手把手带你调参Yolo v5 (v6.2)(三)
手把手带你调参Yolo v5 (v6.2)(三)
文章目录
- 手把手带你调参Yolo v5 (v6.2)(三)
-
- 1.val.py参数解析
-
- 1.1"--data"
- 1.2"--weights"
- 1.3"--batch-size"
- 1.4"--imgsz', '--img', '--img-size"
- 1.5"--conf-thres"
- 1.6"--iou-thres"
- 1.7"--task"
- 1.8"--device"
- 1.9 "--workers"
- 2.0"--single-cls"
- 2.1"--augment"
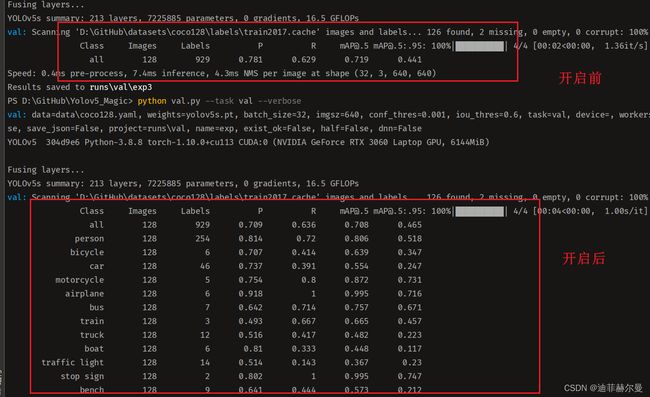
- 2.2"--verbose"
- 2.3"--save-txt"
- 2.4"--save-hybrid"
- 2.5"--save-conf"
- 2.6"--save-json"
- 2.7"--project"
- 2.8"--name"
- 2.9"--exist-ok"
- 3.0"--half"
- 3.1"--dnn"
- 本人更多Yolov5(v6.2)实战内容导航

数据集有三大功能: 训练、验证和测试
训练最好理解,是拟合模型的过程,模型会通过分析数据、调节内部参数从而得到最优的模型效果。
验证即验证模型效果,效果可以指导我们调整模型中的超参数(在开始训练之前设置参数,而不是通过训练得到参数),通常会使用少量未参与训练的数据对模型进行验证,在训练的间隙中进行。
测试的作用是检查模型是否具有泛化能力(泛化能力是指模型对训练集之外的数据集是否也有很好的拟合能力)。通常会在模型训练完毕之后,选用较多训练集以外的数据进行测试。
1.val.py参数解析
先说一下这个文件主要是用来干什么的,我们在训练结束后会打印出每个类别的一些评价指标,但是如果当时忘记记录,很多人就不知道怎么再次看到这些评价指标,那么我们就可以通过这个文件再次打印这些评价指标
还有就是我们在train的时候每轮打印出来的那些评价指标是验证集的评价指标,并不是测试集的评价指标,我们最终要放到论文里面的应该是测试集的评价指标
测试集的图片只在模型训练完成以后跑一轮,并且测试集的图片也是需要标注的!
1.1"–data"
![]()
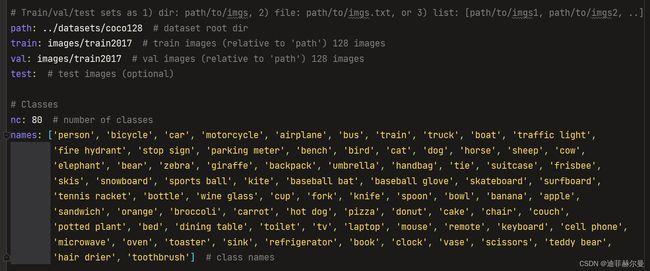
数据集配置文件的路径,默认是coco128数据集,yaml文件里面包含数据集的路径、类别等信息
1.2"–weights"
![]()
模型的权重文件地址 ,这里要改成你想参与验证的模型的路径
1.3"–batch-size"
![]()
前向传播的批大小
1.4"–imgsz’, ‘–img’, '–img-size"
![]()
输入网络的图片分辨率 默认640
1.5"–conf-thres"
![]()
置信度阈值
1.6"–iou-thres"
![]()
NMS时IOU的阈值
1.7"–task"
![]()
这个参数比较重要,这个文件最核心的部分就是这个参数,我们想得到各个数据集的评价指标都是通过这个参数,如果想得到验证集的参数可以使用如下指令,(speed和study似乎还没实现,用了会报错)
python val.py --task test
这样就会打印测试集的评价指标
1.8"–device"
![]()
指定测试的设备
1.9 “–workers”
![]()
线程数,和你训练时一样不报错就好
2.0"–single-cls"
![]()
数据集是否只用一个类别 默认False
2.1"–augment"
![]()
这也是一个比较重要的参数,即测试是否使用TTA Test Time Augment,指定这个参数后各项指标会明显提升几个点,但是如果要用这个参数,你的基线也要记得使用
2.2"–verbose"
![]()
是否打印出每个类别的mAP 默认False
2.3"–save-txt"
![]()
是否保存txt格式文件,默认关闭
打开了就多了这个
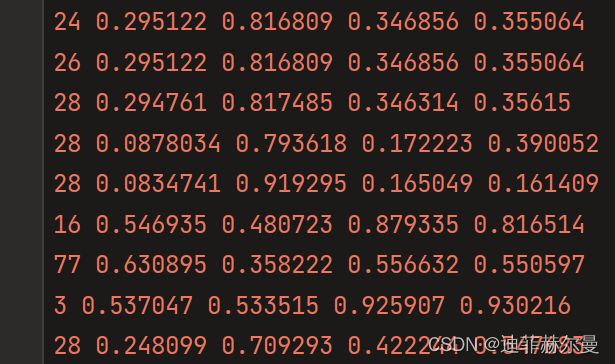
里面就是这样的,包含了类别信息和中心点坐标和宽高
2.4"–save-hybrid"
![]()
将标签+预测混合结果保存到 .txt
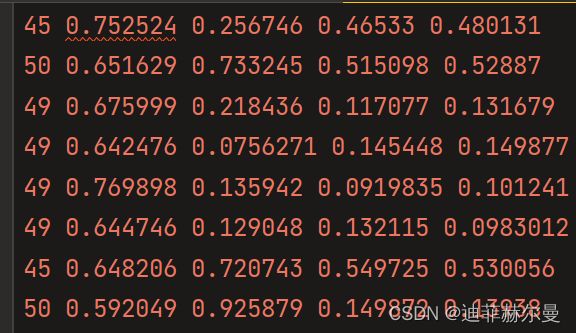
同一个txt文件不开启是这样的
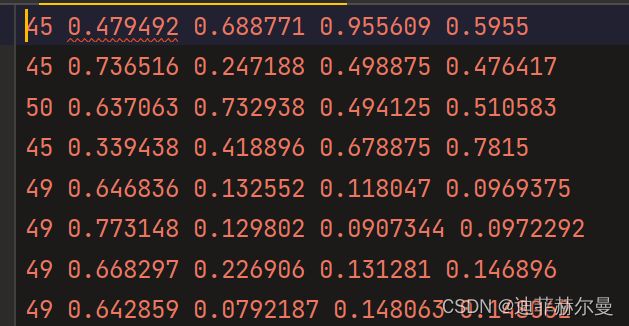
开启是这样的
2.5"–save-conf"
![]()
这个参数的意思就是是否以.txt的格式保存目标的置信度
如果单独指定这个命令是没有效果的;
python detect.py --save-conf #不报错,但没效果
必须和–save-txt配合使用,即:
python detect.py --save-txt --save-conf
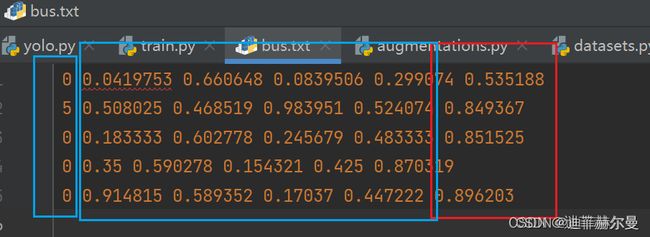
如果指定了这个参数就可以发现,同样是保存txt格式的文件,这次多了红色框里面的置信度值。原来每行只有5个数字,现在有6个了。
2.6"–save-json"
![]()
是否按照coco的json格式保存预测框,并且使用cocoapi做评估(需要同样coco的json格式的标签) 默认False
开启后就多了这个json文件

打开就这这样子的
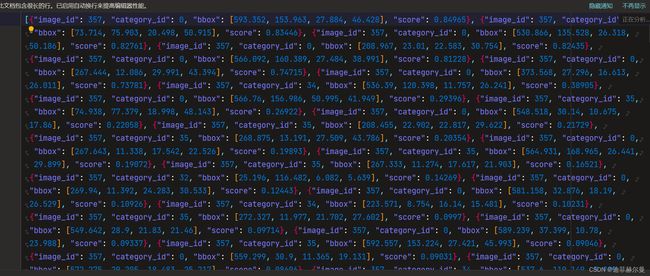
2.7"–project"
![]()
保存的源文件地址
2.8"–name"
![]()
测试保存的文件地址名字 默认exp
2.9"–exist-ok"
![]()
是否存在当前文件 默认False
3.0"–half"
![]()
是否使用半精度推理 默认False
3.1"–dnn"
![]()
这个参数的意思就是是否使用 OpenCV DNN 进行 ONNX 推理
本人更多Yolov5(v6.2)实战内容导航
1.手把手带你调参Yolo v5 (v6.2)(一)强烈推荐
2.手把手带你调参Yolo v5 (v6.2)(二)
3.如何快速使用自己的数据集训练Yolov5模型
4.手把手带你Yolov5 (v6.2)添加注意力机制(一)(并附上30多种顶会Attention原理图)
5.手把手带你Yolov5 (v6.2)添加注意力机制(二)(在C3模块中加入注意力机制)
6.Yolov5如何更换激活函数?
7.Yolov5 (v6.2)数据增强方式解析
8.Yolov5更换上采样方式( 最近邻 / 双线性 / 双立方 / 三线性 / 转置卷积)
9.Yolov5如何更换EIOU / alpha IOU / SIoU?
10.Yolov5更换主干网络之《旷视轻量化卷积神经网络ShuffleNetv2》
11.YOLOv5应用轻量级通用上采样算子CARAFE
12.空间金字塔池化改进 SPP / SPPF / ASPP / SimSPPF / RFB / SPPCSPC
13.用于低分辨率图像和小物体的模块SPD-Conv
14.持续更新中
有问题欢迎大家指正,如果感觉有帮助的话请点赞支持下