【datawhale202203】深入浅出PyTorch:PyTorch进阶训练
前情回顾
- PyTorch的模型定义及模型搭建
小结
本节学习了一些进阶训练方法在PyTorch中的实现,包含自定义损失函数,动态调整学习率,以及模型微调的实现,半精度训练的实现.
其中,损失函数常以类的方式进行自定义;
可以调用官方Scheduler或是自定义的方式实现动态学习率;
模型微调则需先读取含参数的预训练模型,然后锁定参数,随后更改输出层,来实现微调训练;
半精度训练主要通过autocast配置.
目录
-
- 前情回顾
- 小结
- 1 自定义损失函数
-
- 1.1 以函数方式定义
- 1.2 以类的方式定义
- 2 动态调整学习率
-
- 2.1 使用官方scheduler
-
- 2.1.1 官方提供的API
- 2.1.2 使用官方API
- 2.2 自定义Scheduler
- 3 模型微调
-
- 3.1 模型微调的流程
- 3.2 使用已有模型结构
- 3.3 训练特定层
- 4 半精度训练
1 自定义损失函数
PyTorch在
torch.nn模块为我们提供了许多常用的损失函数,比如:MSELoss,L1Loss,BCELoss… 但是随着深度学习的发展,出现了越来越多的非官方提供的Loss,比如DiceLoss,HuberLoss,SobolevLoss.… 这些Loss Function专门针对一些非通用的模型,PyTorch不能将他们全部添加到库中去,因此这些损失函数的实现则需要我们通过自定义损失函数来实现。
另外,在科学研究中,我们往往会提出全新的损失函数来提升模型的表现,这时我们既无法使用PyTorch自带的损失函数,也没有相关的博客供参考,此时自己实现损失函数就显得更为重要了。
自定义损失函数有两种方式
- 以函数方式定义
- 以类方式定义
1.1 以函数方式定义
可以通过直接以函数定义的方式定义一个自己的函数。
教程中给出了一个平方和的平均函数的定义方式。
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss
也可以定义一个CV(RMSE),公式如下
C V ( R M S E ) = 1 N ∑ i = 1 n ( y i − y ^ i ) 2 1 N ∑ i = 1 n y i = N ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n y i \begin{aligned} CV(RMSE) &= \frac{\sqrt{\frac{1}{N} \sum^{n}_{i=1}{(y_i -\hat y_i )^2}}}{\frac{1}{N} \sum^{n}_{i=1}y_i} \\ &= \frac{\sqrt{N \sum^{n}_{i=1}{(y_i -\hat y_i )^2}}}{\sum^{n}_{i=1}y_i} \end{aligned} CV(RMSE)=N1∑i=1nyiN1∑i=1n(yi−y^i)2=∑i=1nyiN∑i=1n(yi−y^i)2
则对应的函数定义方式如下
def cv_rmse(output, target):
loss = torch.sqrt(1/output.shape[0] * torch.sum(output - target)**2)/torch.mean(target)
return loss
1.2 以类的方式定义
这一种定义更加常用(为什么)
在以类方式定义损失函数时,我们如果看每一个损失函数的继承关系我们就可以发现
Loss函数部分继承自_loss, 部分继承自_WeightedLoss, 而_WeightedLoss继承自_loss,_loss继承自 nn.Module。
可以将损失函数当作神经网络的一层来对待
自定义损失函数需要继承自nn.Module类.
以DiceLoss为例。Dice Loss是一种在分割领域常见的损失函数,定义如下:
D S C = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DSC = \frac{2|X∩Y|}{|X|+|Y|} DSC=∣X∣+∣Y∣2∣X∩Y∣
实现代码如下:
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
在forward中实现了对loss函数的定义
可以进行实例化后使用
criterion = DiceLoss()
loss = criterion(input,targets)
在自定义损失函数时,涉及到数学运算时,我们最好全程使用PyTorch提供的张量计算接口,这样就不需要我们实现自动求导功能并且我们可以直接调用cuda,使用numpy或者scipy的数学运算时,操作会有些麻烦。
为什么使用类定义损失函数
参考链接

作为类定义可以容易地被分配到cuda上.
2 动态调整学习率
当我们选定了一个合适的学习率,经过许多轮的训练后,可能会出现准确率震荡或loss不再下降等情况,说明当前学习率已不能满足模型调优的需求。
此时我们就可以通过一个适当的学习率衰减策略来改善这种现象,提高我们的精度,这种设置方式在PyTorch中被称为scheduler
2.1 使用官方scheduler
2.1.1 官方提供的API
在训练神经网络的过程中,学习率是最重要的超参数之一,作为当前较为流行的深度学习框架,PyTorch已经在
torch.optim.lr_scheduler为我们封装好了一些动态调整学习率的方法供我们使用,如下面列出的这些scheduler。
lr_scheduler.LambdaLRlr_scheduler.MultiplicativeLRlr_scheduler.StepLRlr_scheduler.MultiStepLRlr_scheduler.ExponentialLRlr_scheduler.CosineAnnealingLRlr_scheduler.ReduceLROnPlateaulr_scheduler.CyclicLRlr_scheduler.OneCycleLRlr_scheduler.CosineAnnealingWarmRestarts
2.1.2 使用官方API
PyTorch官方很人性化的给出了使用实例代码。
# 选择一种优化器
optimizer = torch.optim.Adam(...)
# 选择上面提到的一种或多种动态调整学习率的方法
scheduler1 = torch.optim.lr_scheduler....
scheduler2 = torch.optim.lr_scheduler....
...
schedulern = torch.optim.lr_scheduler....
# 进行训练
for epoch in range(100):
train(...)
validate(...)
optimizer.step()
# 需要在优化器参数更新之后再动态调整学习率
scheduler1.step()
...
schedulern.step()
主要流程是,选择一种优化器后确定动态调整学习率的方法
之后在每次步进优化器之后步进调整方法
我们在使用官方给出的
torch.optim.lr_scheduler时,需要将scheduler.step()放在optimizer.step()后面进行使用。
2.2 自定义Scheduler
虽然PyTorch官方给我们提供了许多的API,但是在实验中也有可能碰到需要我们自己定义学习率调整策略的情况
以自定义函数adjust_learning_rate来改变param_group中lr的值为例
假设我们现在正在做实验,需要学习率每30轮下降为原来的1/10,假设已有的官方API中没有符合我们需求的,那就需要自定义函数来实现学习率的改变。
自定义的方式其实就是,写一个函数
def adjust_learning_rate(optimizer, epoch):
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
有了adjust_learning_rate函数的定义,在训练的过程就可以调用我们的函数来实现学习率的动态变化
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9)
for epoch in range(10):
train(...)
validate(...)
adjust_learning_rate(optimizer,epoch)
问题来了,这里为什么不需要步进optimizer
3 模型微调
迁移学习的一大应用场景是模型微调(finetune)
简单来说,就是我们先找到一个同类的别人训练好的模型,把别人现成的训练好了的模型拿过来,换成自己的数据,通过训练调整一下参数。 在PyTorch中提供了许多预训练好的网络模型(VGG,ResNet系列,mobilenet系列…),这些模型都是PyTorch官方在相应的大型数据集训练好的。学习如何进行模型微调,可以方便我们快速使用预训练模型完成自己的任务。
3.1 模型微调的流程

- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
简单来说,就是使用一个已有的预训练模型的结构和训练好的参数,然后在新的数据集上训练新的模型,训练过程对原有模型的特征提取层仅进行参数修改,输出层从头开始训练.
此处与后面是矛盾的,似乎应该是特征提取层参数锁定,而输出层训练,为何此处特征提取为微调
3.2 使用已有模型结构
下面以torchvision中的resnet18为例,展示如何在图像分类任务中使用PyTorch提供的常见模型结构和参数。
- 实例化网络
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于与上面的表达式
- 传递
pretrained参数
通过True或者False来决定是否使用预训练好的权重,在默认状态下pretrained = False,意味着我们不使用预训练得到的权重,当pretrained = True,意味着我们将使用在一些数据集上预训练得到的权重。
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
一些关于加载预训练模型的tips:
注意事项:
- 通常PyTorch模型的扩展为
.pt或.pth,程序运行时会首先检查默认路径中是否有已经下载的模型权重,一旦权重被下载,下次加载就不需要下载了。- 一般情况下预训练模型的下载会比较慢,我们可以直接通过迅雷或者其他方式去 这里 查看自己的模型里面
model_urls,然后手动下载,预训练模型的权重在Linux和Mac的默认下载路径是用户根目录下的.cache文件夹。在Windows下就是C:\Users\。我们可以通过使用\.cache\torch\hub\checkpoint torch.utils.model_zoo.load_url()设置权重的下载地址。- 如果觉得麻烦,还可以将自己的权重下载下来放到同文件夹下,然后再将参数加载网络。
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
- 如果中途强行停止下载的话,一定要去对应路径下将权重文件删除干净,要不然可能会报错。
3.3 训练特定层
在默认情况下,参数的属性.requires_grad = True,如果我们从头开始训练或微调不需要注意这里。
但如果我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。(也就是微调)
那就需要通过设置requires_grad = False来冻结部分层。在PyTorch官方中提供了这样一个例程。
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
使用resnet18为例的将1000类改为4类,但是仅改变最后一层的模型参数,不改变特征提取的模型参数;
先冻结模型参数的梯度,再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的。
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型
num_ftrs = model.fc.in_features
model.fc = nn.Linear(in_features=512, out_features=4, bias=True)
上面的代码先实现了参数锁定,再替换了输出层,从而实现了特征提取层的锁定和输出层的全新随机初始化.
之后在训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层。
参考阅读里头给到了一个比较有意思的博客内容: 给不同层分配不同的学习率,提到了可以通过optimizer中 param_groups来分配.
4 半精度训练
提到PyTorch时候,总会想到要用硬件设备GPU的支持,也就是“卡”。GPU的性能主要分为两部分:算力和显存,前者决定了显卡计算的速度,后者则决定了显卡可以同时放入多少数据用于计算。在可以使用的显存数量一定的情况下,每次训练能够加载的数据更多(也就是batch size更大),则也可以提高训练效率。另外,有时候数据本身也比较大(比如3D图像、视频等),显存较小的情况下可能甚至batch size为1的情况都无法实现。因此,合理使用显存也就显得十分重要。
半精度
PyTorch默认的浮点数存储方式用的是torch.float32,小数点后位数更多固然能保证数据的精确性,但绝大多数场景其实并不需要这么精确,只保留一半的信息也不会影响结果,也就是使用torch.float16格式。由于数位减了一半,因此被称为“半精度”
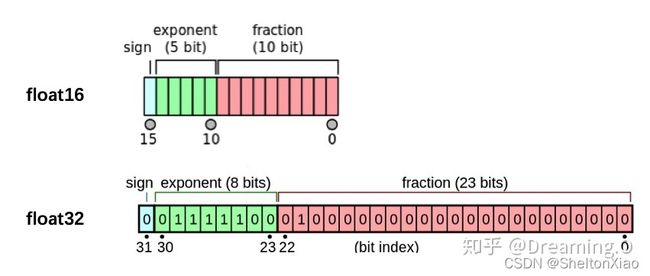
在PyTorch中使用autocast配置半精度训练,同时需要在下面三处加以设置:
- import autocast
from torch.cuda.amp import autocast
- 模型设置
在模型定义中,使用python的装饰器方法,用autocast装饰模型中的forward函数。关于装饰器的使用,可以参考这里:
@autocast()
def forward(self, x):
...
return x
- 训练过程
在训练过程中,只需在将数据输入模型及其之后的部分放入“with autocast():“即可:
for x in train_loader:
x = x.cuda()
with autocast():
output = model(x)
...
注意:
半精度训练主要适用于数据本身的size比较大(比如说3D图像、视频等)。当数据本身的size并不大时(比如手写数字MNIST数据集的图片尺寸只有28*28),使用半精度训练则可能不会带来显著的提升。