【写在前面】
作者提出了统一文本和框输出的 UniTAB,用于基础视觉语言 (VL) 建模。ground的 VL 任务(例如grounded captioning)需要模型生成文本描述并将预测的单词与对象区域对齐。为此,模型必须同时生成所需的文本和框输出,同时指示单词和框之间的对齐方式。与使用多个单独模块用于不同输出的现有解决方案相比,UniTAB 使用共享token序列表示文本和框输出,并引入特殊的 \
1. 论文和代码地址

UniTAB: Unifying Text and Box Outputs for
Grounded Vision-Language Modeling
论文地址:https://arxiv.org/abs/2111.12085
代码地址:https://github.com/microsoft/UniTAB
2. Motivation
文本序列和边界框是图像理解任务的两种代表性输出格式。文本非常适合生成图像级预测,例如用句子描述图像或使用关键字标记图像,但无法引用密集图像区域。另一方面,box 可以指向任何图像区域,但它提供语义丰富的描述的能力有限。一个自然的问题是,能否有一个统一文本和框输出的模型,即在将预测词与框对齐的同时生成文本和框输出。统一这两种输出格式可以让模型更好地表达图片。以字幕为例,这样一个统一的模型可以将字幕中的所有名词实体返回到对齐的图像区域,从而提供更全面和可解释的图像描述。这个问题被称为grounded captioning。此外,统一输出格式是朝着构建与任务无关的通用视觉系统的宏伟愿景迈出的重要一步,该系统具有参数效率和良好的泛化性。
最近的工作开发了可以生成文本和框输出的模型。具体来说,该系统将预测框的在线或离线对象检测模块与生成文本的视觉语言模型相结合。然后分别生成单词和框对齐作为附加预测,例如相关性分数。分别预测文本、框和它们的对齐方式会削弱统一系统的好处。单独的模块阻止了框架的简单和参数效率。此外,显式目标检测组件增加了模型运行时间,并可能限制其在给定预设检测器词汇的情况下的泛化能力,如之前的 VL 研究中所讨论的。除了这些成功的初步探索之外,作者还提出了一个更大胆的问题:能否在没有单独模块的情况下统一输出格式?具体来说,作者探讨 1)如何在没有显式检测器联合生成文本和框的情况下拥有单一架构,以及 2)如何在输出中自然地表示词框对齐以避免额外的对齐预测。为此,作者将文本和框预测建模为自回归token生成任务,并提出在文本、框和对齐预测之间完全共享的单个编码器-解码器模型。
本文的框预测建模灵感来自 Pix2seq ,这是一项对象检测研究,表明以自回归方式预测框会产生良好的检测性能。其核心思想是将每个box中的四个坐标量化为四个离散的box token,并以固定的方式排列为token序列:$\left[y_{\min }, x_{\min }, y_{\max }, x_{\max }\right]$。然后可以将框预测建模为多步分类任务,而不是传统的坐标回归 。与文本生成中相同的分类建模使得统一文本和框预测成为可能。然而,Pix2seq 是为单模态目标检测任务而设计的,不支持开放式文本生成,也不支持多模态输入和输出。此外,尚不清楚文本和框对齐如何以统一的顺序呈现。
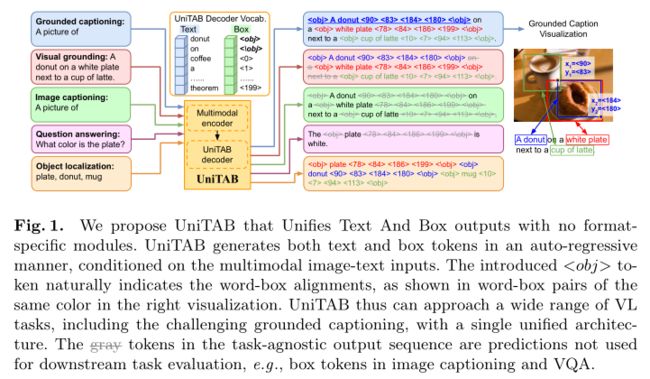
在这项研究中,作者提出了统一文本和框输出的 UniTAB。如上图所示,作者将开放式文本生成 和离散框标记预测统一到一个共享解码器中。在自回归解码期间,UniTAB 在任何要ground的文本词之后立即切换到框标记,并在预测框后切换回文本标记。在 UniTAB 中,作者研究如何处理这种文本框代码切换并自然地表示词框对齐。作者引入了一个特殊的 \
作者进一步将 UniTAB 应用于一般 VL 任务 并观察到两个独特的属性。首先,文本、框和对齐预测的统一架构使 UniTAB 能够执行多任务训练 ,它为不同的 VL 任务学习一组参数,而无需引入特定于任务的头。多任务训练避免了特定于任务的模型副本,从而保存了要存储的参数。它还有助于在不同任务中使用数据,从而提高某些 VL 任务的性能。其次,如上图所示,UniTAB 的输出序列设计为与任务无关,并且在不同的 VL 任务中共享相同的文本+框设计。与任务无关的输出设计可以帮助 UniTAB 泛化到某些看不见的任务,方法是将新任务的所需输出重新格式化为可见的文本+框序列。
作者在 7 个 VL 基准上评估 UniTAB,包括grounded captioning、 visual grounding、 image captioning 和视觉问答,所有这些都具有单个编码器-解码器网络架构,由交叉熵语言建模目标训练。借助统一的框架和最低限度的特定任务假设,本文的模型可以实现与特定任务的现有技术更好或相当的性能。在grounded captioning中,UniTAB 不仅通过消除单独的任务特定头提供了一种更简单的解决方案,而且还显着优于现有技术 。本文的贡献总结如下:
- UniTAB 是第一个可以处理广泛任务的 ground VL 模型,包括具有挑战性的grounded captioning,而无需单独的输出模块。作者引入了 \
token,它可以帮助文本和框输出协同工作,并自然地表示它们的对齐方式。 - UniTAB 在 7 个 VL 基准测试中实现了与现有技术更好或相当的性能。其统一的多任务网络和与任务无关的输出序列设计使其参数高效且可推广到新任务。
3. 方法
3.1 Architecture Overview
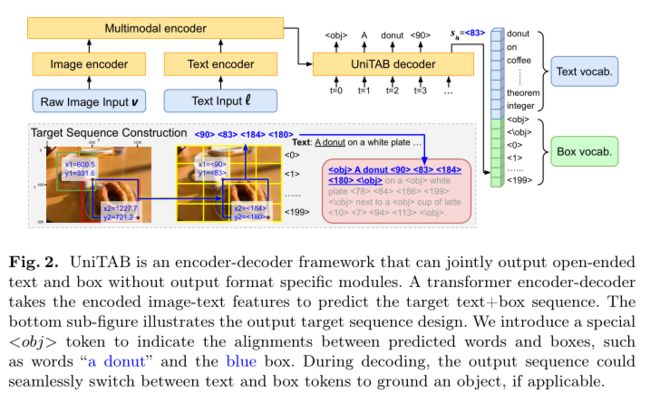
作者使用构建在单模态图像和文本编码器之上的Transformer编码器-解码器架构来实现 UniTAB,如上图所示。对于图像,作者使用 ResNet-101对原始图像输入 v 进行编码,并将网格特征展平作为视觉表示。对于文本,使用$RoBERTa_{BASE}$将输入文本 l 编码为隐藏词特征。作者使用一个 6 层的 Transformer 编码器,它接收concat的图像和文本特征序列作为输入,以及用于生成输出序列的 6 层Transformer 解码器。解码器以自回归方式生成输出token,类似于语言建模。 UniTAB 解码器可以从文本和方框词汇中生成token,如上图右侧所示。
3.2 UniTAB Target Output Sequence
作者展示了如何构建真实的目标输出序列,使得文本和框可以用包含在行内的词框对齐来联合表示。
Box token sequence
作者首先回顾 Pix2seq中引入的边界框量化方法。如上图底部所示,二维图像中的矩形边界框可以用四个浮点数表示,即$\left[x_{\min }, y_{\min }, x_{\max }, y_{\max }\right]$。已建立的对象检测范式预测四个连续浮点值以在单个步骤中回归坐标。相比之下,Pix2seq 将每个坐标量化为一个 $n_{\text {bins }}$个 离散bin,并用顺序排列的四个标记表示每个框。作者采用类似的想法,将每个框表示为四个离散的token

其中\
Unified decoding sequence with \ token
本文的目标是有一个统一的解码序列 s 可以联合表示文本和框,同时表示词框对齐。对于前者,作者统一了文本和框词汇表,这样单个解码器就可以在任何解码步骤中自由生成文本或框token。具体来说,UniTAB 的解码词汇包含文本和框token,大小为 $n_{\text {text }}+n_{\text {bins }}+2$。 $n_{\text {text }}$和$n_{\text {bins }}$是文本词汇大小和坐标 bin 的数量。作者对所有四个框坐标使用相同的 $n_{\text {bins }}$个框token。每个解码步骤的输出token选择是在整个统一词汇表上进行的。
剩下的问题是如何表示输出序列中的词-框对齐。作者没有用额外的对齐分数预测,而是使用两个引入的特殊token \
3.3 UniTAB Training
Objective
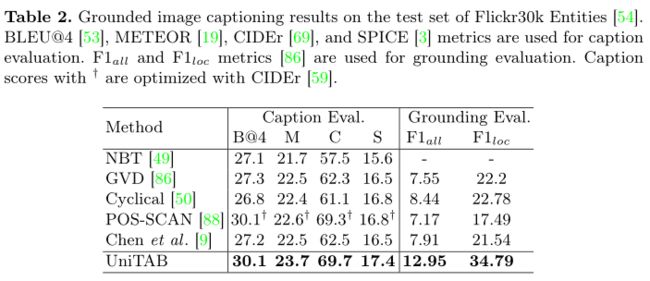
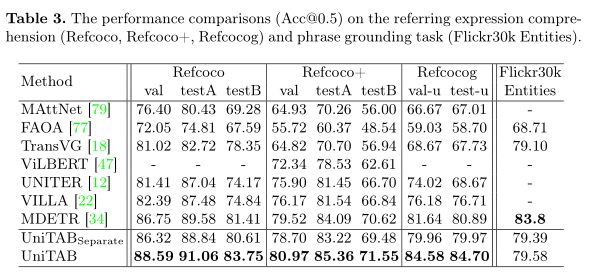
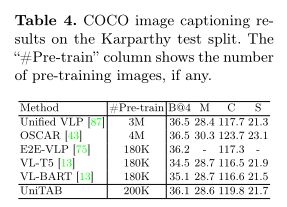
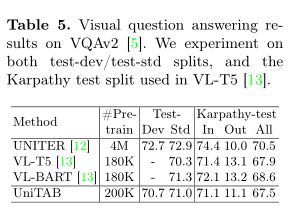
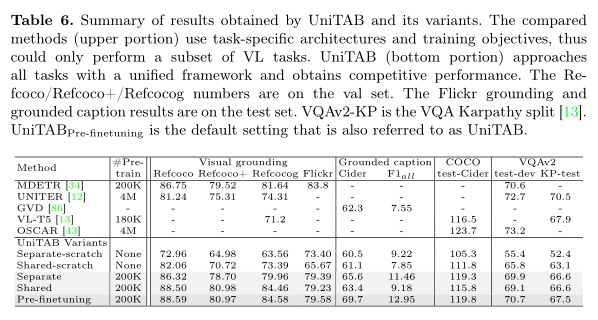
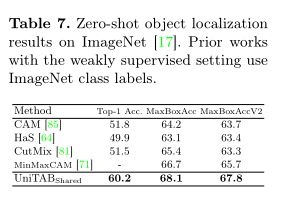
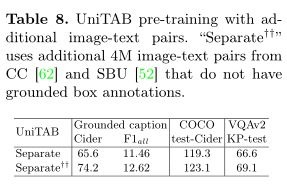
作者使用单一语言建模目标训练模型,即在每个解码步骤 t 中,最大化目标token $s_t$ 以输入图像 v、输入文本 l 和先前目标token$S 其中θ表示模型参数,T是目标序列长度。 UniTAB 的统一结构有助于使用相同语言建模目标的预训练和微调。作者最多训练三个阶段的 UniTAB。第一个是视觉语言预训练,它利用大规模图像文本数据集可选地带有ground框注释。然后,执行多任务微调,将多个带有监督注释的下游任务数据集合并,为不同的 VL 任务微调单个模型。最后,进行特定于任务的微调,使模型适应每个特定任务以进一步改进。这三个阶段的训练目标相同,但具有不同的训练语料库和输入输出设计。 预训练旨在使用与下游任务松散相关的大规模数据进行通用 VL 表示学习。使用单一语言建模目标对模型进行预训练,以预测目标序列 s,以图像 v 和输入文本 l 为条件。作者将输入文本 l 随机设置为空字符串或纯文本图像描述,相同的概率为 0.5。训练模型生成上图所示的文本+框序列。因此,该模型在预训练期间学习执行类似captioning(使用空字符串输入)和类似grounding(使用图像描述输入)的 VL 任务。 多任务微调旨在使用来自多个下游任务数据集的监督注释来训练单个模型,从而避免特定任务的模型复制并进一步提高模型性能。UniTAB 的统一架构和训练目标促进了多任务微调的独特属性。多任务微调不是让预训练模型有多个副本,每个副本都针对下游任务进行了优化,而是训练一组参数来执行所有不同的 VL 任务。作者从所有 7 个实验性 VL 任务中收集监督数据注释,并使用语言建模目标训练单个模型。多任务微调的一个主要优点是单个模型可以支持多个 VL 任务,从而节省模型参数。多任务微调还可以通过使用来自不同任务的注释来提高某些下游任务的性能。 UniTAB 还可以执行标准的特定任务微调,如 VLP 研究。此外,作者观察到多任务微调不仅会生成在不同 VL 任务中表现良好的单个模型,而且还可以作为第二阶段特定任务微调的良好初始化点。作者将此设置称为“预微调”。 作者使用 argmax 采样来获得序列预测。然后,从离线序列中提取文本和框预测以进行最终评估。例如,作者丢弃框token以获得文本预测,并去量化框token以获得框预测。最后,作者在每个下游任务上评估模型及其所需的输出格式,例如,用于 VQA 的文本、用于visual ground的框,或用于ground captioning的文本和框。 上表展示了Flickr30k 实体测试集上的Grounded image captioning结果。 上表展示了REC任务和phrase grounding任务的实验结果。 上表为Karparthy 测试拆分的 COCO 图像字幕结果。 上表为VQA v2 上的视觉问答结果。 上表为UniTAB 及其变体获得的结果。 上表为ImageNet 上的Zero-Shot目标定位结果。 使用额外的图像-文本对进行 UniTAB 预训练结果。 上图为UniTAB的定性结果。 作者提出了统一文本和框输出的 UniTAB,用于ground VL 建模。使用特殊的 \ 已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!! 请关注FightingCV公众号,并后台回复ECCV2022即可获得ECCV中稿论文汇总列表。 推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称 面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch 面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair 为感谢各位老粉和新粉的支持,FightingCV公众号将在9月10日包邮送出4本《深度学习与目标检测:工具、原理与算法》来帮助大家学习,赠书对象为当日阅读榜和分享榜前两名。想要参与赠书活动的朋友,请添加小助手微信FightngCV666(备注“城市-方向-ID”),方便联系获得邮寄地址。 本文由mdnice多平台发布
Training stages
1.Pre-training
2.Multi-task finetuning
3.Task-specific finetuning
Inference
4.实验

5. 总结
【技术交流】

【赠书活动】
