gadecod matlab,【预测模型】基于遗传算法优化BP神经网络房价预测matlab源码
一、简介
1 遗传算法概述
遗传算法(Genetic Algorithm,GA)是进化计算的一部分,是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法简单、通用,鲁棒性强,适于并行处理。
2 遗传算法的特点和应用
遗传算法是一类可用于复杂系统优化的具有鲁棒性的搜索算法,与传统的优化算法相比,具有以下特点:
(1)以决策变量的编码作为运算对象。传统的优化算法往往直接利用决策变量的实际值本身来进行优化计算,但遗传算法是使用决策变量的某种形式的编码作为运算对象。这种对决策变量的编码处理方式,使得我们在优化计算中可借鉴生物学中染色体和基因等概念,可以模仿自然界中生物的遗传和进化激励,也可以很方便地应用遗传操作算子。
(2)直接以适应度作为搜索信息。传统的优化算法不仅需要利用目标函数值,而且搜索过程往往受目标函数的连续性约束,有可能还需要满足“目标函数的导数必须存在”的要求以确定搜索方向。遗传算法仅使用由目标函数值变换来的适应度函数值就可确定进一步的搜索范围,无需目标函数的导数值等其他辅助信息。直接利用目标函数值或个体适应度值也可以将搜索范围集中到适应度较高部分的搜索空间中,从而提高搜索效率。
(3)使用多个点的搜索信息,具有隐含并行性。传统的优化算法往往是从解空间的一个初始点开始最优解的迭代搜索过程。单个点所提供的搜索信息不多,所以搜索效率不高,还有可能陷入局部最优解而停滞;遗传算法从由很多个体组成的初始种群开始最优解的搜索过程,而不是从单个个体开始搜索。对初始群体进行的、选择、交叉、变异等运算,产生出新一代群体,其中包括了许多群体信息。这些信息可以避免搜索一些不必要的点,从而避免陷入局部最优,逐步逼近全局最优解。
(4) 使用概率搜索而非确定性规则。传统的优化算法往往使用确定性的搜索方法,一个搜索点到另一个搜索点的转移有确定的转移方向和转移关系,这种确定性可能使得搜索达不到最优店,限制了算法的应用范围。遗传算法是一种自适应搜索技术,其选择、交叉、变异等运算都是以一种概率方式进行的,增加了搜索过程的灵活性,而且能以较大概率收敛于最优解,具有较好的全局优化求解能力。但,交叉概率、变异概率等参数也会影响算法的搜索结果和搜索效率,所以如何选择遗传算法的参数在其应用中是一个比较重要的问题。
综上,由于遗传算法的整体搜索策略和优化搜索方式在计算时不依赖于梯度信息或其他辅助知识,只需要求解影响搜索方向的目标函数和相应的适应度函数,所以遗传算法提供了一种求解复杂系统问题的通用框架。它不依赖于问题的具体领域,对问题的种类有很强的鲁棒性,所以广泛应用于各种领域,包括:函数优化、组合优化生产调度问题、自动控制
、机器人学、图像处理(图像恢复、图像边缘特征提取…)、人工生命、遗传编程、机器学习。
3 遗传算法的基本流程及实现技术
基本遗传算法(Simple Genetic Algorithms,SGA)只使用选择算子、交叉算子和变异算子这三种遗传算子,进化过程简单,是其他遗传算法的基础。
3.1 遗传算法的基本流程
通过随机方式产生若干由确定长度(长度与待求解问题的精度有关)编码的初始群体;
通过适应度函数对每个个体进行评价,选择适应度值高的个体参与遗传操作,适应度低的个体被淘汰;
经遗传操作(复制、交叉、变异)的个体集合形成新一代种群,直到满足停止准则(进化代数GEN>=?);
将后代中变现最好的个体作为遗传算法的执行结果。
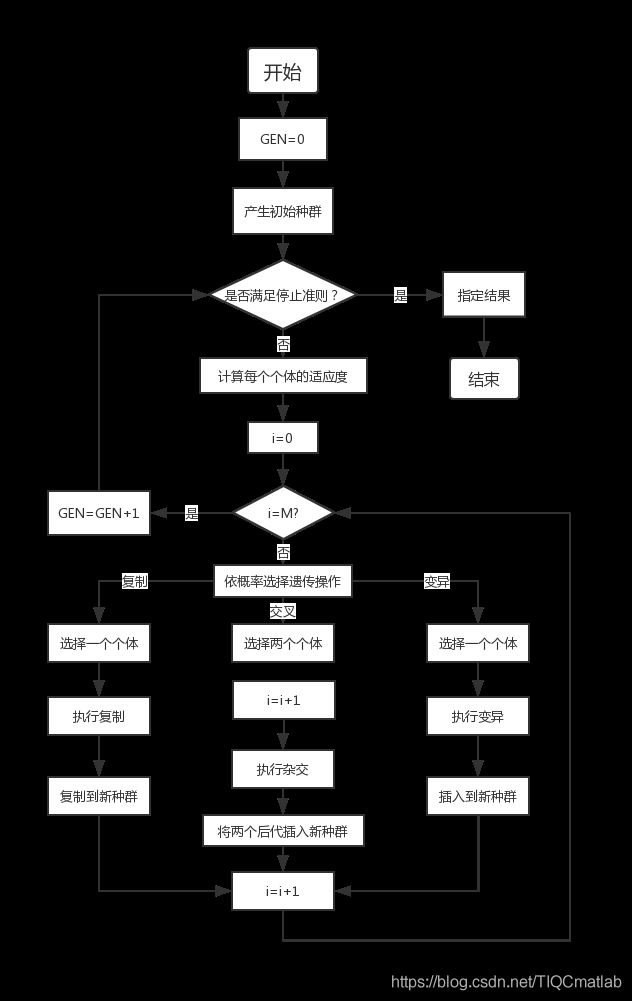
其中,GEN是当前代数;M是种群规模,i代表种群数量。
3.2 遗传算法的实现技术
基本遗传算法(SGA)由编码、适应度函数、遗传算子(选择、交叉、变异)及运行参数组成。
3.2.1 编码
(1)二进制编码
二进制编码的字符串长度与问题所求解的精度有关。需要保证所求解空间内的每一个个体都可以被编码。
优点:编、解码操作简单,遗传、交叉便于实现
缺点:长度大
(2)其他编码方法
格雷码、浮点数编码、符号编码、多参数编码等
3.2.2 适应度函数
适应度函数要有效反映每一个染色体与问题的最优解染色体之间的差距。
3.2.3选择算子

3.2.4 交叉算子
交叉运算是指对两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体;交叉运算是遗传算法区别于其他进化算法的重要特征,是产生新个体的主要方法。在交叉之前需要将群体中的个体进行配对,一般采取随机配对原则。
常用的交叉方式:
单点交叉
双点交叉(多点交叉,交叉点数越多,个体的结构被破坏的可能性越大,一般不采用多点交叉的方式)
均匀交叉
算术交叉
3.2.5 变异算子
遗传算法中的变异运算是指将个体染色体编码串中的某些基因座上的基因值用该基因座的其他等位基因来替换,从而形成一个新的个体。
就遗传算法运算过程中产生新个体的能力方面来说,交叉运算是产生新个体的主要方法,它决定了遗传算法的全局搜索能力;而变异运算只是产生新个体的辅助方法,但也是必不可少的一个运算步骤,它决定了遗传算法的局部搜索能力。交叉算子与变异算子的共同配合完成了其对搜索空间的全局搜索和局部搜索,从而使遗传算法能以良好的搜索性能完成最优化问题的寻优过程。
3.2.6 运行参数

4 遗传算法的基本原理
4.1 模式定理

4.2 积木块假设
具有低阶、定义长度短,且适应度值高于群体平均适应度值的模式称为基因块或积木块。
积木块假设:个体的基因块通过选择、交叉、变异等遗传算子的作用,能够相互拼接在一起,形成适应度更高的个体编码串。
积木块假设说明了用遗传算法求解各类问题的基本思想,即通过积木块直接相互拼接在一起能够产生更好的解。
clear all
clc
close all
tic
%% 全局变量
global pn
global tn
global R
global S2
global S1
global S
S1 = 12;
%% 数据处理
%% 数据处理
data1 =xlsread('数据.xls');%导入数据
%% 训练数据
input = data1(1:9,2:7);%训练输入
output = data1(1:9,8);%训练输出
input_test = data1(10:end,2:7);%测试输入
output_test= data1(10:end,end);%测试输出
output_test = output_test';
M =size(input,2); %输入节点个数
N =size(output,2);%输出节点个数
%% 训练数据
p = input';
t = output';
[pn,minp,maxp,tn,mint,maxt] =premnmx(p,t);%归一化
%% 建立神经网络
net = newff(minmax(pn),[S1,1],{'tansig','purelin'});
net.trainParam.show = 50;
net.trainParam.lr = 0.1;
net.trainParam.epochs = 1000;
net.trainParam.goal =1e-10;
[net,tr] = train(net,pn,tn);
%% 遗传操作
R = size(p,1);
S2= size(t,1);
S = R*S1+S1*S2+S1+S2;
aa = ones(S,1)*[-1 1];
popu = 50;
initPpp = initializega(popu,aa,'gabpEval');
gen = 500;
[x,endPop,bPop,trace] = ga(aa,'gabpEval',[],initPpp,[1e-6 1 1],'maxGenTerm',gen,...
'normGeomSelect',[0.09],['arithXover'],[2],'nonUnifMutation',[2 gen 3]);
%% 画图迭代图
figure(1)
plot(trace(:,1),1./trace(:,3),'r-');
hold on
grid on
plot(trace(:,1),1./trace(:,2),'b-');
xlabel('迭代数')
ylabel('均方误差')
title('均方误差曲线图')
figure(2)
plot(trace(:,1),trace(:,3),'r-');
hold on
grid on
plot(trace(:,1),trace(:,2),'b-');
xlabel('迭代数')
ylabel('适应度函数值')
title('适应度函数迭代曲线图')
[W1,B1,W2,B2,val] = gadecod(x);
W1;
W2;
B1;
B2;
net.IW{1,1} = W1;
net.LW{2,1} = W2;
net.b{1} = B1;
net.b{2} = B2;
net = train(net,pn,tn);
k = input_test';
kn = tramnmx(k,minp,maxp);
s_bp = sim(net,kn);
s_bp2 = postmnmx(s_bp,mint,maxt)
toc
warning off %清除警告
%% 数据处理
data1 =xlsread('数据.xls');%导入数据
%% 训练数据
data_p = data1(1:9,2:7);%训练输入
data_t = data1(1:9,8);%训练输出
data_k = data1(10:end,2:7);%测试输入
outtest = data1(10:end,end);%测试输出
[m1,n1] = size(data_p);%训练数据的大小
[m2,n2] = size(data_t);%测试数据的大小
p = data_p';%转置 适应BP工具箱
t = data_t';%转置 适应BP工具箱
[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t);%归一化
k = data_k';%测试输入装置
kn = tramnmx(k,minp,maxp);%测试输入归一化
%% BP模型
%建立网络及参数设置
S1 =10;%隐含层
net = newff(minmax(pn),[S1,1],{'tansig','purelin'});%建立网络
inputWeights = net.IW{1,1};%输入层到隐含层权值
inputbias = net.b{1};%输入层到隐含层阀值
layerWeights = net.IW{2,1};%隐含层到输出权值
layerbias = net.b{2};%隐含层到输出阀值
net.trainParam.show = 50;%迭代显示步数间隔 对结果无影响
net.trainParam.lr = 0.1;%学习率
net.trainParam.mc = 0.9;%动量因子
net.trainParam.epochs = 10000;%最大迭代次数
net.trainParam.goal =0.00001;%训练目标
%% 训练模型
[net,tr] = train(net,pn,tn);%训练网络
nihe = sim(net,pn);%训练输出
nihe2 = postmnmx(nihe,mint,maxt);%训练输出反归一化
figure%画图
xk = 2;%线宽
plot(2006:2014,nihe2,'r-o',2006:2014,data_t,'b.-','linewidth',xk)%训练输出与拟合值的对比图
grid on%网格
legend('真实值','预测值')%图例
title('神经网预测真实值与预测值对比')%标题
xlabel('年份')%横坐标标题
ylabel('商品房平均房价')%纵坐标标题
%% 预测
s_bp = sim(net,kn);%预测
s_bp2 = postmnmx(s_bp,mint,maxt);%预测输出反归一化
s_bp2 = s_bp2';%转置
figure%画图
plot(2015:2017,outtest,'r-',2015:2017,s_bp2,'b.-','linewidth',xk)%测试输出与真实值的对比图
grid on%加网格
legend('真实值','预测值')%图例
title('神经网预测真实值与预测值对比')%标题
xlabel('年份')%横坐标标题
ylabel('商品房平均房价')%纵坐标标题
%% 误差分析
三、运行结果
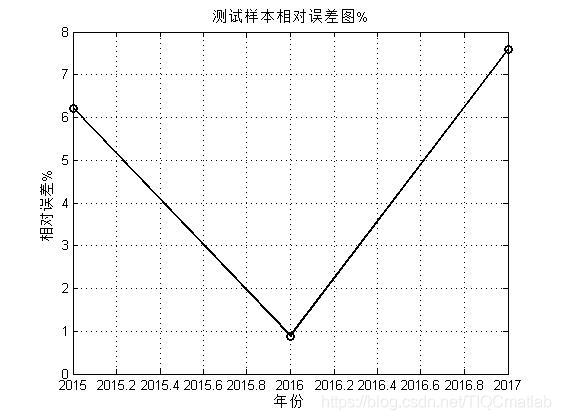
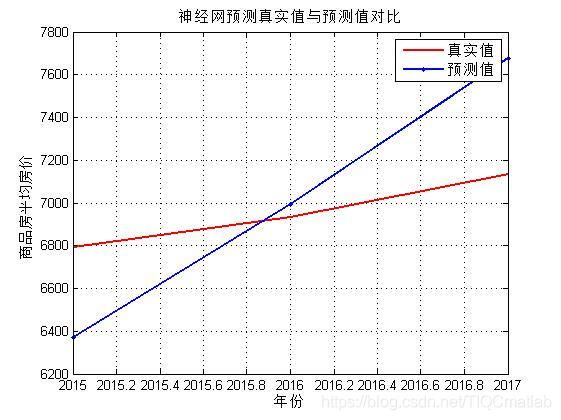
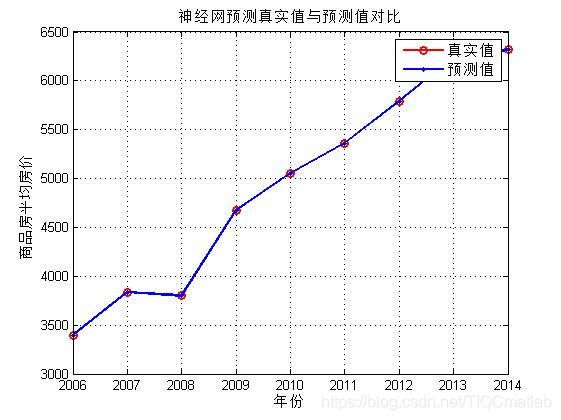
完整代码或者代写添加QQ1575304183
往期回顾>>>>>>
【SVM预测】灰狼算法优化svm支持向量机预测matlab源码
【SVM预测】基于蝙蝠算法改进的SVM预测matlab源码
【ELM预测】粒子群优化ELM网络预测matlab源码
【lssvm预测】基于鲸鱼优化算法的lssvm数据预测matlab源码
【lssvm预测模型】基于蝙蝠算法改进的最小二乘支持向量机lssvm预测
【lssvm预测】基于飞蛾扑火算法改进的最小二乘支持向量机lssvm预测
【lstm预测】基于鲸鱼优化算法改进的lstm预测matlab源码
【BP预测模型】BP神经网络的预测matlab源码
【BP预测】基于麻雀优化的BP神经网络matlab源码
【ANN预测模型】基于差分算法改进ANN网络预测matlab源码
【SVM预测】基于SVM进行股票预测matlab源码
【BP预测】基于麻雀算法优化BP预测matlab源码
【预测模型】基于RLS算法进行预测matlab源码
【SVM预测】基于SVM和LSR交通流预测matlab源码
【预测模型】基于SVM电力系统短期负荷预测matlab源码
【预测模型】基于 Elm神经网络的电力负荷预测模型matlab源码
【BP预测模型】基于 BP神经网络的电力负荷预测模型matlab源码
【CNN预测】基于CNN神经网络预测matlab源码
【BP预测】基于粒子群优化BP神经网络预测matlab源码
【预测模型】基于 bp神经网络风电功率预测matlab源码
【预测模型】基于小波神经网络的短时交通流量预测matlab源码
【lsp预测】基于强化学习预测matlab源码
【lsp预测】基于粒子群优化强化学习预测matlab源码
【预测模型】基于卡尔曼滤波实现运动轨迹预测matlab源码