YOLOv5手把手教你制作VOC格式数据集与模型训练
引言
2020年2月YOLO之父Joseph Redmon宣布退出计算机视觉研究领域,2020 年 4 月 23 日YOLOv4 发布,2020 年 6 月 10 日YOLOv5发布。

YOLOv5源代码:https://github.com/ultralytics/yolov5
如果接触过目标检测算法框架,相信大家对YOLOv5再熟悉不过了,并且根据不同的项目的背景下,制作自己的数据集,是我们必不可少的一步。废话不多说,下面手把手的教你制作自己的训练数据集。
数据预处理
1. 视频–>图像
一般我们拿到手的是视频,或者是图像;对于视频,我们根据项目的需求,把视频先转换成图像。新建一个images文件夹用于存放图像;新建一个Annotations文件夹用于存放标注数据后对应的Xml数据;新建一个labels文件夹用于存放已经标注过的图像源与对应的Xml文件文件名与路径,为其后模型训练做准备。
本文images和Xml文件夹的路径为 D:/inspectionData/VOCData/。
存放视频的路径为 D:/inspectionData/video/10.10.0.36_01_20210729205306871.mp4
【注:如果拿到手的源数据是图像,则省略此步骤】

代码
import cv2
import numpy as np
vc = cv2.VideoCapture(r'D:/inspectionData/video/10.10.0.36_01_20210729205306871.mp4') # 读入视频文件
c = 1
if vc.isOpened(): # 判断是否正常打开
rval, frame = vc.read()
else:
rval = False
timeF = 6 # 视频帧计数间隔频率
while rval: # 循环读取视频帧
rval, frame = vc.read()
if (c % timeF == 0): # 每隔timeF帧进行存储操作
# cv2.imshow('pic',frame)
cv2.imwrite(r'D:/inspectionData/VOCData/images/' + str('hat_') + str(c) + '.jpg', frame) # 存储为图像
c = c + 1
cv2.waitKey(1)
vc.release()
注: 在运行前需要修改对应的视频路径和存放数据集的路径。
运行
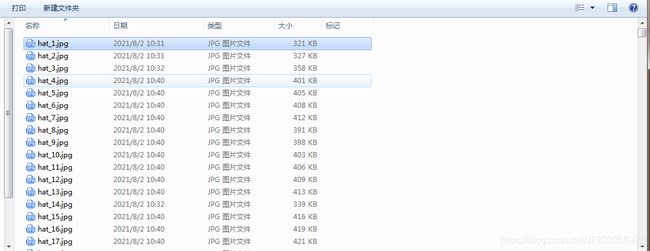
处理后的数据
2. 安装标注数据的工具
LabelImg是一个开源的图形图像注释工具,地址:https://github.com/chinakook/labelImg2
下载解压后,本文解压目录为 D:\labelImg2-master 。在解压的目录下安装对应的依赖库
Windows + Anaconda
# 安装pyqt依赖包
conda install pyqt=5
安装后在对应的解压目录下启动该工具
# 启动 labelImg
python labelImg.py
成功启动 labelImg 后界面如下:

3. 标注数据
下面讲解如何使用 labelImage工具标注图片信息用于训练自己的数据集。 在 labelImage工具 左上角的菜单栏打开我们的要标注图像的文件夹:
File ->Open Dir
在 labelImage工具 左上角的菜单栏打开我们的要保存标注后对应Xml的文件夹:
File ->Open Save Dir
在 labelImage工具中加载进来图像后如下图:
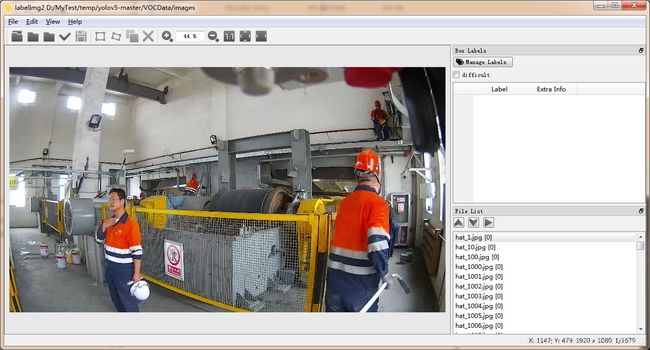
首先,设置自动保存:
View -> Auto Saving
通过快捷键w + 拖动鼠标选中我们要标注的对象,在 labelImg工具 的右上角Manage Label 中输入目标的标签hat ->add ->set as defult,点击OK,即可获得一个xml文件。
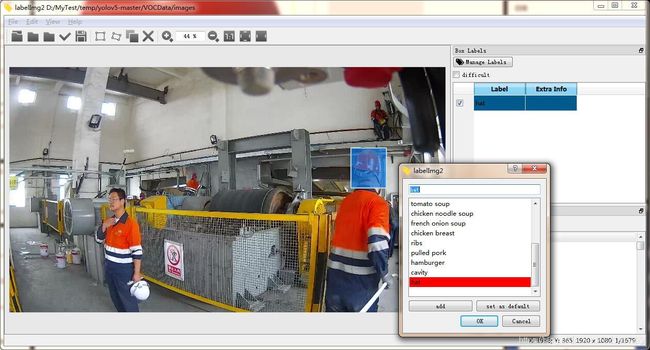

由于我们设置了自动保存,直接按 “d” 快捷键切换下一张图像以同样的操作进行标注。
到此,即可完成自己制作VOC格式的数据集。
labelImage工具快捷键
| Ctrl + u | 从目录加载所有图像 |
|---|---|
| Ctrl + r | 更改默认注解目标目录 |
| Ctrl + s | 保存 |
| Ctrl + d | 复制当前标签和矩形框 |
| Space | 将当前图像标记为已验证 |
| w | 创建一个矩形框 |
| d | 下一张图片 |
| a | 上一张图片 |
| del | 删除选中的矩形框 |
| Enter | 选择一个矩形框 |
| Ctrl + + | 放大 |
| Ctrl - - | 缩小 |
| ↑→↓← | 键盘箭头移动选定的矩形框 |
4. 训练模型
- voc格式数据集转化yolov5格式数据集
转换格式代码
第一步: 写一个split.py脚本,创建存放转化yolov5格式数据集的目录
import os
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='VOCData/Annotations', type=str, help='input xml label path')
parser.add_argument('--txt_path', default='VOCData/labels', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行
创建转化yolov5格式数据集的目录结构后,会生成如下4个文件:

第二步:再写一个txt2yolo_label.py脚本
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["person", "head","hat","sleep","uniform","mobilePhone","clothes"]
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
# try:
in_file = open('VOCData/Annotations/%s.xml' % (image_id), encoding='utf-8')
# print(in_file)
out_file = open('VOCData/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# print(xmlbox)
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
# except Exception as e:
# print(e, image_id)
wd = getcwd()
for image_set in sets:
if not os.path.exists('VOCData/labels/'):
os.makedirs('VOCData/labels/')
image_ids = open('VOCData/labels/%s.txt' %
(image_set)).read().strip().split()
list_file = open('VOCData/%s.txt' % (image_set), 'w')
for image_id in tqdm(image_ids):
list_file.write('VOCData/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
注: 运行代码之前,修改里面相关标签名
运行
运行结果:

- 配置yaml文件
新建一个yaml文件,配置一份属于自己数据集的yaml文件,在这个需要修改自己的标签个数和标签名字。
# (1)修改train,val的路径为自己刚刚生成的路径
# (2) nc 里的数字代表数据集的类别,我这里有7类,所以修改为7
# (3)names 里为自己数据集标注的类名称,我这里是"person", "head","hat","sleep","uniform","mobilePhone","clothes"
train: VOCData/train.txt
val: VOCData/val.txt
# number of classes
nc: 7
# class names
names: ["person", "head","hat","sleep","uniform","mobilePhone","clothes"]
- 修改models模型文件
修改所选用到的models模型对应的yaml配置文件,这里的标签数量和我们新建yaml文件保持一致

- 修改训练模型脚本参数
这里需要对train.py文件内的参数进行修改
# 第一个参数:设置需要重构的训练模型;
# 第二个参数:设置重构模型的对应的yaml配置文件;
# 第三个参数:设置我们自己制作数据集对应的yaml配置文件。
parser.add_argument('--weights', type=str, default='yolov5x.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5x.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/menberCondition.yaml', help='dataset.yaml path')
开始训练
如下图则说明开始模型训练,模型的训练需要一定的时间,我们耐心等待就好了。
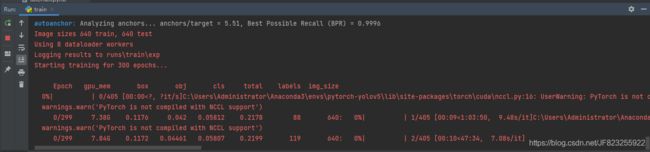
至此,制作自己的yolov5数据集并进行训练就结束啦,训练好模型,就可以开始愉快的测试工作啦!!!