目标检测算法实战综述
目录
一、目标检测问题定义
二、目标检测问题方法
三、常见传统目标检测算法
3.1 Viola-Jones (人脸检测)
3.2 HOG+SVM (行人检测、Opencv实现)
3.3 DPM (物体检测)
3.4 NMS(非极大值抑制算法)
四、深度学习目标检测算法原理实践
4.1 基于Two-stage的目标检测算法综述
4.2 基于One-stage的目标检测算法综述
一、目标检测问题定义
目标检测(0bject Detection ) = What, and Where
➢目标种类与数量问题
➢目标尺度问题
➢外在环境干扰问题
目标检测是在图片中对可变数量的目标进行查找和分类: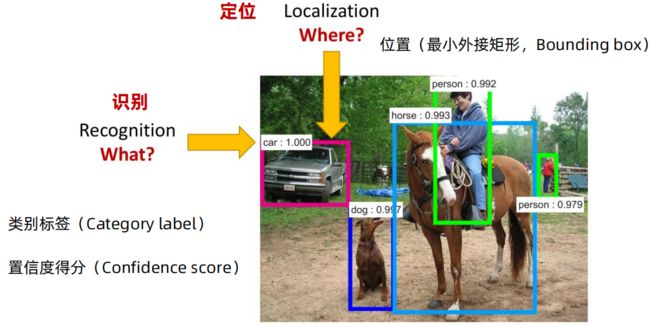
目标检测vs图像分类
目标检测不仅给出图像所在位置标注矩形框,并通过不同颜色的矩形框来表示不同类别;图像分类则是以一张图片作为输入,不同类别的概率分布作为输出。
目标检测vs目标分割
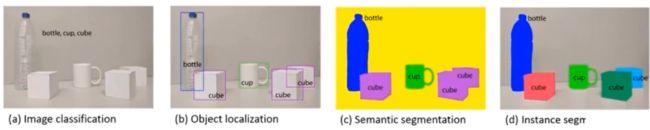
a图为图像分类,只需要指出图像所属的类别
b图为目标检测,需要定位图像所处的位置(不同矩形框)
c图为目标分割,其不同与目标检测,其需要找到当前目标所占的区域,c图表示语义分割;d图则为实例分割;对于语义分割只需要找到同一类目标所占的区域,实例分割比语义分割更加精细,不仅要区分不同语义的目标,而且对于同一类别的目标也要进行分割
总结:对于目标检测来说更关注语义分割层面的结果,对于目标分割更关注对于像素层面的分割结果。目标检测主要是定义物体的位置,位置可以由一个矩形表示(四维数据);目标分割需要对每个像素点进行不同类别的划分,这时候我们的结果需要与原始的图片大小保持一致。
二、目标检测问题方法
传统目标检测方法到深度学习目标检测方法的变迁
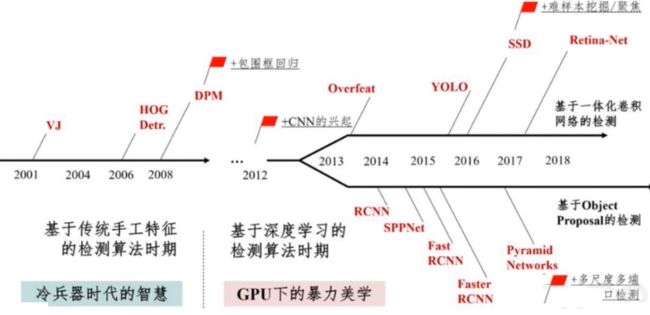
传统目标检测算法包括HOG、DPM等等,这些方法遵循了了传统手动设计特征,并结合滑动窗口的方式来进行目标检测和定位,其主要存在的问题有:1、手动设计特征不但很难设计,往往设计出来的特征会存在各种各样的问题,如对于某些特定条件不适应,特征鲁棒性差,效率低。2、通过滑动窗口的方式定义目标框并对目标框进行判定,在提取滑动窗口是的流程十分地繁琐,速度慢。DPM在imagenet数据集上使用传统方式已经处于高点,传统的目标检测算法已经遇到瓶颈,很难再网上提升。
基于卷积方法如RCNN提出后,目标检测在使用卷积神经网络时,只是使用深度学习进行特征提取,并没有从本质上改变搜索框对目标区域提取的策略。因此这些方法在速度上依然存在瓶颈,直到后来Faster-RCNN这样的方法提出后,通过RTN网络来代替原始的滑动窗口策略也标志着基于深度学习的目标检测方法彻底地完成了一个端到端的过程。整个过程只需要通过一个网络就可以完成,这样就使得在基于深度学习的目标检测方法不仅在性能上,而且在速度上同样得到了很大的提升。
后来我们不采用提取候选框的策略,采用直接回归目标框位置的策略如YOLO、SSD方法来完成目标检测和定位,对目标检测算法有了进一步提升,而且能够有原先Proposal一样的精度。
算法基本流程
传统目标检测方法.
➢Viola-Jones 采用积分图特征结合AdaBoost分类器来进行人脸检测等任务
➢HOG+ SVM 主要用于行人检测的任务,通过对行人目标候选区域提取HOG特征并结合SVM分类器来进行判定
➢DPM 是基于HOG特征的一种变种,在DPM会加入一些额外的策略来提升检测的精度,DPM是目前非深度学习目标检测算法中,性能最优的一种方法。
➢......
深度学习目标检测方法
➢One-stage (YOLO和SSD系列) 直接回归目标的位置进行目标检测和定位
➢Two-stage ( Faster RCNN系列) 易用RPN网络对候选区域进行推荐
传统目标检测方法VS深度学习目标检测方法
➢手动设计特征 ➢深度网络学习特征
➢滑动窗口 ➢Proposal或者 直接回归
➢传统分类器 ➢深度网络
➢多步骤 ➢端到端
➢准确度和实时性差 ➢准确度高和实时性好
三、常见传统目标检测算法
3.1 Viola-Jones (人脸检测)
Haar特征抽取➢训练人脸分类器(Adaboost 算法等)➢滑动窗口
➢Haar特征(value=白-黑)
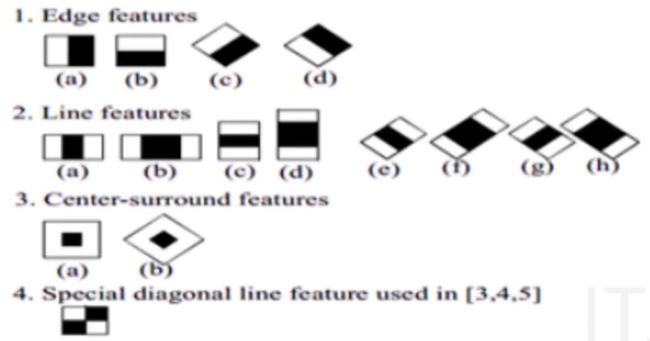
➢Adaboost算法
初始化样本的权重w,样本权重之和为1===》训练弱分类器==》更新样本权重==》循环第2步==》结合做个分类器结果,进行投票
3.2 HOG+SVM (行人检测、Opencv实现)
➢提取HOG特征➢训练SVM分类器➢利用滑动窗口提取目标区域,进行分类判断➢NMS➢输出检测结果
➢HOG特征
(1)灰度化+ Gamma变换(对值进行根号求解,使得数据变得更加平滑)
(2)计算梯度map(计算一个点在X、Y方向的梯度值,然后用x/y得到一个tan,再使用arctan得到一个方向角 ,再将方向角量化到0到360)
,再将方向角量化到0到360)
(3)图像划分成小的cell,统计每个cell梯度直方图
(4)多个cell组成一个block, 特征归一化
(5)多个block串联,并归一化
➢SVM
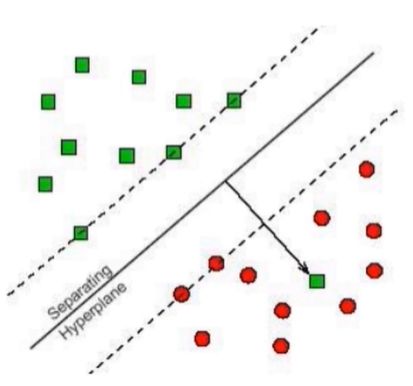
➢最大分类间隔面
3.3 DPM (物体检测)
2008年Pedro Felzenszwalb提出;VOC,07,08,09年的检测冠军;2010 VOC授予“终身成就奖”;是HOG的扩展
➢利用SVM训练得到物体的梯度
DPM特征提取:有符号梯度vs无符号梯度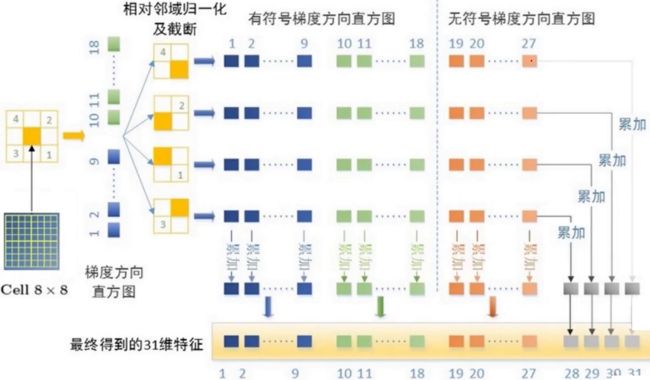
➢计算DPM特征图


➢计算响应图(root filter和part filter)
➢Latent SVM分类器训练
➢检测识别
3.4 NMS(非极大值抑制算法)
➢目的:为了消除多余的框,找到最佳的物体检测的位置
➢思想:选取那些邻域里分数最高的窗口,同时抑制那些分数低的窗
➢Soft-NMS

用分类器对目标检测进行分类时会得到不同分类的概率值,利用概率值对所有检测框进行排序后选出得分最大的那个检测框,把与当前最大检测框与其他检测卡LOU面积超出阈值的检测框进行删除,接下来对哪些没有处理过的检测框重新进行排序,迭代上述步骤。
改进算法:Soft-NMS (非极大值抑制算法)
➢相邻区域内的检测框的分数进行调整而非彻底抑制,从而提高了高检索率情况下的准确率
➢在低检索率时仍能对物体检测性能有明显提升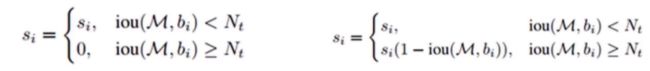
四、深度学习目标检测算法原理实践
4.1 基于Two-stage的目标检测算法综述
Two-stage基本介绍
●CNN卷积特征
●R. Girshick et al, 2014提出R-CNN到faster RCNN
●端到端的目标检测(RPN网络)
●准确度高、速度相对one-stage慢
Two-stage基本流程


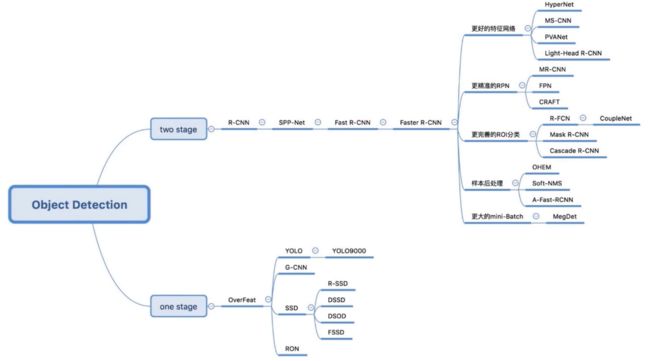
Two-stage常见算法:RCNN、Fast RCNN、Faster RCNN、Faster RCNN变种
Two-stage核心组件:CNN网络与RPN网络
CNN网络设计原则
➢从简到繁再到简的卷积神经网
➢多尺度特征融合的网络
➢更轻量级的CNN网络
RPN网络
➢区域推荐(Anchor机制)
➢ROI Pooling
➢分类和回归
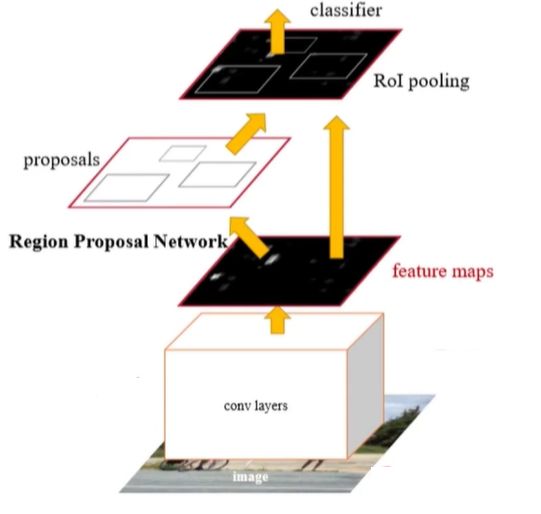
RPN网络的区域推荐(Anchor机制)
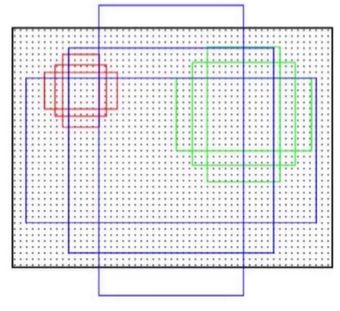
解释:对于当前的feature map其大小为n*c*w*h,用w,h候选区的中心点去提取候选区域,每个点都成为一个Anchor,然后以这个点为中心,提取候选区域。通常Fast-RCNN采用的是9个不同尺度提取9个候选区。
也可参考:RPN网络的anchor机制_wchange7的博客-CSDN博客_rpn网络的anchor生成细节
RPN网络➢ROI Pooling
➢输入: 特征图、rois (1*5x1x1)以及ROI参数
➢输出: 固定尺寸的feature map
rois中5的解释:ROI区域为5个值,正常情况便是矩形框只需要4个值(X,Y,W,H),这里的五个值为(index,X,Y,W,H),最前面的是索引,表示当前batch中的哪个图片。
ROI Pooling主要完成的是一个抠图+resize的操作,resize是使得抠图得到的feature map固定到同一个大小的feature map上。
Two-stage改进方向
●更好的网络特征
●更精准的RPN
●更完善的ROI分类
●样本后处理
●更大的mini-Batch
4.2 基于One-stage的目标检测算法综述
One-stage基本介绍:
●使用CNN卷积特征
●直接回归物体的类别概率和位置坐标值(无regionproposal)
●准确度低、速度相对two-stage快
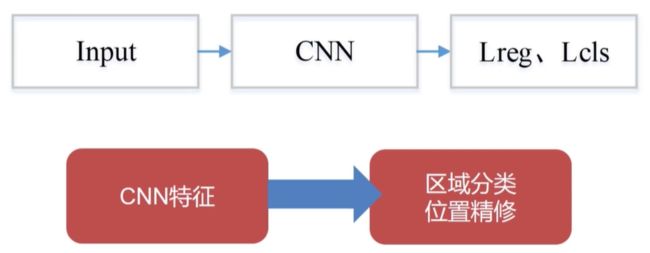
One-stage基本流程:
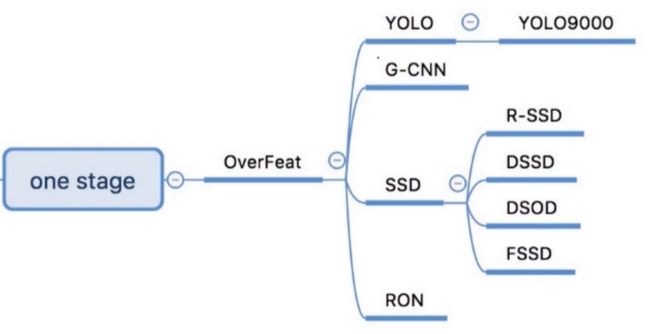
One-stage常见算法:YoloV1/2/V3、SSD/DSSD等、Retina-Net等等
One-stage核心组件:CNN网络与回归网络
CNN网络设计原则
➢从简到繁再到简的卷积神经网
➢多尺度特征融合的网络
➢更轻量级的CNN网络
回归网络
➢区域回归(置信度、位置、类别)
➢Anchor机制(SSD)

区域回归是指通过回归网络直接输出最终目标Bounding boxes的位置信息,如图片中红框和蓝框;置信度是表示当前区域是否存在目标。
回归网络预测过程(Yolo)
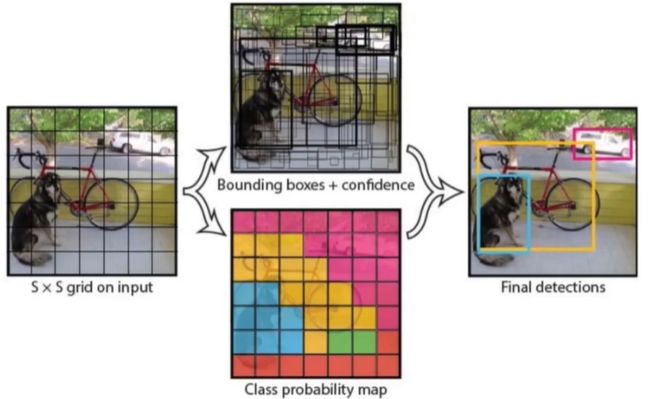
yolo算法在进行回归网络计算时,会对整张图片进行划分,划分为SxS,针对每个网格来分别预测当前网格为中心的目标区域的位置信息,还会给出置信度表示目标区域的可能性,输出目标所属类别的概率分布图(Class probability map)。
One-stage VS Two-stage
●One-stage ●Two-stage
➢优点 ➢优点
速度快 精度高(定位、检出率)
●避免背景错误,产生false positives ●Anchor机制
●学到物体的泛化特征 ●共享计算量
➢缺点 ➢缺点
精度低(定位、检出率) 速度慢
●小物体的检测效果不好 训练时间长,误报高
参考: RPN网络的anchor机制_wchange7的博客-CSDN博客_rpn网络的anchor生成细节