吴恩达老师机器学习课程笔记:(一)机器学习入门知识
机器学习入门知识
- 一.机器学习定义
- 二.机器学习分类
-
- 监督学习(supervised learning)
- 无监督学习(unsupervised learning)
- 其它类型的机器学习
- 三.模型相关描述及常用变量符号规定
-
- 训练集(Training set)、测试集(Test set)和验证集(Validation set)
- 假设函数(Hypothesis)
- 代价函数(Cost function)
- 常用变量符号规定
- 总结
一.机器学习定义
关于机器学习,Tom Mitchell给出的定义是:计算机程序从经验E中学习,解决某一任务T进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
在吴老师举的例子中:是通过机器学习来判断反垃圾邮件中哪个是任务T。在这里,分类邮件是垃圾邮件还是非垃圾邮件是T,观测邮件是垃圾邮件还是非垃圾邮件是经验E,正确归类邮件的比例就是性能度量P。
二.机器学习分类
在机器学习分类中,吴老师主要将机器学习分为三类,第一类就是监督学习,第二类就是无监督学习,第三类就是其它类型的机器学习。然后主要学习的重点就是监督学习和无监督学习。
监督学习(supervised learning)

监督学习,我们从已有的数据集(通常较大)中通过某种训练算法进行训练,然后得到一个模型h,并且注意在监督学习中我们的训练集通常是以每个数据和其对于对应的label组成一个完整的输入。也就是一个数据,我们通常都会打上它的相应的标签,这个标签即输出是我们自己获取到的。如上图所示,仅以房子的大小和价格作为数据,房子的大小是一个变量(只有一维),这个价格就是我们标记的label,从而我们得到的模型h是一个从房子大小(x)到房子预测价格(y)的之间的关系。
吴老师还讲了一个关于肿瘤的例子,首先是只从一个特征出发,也就是肿瘤大小,之后加入一个特征,患者的年龄,来综合判断肿瘤是良性的还是恶性的。之后还可以加入若干特征,甚至到无穷多个特征,来综合判断肿瘤是良性的。
监督学习又包括回归问题和分类问题,关于是回归问题还是分类问题,可以从它的输出形式来判断,输出结果是离散的,就是分类问题,输出结果是连续的,就是回归问题。如预测房价问题,它就是回归问题,如预测是否为恶性肿瘤,就是分类问题。
无监督学习(unsupervised learning)
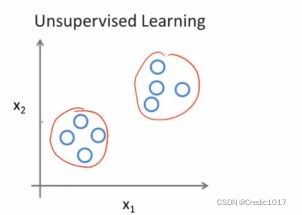
在无监督学习中,可能给我的只有一个数据集,但是无监督学习算法,可以根据学习算法将这些数据分为两个簇。在前面的监督学习算法中,可能上面的数据都有label,然后再进行其它的运算,但是这个它是没有标签的。
比如Google上的新闻,经常用到这种算法,比如将不同的但是同一主题的新闻归类为一个新闻集。
就是不知道事先的数据对应的结果,然后对其进行分类,这点和监督学习事先给定label并且有相应结果很不一样。
吴老师还给出了几个无监督学习的例子:数据中心的计算机集群,如果把相同的有协助能力的几台电脑放在一起会更加高效;Google上的社交网络,谁的社交圈子最有可能是一个群体,然后推荐给其他人;市场分隔,把不同市场的进行分簇分圈,这样在进行相应的市场推广可以更加精确,节省成本。
当然这里介绍的只是无监督学习其中的一种:聚类算法。
其它类型的机器学习
其它类型的机器学习主要包括强化学习(Reinforcement Learning)和推荐系统(Recommender systems)。
三.模型相关描述及常用变量符号规定
训练集(Training set)、测试集(Test set)和验证集(Validation set)
训练集相当于总体数据集的一部分,比较大的一部分拿来当训练集,用以训练模型的参数。除此以外还有测试集和验证集。对于数据量(万级别的)一般划分训练集和测试集为8:2或者7:3。更常规的还有训练集与测试集、验证集的比例为6:2:2。
测试集和验证集的区别在于:验证集用于进一步确定模型中的超参数(例如正则项系数、ANN中隐含层的节点个数等),而测试集只是用于评估模型的精确度。
假设函数(Hypothesis)
我理解的假设函数其实就是一个模型,我们由训练集通过某种训练得到的某种表达模型。例如以房子大小与价格的关系构建的模型,可能是个一元线性函数之间的关系,这个一元线性函数就是假设函数。
代价函数(Cost function)
我们想得到我们的假设函数,但是我们想要知道啥时候的假设函数是最优的,因为很多时候不止一个假设函数可以拟合我们的数据,我们可以通过代价函数来求得当前假设函数的“代价”,即代价越大这个模型越不拟合我们的数据,代价越小越加拟合我们的数据。
常用变量符号规定
以吴老师课程里的常用变量约定符号。
用m来表示样本量大小。用小写字母x来代表输入变量。y代表输出变量。
(x,y)代表一个训练样本, ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))代表的是样本集中的第i个样本。
并且常用 h θ ( x ) h_{θ}(x) hθ(x)来表示假设函数(hypothesis)。并且常常省略掉右下角的符号θ,以h(x)来表示假设函数。这里的θ其实也就是假设模型中的若干参数。
常用 θ 0 , θ 1 , θ 2 , . . . θ_0,θ_1,θ_2,... θ0,θ1,θ2,...来表示假设模型的参数变量。
常用 J ( θ 0 , θ 1 , . . . ) J(θ_0,θ_1,...) J(θ0,θ1,...)来表示代价函数。
总结
本次总结了关于机器学习的分类以及后面学习的重心(监督学习和无监督学习),并且对于一些机器学习的不同分支介绍了一些应用场景。对于模型里面出现的常用部分进行一个简单的介绍,对模型内部用到的变量进行了一个约定。