面试大厂真题:怎么实现JVM性能调优?
对于工作3年左右的Java程序员来说,在面试大厂的过程中,面试官可能不会太关注你做了多少个项目、你的CRUD水平如何。更多的是关注你对某项技术点的理解深度,所以说,工作3年左右的小伙伴一定要把自己的重心放到技术的深度上来。
今天,我们先一起聊聊关于JVM性能调优的话题,本文的主要结构如下所示。

常见面试题
关于JVM,一道常见的面试题就是:Java中创建的对象是存储在JVM中的哪个区域的?
例如,这里,我们简单的列举一行代码,如下所示。
User user = new User();
关于上面的代码,不少小伙伴都知道,创建出来的User对象是放在JVM中的堆区域的,而User对象的引用是放在栈中的。但如果你只是了解到这种程度,那面试官就会认为你了解的太浅显了,可能就会达不到他们的要求。其实面试官想要了解你是否对JVM有一个更深入的认识。
站在面试官的角度来看这个问题时,回答创建出来的User对象是放在JVM的堆区,也并没有错。但是JVM的堆内存区域又会分为年轻代和老年代,而年轻代又会分为Eden区和Survivor区。JVM堆空间的逻辑结构如下图所示。
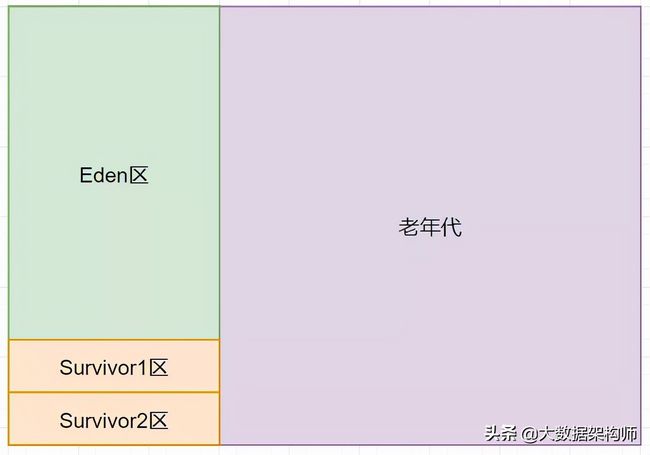
而面试官更想了解的是你能不能说出来创建的对象具体是存放在JVM堆空间的哪个区域。
在JVM内部,会将整个堆空间划分成年轻代和老年代,年轻代默认会占整个堆内存空间的1/3,老年代默认会占整个堆内存空间的2/3。年轻代又会划分为Eden区和两个Survivor区,它们之间的默认比例是Eden:Survivor1:Survivor2 = 8:1:1。

如果你能回答出 新创建的User对象是存放在JVM堆空间中年轻代的Eden区,那面试官就会对你刮目相看了。当然,这里没有考虑JVM的逃逸分析情况,关于JVM的逃逸分析,大家可以参考《逃逸分析》一文。
JVM体系结构
JVM主要由三个子系统构成,分别为:类加载器子系统、运行时数据区(内存结构)和字节码执行引擎。

关于JVM的体系结构全貌,我们先来看一张图。

当我们开发Java程序时,首先会编写.java文件,之后,会将.java文件编译成.class文件。
JVM中,会通过类装载子系统将.class文件的内容装载到JVM的运行时数据区,而JVM的运行时数据区又会分为:方法区、堆、栈、本地方法栈和程序计数器 几个部分。
在装载class文件的内容时,会将class文件的内容拆分为几个部分,分别装载到JVM运行时数据区的几个部分。其中,值得注意的是:程序计数器的作用是:记录程序执行的下一条指令的地址。
方法区也叫作元空间,主要包含了:运行时常量池、类型信息、字段信息、方法信息、类加载器的引用、对应的Class实例的引用等信息。
在JVM中,程序的执行是通过执行引擎进行的,执行引擎会调用本地方法的接口来执行本地方法库,进而完成整个程序逻辑的执行。
我们常说的垃圾收集器是包含在执行引擎中的,在程序的运行过程中,执行引擎会开启垃圾收集器,并在后台运行,垃圾收集器会不断监控程序运行过程中产生的内存垃圾信息,并根据相应的策略对垃圾信息进行清理。
这里,大家需要注意的是:栈、本地方法栈和程序计数器是每个线程运行时独占的,而方法区和堆是所有线程共享的。所以,栈、本地方法栈和程序计数器不会涉及线程安全问题,而方法区和堆会涉及线程安全问题。
方法区(元空间)
很多小伙伴一看到方法区三个字,脑海中的第一印象可能是存储方法的地方吧。
实则不然,方法区的另一个名字叫作元空间,相信不少小伙伴或多或少的听说过元空间。这个区域是JDK1.8中划分出来的。主要包含:运行时常量池、类型信息、字段信息、方法信息、类加载器的引用、对应的Class实例的引用等信息。方法区中的信息能够被多个线程共享。
例如,在程序中声明的常量、静态变量和有关于类的信息等的引用,都会存放在方法区,而这些引用所指向的具体对象 一般都会在堆中开辟单独的空间进行存储,也可能会在直接内存中进行存储。

堆
堆中主要存储的是实际创建的对象,也就是会存储通过new关键字创建的对象,堆中的对象能够被多个线程共享。堆中的数据不需要事先明确生存期,可以动态的分配内存,不再使用的数据和对象由JVM中的GC机制自动回收。对JVM的性能调优一般就是对堆内存的调优。
Java中基本类型的包装类:Byte、Short、Integer、Long、Float、Double、Boolean、Character类型的数据是存储在堆中的。
堆一般会被分成年轻代和老年代。而年轻代又会被进一步分为1个Eden区和2个Survivor区。在内存分配上,如果保持默认配置的话,年轻代和老年代的内存大小比例为1 : 2,年轻代中的1个Eden区和2个Survivor区的内存大小比例为:8 : 1 : 1。

栈
栈一般又叫作线程栈或虚拟机栈,一般存储的是局部变量。在Java中,每个线程都会有一个单独的栈区,每个栈中的元素都是私有的,不会被其他的栈所访问。栈中的数据大小和生存期都是确定的,存取速度比较快。
在Java中,所有的基本数据类型(byte、short、int、long、float、double、boolean、char)和引用变量(对象引用)都是在栈中的。一般情况下,线程退出或者方法退出时,栈中的数据会被自动清除。
程序在执行过程中,会在栈中为不同的方法创建不同的栈帧,在栈帧中又包含了:局部变量表、操作数栈、动态链接和方法出口。

关于局部变量表、操作数栈、动态链接和方法出口的具体作用,会在《架构师进阶系列》中的后续文章中详细阐述。
栈中一般会存储对象的引用,这些引用所指向的具体对象一般都会在堆中开辟单独的地址空间进行存储,也有可能存储在直接内存中。

注意:这里说的是这些引用所指向的具体对象一般都会在堆中开辟单独的地址空间进行存储,也有可能存储在直接内存中。
因为在JVM中,如果开启了逃逸分析和标量替换,则可能不会再在堆上创建对象,可能会将对象直接分配到栈上,也可能不再创建对象,而是进一步分解对象中的成员变量,将其直接在栈上分配空间并赋值。
本地方法栈
本地方法栈相对来说比较简单,就是保存native方法进入区域的地址。
例如,在Java中创建线程,调用Thread对象的start()方法时,会通过本地方法start0()调用操作系统创建线程的方法。此时,本地方法栈就会保存start0()方法进入区域的内存地址。
程序计数器
程序计数器也叫作PC计数器,只要存储的是下一条将要执行的命令的地址。
双亲委派机制
何为双亲委派?
JVM中是通过类的双亲委派机制来加载的,那什么是双亲委派机制呢?我们先来看一张图。

当JVM加载某个类的时候,不会直接使用当前类的加载器加载该类,会先委托父加载器寻找要加载的目标类,找不到再委托上层的父加载器进行加载,直到引导类加载器同样找不到要加载的目标类,就会在自己的类加载路径中查找并加载目标类。
简单来说:双亲委派机制就是:先使用父加载器加载,如果父加载器找不到要加载的目标类,就使用子加载器自己加载。
为何使用双亲委派机制?
这里,小伙伴们有没有想过这样一个问题:JVM为何要使用双亲委派机制呢?
为了更好的说明问题,我们自己创建一个java.lang包,并在java.lang包下,创建一个String类,如下所示。
package java.lang;
/**
* @author binghe
* @version 1.0.0
* @description 测试时双亲委派机制
*/
public class String {
public static void main(String[] args){
System.out.println("自定义的String类");
}
}
这里,我们自己创建一个java.lang.String类,而JDK中也存在一个java.lang.String类,如果运行我们自己创建的java.lang.String会发生什么呢?会输出如下错误信息。
错误: 在类 java.lang.String 中找不到 main 方法, 请将 main 方法定义为:
public static void main(String[] args)
否则 JavaFX 应用程序类必须扩展javafx.application.Application
那JVM为何要使用双亲委派机制呢?试想,如果我们自己写的类能够随随便便覆盖JDK中的类的话,那JDK中的代码是不是就没有任何安全性可言了?没错,JVM为了代码的安全性,也即是沙箱安全机制,使用了双亲委派机制。
另外,使用双亲委派机制,也能防止JVM内存中出现多份相同的字节码。例如,两个类A和B,都需要加载System类。如果JVM没有提供双亲委派机制,那么A和B两个类就会分别加载一份System的字节码,这样JVM内存中就会出现这份System字节码。
相反,JVM提供了双亲委派机制的话,在加载System类的过程中,会递归的向父加载器查找并加载,整个过程会优先选用BootStrapClassLoader加载器,也就是我们通常说的引导类加载器。如果找不到就逐级向下使用子加载器进行加载。
而System类可以在BootStrapClassLoader中进行加载,如果System类已经通过A类的引用加载过,此时B类也要加载System类,也会从BootStrapClassLoader开始加载System类,此时,BootStrapClassLoader发现已经加载过System类了,就会直接返回内存中的System,不再重新加载。
这样,在JVM内存中,就只会存在一份System类的字节码。
类加载器的父子关系
如何确认类加载器的父子关系呢?这里,我们再来看一个示例代码,如下所示。
/**
* @author binghe
* @version 1.0.0
* @description 类的双亲委派机制
*/
public class User {
public static void main(String[] args){
User user = new User();
System.out.println(user.getClass().getClassLoader());
System.out.println(user.getClass().getClassLoader().getParent());
System.out.println(user.getClass().getClassLoader().getParent().getParent());
}
}
这段代码也比较简单,创建了一个User对象,打印User对象的类加载器,父类加载和上层父加载器。在IDEA中运行上述代码,会输出如下信息。
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$ExtClassLoader@135fbaa4
null
可以看到,User对象的类加载器是AppClassLoader,父加载器是ExtClassLoader。而输出的null其实是BootStrapClassLoader,而BootStrapClassLoader也就是上层父加载器。
这样,类加载器的父子关系就出来了:AppClassLoader的父加载器是ExtClassLoader,ExtClassLoader的父加载器是BootStrapClassLoader。
这里,需要注意的是:父加载器并不是父类。
类加载器加载的类
- 引导类加载器(BootStrapClassLoader):负责加载%JAVA_HOME%/jre/lib目录下的所有jar包,或者是-Xbootclasspath参数指定的路径;
- 扩展类加载器(ExtClassLoader):负责加载%JAVA_HOME%/jre/lib/ext目录下的所有jar包,或者是java.ext.dirs参数指定的路径;
- 应用类加载器(AppClassLoader):负责加载用户类路径上所指定的类库。
注意:引导类加载器和扩展类加载器加载的类都是预先加载好的,而应用类加载器用来加载应用工程的classes以及lib下的类库,仅仅声明,并不会提前载入JVM内存,等到使用的时候才会加载到JVM内存中。
类的加载过程
一个类在JVM中的加载过程大致经历了加载、验证、准备、解析和初始化。
- 加载: 主要是在计算机磁盘上通过IO流读取字节码文件(.class文件),当程序需要使用某个类时,才会对这个类进行加载操作,比如,在程序中调用某个类的静态方法,使用new关键字创建某个类的对象等。在加载阶段,往往会在JVM的堆内存中生成一个代表这个类的Class对象,这个对象作为存放在JVM方法区中这个类的各种数据的访问入口,也可以叫做访问句柄。
- 验证:主要的作用就是校验字节码的正确性,是否符合JVM规范。
- 准备:为类的静态变量分配相应的内存,并赋予默认值。
- 解析:将程序中的符号引用替换为直接引用,这里的符号引用包括:静态方法等。此阶段就是将一些静态方法等符号引用替换成指向数据所在内存地址的指针,这些指针就是直接引用。如果是在类加载过程中完成的符号引用到直接引用的替换,这个替换的过程就叫作静态链接过程。如果是在运行期间完成的符号引用到直接引用的替换,这个替换的过程就叫作动态链接过程。
- 初始化:对类的静态变量进行初始化,为其赋予程序中指定的值,并执行静态代码块中的代码。
注意:在准备阶段和初始化阶段都会为类的静态变量赋值,不同之处就是在准备阶段为类的静态变量赋予的是默认值,而在初始化阶段为类的静态变量赋予的是真正要赋予的值。
例如,在程序中有如下静态变量。
public static int count = 100;
在准备阶段会为count赋予一个默认值0,而在初始化阶段才会真正将count赋值为100。
JVM调优参数
在JVM中,主要是对堆(新生代)、方法区和栈进行性能调优。各个区域的调优参数如下所示。
- 堆:-Xms、-Xmx
- 新生代:-Xmn
- 方法区(元空间):-XX:MetaspaceSize、-XX:MaxMetaspaceSize
- 栈(线程):-Xss
为了更加直观的表述,我们可以将JVM的内存区域和对应的调优参数总结成下图所示。
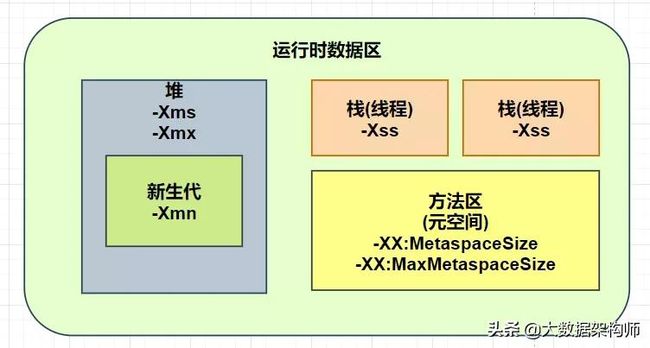
在设置JVM启动参数时,需要特别注意方法区(元空间)的参数设置。
关于方法区(元空间)的JVM参数主要有两个:-XX:MetaspaceSize和-XX:MaxMetaspaceSize。
-XX:MetaspaceSize: 指的是方法区(元空间)触发Full GC的初始内存大小(方法区没有固定的初始内存大小),以字节为单位,默认为21M。达到设置的值时,会触发Full GC,同时垃圾收集器会对这个值进行修改。
如果在发生Full GC时,回收了大量内存空间,则垃圾收集器会适当降低此值的大小;如果在发生Full GC时,释放的空间比较少,则在不超过设置的-XX:MetaspaceSize值或者在没设置-XX:MetaspaceSize的值时不超过21M,适当提高此值。
-XX:MaxMetaspaceSize: 指的是方法区(元空间)的最大值,默认值为-1,不受堆内存大小限制,此时,只会受限于本地内存大小。
最后需要注意的是: 调整方法区(元空间)的大小会发生Full GC,这种操作的代价是非常昂贵的。如果发现应用在启动的时候发生了Full GC,则很有可能是方法区(元空间)的大小被动态调整了。
所以,为了尽量不让JVM动态调整方法区(元空间)的大小造成频繁的Full GC,一般将-XX:MetaspaceSize和-XX:MaxMetaspaceSize设置成一样的值。例如,物理内存8G,可以将这两个值设置为256M
最后,我们一起看下在物理内存8G的情况下,启动应用程序时,可以设置的JVM参数。当然,我这里给出的是一些经验值,实际部署到生产环境时,需要经过压测找到最佳的参数值。
- 启动SpringBoot
java ‐Xms2048M ‐Xmx2048M ‐Xmn1024M ‐Xss512K ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐jar xxx.jar
- 启动Tomcat(Linux)
在Tomcat bin目录下catalina.sh文件里配置。
‐Xms2048M ‐Xmx2048M ‐Xmn1024M ‐Xss512K ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M
- 启动Tomcat(Windows)
在Tomcat bin目录下catalina.bat文件里配置。
‐Xms2048M ‐Xmx2048M ‐Xmn1024M ‐Xss512K ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M
总结
本文以面试为背景,探讨了有关JVM的常见面试问题。文章开头以一个常见的面试题举例,说明了JVM在互联网大厂面试中的重要性。接下里,介绍了JVM的体系结构,包含:方法区(元空间)、堆、栈、本地方法栈和程序计数器。
随后,介绍了JVM中的双亲委派机制,说明了何为双亲委派,为何使用双亲委派机制,类加载器的父子关系。需要注意的是:这里说的类加载器的父子关系并不是父类和子类的关系。随后,介绍了各个类加载器要加载哪些类。
接下来,介绍了类的加载过程,主要包含:加载、验证、准备、解析和初始化等步骤,同时,说明了各个步骤的主要作用。
最后,介绍了JVM中常用的调优参数,涵盖堆、新生代、方法区(元空间)和栈(线程)常用的调优参数。并以Tomcat调优为例,详细说明了如何使用这些调优参数。
说了这么多你都掌握了吗?