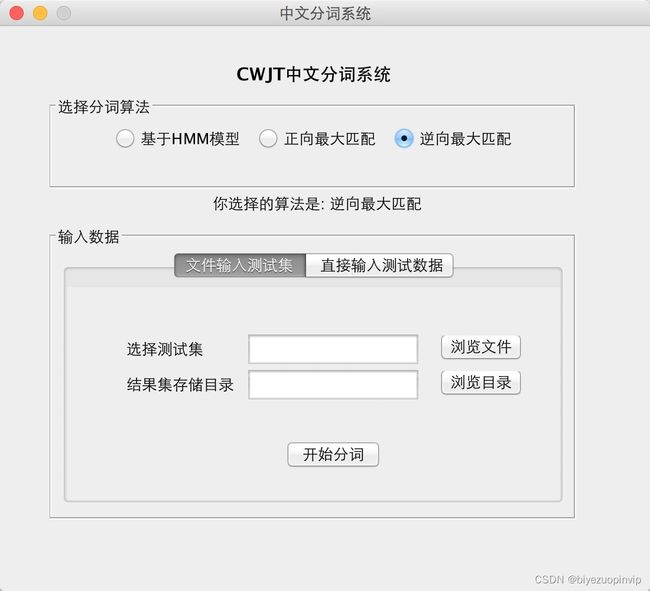
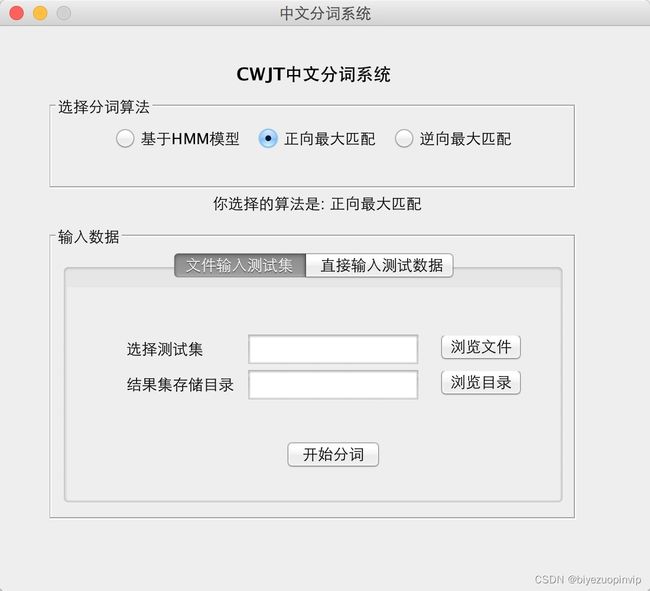


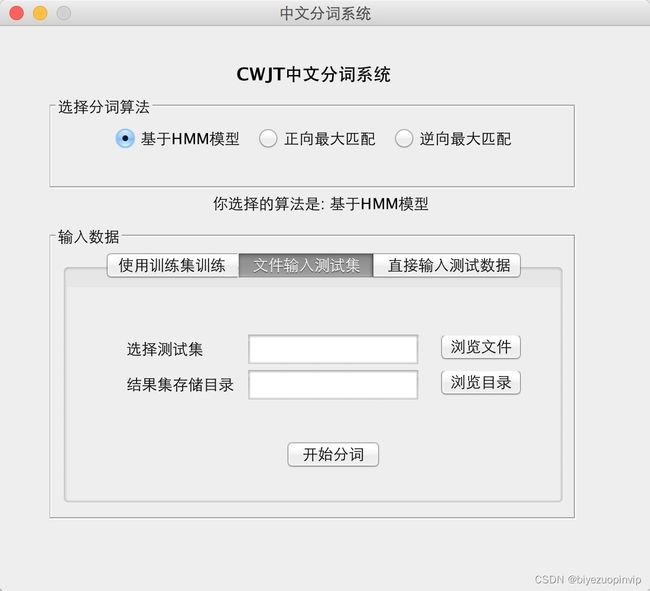



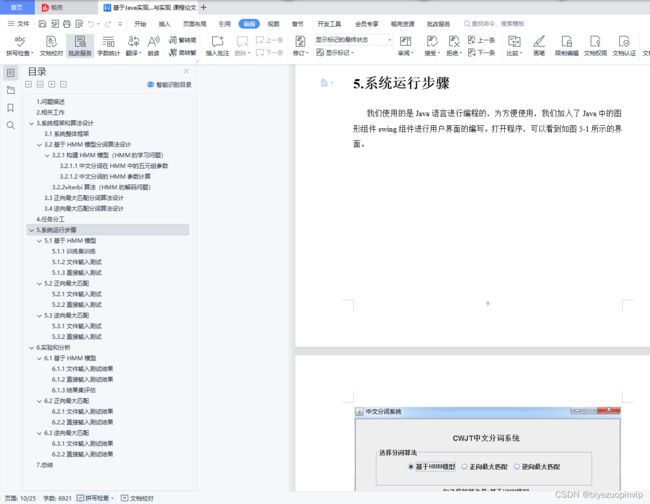
到此这篇关于基于Java实现中文分词系统的示例代码的文章就介绍到这了,更多相关Java中文分词系统内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!