3D点云模型总结
3D点云模型总结
- 点云数据预处理 FAQ
-
- 1. 点云有哪些常用的数据集?
- 2. 点云中点的个数如何确定?
- 3. 如何划分train/val/test ?
- 4. 如何归一化?
- 5. 如何shuffle?
- 6. 数据增强(augmentation)
- Farthest Point Sampling (FPS)算法核心思想解析
-
- 1. 逻辑描述
- 2. 算法原理
- 3. 算法分析
- PointNet++: classification笔记
-
- 1. Set Abstraction模块
- 2. 分类网络总体结构
- 3. 总结
- cuda编程基础:PointNet++里面的cuda编程
-
- 1. __global__ 关键字
- 2. CUDA的线程层次结构
- 3. Grid Stride Loop
- 4. 设置Grid、Block大小
- 5. 同一个block内共享显存
- Dynamic Graph CNN for Learning on Point Clouds ------DGN笔记
-
- 1. EdgeConv
- 2. Dynamic Graph
- 3. 总体网络结构
- DeepGCNs: Can GCNs Go as Deep as CNNs? ——CVPR 2019
-
- 1. GCN网络结构
- 2. Feature更新模块
- 3. Feature融合模块
- 4. 预测模块
- Spherical Kernel for Graph Convolution ---点云球核卷积
-
- 1. 球核(Spherical Kernel)的定义
- 2. 球核卷积
- 3. 分类网络实现
- 4. 总结
- DCP: Deep Closest Point(点云匹配 ICCV 2019)
-
- 1. Registration的目标
- 2. Registration的难点
- 3. Transformer回顾
- 4. 网络结构
- 5. 总结
- ShellNet: 点云壳卷积网络 (ICCV 2019)
-
- 1. ShellConv 壳卷积
- 2. ShellNet 壳网络
- 3. 总结
- KPConv:点云核心点卷积 (ICCV 2019)
-
- 1. Kernel Point Convolution定义
- 2. 如何确定每个kernel point的位置?
- 4. 总结
- PointCNN:可以处理点云的CNN (NIPS 2018)
-
- 1.解决的问题
- 2 算法
- 3. 总结
- PointConv: 3D点云卷积 (CVPR 2019)
-
- 1. 卷积概念、论文核心思想
- 2. 具体实现
- 3. 优化
- 4.总结
- PointRend: 从图像渲染的角度思考分割问题
-
- 1. 概述
- 2. 具体方法
- 3. 总结
- RS-CNN for Point Cloud(Relation-Shape Convolutional Neural Network) :点云卷积(CVPR 2019)
-
- 1. 核心思想
- 2. 几何拓扑关系信息
- 3. RS-CNN结构
- 4. 总结
- Contextual Point Representations
-
- 1. 概述
- 2.Point Enrichment
- 3. Feature Representation
- 4 Prediction
- 5 总结
- ImVoteNet: 用2D图片信息 优化 3D点云物体检测(CVPR2020)
-
- 1. 核心思想
- 2. VoteNet回顾
- 3. ImVoteNet概述
- 4. 图片的几何信息(Geometric cues)
- 4. 图片的语义信息(Semantic cues)
- 5. 图片的纹理信息(Texture cues)
- 6. 特征融合、多模态训练(Feature Fusion and Multi-tower Training)
- 7. 总结
- Non-local Neural Networks (CVPR 2018)
-
- 1. Motivation
- 2. Non-local Operation Formulation
- 3. Non-local Operation Instantiations
- 4. Non-local Block
- 5. Conclusion
- Graph Attention Networks (ICLR 2018)
-
- 1. Graph Attention 操作流程
- 2. 总结
- PointASNL: 点云Adaptive Sampling与Nonlocal(CVPR 2020)
-
- 1. 噪点
- 2. Adaptive Sampling(AS)模块
- 3. Local-NonLocal(L-NL)模块
- 4. 网络结构
- 5. 总结
点云数据预处理 FAQ
1. 点云有哪些常用的数据集?
1)ModelNet40:可以用来训练分类(classification)。训练集有9843个点云、测试集有2468个点云。有40个类。
2)ShapeNet:可以用来训练零件分割(part segmentation)。训练集有14007个点云,测试集有2874个点云。
3)RueMonge2014:可以用来训练室外场景的语义分割(semantic segmentation)。里面包含7个类:window, wall, balcony, door, roof, sky, shop。
4)ScanNet:可以用来训练室内场景的语义分割(semantic segmentation)。训练集有1513个训练场景,100个测试场景。
5)S3DIS:Stanford large-scale 3D Indoor Spaces dataset。可以用来训练语义分割(semantic segmentation)。其中分为6个area,每个area内有若干个场景。
2. 点云中点的个数如何确定?
downsample
如果下载的数据集里面,每个点云有固定的数量(例如:1024、2048),基本可以满足要求了。如果点云比较大,用十万、百万个点,一般要进行一些采样操作。一般采用VoxelGrid来采样。Matlab中对应的是gridaverage pcdownsample:
ptCloudOut = pcdownsample(ptCloudIn,'gridAverage',gridStep)里面的逻辑大概为:将三维空间按照指定步长 (gridStep),划分为一个三维网格(grid),每个grid内的点,最后取均值,得出一个点。需要注意的是:有些grid内可能没有点,所以,downsample后,点的个数,一般小于grid的个数。
例如:S3DIS数据集,一般会用pcdownsample来采样。
选子区域
下采样后,点云如果还是很大,可以进一步在xy坐标系下,按照一定的规则,将一个点云分割为若干个小的点云。每个子区域,一般会再额外扩大一点,扩大的空间范围内包含的点,作为context points参与训练,但是context points不参与计算loss。
统一点数
作为模型的输入,一般是希望每个点云中点的数量是相同的。采样、选子区域后,不能保证每个点云的数量完全一样。假设希望最后每个点云有NUM_POINT=2048个点,当前点云中的点数为num。
当采样后点数小于2048时,可以使用:
np.random.choice(num, NUM_POINT, replace=True)当采样后点数大于2048时,可以使用:
np.random.choice(num, NUM_POINT, replace=False)3. 如何划分train/val/test ?
目前,基本只划分为train、test两个集合。具体划分方式,一般参考“惯例”来划分,即:前面的一些经典论文怎么划分,跟它采用一样的方式即可。
例如,对于S3DIS数据集,里面有6个area,选其中一个area包含的所有点云作为test集,其它5个area作为train集。这样,可以得到6组train、test数据集。实际上,一般选第5个area作为test集,其它5个area作为train集。
4. 如何归一化?
xyz坐标:
1)在3d空间中找一个能包含所有点的最小的立方体,立方体的三条边与xyz轴平行。找到这个立方体的下表面的中心点,以这个点作为归一化的参考点。所有点的坐标,减去参考点的坐标。
2)可以进一步将x、y、z归一化到[-1, 1]之间。
第1步一般是必须的,效果会很明显。第2步是否有效果,需要通过实验来验证。颜色值:一般归一化到[-1, 1]之间。
5. 如何shuffle?
有以下两种方式:
一个batch内,点云的顺序,shuffle
一个点云内,点的顺序,shuffle
6. 数据增强(augmentation)
Data augmentation可以增强模型的范化能力。一般的方式有:
1)一个batch内,选一定比例的点云,绕z轴随机旋转(0 - 360)度;
2)一个batch内,选一定比例的点云,分别绕x、y、z随机旋转一个小的角度,比如20度左右;
3)一个batch内,所有点进行随机抖动(jitter);
Farthest Point Sampling (FPS)算法核心思想解析
参考:https://zhuanlan.zhihu.com/p/114522377
在点云研究中,采样算法举足轻重。目前很多流行的点云模型结构里面,都用到了FPS算法。本文将详细介绍FPS算法的流程以及代码实现里面的优化技巧,希望通过文本,对FPS的操作逻辑,时间、空间复杂度等,都能有一个清晰的理解,从而更好的理解相关文章。
1. 逻辑描述
假设有n个点,要从里面按照FPS算法,采样出k个点(k 初始情况。 集合A为空,集合B包括所有点。 2)选第二个点。分别计算出集合B里面的每个点到集合A中的一个点的距离,选距离最大的点,将其移动到集合A 中。此时,集合A包含2个点,集合B包含 n-2 个点。 3)选第三个点。此时,如何定义集合B里面的点,到集合A里面的点的距离?因为集合 A里面不止有一个点。这是理解FPS的核心。假设点Pb 是集合B里面的一个点,计算Pb的距离的方式如下: 4)对于集合B里面的每个点,都可以计算出一个距离值: {Pb1,Pb2…Pb(n-2)}。选出最大的距离值对应的点,最为第3个点,移动到集合A中。此时,集合A包含3个点,集合B包含n-3个点。 5)之后可以按照选第三个点的方式,直到选出k个点为止。 假设此时集合A中包含m个点,集合B中包含 n-m个点。按照上面描述的逻辑,当选下一个点时,对于集合B里面的每个点,需要分别计算出到集合A中每个点的距离。大概估算一下,集合B共有n-m个点,每个点要计算出m个距离值。所以,选下一个点的时间复杂度是(n-m)×m。 里面包含一些重复的步骤: 2)退回到选取第m个点时,对于集合B中的点Pb,因为集合A中包含m-1个点,所以需要计算的距离为:{dB1,dB2…dB(m-1)}; 对比一下,可以看出,前后两步,点Pb重复计算的距离为: {dB1,dB2…dB(m-1)} 。如何进行优化? 假设在选第m个点时,对于集合B里面的点Pb,设Tb(m-1)表示点Pb到集合A里面的m-1个点的距离的最小值:Tb(m-1)=min({dB1,dB2…dB(m-1)}),选第m个点后,对于点Pb,继续选择第m+1个点,需要计算出:min({dB1,dB2…dBm}),然而此时不需要重复计算点Pb到集合A中前m-1个距离,只需要计算Pb到选出的第m个点的距离dBm,然后用min(min({dB1,dB2…dB(m-1)}),dBm),则可以计算出Pb到集合A的距离,其公式: 该公式可以递推,若tB(m-1)= min({dB1,dB2…dB(m-1)}),则tBm = min(tB(m-1),dBm),如此以来,即可去掉重复计算的部分。代码实现上,只需要一个长度为n的数组,分别保存每个点到集合A的距离。每次新选出一个点后,按以上公式来更新这个数组即可。 pointnet2里面fps的代码中的变量temp,正是用来保存每个点到集合A的距离。 时间复杂度:每次选一个点,需要计算n个距离;选k个点,时间复杂度可以认为是: O(kn) ,由于k和n有一个常数比例关系,所以也可以认为是: O(n^2) 。 空间复杂度:需要一个长度为n的数组,来记录、更新每个点的距离值,所以复杂度为:O(n)。 PointNet++作为PointNet的改进版,网络结构修改很大。本文以分类功能为例,介绍其大概处理流程。 这个模块可以认为是构成PointNet++网络的一个基本单元。整个分类网络,由3个Set Abstraction模块,再加3个全连接层构成。Set Abstraction模块内部,可以划分为3个串行操作的层: 3)重复第2步,一直采样到目标数量N为止。 从FPS算法逻辑上看,第1步可以认为是只有一个集合的点,所以可以统一按照第2步点逻辑来实现。在PointNet++源码中,有基于cuda的并行计算实现,实现细节可参考源码:https://github.com/charlesq34/p 1.2 Grouping layer 1.3 PointNet layer 总体上看,Set Abstraction相当于: 整个分类网络,由3个Set Abstraction模块,再加3个全连接层构成。第三个Set Abstraction模块与前两个Set Abstraction模块有些区别:省掉了sampling和grouping,相当于把输入的点云中的所有点,当成一个group,再用PointNet来处理。 算法在FPS采样、球体Grouping时,使用的是每个点的xyz坐标,这些坐标始终没有变化,相当于:点是固定的。DGCNN中,除第一层使用xyz坐标系计算外,后续使用计算出来的feature在feature空间KNN内采样、构建局部图,相当于每个点是动态变化的。 https://zhuanlan.zhihu.com/p/87763943 CUDA中有两个重要的名称:host,device: 带有cuda编程的代码,总体上可以分为两部分,一部分会在host上运行,另一部分会在device上运行。用__global__关键字修饰的函数,表示该函数需要在device上执行(GPU来执行)。 在__global__关键字修饰的函数内部,可以通过以下内置变量获取到Grid、Block的维度、位置信息: 在__global__函数内部,一般会通过以上几个内置的变量,计算出当前线程的一个全局的编号,用这个编号来“规划”用这个线程处理哪些输入数据。可以想象成把三维立方体(三维数组)转化为一条一维直线(一维数组),每个元素对应一个线程,然后自己来“规划”每个线程需要处理哪些数据。如下例子: 根据cuda线程的层级结构,可以看出,一个Grid内,并行执行的线程数量为: 当调用__global__函数时,可以在调用的地方,用<< gridSize, blockSize 均为dim3 类型的变量。默认情况下,gridSize, blockSize里面的xyz初始值为1,创建dim3时,缺少的维度默认为1。也可以直接用整数来设置gridSize, blockSize。例如: block的大小,一般设置为32的倍数,因为最终在执行时,所有线程会被分配到以32个线程为基本执行单元的线程束(wraps)上。设置好之后,即可在__global__函数内通过内置变量gridDim, blockDim来访问。 在__global__函数内,用__shared__关键词修饰的变量,会在同一个block内的所有线程之间共享。相比其它类型的变量,这种类型的变量效率更高。 使用__shared__变量后,不可避免的会引入变量同步的问题。因为实际上,同一个block内的所有线程,对共享变量的操作,执行的先后顺序是不一样的。cuda提供了一个同步API:__syncthreads()来处理__shared__类型变量的同步问题。 当一个线程在执行时遇到了__syncthreads()并执行完该函数后,会停下来,等所在block内所有线程都执行完该__syncthreads()调用后,再继续执行。因此,可以在__syncthreads()之前,执行写操作,__syncthreads()之后,执行读操作,这样就不会出现状态不一致的问题。 参考:https://zhuanlan.zhihu.com/p/85857744 PointNet的主要流程是:先单独计算(更新)每个点的feature,更新多次之后,最后用global pool将所有点的feature整合为一个点云的feature。更新的每个点的特征只与之前的特征有关,而与其他点的特征没有建立关系,认为每个点的特征都可以作为全局特征,明显存在一定的缺陷。 edgeConv在计算(更新)每个点的feature时,不仅考虑这个点当前的feature,还考虑了在当前的feature空间内,与当前点距离最近的K个点的feature。在feature空间内与目标点临近的K个点,可以在小范围内构成一个小的局部图,从中计算出来的信息,可以认为是一种局部feature。让全局feature和局部feature共同来影响每个点的feature的更新,似乎会更好一些。下面对一个点的feature的单次更新过程做简要说明: 从edgeConv的计算过程可以看出,每更新一次feature,重新用KNN找K个最近点时,由于是按照新的feature的距离来找,所以每次KNN的结果都会不同,每次构建的局部图都会动态的更新。 如果把KNN找到的点,看作是receptive field,那么深层网络处,由于每层KNN的结构都不同,每个点的receptive field会越来越大。直觉上,这种方式可能更有利于全局feature的学习。 参考:https://zhuanlan.zhihu.com/p/86896852 论文将Residual connection的思路运用到了GCN点云网络中,加深了网络层数,提升了模型性能。 GCN网络可以总结为以下3个模块: 从总体结构上看,特征更新模块在论文提出了三种结构: 每层模块内部更新feature的过程,可以分为两个操作步骤:选邻居、计算feature。 选邻居。以点Xi为中心,用KNN选出 k个最近的点。为了增加每个点的receptive field,论文在knn的基础上,文提出了dilated knn选点方法。 以segmentation为例,该模块使用一个卷积层处理后,用max_pool将点云中所有点的feature整合为一个点云的全局feature,再将该全局feature拼接到每个点的feature上。此时,每个点既有局部信息,也有全局信息。 用多个卷积层对每个点的feautre进行处理、降维,计算出每个点属于每个类的概率。 https://zhuanlan.zhihu.com/p/87426221 对球体范围内的所有点的feature,按照球核(Spherical Kernel)定义的可训练参数分别更新后,相加,求均值,得到中心点Xi卷积后的feature。求均值的具体实现代码,可以参考:depthwise_conv3d_forward 分类网络使用了一种coarsening的操作,将点云逐层稀疏化: 以代码中给出的modelnet40分类网络为例,分类的流程如下: 4)将球卷积核的半径改的很大,使每个点的邻居,能包括其它所有点; 点云中点的feature的更新操作,是点云里面的核心操作,很多论文本质上是关于这个操作的研究。DGCNN使用KNN来找邻居,构建局部图,在局部图上,使用传统的CNN、Pool等操作来计算、更新feature。相比之前的方法,这篇论文提出: 点云匹配(Point Cloud Registration)问题,在机器人、医疗图像以及其它相关的计算机视觉任务中是一个很关键的问题。本文主要介绍ICCV2019里面一篇做Registration的文章,记录一些学习笔记和心得。 对于两个本质“形状”接近的点云:X和Y ,如何通过旋转、平移,来调整X,使X 尽量与 Y 重合。 点云中的点是无序的。旋转、平移,本质是对点云中每个点的调整。那么问题来了,如何确定 X、Y中点的对应关系? 传统的方法(ICP、Go-ICP等)提供的一些方案,其存在一些问题:很容易陷入局部最优点、太耗时。 论文提出了一种end-to-end DCP算法(Deep Closest Point)来处理Point Cloud Registration问题,相比之前的方法,性能提升很大。 作者提出的DCP算法,里面使用了NIPS 2017 里面《Attention Is All You Need》中提出的Transformer网络结构。理解DCP算法之前,有必要对Transformer有一个大概的了解。 在seq2seq问题里面(例如机器翻译),基于RNN、LSTM的Encoder-Decoder方案主要的问题在于: Transformer里面,并没有使用RNN等循环网络,而是使用一种self-attention的机制来实现seq2seq任务,在处理以上两个问题时,性能高于传统RNN方式的网络结构。 所以,Transformer主要是一种基于self-attention的序列模型。在处理Point Cloud Registration问题时,可以将两个待匹配的点云,分别看作两个序列(无序),那么,Registration问题正好可以类比为一种特殊形式的seq2seq问题,目标是找到两个序列(点云的点集合)之间的位置转换关系。作者对Transformer进行了一些修改后,用到了DCP网络中。 4.3 Pointer Generation 论文将Transformer应用到了点云Registration问题中,通过Transformer中的attention机制,计算出一个“假想的目标点云“,这个假想的目标点云与待调整点云之间点的对应关系已知(soft matching)。再通过Loss约束,间接使得假想的目标点云向真正的目标点云不断逼近,最终实现点云的对齐匹配。 https://zhuanlan.zhihu.com/p/90925811 ShellConv的操作流程: 对于一个采样点,使用ShellConv计算feature的详细流程(源码实现)如下: shellNet与点云球核卷积有较多相似之处: https://zhuanlan.zhihu.com/p/92244933 Kernel Point Convolution的作用是:计算出3D空间中一个点x的feature。下面以点x的feature计算过程为例,说明KPConv的定义。 点云中的点定义为:P∈RN×3,所有点的feature定义为:F∈RN×D。以x为球心,r为半径,确定一个球体。落在该球体内的点,将作为点x的邻居点,参与x的feature计算。x的邻居点定义为: 基于以上内容,点x处的核心点卷积KPConv定义为,对每个邻居点xi的特征fi,分别用矩阵g(xi - x)变换后,累加起来: 论文中使用2D形式的核心点卷积来进行图示: 所有的kernel point都在半径 限定的球体范围内。每个点的位置的确定方式大概如下: 具体过程,可以参考源码实现。按这种方式,得到的结果类似于: 论文核心在于核函数g 和相关性函数h。面对多个矩阵,h计算出每个矩阵的系数,g使用h的计算结果对所有矩阵加权求和,最终计算出一个权重矩阵,用于feature的更新。 与PointNet比较,PointNet中的某一层,所有点的feature的更新,使用相同的矩阵。而KPConv中,每个点根据其位置,计算出一个特别的矩阵来执行feature的更新。 文章通过一种自定义的 χ-Conv 操作,使常规的Convolution也能处理点云。 假设有4个点组成的一个点云,对比常规的2D图片,示意图如下: 2.1 类二维CNN操作 而PointCNN的输入时点集F1 = {(p1,i , f1,i ) : i = 1, 2, …, N1},, 其中p是点的D维坐标(作者没有假设点的维数,所以这里用D,如果是3维空间D就是3),f是点对应的特征。这里N个点到底怎么取,在论文后面有提,这里先放着。对F1用 X-Conv(就是带X变换的卷积)得到F2 = {(p2,i , f2,i ) : f2,i ∈ RC2 , i =1, 2, …, N2}。仿照CNN,这里也要求N2 2.2 局部特征的提取 为了计算出点p的feature,首先确定其邻居点集P(使用FPS,或者KNN),按以上算法操作: 算法也可以用如下公式来表达: 可以看到χ矩阵。论文希望通过该矩阵来将邻居点的feature矩阵变得与邻居点的顺序无关。 参考:https://zhuanlan.zhihu.com/p/99863795 如何在点云上执行卷积?点云中点的无序性,以及每个点的位置的随机性,使得在图片上表现出色的卷积操作,不好直接运用到点云上。这篇文章通过学习一个“连续”的卷积核,实现了对点云执行卷积操作。 卷积的含义是:对于一维时间状态下,系统在t时刻的输出,不仅与系统在t时刻的输入有关,还与它在t时刻之前的输入有关,并且不同时刻的输入,有不同的权重。所以,卷积本质上做的事情是:不同时刻的输入的加权求和。权重是一个关于时间t的连续函数。 类似的概念映射到2D图片卷积上:对于2D图片来说,某个位置的输出,不仅与该位置的输入有关,还与此位置周边位置的输入有关,不同位置的输入,具有不同的权重。卷积所做的事情,同样是一个加权求和。由于位置坐标是固定的有限个值,所以,权重是一个关于位置的离散函数。现有的convolution操作实现了这个操作,只是并没有显式的将权重作为一个关于位置的函数,而是直接给每个位置设置一个权重系数。 点云卷积上:对于3D点云来说,某个位置的输出,不仅与该位置的输入有关,还与此位置点的K个最近的邻居点有关。位置具有随机性,取值空间在3D空间中是连续的。按照卷积的原理,不同位置的权重不同,所以,权重应该是一个关于3D坐标的连续函数。如果能得到这个“连续”的权重函数,就可以解决3D点云上的卷积问题。这大概就是这篇论文的核心思想。 从内存消耗和运行效率的角度出来,论文对以上网络结构进行了优化,得出Efficient PointConv,最终结果为: 之前的一些文章通过人工构建一些规则的形状(3D grid、Ball、Shell),先将连续的3D空间离散化,然后模拟2D图片卷积的逻辑来处理3D点云。相对于位置,权重是离散的。这篇论文从卷积的定义出发,使用MLP学习出不同位置的不同权重,实现了权重的连续性。 Rend:渲染 之前的分割算法,可以看成是: 一张任意图片里面,有低频、高频区域。在图像分割问题里面,两类区域有如下不同: 用均匀网格划分图片采样的方式,对于低频区域来说,可能会过采样,浪费一些计算资源;对于高频区域来说,可能会欠采样,不能够得出精细的结果。按照以上分析,即可得出优化分割算法的一个重要思路:优化采样方式。类似的采样问题,在graphics图像渲染领域,已经研究了很久。以图像渲染为例,一个常见的处理方式是: 1)首先使用某种采样方式进行采样。采样是不规则的,比如,高频区域多采样、低频区域少采样。然后计算每个采样点的像素值。 借鉴graphics里面渲染的思路,论文将分割问题看作一个类似的渲染问题来处理: PointRend主要有3部分组成:point selection strategy、point-wise feature representation、point head。 Inference。Inference使用的采点策略,受adaptive subdivision启发,操作示意图如下: Training。Training过程中使用的采点策略不同于Inference过程,示意图如下: 2.2 point-wise feature representation 2.3 point head 总体示意图如下: 此方法的核心是:upsample时,对一些高频位置的点进行特殊处理,使结果更加精细。 https://zhuanlan.zhihu.com/p/102341185 对于常规的2D卷积操作,如下图所示: 类比到点云,如果有一种卷积,能够在点云上执行卷积,那卷积的kernel里面的每个参数,可能也应该包含一些形状关系信息。如何能让参数包含形状关系信息? 使用点云的形状关系数据,通过MLP网络,学习出kernel里面的参数。这样一来,kernel里面的参数就可以认为携带着点云的形状关系信息。这个学出来的kernel,从包含位置形状关系信息的角度来看,就跟2D卷积很像了。 所以,论文的核心思想是:用点云中每个点的一些几何拓扑关系信息来学习卷积的kernel。基于此想法,论文提出了一种卷积操作:RS-CNN(Relation-Shape Convolutional Neural Network)。 3)计算出所有邻居点的feature后,用一个Aggregation函数( A),max或者avg,来处理所有邻居点的feature; 以上过程可以总结为: 论文用一个共享的MLP,从每个点的几何拓扑信息,学习每个点的卷积参数; 通过几何信息学习卷积参数的这个操作,与cvpr2019中的另一篇文章 PointConv 类似。PointConv 从“卷积参数应该是一个关于3D坐标的连续函数“的角度出发,用一个共享的MLP从每个点的坐标学习出卷积参数。 点云语义分割本文介绍一篇nips 2019点云语义分割相关的一篇文章https://zhuanlan.zhihu.com/p/107181849 文章以PointNet、PointNet++为例,提出了这两个网络的几个不足之处: 基于以上问题,文章提出了一个新的点云分割模型: 这个部分主要对每个点的初始feature进行增强,解决前面提到的初始feature表达不足的问题。主要思想是:加上邻居点的相关信息。具体实现如下: 这个模块以Point Enrichment之后的feature作为输出,给每个点计算出一个更有意义的feature。总体网络结构采用传统的Encoder-Decoder方式。在Encoder中,论文提出了一个GPM模块,来解决论文开头提出的PointNet++处理局部点云能力较弱的问题。 3.1 Encoder 经过以上处理,论文认为,每个点的feature里面只包含了一个local范围内点之间复杂的关系信息,并没有包含global全局信息。给每个点计算label时,全局信息可能也很重要。为了把全局信息也融合到每个点的feature里面,论文提出了Spatial-wise Attention和Channel-wise Attention两种融合方式。 4.2 Channel-wise Attention 4.3 prediction 这篇文章可以总结为: 文章的主要内容,可以总结为:如何在local、global范围内,进行feature融合。 https://zhuanlan.zhihu.com/p/125754197 充分利用2D图片中的几何坐标、语义、像素纹理信息,来辅助3D点云物体检测。 这篇文章,可以认为是VoteNet的升级版。这里先对VoteNet进行简单的介绍回顾。VoteNet以点云作为输入,输出预测出来的物体类别、bounding box信息。其网络结构图如下: 因此,Vote的核心也可以总结: VoteNet里面只使用了3D点云作为输入,没有利用3D点云对应的2D图片中包含的有用信息。ImVoteNet就是想通过加入2D图片里面的有用信息,来对VoteNet进行改进。对照上面的VoteNet网络结构,要加入2D图片包含的有用信息,需要解决以下问题: 第一个问题。ImVoteNet是在如下位置添加图片信息: 如上图所示,在一个针孔相机模型下,已知相机内参(intrinsic matrix),即可把2D照片上的一个点,映射到3D相机坐标系下的一条线上。如果能在2D图片上找到物体的中心点,并把该点映射到3D坐标系下,那么在3D点云里面,可以认为,该物体的中心点,就落在了中心点映射得到的线上。之前在VoteNet里面,3D点云里面每个点投票决定其所属物体的中心点时,搜索空间没有任何限制。有了2D图片上的中心点后,3D点云里面每个点再投票时,其搜索范围就缩小到了一条线上。所以,这个信息可以帮助网络缩小搜索空间。具体操作如下: 在以上相机模型里面,可以知道以下3个点的坐标:P(x1,y1,z1)、p(u1,v1)、c(u2,v2),目标是:模型能够预测出点P所属物体中心点C的坐标 C(x2,y2,z2) 。这个点未知。假设该点已知,根据相机模型,可计算出2D图片上的向量: 点云里面,如果一个点P映射到2D图片后,落在了一个物体内,相当于已经知道了这个点P所属物体的类别信息。所属物体的类别信息,或许能够帮助点P更好的vote出点 C 的坐标。类别信息可以用one-hot score表示,也可以用RoI来表示。从论文给出的试验结果来看,用one-hot score作为语义信息,能取得更好的效果。 对于点云里面的一个点P,找到其映射到2D图片上的像素点,将RGB像素值也作为额外的feature,添加到点P的feature里面,帮助点P更好的vote出所属物体中心点C的坐标。 ImVoteNet的网络结构如下图所示: 里面的每个tower网络,与VoteNet里面vote层之后(包括vote层)的网络结构相同。总loss为: 值得注意的是,虽然训练过程中,使用3个分支来训练,但是一旦训练结束,inference的时候,只需要使用joint tower。image tower 和 point tower 只在训练过程中使用到。 这篇文章给出了一个方案,展示了如何利用2D图片中的有用信息,来提升3D点云物体检测的性能,值得借鉴。 深度学习网络中,如何将全局信息很好的融合到局部信息中,从而提升算法性能,是一个很重要的问题。目前在一些3D点云算法中,也通过使用到一些global、local feature的融合方式来提升算法性能。这些算法,或者直接借鉴Non-local Neural Networks 里面介绍的网络结构,或者对其进行改进后提出一个新的网络结构。本文主要对Non-local Neural Networks进行大概介绍,帮助读者能更好的理解其它相关文章 以图片segmentation为例,一般在网络最后层,每个像素位置都会计算出来一个feature,然后每个像素位置,分别使用自己的feature作为输入,再通过某种网络,计算出segmentation的结果。 当整体网络层数比较少时,每个像素位置的feature的receptive field所覆盖的区域,可能很小,相当于是一个local feature。对于一个像素位置来说,很可能在receptive field之外,有一些信息对该像素位置的segmentation起到很大的帮助作用。这种情况下,receptive field之外的有用信息,无法传播到像素位置的local feature里面。 当整体网络层数很多时,每个像素位置的receptive field一般可以覆盖整个图片,看上去可以解决以上的问题。但很深的网络,同时也引入了以下问题: 如何解决以上问题呢,让任何一个像素位置,能够很方便的从其它所有的像素位置获取有用信息,帮助其进行segmentation,文章使用了Non-local Operation。 论文抽象出了一个通用的non-local操作: 上面给了non-local的一个抽象结构。按照抽象出来的结构,论文给出了多种具体的实现: 里面的Embedded Gaussian,在后续论文里面出现的频率很高,因此对其进行详细介绍。 对Non-local Operation计算出来的Non-local feature(yi) ,经过一次embedding,最后与残差连接(residual connection),组成一个Non-local Block:zi = Wz*yi + xi。 论文中以视频分类作为具体任务,给出了Embedded Gaussian的一种具体实现: 论文提出的Non-local操作的抽象公式,似乎涵盖、总结了很多实论文中的各种实现,值得学习。 Non-local实际做的是一个feature融合的操作:将多个feature融合为一个feature。在点云算法网络中,可以使用Non-local操作: 目前,attention机制被广泛应用到各种深度学习网络模型中。本文主要介绍一篇ICLR 2018里面针对图网络(3D meshes, social networks, telecommunication networks, biological networks, brain connectomes)提出的一种attention机制。对于3D点云,虽然点与点之间没有图网络里面的有向关系,但可以把点云看做一种“简化“后的图网络。尤其是处理点云里面某个点的邻域时,“中心点“和邻域里面的“邻居点”,可以看作是一个局部有向的图网络。所以,论文提出的attention机制,同样可以用到点云模型中。 定义如下变量: 1)拼接K个分支: 论文本质上做的一件事情是:对每个邻居点分别学习出一个权重系数,最后加权求和。在点云模型中,可以用Graph Attention在local、global范围内进行feature融合。 点云数据里面,一般会有一些噪点,理论上,这些噪点可能会对具体应用的性能产生影响。本文主要介绍CVPR 2020的一篇处理噪点的论文。文章主要对所有采样点的位置、feature进行调整,减弱噪点的影响,论文将这步称为:Adaptive Sampling(AS);并进一步使用Local-NonLocal(L-NL)来对feature进行增强。 如上图左图所示,对于一个飞机点云,红圈、蓝圈、绿圈、黄五角星,均表示噪点。当使用FPS进行下采样后,黄色五角星所在的点被采中。直觉上,这个点如果不处理,会对网络性能有所影响。 针对这个问题,论文提出了一个Adaptive Sampling(AS)模块,来实现调整噪点的操作,从而降低噪点对网络性能的影响。 用KNN算法,给每个下采样得到的点找K个邻居点。假设点xi的邻居点集合为:{xi,1,xi,2…xi,k}∈N(xi) ,对应的邻居点的feature集合为:{fi,1,fi,2…fi,k }。 2.2 Self-attention增强邻居点feature 主要思路是:对于点xi的第k个邻居点,分别计算出它与xi的其它邻居点的相关性,然后用softmax计算出一组权重,最后使用权重对xi的所有邻居点的feature进行加权求和,得出点xi的第k个邻居点的新的feature。直觉上,经过这步处理后,每个邻居点的feature会包含邻域范围内的所有点的一些信息。具体操作流程如下: 1)邻居点坐标normalization:所有邻居点的坐标,减去第一个邻居点的坐标,转成相对于第一个点的相对坐标。 以上过程即为论文中的如下公式: 主要思路是:用增强后的邻居点的feature,通过网络学出以下两个信息: 具体操作流程如下: 总结:Adaptive Sampling在邻域内,先用Self-Attention进行feature增强,然后用另一种attention在邻域内进行feature、坐标的加权求和,得出所有采样点的feature、坐标。论文认为,这样即可对采样点中包含的噪点进行处理。 该模块通过使用局部、全局信息,进一步对采样所得点的feature进行增强。 3.1 Local 对于每个采样点,Local主要是在每个点的局部邻域范围内,对其邻居点的feature进行融合,计算出一个新的feature。这部分使用了PointConv的思想(连续空间下的卷积操作),将每个邻居点的相对坐标映射为一组卷积操作的系数矩阵,然后用每个邻居点的系数矩阵对其feature进行变换,最后用一个Aggregation操作,将邻居点的feature融合为得到中心点xi的local feature。对应的公式为: 3.2 NonLocal NonLocal本质上是使用Self-Attention,对每个采样所得点,在整个点云范围内进行feature融合,为每个采样点计算出一个包含全局信息的feature。流程图如下: 3.3 feature融合 除了Local、NonLocal两个分支外,代码中其实还有一个skip connection的分支。对于每个采样所得点,该分支直接对采样点的邻居点的feature执行max_pool,最后通过一个1d convolution给每个采样点计算出来一个新的feature。最后将local、nonlocal、skip-connection三个分支的feature加到一起,再用一个1d convolution对feature的channel进行变换,得到每个采样点的feature。 以segmentation为例: 读完文章、代码,会发现:本文的核心是Adaptive Sampling、Local-NonLocal; 总体上,这篇文章演示了如何融合local、global范围内的feature,进行feature增强。比较特别的是,作者从“噪点“这个角度作为文章的出发点,如此一来,就有别于其它点云feature融合的文章了。 2020/06/06
1)选第一个点。可以对所有点shuffle后,选第一个点即可。大部分实现也是这么做的。第一个点选完之后,将其移动到集合A中。此时,集合A包含1个点,集合B包含 n-1个点。
①分别计算出 Pb到集合A中每个点的距离。此时集合A里面有两个点,所以可以计算出两个距离值。
②从计算出来的距离值里面,取最小的距离值,作为点Pb到集合A的距离值。2. 算法原理
1)在选第m+1个点时,对于集合B里面的每一个点Pb,需要分别计算出到集合A里面每个点的距离。假设dB1表示Pb到集合A中第一个点的距离,则需要计算的距离为:{dB1,dB2…dBm},取其中的最小值min({dB1,dB2…dBm}),作为Pb 的距离值。
min({dB1,dB2…dBm})= min(min({dB1,dB2…dB(m-1)}),dBm)3. 算法分析
PointNet++: classification笔记
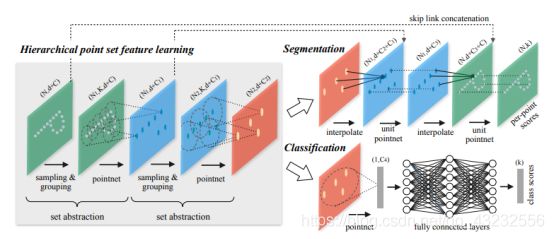
1. Set Abstraction模块
1.1 Sampling Layer
采样层使用farthest point sampling (FPS)采样算法,从初始点云中采样出有限个点进行后续处理。FPS算法的逻辑为:
1)以点云第一个点,作为查询点,从剩余点中,取一个距离最远的点;
2)继续以取出来的点,作为查询点,从剩余点中,取距离最远的点。此时,由于已经取出来的点的个数大于1,需要考虑已经选出来的点集中的每个点。计算逻辑如下:
①对于任意一个剩余点,计算该点到已经选中的点集中所有点的距离;
②取最小值,作为该点到点集的距离;
③计算出每个剩余点到点集的距离后,取距离最大的那个点。
分别以每个采样点为球心,在一个特定半径的球体范围内,找出落在该球体范围内的特殊数目K个点,构成一个group。
Grouping layer得出的每个group,可以看做是一个“局部点云”,用PointNet网络来计算出这个局部点云的feature。
1)按照xyz空间坐标,从输入点云采样出一个稀疏的点云;
2)每个采样点通过group、pointNet网络,计算出该点的一个新的feature;2. 分类网络总体结构
3. 总结
cuda编程基础:PointNet++里面的cuda编程
1. global 关键字
host:CPU、内存构成的一个环境
device:GPU、显存构成的一个环境2. CUDA的线程层次结构
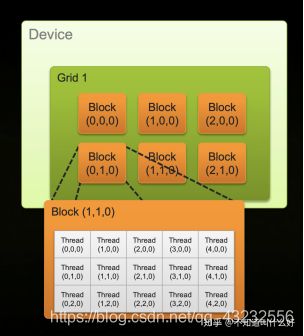
如上图所示(截图出自:CUDA C/C++ Basics),cuda在逻辑上,将多线程分为两个层次:
· Grid:第一层,将所有线程划分为很多个相同大小的block,所有block组成一个grid。上图展示的是二维的情况,实际上,可以把grid想象成一个立方体,如果它的尺寸为:(x,y,z),则表示总共有xyz个block。
· Block:第二层,每个block,也可以想象成一个立方体,如果尺寸为:(x,y,z),则表示这个block内部有xyz 个thread。
1)gridDim:第一层的维度信息,分别用:gridDim.x、gridDim.y、gridDim.z来获取3个分量。这个变量跟实际执行的线程无关,是固定的。
2)blockDim:第二层的维度信息,分别用:blockDim.x、blockDim.y、blockDim.z来获取3个分量信息。这个变量跟实际执行的线程无关,是固定的。
3)blockIdx:表示当前线程所在的block,在grid内的索引坐标(把grid想象成立方体),同样有xyz三个分量。这个变量的值取决于当前线程,不同的线程,可能不一样:相同一个block内的线程是一样的,不同block内的线程,不同。
4)threadIdx:表示当前线程,在它所在的block内的的索引坐标(把block想象成立方体),同样有xyz三个分量。这个变量的值取决于当前线程,不同的线程,可能不一样:相同一个block内的线程是不一样,不同block内的线程,有可能一样;


3. Grid Stride Loop
![]()
假设需要执行矩阵加法操作,可以先把矩阵(2维,3维,甚至更高维)转换成1维,然后对应下标的元素相加,再将结果转换成原始的维度。当1维数组中元素的个数小于线程的个数,每个下标都可以用一个独立的线程来计算,最大化的利用并行的优势。但是,当1维数组中元素的个数大于线程的个数时,每个线程需要处理多个下标元素相加的计算任务。这种情况下,一般采用stride为num的方式,为每个线程分配计算任务。例如,线程总数2,元素数量为6,编号从0开始,则:
· 线程0处理的元素下标为:0,2,4
· 线程1处理的元素下标为:1,3,5
每个线程处理的元素下标的stride正好为grid包含的线程总数。实际使用时,可以按照实际情况灵活的划分每个线程的计算任务。比如在PointNet++源码中,作者设置的gridDim的大小等于batch size,相当于一个block内的线程,处理一个batch内的一个点云数据。然后在block内部,再进一步划分哪个线程处理哪些点的数据。4. 设置Grid、Block大小
__global__ void add(...)
{ ...}
dim3 gridSize(2, 2, 2);
dim3 blockSize(2, 2, 2);
add<<<gridSize, blockSize>>>(...);__global__ void add(...)
{ ...}
dim3 gridSize(2, 2); // gridSize(2, 2, 1)
dim3 blockSize(2); // blockSize(2, 1,1)
add<<<gridSize, blockSize>>>(...);
add<<<4, 2>>>(...); // gridSize(4, 1, 1), blockSize(2, 1,1)5. 同一个block内共享显存
Dynamic Graph CNN for Learning on Point Clouds ------DGN笔记
在PointNet的基础上,提出了一种新的计算点云中点的feature的算法,提升了点云分类、分割等任务的性能。具体来说,论文提出了两个新的概念:EdgeConv和Dynamic Graph,二者算是这篇论文的精华。1. EdgeConv
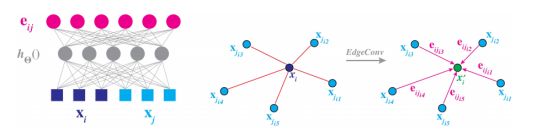
EdgeConv主要实现对点云中节点的feature的更新操作,改进了PointNet中缺少局部信息的缺点。


2. Dynamic Graph
3. 总体网络结构

DeepGCNs: Can GCNs Go as Deep as CNNs? ——CVPR 2019
1. GCN网络结构
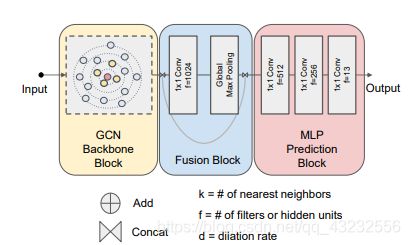
1)Feature更新模块(论文中称为:GCN Backbone Block),完成点云中每个点的feature的反复更新。
2)Feature融合模块(论文中称为:Fusion Block),该模块将点云中所有点的feature整合到一起,得出一个点云的整体的feature。
3)预测模块(论文中称为:MLP Prediction Block),该模块使用之前得到的每个点feature,以及点云的整体feature,进行点云分类、分割等视觉任务。2. Feature更新模块

1)PlainGCN: 每层模块接收上一层的输出,作为输入,内部处理完后,产生输出。
2)ResGCN:每层模块接收上一层的输出,作为输入,内部处理完后,产生的输出,从输入加了一个Residual连接。
3)DenseGCN:每层模块接收之前所有层的输出,作为输入。

计算feature。选出k个点后,有多种方式来计算Xi的feature。代码中实现了4种,每种方法的大概流程总结如下:
1)用每个邻居点的feature与Xi的feature做差,得到Xi个feature;max后,整合为一个feature,与Xi的feature拼接,再经过一个1x1的卷积层,计算出Xi的新feature;—先做差,再max,后拼接,最后卷积。
2)用每个邻居点的feature与Xi的feature做差,得到Xi个feature;将Xi的feature分别拼接到Xi个feature中;经过一个1x1的卷积层处理;最后max,整合为一个feature,作为Xi的新feature;—先做差,再拼接,后max,最后卷积。
3)用每个邻居点的feature与Xi的feature做差,得到Xi个feature;将Xi的feature分别拼接到Xi个feature中;经过一个1x1的卷积层处理;最后max,整合为一个feature,作为Xi的新feature;–先做差,再拼接,后卷积,最后max。
4)用每个邻居点的feature与Xi的feature做差,得到Xi个feature;reduce_sum后,得到一个feature;这个feature与Xi的feature加起来;经过一个1x1的卷积层处理,作为Xi的新feature。—先做差,再reduce sum,后拼接,最后卷积。3. Feature融合模块
4. 预测模块
Spherical Kernel for Graph Convolution —点云球核卷积
这篇论文作为CVPR2019《Octree guided CNN with Spherical Kernels for 3D Point Clouds》的扩展,提出了一个针对3D点云的球核(Spherical Kernel)图卷积算法,本文对该算法进行一个简要的介绍。1. 球核(Spherical Kernel)的定义

取任意点Xi作为原点,半径为r的空间范围,构成一个球体。在右侧所示的坐标系下,分别在(γ,θ,φ) 三个维度上,对空间进行划分,即可将球体划分为上图所示的若干区域。其中,每个区域对应一组可训练的参数,对落在此区域内的点的feature进行更新。更新规则如下:

每个区域内,每个点的feature的更新方式,可以总结为下图(c=3,λ = 2):
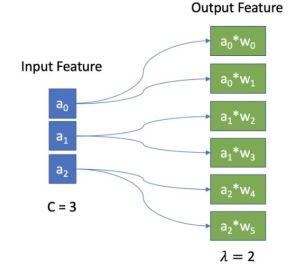
可以看出,这种方式不需要像Convolution的kernel那样对数据的“格式”有严格的要求,球体被划分后得到的每个区域内,不需要有确定数量的点,灵活一些。如何将每个邻居点对应到一个具体格子里面,从而对应到具体的参数ω,这部分具体实现,可以参考:build_spherical_kernel,如何更新每个邻居点的feature,这部分的具体实现,可以参考:depthwise_conv3d_forward2. 球核卷积
3. 分类网络实现
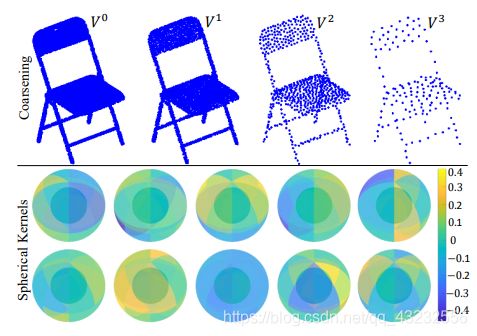
类似于multi scale的思路,在每种密度的点云上计算一个feature,最后把所有feature整合到一起,作为点云最终的feature。代码中给出了三种方式来实现coarsening:
1)farthest_point_sample;
2)inverse_density_sample;
3)random_sample;
分类、分割网络的总体结构跟之前的其它网路类似,只是在更新feature时,使用了球卷积的操作。
1)对输入数据做Normalize;
2)Pointwise-convolution: 用一个全连接层对每个点的feature做一次变换;
3)使用不同的radius(例如:radius = [0.1, 0.2, 0.4, 0.8]),分别执行:
①将原始的xyz拼接到新的feature里面;
②按当前的radius半径找每个点的邻居(用点的索引值表示),每个点找到的邻居可能不一样多;
③把找到的邻居点,对应到球卷积核的对应区域内,每个邻居点对应一个索引;
④连续执行2次球卷积;
⑤执行一次coarsening 采样操作,点云密度降低;
⑥用每个采样点的所有邻居的feature,用max pool,计算出一个新的feature,作为这个采样点的feature;
⑦用一个reduce_max计算出点云的全局feature,保存起来(对应点云密度下的feature);
5)将每个点的邻居,映射到新的球卷积核上的不同区域上;
6)执接调整维度,加激活函数等行一次球卷积,全连;
7)用reduce_max计算出全局feature;
8)将不同密度下的所有全局feature拼接起来,构成最终的全局feature;
9)用三个全连接层,将维度降到类的数量,可以计算出属于每个类的概率。4. 总结
1)使用一个指定半径的球体来找邻居;
2)定义了一个球核实现卷积,实现feature的更新;
3)球体范围内执行pool。DCP: Deep Closest Point(点云匹配 ICCV 2019)
1. Registration的目标
2. Registration的难点
3. Transformer回顾
1)处理太长的sequence时,效果不佳;
2)RNN、LSTM后一步的输入,依赖于前一步的输出,因此很难实现并行化计算。4. 网络结构
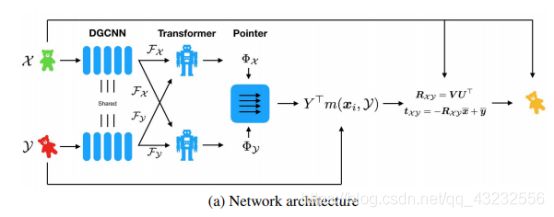
整个网络分为:Initial Features、Attention、Pointer Generation、SVD Module四步。
4.1 Initial Features
使用一个共享的DGCNN网络分别计算点云X,Y 中每个点的feature,得到:
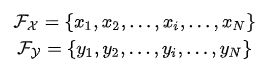
4.2 Attention
上面计算出来的FX,FY,在计算过程中彼此独立,相互之间没有关系。为了让二者能产生关系,彼此知道对方的存在,从而更好的计算出“如何才能调整到对方的位置“,作者在这里使用了修改过的Transformer网络:
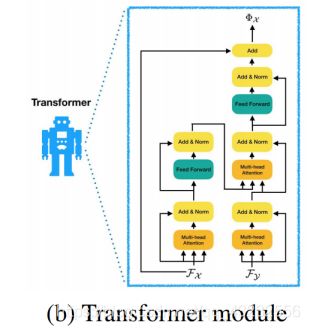
Transformer的输出为:
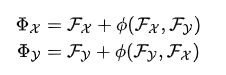
Φ相当于Transformer对feature学习到一个“条件”残差变化量。例如,对于FX,Φ(FX,FY)表示要将X调整到Y,应该怎么调整X的feature。相当于以Fy作为条件(condition),计算出Fx的残差变化量。
Registration的难点在于如何寻找两个点与点之间的对应关系。作者用Φx,Φy计算出soft pointer(类似于soft attention,soft map),得出一种基于概率的点与点的对应关系。具体做法如下:

4.4 SVD Module
4.5 Loss
整个网络相当于输入点云X、Y,输出 Rxy,txy。用 Rxy,txy与ground truth值来构建Loss:

Loss中的第一项:因为希望 Rxy,是单位正交矩阵(Orthogonal Matrix),所以它的转置和逆应该相同。因此,理想情况下,以下等式应该成立:

5. 总结
ShellNet: 点云壳卷积网络 (ICCV 2019)
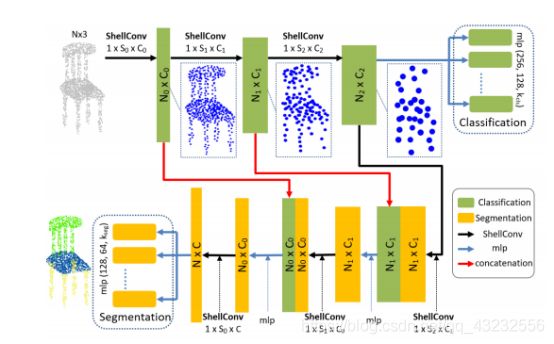
如何针对点云这种非结构化数据进行高效的特征计算,其中的核心问题是:如何计算点云中每个点的feature?从PointNet开始,很多不同的算法被提出来。本文介绍ICCV 2019的一篇文章,里面提出了一个新的操作:壳卷积ShellConv,以及包含壳卷积的壳网络ShellNet。1. ShellConv 壳卷积

ShellConv实现的功能是计算出一个采样点的feature。如上图©所示,一个Shell表示两个同心但不同半径的球面之间的空间范围。ShellConv的主要思路是:
1)将采样点的邻居点划分到不同的shell内;
2)同一个shell内的点,通过聚合函数(max_pool)计算出一个shell的局部feature;
3)最后用多个shell的局部feature,计算出采样点的feature;
1)用KNN找到K = ss·D 个邻居。ss表示shell size,即每个shell包含多少个邻居点;D表示shell的个数。K个邻居点按照到采样点的距离,升序排列。因此,每个邻居点会落到对应的shell里面;
2)K个邻居点的xyz坐标(相对于采样点的坐标)分别经过两个共享的Dense层(全连接层)处理,得到K个高维的feature;
3)如果K个邻居点之前已经有feature,则将之前的feature拼接到Dense层计算出来的feature后面;
4)分别在每个shell内,对包含在该shell内的点,用max_pool计算出每个shell的局部feature,得出D个feature;
5)用kernel大小为 [1, D] 的conv2d对D个feature进行聚合,计算出采样点的feature。2. ShellNet 壳网络
上图即为点云分类、分割的网络结构。以分割为例,详细流程(源码实现)如下:
1)输入的点云为N×3,feature为None;
2)用FPS采样得到的点为 N0 ,用ShellConv计算每个采样点的feature,得到N0×C0;
3)类似上一步,得到的点为 N1 ,feature为C1 ;
4)类似上一步,得到的点为N2,feature为C2。至此,完成了下采样的过程;5)直接用第3步得到的点 N1×3 ,作为采样点,用ShellConv计算每个采样点的feature,得到N1×C1,与第3步的feature拼接后得到 N1×2C1,经过一个Dense层得到N1×C1;
6)类似上一步,得到点N0,feature为C0 ;
7)类似上一步,没有feature拼接,得到点N ,feature为C ;
8)最后通过3个dense层,得到N×Kseg。Kseg 表示类的个数。3. 总结
ShellConv参数量少,运行速度应该比SphericalConv快。KPConv:点云核心点卷积 (ICCV 2019)
本文介绍ICCV2019的一篇用核心点卷积(Kernel Point Convolution)来计算feature的文章,研究如何高效的计算点云中点的feature。1. Kernel Point Convolution定义
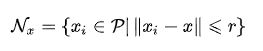
将球体定义为:
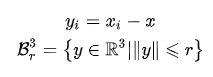
在球体内,找K个点,作为核心点(kernel points)。核心点并不是点云中的点,而是通过特定规则计算出来的一些特殊的位置,核心点位置的确定,此处先忽略,后面会介绍。K个核心点定义为:
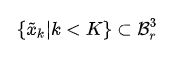
对于每个核心点 x ~ \widetilde x x k,分别有一个权重矩阵 Wk与之对应。Wk的定义为:

在前面定义的球体范围Br3,对于落在该范围内的点 xi(点云中的点),可以得到其相对于x的距离 y~i ~= xi- x,对于任意的yI,定义核函数g为:
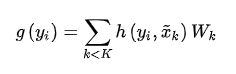
可以直观的看出,g(yi)相当于对K个权重矩阵加权求和。权重系数h(yi, x ~ \widetilde x x k)定义为: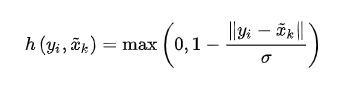
可以看出,每个权重矩阵Wk的系数,由Wk对应的核心点 到yi的相对距离来确定。相对距离越小,权重越大,最大值为1;相对距离越大,权重越小,最小值为0。 直观的解释:距离越近,相关性越大,结果越大;反之亦然。g(yi)可以看作:专门针对xi 计算出来一个权重矩阵。其中,yi = xi - x 。
总结一下核心点卷积的大概思路:
1)以点x为球心确定一个球体;
2)在球体内确定若干个核心点,每个核心点带一个权重矩阵;
3)对于落在球体范围内的任意点,用核函数,计算出该点的权重矩阵,用该矩阵对这个点的feature进行变换;
4)对于落在球体内的每个点,都用上一步的方法,得出一个新的feature,最后将feature累加起来,作为点x的feature。

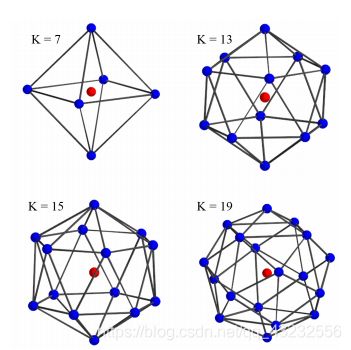
如上图所示,以第二个点为例,首先通过h分别计算出7个核心点权重矩阵Wk的系数,加权求和后,得到第二个点的feature的转换矩阵,对第二个点的feature进行变换。圆圈范围内(对应于3D里面的球体)的4个点,每个点分别计算出来一个feature,最后求和,得到目标点的feature。2. 如何确定每个kernel point的位置?
1)球心作为一个kernel point的位置;
2)球心对其它点有一定的引力(attractive force)来吸引它们靠拢;
3)其它的kernel points之间有一定的斥力(repulsive force)来使它们相互远离。
4)这个由引力、斥力组成的系统稳定后,即可确定每个kernel point的位置。
4. 总结
PointCNN:可以处理点云的CNN (NIPS 2018)
参考:https://zhuanlan.zhihu.com/p/960672551.解决的问题
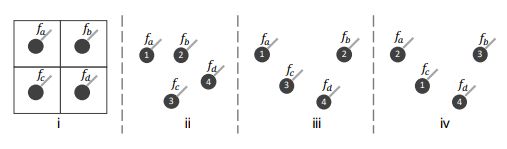
图(i)表示2D图片的情况,此时,四个点的位置顺序是固定的。对于点云,其位置顺序有很多可能,如图(ii, iii, iv)所示。如果对图(ii, iii, iv)执行Convolution操作:
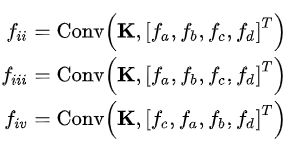
对于Convolution来说,输入点的顺序发生变化,输出也会变化。这并不是我们希望的结果。因为它们是同一个点云,我们希望即使输入的顺序发生变化,Convolution也能得出相同的结果。所以,点云里面的点的输入顺序,是阻碍Convolution操作的主要问题。论文定义了一个 χ变换矩阵,该矩阵能对某个特定顺序的输入进行处理,得到一个与顺序无关的feature。先经过 χ变换矩阵处理,再执行Convolution的操作:

其中,不同的输入顺序,对应不同的 χ 变换矩阵。对于以上等式中的fiii和fiv,如果能够使χiii= χiv × II,II满足:
![]()
这样的话,fiii和fiv理论上就能相等,Convolution的输出不再与输入点的顺序有关。2 算法
先看CNN的卷积,CNN的输入是[R1,R1,C1]而卷积核的大小是[K,K,C1,C2]从前一层F1中大小为[K, K, C1]的区域生成F2中形状大小为[R2, R2, C2]的特征。其中R2
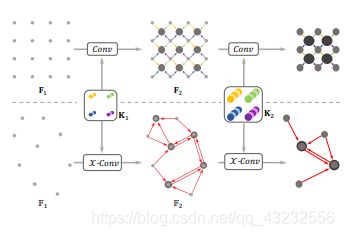
上边的是CNN,通过conv提取特征,通过池化降采样,下面是PointCNN,类似。 通过X-Conv把点减少,把特征集中到某些点上。F2中的点怎么选,论文里说他们以后还要改进,暂时的实现是:对分类问题:p2是p1的随机下采样,对语义分割问题:p2是p1的最远点采样。
为了实现与conv类似的空间局部相关性,X-conv只作用于局部区域。在F2中的任何一个点,叫做p, 而p在F1中的K临近称作N。所以每一个X-conv针对p的输入是S = {(pi, fi ) : pi ∈ N}, 注意这里S是一个无序集合。不失一般性,S可以表示为KxD的矩阵,P = (p1,p2, …,pK )T 和一个KxC1的矩阵F = (f1, f2, …, fK )T。(一个是点的位置矩阵,一个是特征的矩阵),所以X-Conv的参数有K × (C1 + Cδ ) × C2个。(Cδ 在后面提到)具体的计算方法是: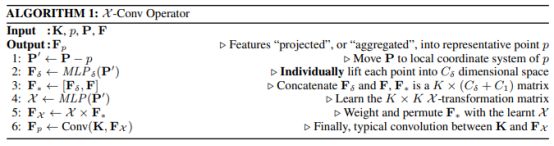
1)P′ ← P − p 得到P相对于p的坐标,p目标点;
2)Fδ ← MLPδ (P′) 将每个点映射到Cδ维的空间中,逐点使用MLP;
3)F∗ ← [Fδ , F] 把Fδ 和 F拼接起来 F∗ 是一个 K × (Cδ + C1) 矩阵,K卷积核;
4)X ← MLP(P′) 用P′预测KxK矩阵;
5)FX ← X × F∗ 到这一步就做完X变换了;
6)Fp ←Conv(K, FX) 做卷积;
1)将所有邻居点的坐标转化为相对p的坐标P’ ← P - p:
2)用一个 MLPδ 网络,将邻居点的位置信息转化为feature信息: Fδ ← MLPδ (P′);
3)将转化得到的feature,与邻居点自己的feature拼接,得到新的feature: F∗ ← [Fδ , F];
4)用一个MLP网络计算出特定输入顺序对应的X 矩阵:X ← MLP(P′) ;
5)用矩阵对特定顺序的feature矩阵进行处理: FX ← X × F∗ ;
6)执行Convolution:Fp ←Conv(K, FX) ,得到 p点的feature。
Fp = X - Conv(K,p,P,F)= Conv(K,MLP(P-p) × [MLPδ(P-p),F])
可以看出,对于不同的顺序,计算出来的X是不同的。论文中给出了一个feature可视化的结果:

F∗ 与邻居点的排列顺序有关,不同的排列顺序,得到的F∗ 不同。第二张图中,同一个颜色的点,表示点p的邻居点集,按不同的排列顺序得到的F∗集合,用 T-SNE 可视化后的结果。对比第三张图片,可以看出,用X 矩阵处理后的FX集合,同一个颜色的点更加集中一些。这说明X 矩阵虽然无法完全实现预期(同一个颜色的点的位置相同),但对不同顺序的feature,能起到一定的修正作用(同一个颜色的点变的集中一些)。3. 总结
PointConv: 3D点云卷积 (CVPR 2019)
1. 卷积概念、论文核心思想
2. 具体实现

2.1 权重函数
论文主要通过一个MLP网络来学习出连续的权重函数。以上图中Compute Weight标记的模块,即为学习出权重函数的MLP。主要由两个共享的1×1Conv层组成。
2.2 密度模块
该模块主要目的是处理点云采样不均的情况。由于卷积本质上是一个加权求和的操纵,如果某些位置的采样点比较密集,而某些位置的采样点比较稀疏,直观感受来看,最终的计算结果主要受到采样密集的位置的点的影响。为了处理这个问题,论文先离线计算出每个点的Density,然后使用一个MLP网络学习出inverse density,来对输入Fin进行调整(re-weight)。3. 优化

4.总结
PointRend: 从图像渲染的角度思考分割问题
本文介绍一篇FAIR关于图像分割的文章。作者从图像渲染的角度出发,提出了一种新的高效、高质量的图像分割算法.。1. 概述
1)首先使用宽、高两个维度的坐标构成的均匀网格对图片进行划分。每个格子(每个坐标点,或者每个像素点)相当于一个采样点;
2)然后使用分割算法,对每个采样点进行分类。
1)对于图片中低频区域(low-frequency、smooth-area),里面的点,大概率属于同一个物体,直觉上,没必要使用太多的采样点。如果使用的点太多,相当于过采样(oversample);2)对于图片中高频区域(high-frequency),里面的点,大概率靠近物体边界。直觉上,如果这些区域的采样点太稀疏,最终会导致分割出来的物体边界过于平滑,不太真实,相当于欠采样(undersample);相反,如果采样点越多,分割出来的物体边界应该会更精细(sharp boundery)、真实。
2)然后通过渲染(rendering),将位置不规则的采样点的像素值,映射(例如插值)到位置规则的grid里面。
1)先通过一种“合理”的采样方式进行非均匀采样,计算出每个采样点的分割结果;
2)然后再将结果映射到规则的grid里面,类比rendering的过程。论文将此方法称为:PointRend。2. 具体方法
2.1 Point selection strategy:选点策略
这步操作主要完成:灵活、自适应的选择合适的采样点。例如,高频(边界)区域多采点,低频区域少采点。具体实现时,Inference和training区别对待。

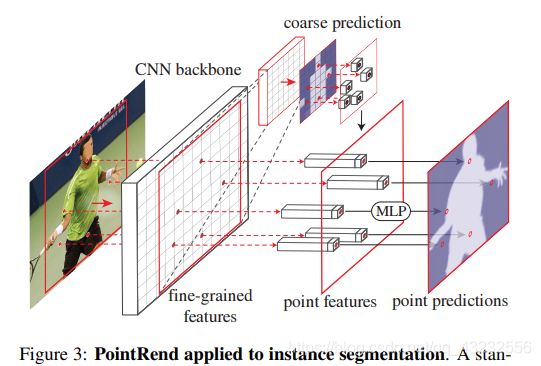
对于每个待分割的region,使用coarse-to-fine的方式来进行分割。大概的分割流程如下:
1)从分辨率最小的层开始,使用规则的grid对该层进行划分后,对每个点进行预测(对应于上图中的最左边的4x4的格子);
2)然后经过多次upsample迭代操作,直到upsample的分辨率满足要求为止。每次迭代的操作如下:
①对前一层的分割结果,使用双线性插值进行上采样(对应于上图中间的8x8格子)。它是通过对左边的4x4的格子使用双线性插值进行上采样后的结果。
②在采样后的结果里面,选择N个最不确定的点。所谓最不确定,是指分割的概率最接近0.5的点,这些点分不清是前景,还是背景(对应于中间图里面有黑圈的位置)。可以看出,这些点位于边界处。
③对于选出来的N个位置,分别计算出每个点的feature(如何计算,后面会提到),并根据feature对其进行分割预测,用得出的结果,更新upsample时插值得出的结果(对应于最右边的图)。相当于“特殊处理“了一下最不确定的N个点。

上图展示了4中采样方式。论文指出,mildly biased采样在training过程中的效果最好。biased采样,是指:向预测结果不确定的点“偏移“的采样方式。
选出来N个最不确定的点后,需要重新预测这些点的分割结果。预测的时候,需要使用这些点的feature。这步操作主要完成每个点的feature的计算。每个点的feature由以下两部分组成:
1)Fine-grained features:使用例如ResNet这样的backbone CNN网络抽取出来的feature;
2)Coarse prediction features:网络计算出来的一个粗略的分割结果。
两部分拼接到一起,构成一个点的feature,作为point head的输入。
point head相当于一个MLP多层网络。通过上面的步骤,计算出每个特殊点的feature后,通过MLP,对每个点的feature进行处理,得出一个新的预测结果。
3. 总结
RS-CNN for Point Cloud(Relation-Shape Convolutional Neural Network) :点云卷积(CVPR 2019)
1. 核心思想
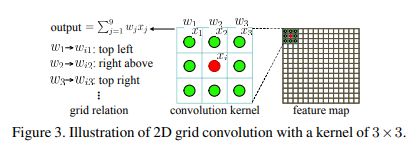
从图中可以看出,对于kernel里面的每个参数,都隐含着一个固定的位置关系。例如,以中心点为参考点,w1对应左上角这个固定的位置,w3对应右上角这个固定的位置。2. 几何拓扑关系信息
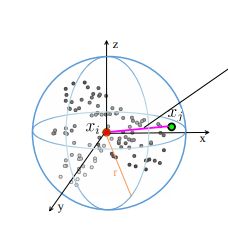
如上图所示,对于一个中心点xi,以r为半径的球体范围内的点,看作xi的邻居点。对于任意邻居点xj,如何描述其相对于中心点xi的几何拓扑关系信息hij?
论文中给出了如下几种方式:

上图中第二列给出了表示hij的5种实现方式,从实验结果来看,第三种效果最好。第三种方式的含义是:
1)3D-Ed:xi到xj的距离,1维;
2)xi-xj,:两点坐标之差,3维;
3)xi,单点坐标,3维;
4)xj,单点坐标,3维;
将以上信息拼接到一起,组成一个channel是10的feature,作为几何拓扑关系信息 。3. RS-CNN结构

如上图所示,基于点xi的RS-CNN操作流程如下:
1)以r为半径找邻居点;
2)对于每个邻居点执行(以xj为例):
①用一个共享的MLP(M )学习出邻居点对应的卷积参数wij,wij与邻居点的featur(fxj)的channel数相同;
②参数和feature按位乘:wij*fxj ,得出新的feature;
4)用一个非线性的激活函数σ来处理A的结果;
5)最后用一个共享的MLP进行channel变换,得出点xi的feature。
fPsub = σ (A({M(hij)·fxj, ∀ \forall ∀xj }))4. 总结
Contextual Point Representations
1. 概述
1)每个点的初始feature表达力不足。每个点的feature不仅可以包括x、y、z等三维坐标,也可以加上该点的颜色、法向量等信息,同时也没有考虑领域点的信息。
2)点云局部结构的复杂性。点云的局部结构可能会很复杂,光靠PointNet++里面处理局部的方式(Pointnet)过于简单,学出效果较差;
3)没有研究点与点之间的全局关系;
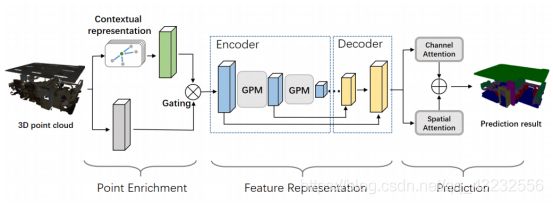
从图中可以看出,模型总体分为3部分:
Point Enrichment
Feature Representation
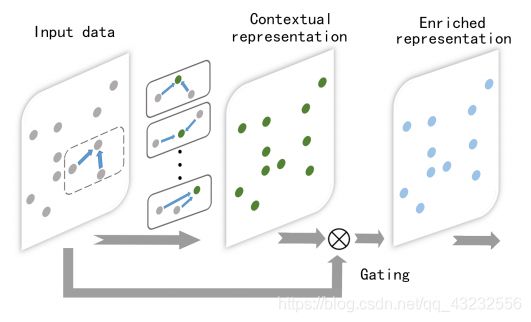
Prediction2.Point Enrichment

论文将这种融合方式成为:gated fusion strategy, 并给了一个流程图:
3. Feature Representation
Encoder使用的PointNet++中的sampling + grouping的方式,对点云进行downsampling。在PointNet++里面,融合邻居点feature来计算中心点feature时,采用的是一个类似于PointNet的网络结构来处理邻居点构成的局部点云。论文认为这种方式过于简单,不利于学习出局部点云内,点与点的复杂关系,提出了一个新的GPM(Graph Pointnet Module)模块。GPM模块的大概结构如下图:
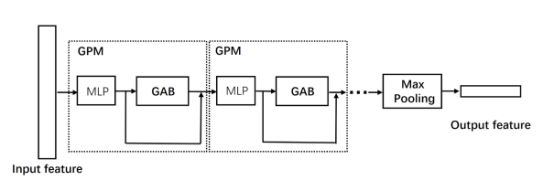
Input feature表示一个local structure(pointnet++ grouping后得到的一个局部点云)。一个GPM模块的操作步骤如下:
在网络中,可以串连多个GPM来多次对邻居点的feature进行融合。最后使用Max Pooling计算出中心点的feature。
3.2 Decoder
Decoder来用了PointNet++里面的方式来实现。4 Prediction
4.1 Spatial-wise Attention
总体思路是:在global范围内,通过计算点与点之间的相关性来融合。具体实现:
1)输入的点云的feature:F∈RCd×Nd ,Cd表示点云的点数,Nd表示每个点的feature的维度。
2)通过两个不同的FC层,计算出连个新的featuer:A,B,{A,B}∈RCd×Nd ,使用A,B计算出全局点与点的影响因子,例如:j对i的影响因子为:vij = softmaxj(Ai·Bj);
3)用另外一个FC层,用F作为输入,计算出另外一个特征:D∈RCd×Nd ;
4)用vij对D融合:

经过融合后,可以认为,每个点的feature里面,包含了全局的关系信息。
总体思路跟spatial-wise attention类似,是在全局channel维度上进行的一个attention融合操作,例如,分别计算出channel之间的相似度,再用softmax计算出channel之间的影响因子,最后用影响因子对channel进行融合。最终可以得到类似的feature: F ~ \widetilde F F ∈ RCd×Nd。
并 F ~ \widetilde F F 和 F ^ \hat F F^,再用一个FC层,即可得到最终的预测结果。5 总结
1)每个点的初始feature,使用Point enrichment,不仅包含自身的信息(坐标、颜色、法线),还融合了它与邻居点之间的相关信息;
2)在计算每个点的feature时,使用GPM模块,进一步将邻居点的信息融合到中心点的feature上。
3)最后在整个点云全局范围内,使用两种attention机制(spatial-wise,channel-wise)进一步融合feature信息。
4)最后基于局部、全局融合后的feature,计算出label。ImVoteNet: 用2D图片信息 优化 3D点云物体检测(CVPR2020)
本文介绍一篇点云物体检测的文章。与当前大部分只从3D点云得出检测结果的算法不同,文章提出的算法,不仅使用3D点云,还使用了对应的2D图片的相关信息(2D物体几何坐标、类别、feature等)。2D与3D结合后,性能得到了一些提升。1. 核心思想
2. VoteNet回顾

其流程:

该流程的核心在于第3步 和 第5步:
第3步:每个原始点投票得出一个该点所属物体的中心点信息:3D坐标+feature。
第5步:对于一个球体内的点,其表示某个原始点vote出来的原始点所属物体的中心点,以及中心点的feature。一个球体内的所有点,他们分别代表的物体中心点应该是很接近的。用这些很接近的vote结果,再经过一个类PointNet网络,计算出一个最终的结果。
1)每个点分别投票得出一个所属物体的中心点;
2) 一堆很接近的中心点,再预测出一个最终的结果;3. ImVoteNet概述
· 2D图片的信息加到哪里?
· 2D图片里面到底有哪些有用信息?
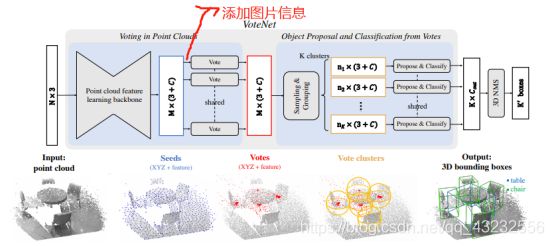
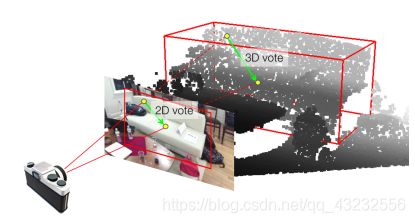
在进行Vote之前,对M个点的feature进行扩充,给每个点分别添加2D图片的有用信息。点云上的每个点,都能映射(projection)到2D图片的一个像素点。因此,可以借助这种对应关系来丰富点云的feature。点云与2D图片的对应关系如下图所示:
对于第二个问题(2D图片里面有哪些有用信息?),正是论文的重点。总的来说,可以从2D图片提取出3类信息,来增强点云的feature:
1)几何信息(Geometric cues)
2)语义信息(Semantic cues)
3)纹理信息(Texture cues)4. 图片的几何信息(Geometric cues)

在一个针孔相机模型下:
p:表示2D图片上某个物体上的一个像素点;
c:表示2D图片上的点p所属物体的中心像素点;
P:表示2D图片上的点p,在3D点云上的对应点;
C:表示2D图片上的点p所属物体的中心像素点,在3D空间里面的对应点(这个点是未知的,但是其所在的直线是可以算出来的)。这个点的坐标,就是VoteNet需要计算的一个目标值。根据前面的描述,模型只需要在OC这条线上搜索物体中心点C即可。
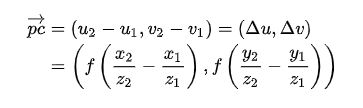
为了简化问题,论文假设3D物体中心点C 的深度(z 坐标)与点P的深度相同。基于此假设,并且由于中心点要落在直线 OC 上,因此,3D物体的中心点变成了上图里面的点 C’ 。根据相机模型,可以计算出3D空间里面的向量:
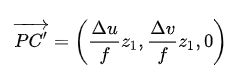
虽然点 C’不是我们最终需要的,但对于点P来说,C’里面包含了点C相对于点P 的一些几何位置信息,这或许能够帮助点 P更好的vote出点 C的坐标。除此之外,点C 所在直线的方向信息,或许也能够帮助点P更好的vote出点 C的坐标。根据相机模型,可以计算出这条直线的方向向量:
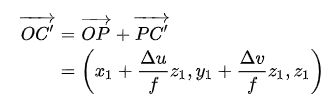
最终,把 P C ′ → \overrightarrow {PC'} PC′的前两个分量,和 O C ′ → \overrightarrow {OC'} OC′Normalize之后的向量信息,作为格外的feature,添加到点P的feature里面:

4. 图片的语义信息(Semantic cues)
5. 图片的纹理信息(Texture cues)
6. 特征融合、多模态训练(Feature Fusion and Multi-tower Training)

从上图可以看出,最终的feature分为3组,用3个分支来训练:
1)只使用从2D图片信息的信息作为feature来vote(image tower);
2)只使用3D点云里面点的feature来vote(point tower);
3)将3D点云里面点的feature和从2D图片提取到的feature拼接起来,一起vote(joint tower);

每个分支用不同的权重来控制。为何不使用一个分支来训练,而需要3个分支?论文中提到,如果只用joint tower分支,效果反而可能会下降,原因是直接使用多模态feature时,如果控制不好,一部分feature可能会起到主导作用,最后导致overfitting。为了避免这个问题,所以采用了这种多分支的训练方式(gradient bleading startegy)。7. 总结
Non-local Neural Networks (CVPR 2018)
1. Motivation
1)模型参数增多,计算量增大;
2)深层网络可能出现梯度消失、梯度爆炸等问题,不是很好训练;
3)距离较远的两个位置之间,需要经过多层之后,信息才能传播给对方。中途多次传播时,可能出现信息丢失,受噪声干扰等。看上去很难。2. Non-local Operation Formulation
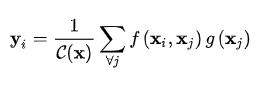
其中:

从公式里面可以看出,当计算某个位置i的输出yi是,所有位置的feature都作为输入,参与运算。最后得到的输出自然就不再是一个local feature了(non-local)。yi相当于所有位置的 x的加权求和。3. Non-local Operation Instantiations
1)Gaussian
2)Embedded Gaussian
3)Dot product
4)Concatenation
对于Embedded Gaussian,上面公式里面的各个分量依次为:

按照这种实现,f(xi,yi)/C(x)正好是沿维度j计算softmax后的第j个分量。4. Non-local Block
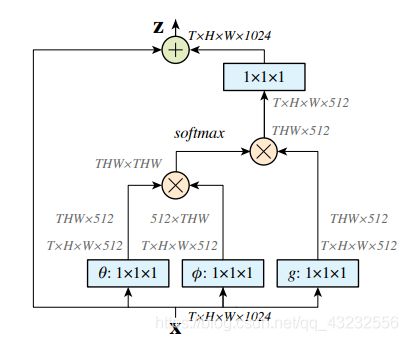
从实验结果上看,Non-local Block能够很好的从全局范围内获取有用的信息:
图中,起始点表示目标点 xi,结束点表示按softmax得分排序后,得分最高的前20个点。5. Conclusion
1)在每个点的邻域范围内,用多个邻居点的feature,融合出中心点的feature;
2)在全局范围内,使用所有点的feature,计算出一个点的feature。Graph Attention Networks (ICLR 2018)
1. Graph Attention 操作流程
1)N:图网络中点的个数;
2) h → \overrightarrow {h} h:一个点的特征向量;
3)h:所有点的向量构成的集合;
4)F:每个点的特征向量的维度;
因此,Graph Attention的输入为:
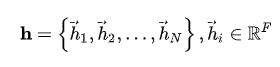
首先,用一个共享的线性变换模块,对每个点进行处理。线性变换模块的参数为:W∈RF’×F,则所有点的特征为:
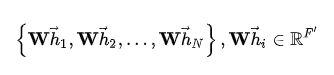
对于任意一个点i,定义一个函数a:R(F’)×R(F)→R,用来计算点i与其任意一个的邻居点 j(在图中,ij之间有一条有向边,并且点i本身也作为自己的邻居点参与计算)的feature之间的影响度eij,表示邻居点j的feature对点i的feature的影响度:
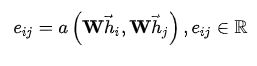
用softmax对邻居点j对点i的影响度eij进行归一化处理(normalization):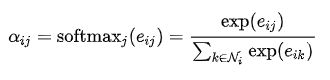
具体实现时,函数a为:
相当于将两个点的feature拼接起来后,用一个全连接层+leakyReLU进行处理。所以:
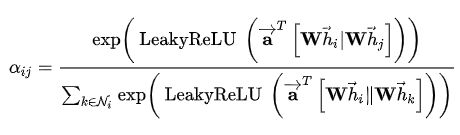
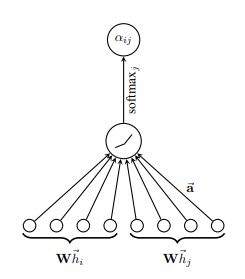
最后,对点i的所有邻居点的feature(包含点 本身),用α加权求和,并有激活函数σ处理,得到点i经过Graph Attention处理后的feature:

以上计算流程可总结为下图(single-head attention):
为增加训练过程的稳定性,可以使用K个Attention分支并行计算,最后将所有分支的结果拼接起来,或者求K个分支的均值。
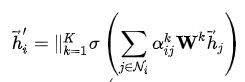
2)求K个分支的均值:
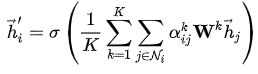
多分支的方式可以总结为下图:
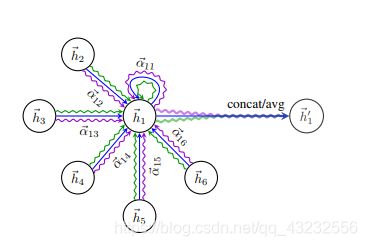
2. 总结
PointASNL: 点云Adaptive Sampling与Nonlocal(CVPR 2020)
1. 噪点
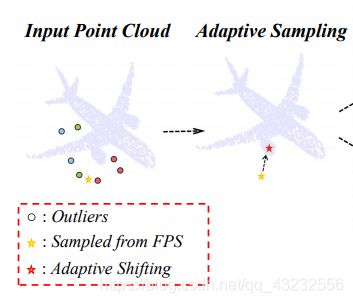
在学习点云的feature时,一般使用encoder + decoder的网络结构。在encoder的downsampling过程中,一般使用FPS采样算法来采样。2. Adaptive Sampling(AS)模块

AS模块首先从上一层的点集合中使用FPS下采样得到Ps、Fs。后续的操作流程如下:
2.1 用KNN找邻居点集
2)重新构建邻居点的feature:每个邻居点的相对坐标,与邻居点的feature,拼到一起,得到每个邻居点的新feature。
3)用self-attention模式,分别计算出邻居点集的3个feature矩阵:query、key、value。
4)用query和key矩阵相乘,并用softmax,得到邻居点之间的attention矩阵。对attention进行scale。
5)用attention和value矩阵相乘,得到所有邻居点feature。
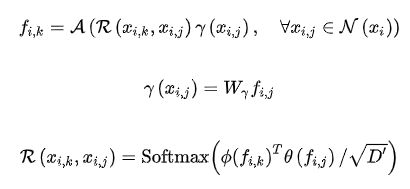
2.3 调整采样点
1)邻居点集的feature的每个channel的attention权重向量,然后分别在每个channel上,用对应channel上的attention权重向量,加权求和,得到采样点xi调整后的feature。
2)邻居点集的坐标的attention权重向量,然后用该attention权重向量,对所有邻居点的坐标加权求和,得到采样点 调整后的坐标。
1)Self-attention后的feature,经过一个多层MLP网络,得出一个新的weight矩阵,该矩阵的维度是:【batch,point_number,neighbor_number,channel+1】。这里额外增加的一个channel是为了后面计算邻居点集的坐标的权重矩阵。
2)在以上的neighbor_number维度上,用softmax,计算出邻居点集的每个channel、坐标的权重矩阵。
3)用channel维度上的权重矩阵,对邻居点集的feature在每个channel上进行加权求和,得到点xi调整后的feature。
4)用坐标的权重矩阵,对邻居点集的坐标进行加权求和,得到点xi调整后的坐标。3. Local-NonLocal(L-NL)模块

其中g是一个MLP网络,将邻居点相对坐标映射为卷积操作的系数矩阵。
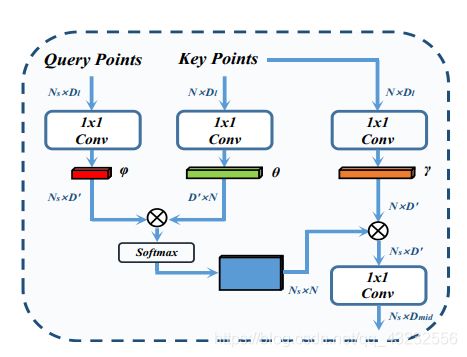
其中:
Query Points:用FPS在前一层点云中采样,并用Adaptive Sampling调整后所得的点云feature;
Key Points:前一层点云的feature。4. 网络结构
每个下采样操作,相当于FPS -> Adaptive Sampling -> Local-Nonlocal
每个上采样操作,相当于Up-Sampling -> Local-Nonlocal总体结果如下图所示:
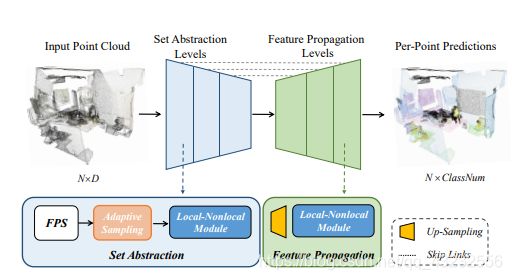
5. 总结
Adaptive Sampling的核心是Self-Attention、Attention,
Local-NonLocal的核心是Self-Attention、PointConv。