基于卷积神经网络CNN的面部表情识别
深度学习在计算机视觉上是非常流行的技术,本文选择卷积神经网络(CNN)作为构建基础创建模型架构,对Fer2013数据集中的面部微表情图像进行识别。过程划分为三个阶段:图片处理、特征提取、模型识别。图片预处理是在计算特征之前,排除掉跟脸无关的一切干扰,主要有数据增强、归一化等。特征提取是通过卷积神经网络模型的计算(卷积核)来提取面部图像相关特征数据,为之后表情识别提供有效的数据特征。
开发环境:Anaconda3,PyCharm2021.2.3,python3.6.13,keras2.6.0,tensorflow-gpu2.6.0
一、数据预处理
(一)数据集的介绍
训练模型使用的是Kaggle2013年面部表情识别挑战赛的数据集Fer2013。它由35887张人脸表情图片组成,包含训练集(Training)28709张,验证集(PublicTest)和测试集(PrivateTest)各3589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,分别对应于数字标签0-6,具体表情对应的标签和中英文如下:0 anger 生气;1 disgust 厌恶;2 fear 恐惧;3 happy 开心;4 sad 伤心;5 surprised 惊讶;6 normal 中性。
数据集下载地址: https://download.csdn.net/download/weixin_48968649/85883963
(二)数据预处理
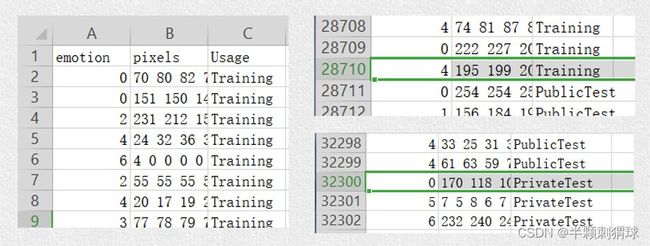
数据集并没有直接给出图片,而是将表情、图片数据、用途的数据保存到csv文件中,第一行是表头,说明每列数据的含义,第一列表示表情标签,第二列为原始图片数据,最后一列为用途。
(三)分离数据集
要想让数据集能够为程序所使用,我们需要将数据集分离并转化为程序方便利用的形式。首先要将数据集按照用途分离成三部分,训练集csv文件、验证集csv文件和测试集csv文件。
import os
import csv
# 载入数据集
database_path = r'C:\深度学习\fer2013' # 数据集路径
datasets_path = r'C:\深度学习\dataset' # 输出路径
csv_file = os.path.join(database_path, 'fer2013.csv') # 数据集
train_csv = os.path.join(datasets_path, 'train.csv') # 训练集
val_csv = os.path.join(datasets_path, 'val.csv') # 验证集
test_csv = os.path.join(datasets_path, 'test.csv') # 测试集
# 分离训练集、验证集和测试集
with open(csv_file) as f:
csvr = csv.reader(f) # 按行读取返回行列表
header = next(csvr) # 获取第一行标题
rows = [row for row in csvr] # 遍历每行
# 按最后一列的标签将数据集进行分割 第一列row[:-1],最后一列row[-1]
trn = [row[:-1] for row in rows if row[-1] == 'Training']
csv.writer(open(train_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + trn)
print("训练集的数量为:", len(trn))
val = [row[:-1] for row in rows if row[-1] == 'PublicTest']
csv.writer(open(val_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + val)
print("验证集的数量为:", len(val))
tst = [row[:-1] for row in rows if row[-1] == 'PrivateTest']
csv.writer(open(test_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + tst)
print("测试集的数量为:", len(tst))接着把csv文件转化成图片文件供我们观察图片(此步骤只是方便我们观察可以省略)
import os
import csv
import numpy as np
from PIL import Image
# 将分开的三个数据集转化为单通道灰度图,同时按照表情进行分类
datasets_path = r'C:\深度学习\dataset'
train_csv = os.path.join(datasets_path, 'train.csv') # 获取数据
val_csv = os.path.join(datasets_path, 'val.csv')
test_csv = os.path.join(datasets_path, 'test.csv')
train_set = os.path.join(datasets_path, 'train') # 输出图片
val_set = os.path.join(datasets_path, 'val')
test_set = os.path.join(datasets_path, 'test')
for save_path, csv_file in [(train_set, train_csv), (val_set, val_csv), (test_set, test_csv)]:
if not os.path.exists(save_path): # 保存文件夹不存在则创建
os.makedirs(save_path)
num = 1
with open(csv_file) as f:
csvr = csv.reader(f)
header = next(csvr)
# 使用enumerate遍历csvr中的标签(label)和特征值(pixel)
for i, (label, pixel) in enumerate(csvr):
# 将特征值的数组转化为48*48的矩阵
pixel = np.asarray([float(p) for p in pixel.split()]).reshape(48, 48)
subfolder = os.path.join(save_path, label)
if not os.path.exists(subfolder):
os.makedirs(subfolder)
# 将该矩阵转化为RGB图像,再通过convert转化为8位灰度图像,L指灰度图模式,L=R*299/1000+G*587/1000+B*114/1000
img = Image.fromarray(pixel).convert('L')
image_name = os.path.join(subfolder, '{:05d}.jpg'.format(i))
print(image_name)
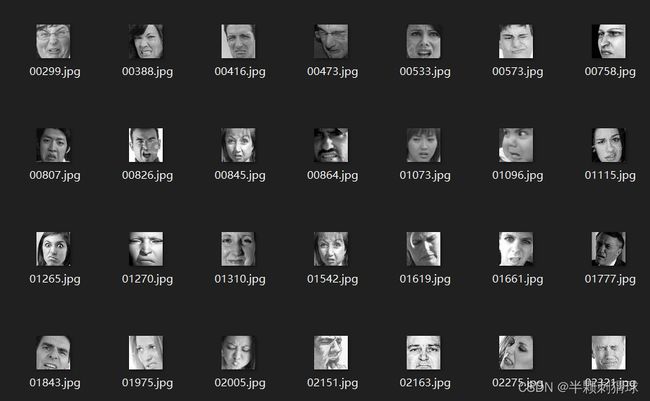
img.save(image_name)
分离前后对比

(四)数据增强
分析训练集后发现,每个类别的训练数据量差别较大,从下图统计的数据能够明显地看出,1 disgust 厌恶 的数据量最少,只有436张样本。一个好的训练数据集是训练一个良好模型的前提,没有一个比较合理的训练数据就不可能得到一个性能良好的模型,因此,在面对一个分布不是很均匀的数据集时,数据增强就显得非常重要了。
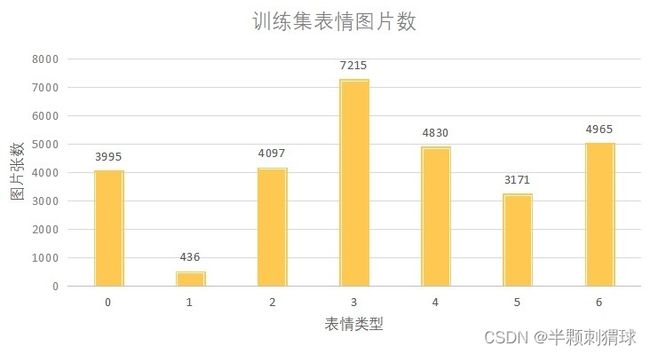
为了防止数据倾斜,我们使用Keras框架中封装的ImageDataGenerator函数,对训练集1 disgust 厌恶 中的样本图片做一些诸如翻转,平移,旋转之类的数据增强操作,此函数在设定的参数范围内做随机的变换,大大增多了数据量,使得1 disgust 厌恶 的样本数量从436张增加到了2738张,训练集数据也从原本的28709张增加到了现在的31011张。
import os
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=20, # 旋转范围
width_shift_range=0.1, # 水平平移范围
height_shift_range=0.1, # 垂直平移范围
shear_range=0.1, # 透视变换的范围
zoom_range=0.1, # 缩放范围
horizontal_flip=True, # 水平反转
fill_mode='nearest')
dir = 'C:/深度学习/dataset/train/1' # 数据增强文件路径
for filename in os.listdir(dir):
print(filename)
img = load_img(dir + '/' + filename) # 这是一个PIL图像
x = img_to_array(img) # 把PIL图像转换成一个numpy数组,形状为(3, 150, 150)
x = x.reshape((1,) + x.shape) # 这是一个numpy数组,形状为 (1, 3, 150, 150)
# 下面是生产图片的代码
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='C:/大三上/深度学习/dataaug/train/1',
save_prefix='1',
save_format='jpeg'):
i += 1
if i > 5:
break # 否则生成器会退出循环二、 卷积神经网络模型搭建
(一)卷积神经网络组成结构
卷积神经网络主要由输入层、卷积层、激活函数、池化层、全连接层和输出层组成。合理的设置上述层结构并在不同层级之间按需进行Dropout、NB等操作才能最终形成一个高效、准确率高的卷积神经网络模型。
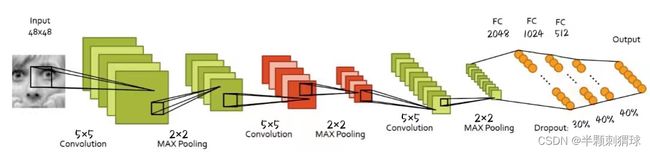
1、卷积层
图像实际是由像素构成的,而像素是一连串的数字组成的,所以图像就是由一连串数字构成的矩阵。
卷积核是一系列的滤波器,用来提取某一种特征。一个卷积核一般包括核大小(Kernel Size)、步长(Stride)以及填充步数(Padding)。我们用卷积核来处理一个图片,当图像特征与过滤器表示的特征相似时,可以得到一个比较大的值,不相似时,得到的值就比较小。每个卷积核生成一个特征图,这些特征图堆叠起来组成整个卷积层的输出结果。
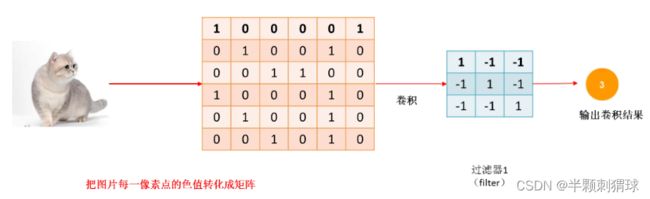
也可以理解为,CNN的卷积层是指对输入的不同局部的矩阵和卷积核矩阵相同位置做相乘后求和的结果,卷积的值越大,特征越明显。

2、池化层
池化层就是对数据进行压缩,它是将输入子矩阵的每n×n个元素变成一个元素。常见的池化层思想认为最大值或者均值代表了这个局部的特征,从局部区域选择最有代表性的像素点数值代替该区域。可以有效的缩小参数矩阵的尺寸,从而减少最后连接层的中的参数数量,也有加快计算速度和防止过拟合的作用。
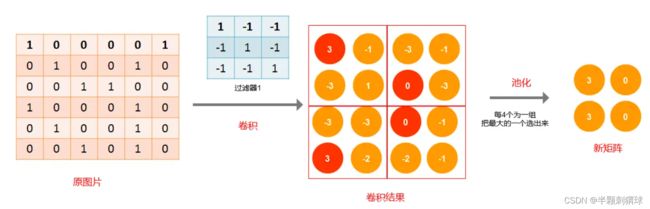
3、全连接层
全连接层将特征图转化为类别输出。全连接层不止一层,为了防止过拟合会在各全连接层之间引入DropOut操作,能有效控制模型对噪声的敏感度,同时也保留架构的复杂度。除此之外,在卷积层和全连接层中间还添加了一层不属于CNN中特有的结构层级的Flatten层过渡,用来将输入“压平”,即把多维数组转换为相同数量的一维向量。

(二)网络模型与训练
整个卷积神经网络由三个卷积段、三个全连接层、一个分类层组成,每个卷积段包含具有相同卷积操作的一个卷积层和相同池化操作的一个池化层。不同于最后一段卷积,前两段卷积均增加了批量标准化操作(Batch Normalization)和Dropout操作。批标准化操作将一个batch中的数据进行标准化处理,使数据尽量落在激活函数梯度较陡的区域避免梯度消失,提高模型的泛化性。Dropout操作随机放弃一定概率的节点信息,以放弃部分计算结果的方式防止模型的“过度学习”导致过拟合的发生。
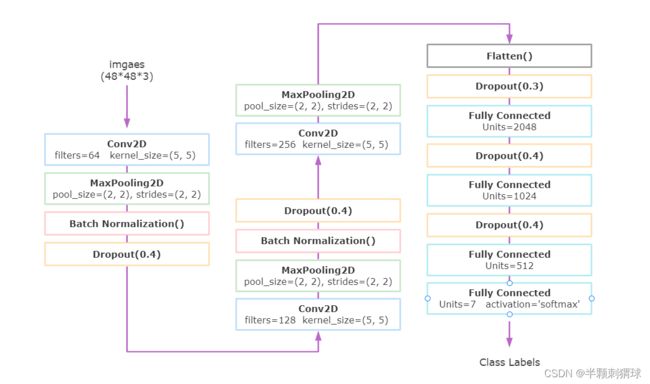
import os
import pickle
from tensorflow import optimizers
from keras.models import Sequential
from matplotlib import pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import BatchNormalization, MaxPooling2D, Dense, Dropout, Flatten, Conv2D
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 生成器读取图像
train_dir = r'C:\深度学习\dataaug\train'
val_dir = r'C:\深度学习\dataset\val'
test_dir = r'C:\深度学习\dataset\test'
train_datagen = ImageDataGenerator(
rescale=1./255, # 重放缩因子,数值乘以1.0/255(归一化)
shear_range=0.2, # 剪切强度(逆时针方向的剪切变换角度)
zoom_range=0.2, # 随机缩放的幅度
horizontal_flip=True # 进行随机水平翻转
)
val_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(48, 48),
batch_size=128,
shuffle=True,
class_mode='categorical'
)
validation_generator = test_datagen.flow_from_directory(
val_dir,
target_size=(48, 48),
batch_size=128,
shuffle=True,
class_mode='categorical'
)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(48, 48),
batch_size=128,
shuffle=True,
class_mode='categorical'
)
# 构建网络
model = Sequential()
# 第一段
# 第一卷积层,64个大小为5×5的卷积核,步长1,激活函数relu,卷积模式same,输入张量的大小
model.add(Conv2D(64, kernel_size=(5, 5), strides=(1, 1), activation='relu', padding='same', input_shape=(48, 48, 3)))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) # 第一池化层,池化核大小为2×2,步长2
model.add(BatchNormalization())
model.add(Dropout(0.4)) # 随机丢弃40%的网络连接,防止过拟合
# 第二段
model.add(Conv2D(128, kernel_size=(5, 5), strides=(1, 1), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(BatchNormalization())
model.add(Dropout(0.4))
# 第三段
model.add(Conv2D(256, kernel_size=(5, 5), strides=(1, 1), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten()) # 过渡层
model.add(Dropout(0.3))
model.add(Dense(2048, activation='relu')) # 全连接层
model.add(Dropout(0.4))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(512, activation='relu'))
model.add(Dense(7, activation='softmax')) # 分类输出层
model.summary()模型的训练时采用的是批处理形式batch_size设为128,数据迭代40轮;所有卷积层均采用5*5的卷积核;采用ReLU激活函数。这里我采用了两种不同的优化器做对比,一个是RMSprop优化器学习率设为0.0001,另一个是Adam优化器。
# 编译
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(), # Adam优化器
# optimizer=optimizers.RMSprop(learning_rate=0.0001), # rmsprop优化器
metrics=['accuracy'])
# 训练模型
history = model.fit(
train_generator, # 生成训练集生成器
steps_per_epoch=243, # train_num/batch_size=128
epochs=40, # 数据迭代轮数
validation_data=validation_generator, # 生成验证集生成器
validation_steps=28 # valid_num/batch_size=128
)
# 评估模型
test_loss, test_acc = model.evaluate(test_generator, steps=28)
print("test_loss: %.4f - test_acc: %.4f" % (test_loss, test_acc * 100))
# 保存模型
model_json = model.to_json()
with open('myModel_2_json.json', 'w') as json_file:
json_file.write(model_json)
model.save_weights('myModel_2_weight.h5')
model.save('myModel_2.h5')
with open('fit_2_log.txt', 'wb') as file_txt:
pickle.dump(history.history, file_txt, 0)(三)结果分析
使用RMSprop优化器训练的结果:经过40轮迭代后,训练集的准确率在76%左右,验证集的准确率在60%左右,模型在测试集的准确率为61%左右,损失值为1.1570。
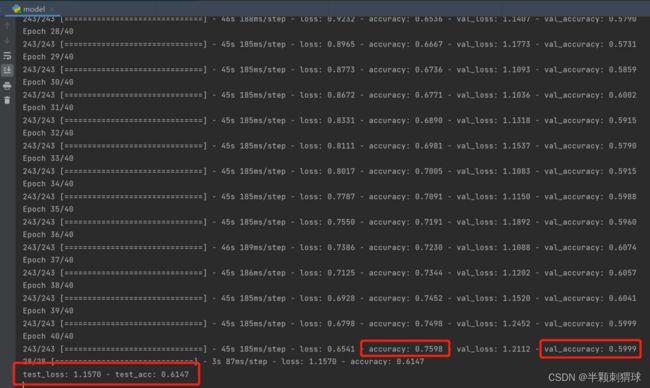 RMSprop优化器
RMSprop优化器
对数据集进行打乱与归一化操作后,使用Adam优化器训练的结果:经过40轮迭代后,模型在测试集的准确率为62%左右,损失值为1.0300。
 Adam优化器
Adam优化器
可以得出对数据集进行打乱与归一化操作对于提高模型准确率的作用并不大,也许是模型参数没有调好,也可能是数据集精度、像素太低及存在错误标签影响了模型的准确度。接下来绘制训练中的精度曲线和损失曲线,对比一下两个优化器的不同。
# 绘制训练中的损失曲线和精度曲线
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure("acc")
plt.plot(epochs, acc, 'r-', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='validation acc')
plt.title('Accuracy curve')
plt.legend()
plt.savefig('acc_2.jpg')
plt.show()
plt.figure("loss")
plt.plot(epochs, loss, 'r-', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='validation loss')
plt.title('Loss curve')
plt.legend()
plt.savefig('loss_2.jpg')
plt.show() RMSprop优化器的精度曲线和损失曲线
RMSprop优化器的精度曲线和损失曲线
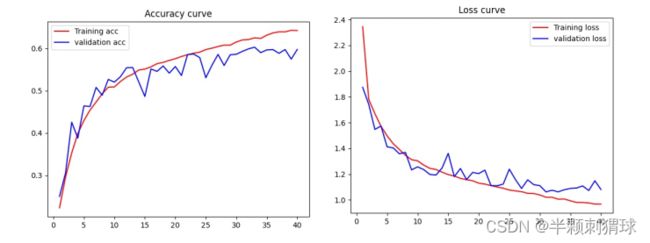 Adam优化器的精度曲线和损失曲线标题
Adam优化器的精度曲线和损失曲线标题
分析损失曲线,总体验证集的损失值高于训练集的,说明模型完全可以提取有用特征信息,但验证集的数据波动较大并且曲线没有收敛,这点在使用RMSprop优化器训练时更为明显。除此之外,我们还可以看到上方两张图的曲线波动比较大,而下方两张图的曲线波动大大减小。这说明RMSprop优化器训练的效果更加丰富,也比较杂乱,Adam优化器训练的效果更加平滑,但细节区域不够精细,且速度较RMSprop优化器慢。