猿创征文|【深度学习前沿应用】文本生成
猿创征文|【深度学习前沿应用】文本生成

作者简介:在校大学生一枚,C/C++领域新星创作者,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 猿创征文|【深度学习前沿应用】文本生成
- 前言
-
-
- 什么是文本生成?
-
- 一、数据加载及预处理
-
- (一)、数据加载
- (二)、构建词表
- (三)、创建指定数据格式
- 二、模型配置
-
- (一)、定义网络超参数
- (二)、定义编码器
- (三)、定义解码器
- 三、模型训练
- 四、模型预测
- 总结
前言
什么是文本生成?
在自然语言处理领域,文本生成任务是指根据给定的输入,自动生成对应的输出,典型的任务包含:机器翻译、智能问答等。文本生成任务在注意力机制提出之后取得了显著的效果,尤其是在2018年基于多头注意力机制的Transformer(原理如下图1所示)在机器翻译领域取得当时最优效果时,基于Transformer的文本生成任务也进入了新的繁荣时期。
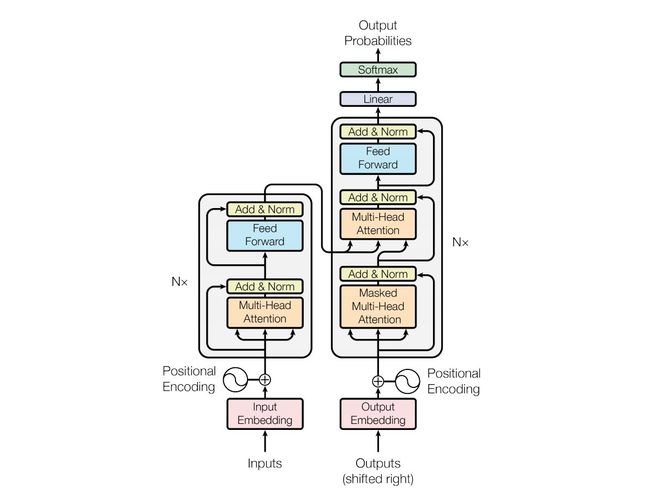
本实验的目的是演示如何使用经典的Transformer实现英-中机器翻译,实验平台为百度AI Studio,实验环境为Python3.7,Paddle2.0。
一、数据加载及预处理
(一)、数据加载
本实验选用开源的小型英-中翻译CMN数据集,该数据集中包含样本总数24360条,均为短文本,部分数据展示如下图2所示:

不同于图像处理,在处理自然语言时,需要指定文本的长度,便于进行批量计算,因此,在数据预处理阶段,应该先统计数据集中文本的长度,然后指定一个恰当的值,进行统一处理。
- 导入相关包
import paddle
import paddle.nn.functional as F
import re
import numpy as np
print(paddle.__version__)
# cpu/gpu环境选择,在 paddle.set_device() 输入对应运行设备。
# device = paddle.set_device('gpu')
- 统计数据集中句子的长度等信息
# 统计数据集中句子的长度等信息
lines = open('data/data78721/cmn.txt','r',encoding='utf-8').readlines()
print(len(lines))
datas = []
dic_en = {}
dic_cn = {}
for line in lines:
ll = line.strip().split('\t')
if len(ll)<2:
continue
datas.append([ll[0].lower().split(' ')[1:-1],list(ll[1])])
# print(ll[0])
if len(ll[0].split(' ')) not in dic_en:
dic_en[len(ll[0].split(' '))] = 1
else:
dic_en[len(ll[0].split(' '))] +=1
if len(ll[1]) not in dic_cn:
dic_cn[len(ll[1])] = 1
else:
dic_cn[len(ll[1])] +=1
keys_en = list(dic_en.keys())
keys_en.sort()
count = 0
# print('英文长度统计:')
for k in keys_en:
count += dic_en[k]
# print(k,dic_en[k],count/len(lines))
keys_cn = list(dic_cn.keys())
keys_cn.sort()
count = 0
# print('中文长度统计:')
for k in keys_cn:
count += dic_cn[k]
# print(k,dic_cn[k],count/len(lines))
en_length = 10
cn_length = 10
(二)、构建词表
对于中英文,需要分别构建词表,进行词向量学习,除此之外,还需要在每个词表中加入开始符号、结束符合以及填充符号:
# 构建中英文词表
en_vocab = {}
cn_vocab = {}
en_vocab['' ], en_vocab['' ], en_vocab['' ] = 0, 1, 2
cn_vocab['' ], cn_vocab['' ], cn_vocab['' ] = 0, 1, 2
en_idx, cn_idx = 3, 3
for en, cn in datas:
# print(en,cn)
for w in en:
if w not in en_vocab:
en_vocab[w] = en_idx
en_idx += 1
for w in cn:
if w not in cn_vocab:
cn_vocab[w] = cn_idx
cn_idx += 1
print(len(list(en_vocab)))
print(len(list(cn_vocab)))
'''
英文词表长度:6057
中文词表长度:3533
'''
(三)、创建指定数据格式
需要将输入英文与输出中文封装为指定格式,即为编码器端输入添加结束符号并填充至固定长度,为解码器输入添加开始、结束符号并填充至固定长度,解码器端输出的正确答案应该只添加结束符号并且填充至固定长度。
padded_en_sents = []
padded_cn_sents = []
padded_cn_label_sents = []
for en, cn in datas:
if len(en)>en_length:
en = en[:en_length]
if len(cn)>cn_length:
cn = cn[:cn_length]
padded_en_sent = en + ['' ] + ['' ] * (en_length - len(en))
padded_en_sent.reverse()
padded_cn_sent = ['' ] + cn + ['' ] + ['' ] * (cn_length - len(cn))
padded_cn_label_sent = cn + ['' ] + ['' ] * (cn_length - len(cn) + 1)
padded_en_sents.append(np.array([en_vocab[w] for w in padded_en_sent]))
padded_cn_sents.append(np.array([cn_vocab[w] for w in padded_cn_sent]) )
padded_cn_label_sents.append(np.array([cn_vocab[w] for w in padded_cn_label_sent]))
train_en_sents = np.array(padded_en_sents)
train_cn_sents = np.array(padded_cn_sents)
train_cn_label_sents = np.array(padded_cn_label_sents)
print(train_en_sents.shape)
print(train_cn_sents.shape)
print(train_cn_label_sents.shape)
二、模型配置
(一)、定义网络超参数
embedding_size = 128
hidden_size = 512
num_encoder_lstm_layers = 1
en_vocab_size = len(list(en_vocab))
cn_vocab_size = len(list(cn_vocab))
epochs = 20
batch_size = 16
(二)、定义编码器
# encoder: simply learn representation of source sentence
class Encoder(paddle.nn.Layer):
def __init__(self,en_vocab_size, embedding_size,num_layers=2,head_number=2,middle_units=512):
super(Encoder, self).__init__()
self.emb = paddle.nn.Embedding(en_vocab_size, embedding_size,)
"""
d_model (int) - 输入输出的维度。
nhead (int) - 多头注意力机制的Head数量。
dim_feedforward (int) - 前馈神经网络中隐藏层的大小。
"""
encoder_layer = paddle.nn.TransformerEncoderLayer(embedding_size, head_number, middle_units)
self.encoder = paddle.nn.TransformerEncoder(encoder_layer, num_layers)
def forward(self, x):
x = self.emb(x)
en_out = self.encoder(x)
return en_out
(三)、定义解码器
class Decoder(paddle.nn.Layer):
def __init__(self,cn_vocab_size, embedding_size,num_layers=2,head_number=2,middle_units=512):
super(Decoder, self).__init__()
self.emb = paddle.nn.Embedding(cn_vocab_size, embedding_size)
decoder_layer = paddle.nn.TransformerDecoderLayer(embedding_size, head_number, middle_units)
self.decoder = paddle.nn.TransformerDecoder(decoder_layer, num_layers)
# for computing output logits
self.outlinear =paddle.nn.Linear(embedding_size, cn_vocab_size)
def forward(self, x, encoder_outputs):
x = self.emb(x)
# dec_input, enc_output,self_attn_mask, cross_attn_mask
de_out = self.decoder(x, encoder_outputs)
output = self.outlinear(de_out)
output = paddle.squeeze(output)
return output
三、模型训练
encoder = Encoder(en_vocab_size, embedding_size)
decoder = Decoder(cn_vocab_size, embedding_size)
opt = paddle.optimizer.Adam(learning_rate=0.0001,
parameters=encoder.parameters() + decoder.parameters())
for epoch in range(epochs):
print("epoch:{}".format(epoch))
# shuffle training data
perm = np.random.permutation(len(train_en_sents))
train_en_sents_shuffled = train_en_sents[perm]
train_cn_sents_shuffled = train_cn_sents[perm]
train_cn_label_sents_shuffled = train_cn_label_sents[perm]
# print(train_en_sents_shuffled.shape[0],train_en_sents_shuffled.shape[1])
for iteration in range(train_en_sents_shuffled.shape[0] // batch_size):
x_data = train_en_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
sent = paddle.to_tensor(x_data)
en_repr = encoder(sent)
x_cn_data = train_cn_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
x_cn_label_data = train_cn_label_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
loss = paddle.zeros([1])
for i in range( cn_length + 2):
cn_word = paddle.to_tensor(x_cn_data[:,i:i+1])
cn_word_label = paddle.to_tensor(x_cn_label_data[:,i])
logits = decoder(cn_word, en_repr)
step_loss = F.cross_entropy(logits, cn_word_label)
loss += step_loss
loss = loss / (cn_length + 2)
if(iteration % 50 == 0):
print("iter {}, loss:{}".format(iteration, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()
输出结果如下图3所示:
四、模型预测
encoder.eval()
decoder.eval()
num_of_exampels_to_evaluate = 10
indices = np.random.choice(len(train_en_sents), num_of_exampels_to_evaluate, replace=False)
x_data = train_en_sents[indices]
sent = paddle.to_tensor(x_data)
en_repr = encoder(sent)
word = np.array(
[[cn_vocab['' ]]] * num_of_exampels_to_evaluate
)
word = paddle.to_tensor(word)
decoded_sent = []
for i in range(cn_length + 2):
logits = decoder(word, en_repr)
word = paddle.argmax(logits, axis=1)
decoded_sent.append(word.numpy())
word = paddle.unsqueeze(word, axis=-1)
results = np.stack(decoded_sent, axis=1)
for i in range(num_of_exampels_to_evaluate):
print('---------------------')
en_input = " ".join(datas[indices[i]][0])
ground_truth_translate = "".join(datas[indices[i]][1])
model_translate = ""
for k in results[i]:
w = list(cn_vocab)[k]
if w != '' and w != '' :
model_translate += w
print(en_input)
print("true: {}".format(ground_truth_translate))
print("pred: {}".format(model_translate))
输出结果如下图4所示:

总结
本系列文章内容为根据清华社出版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~
