yolov7基础知识先导篇
*免责声明:
1\此方法仅提供参考
2\搬了其他博主的操作方法,以贴上路径.
3*
场景一:MP
场景二:高效聚合网络
场景三:SPPCSPC
场景四:结构重参数化
场景五:标签分配–>细分方法:simOTA
场景六:模型复合缩放
…
场景一:MPC-B、MPC-N
1.1 MPC-B

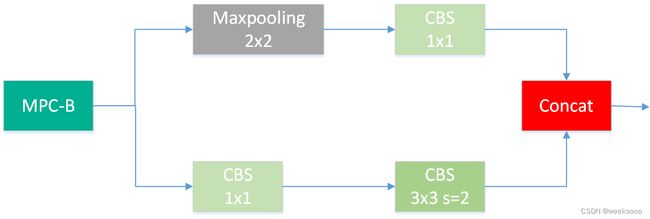
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]],
class MP(nn.Module):
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
1.2 MPC-N

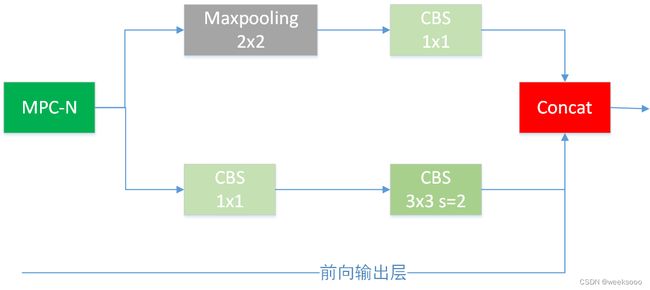
# MPC-H
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
#MPC-H
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
…
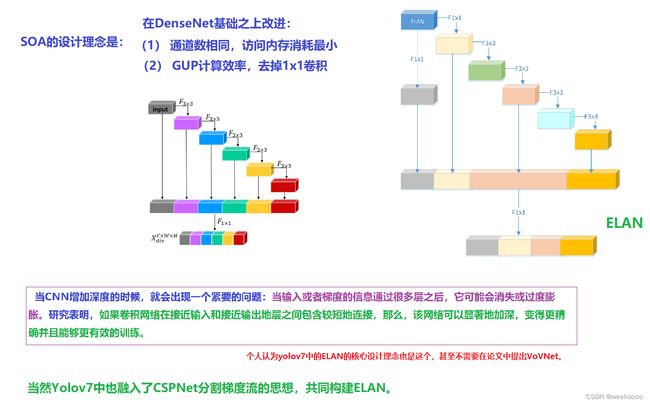
场景二:高效聚合网络
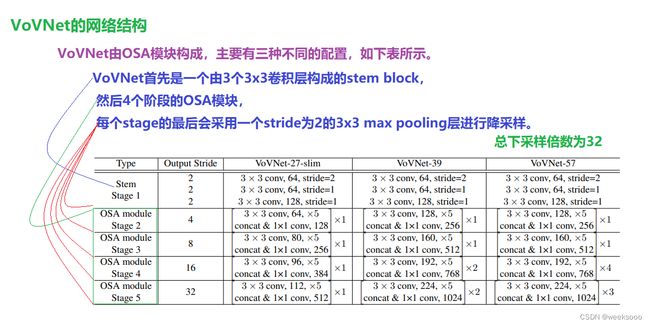
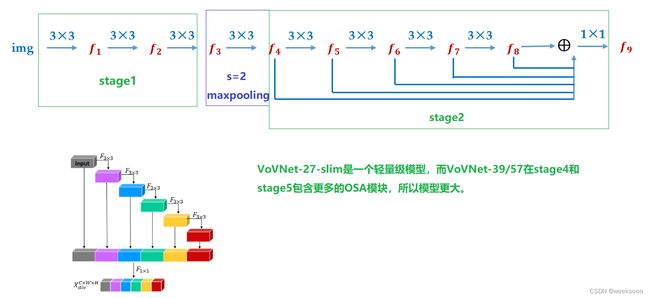
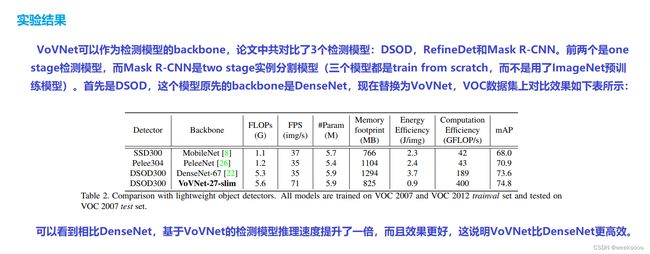
VoVNet:实时目标检测的新backbone网络


1.1 VoVNet
强推先看–>场景十:新增模型:DenseNet
VovNet论文地址

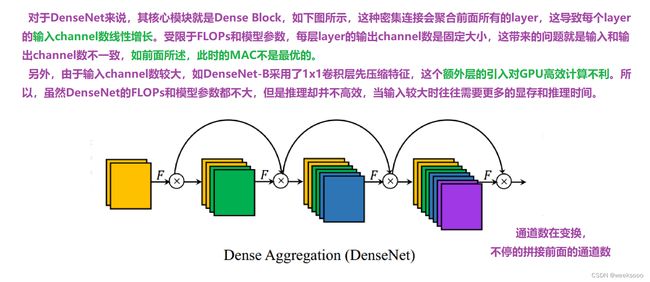
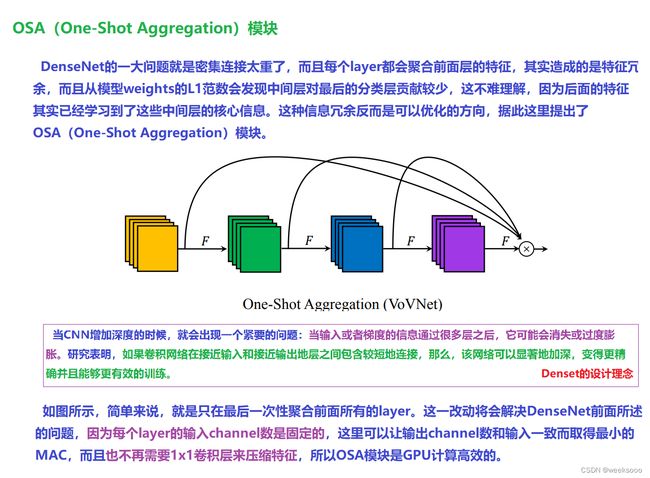
1.2 VoVNet v2
论文地址:CenterMask论文中提出VoVNet v2
场景三:常见的Attention机制–>SENet
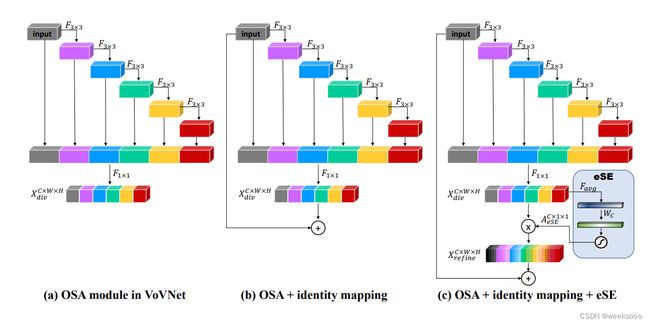

1.3 Yolov7中的ELAN结构
场景五: CSPNet

[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
1.4 Yolov7中的ELAN-H结构
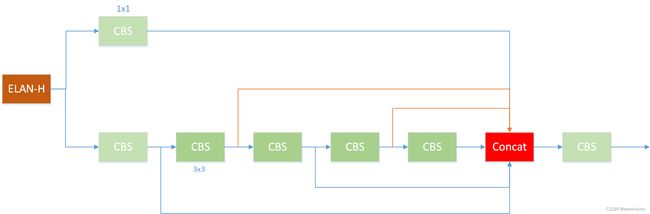
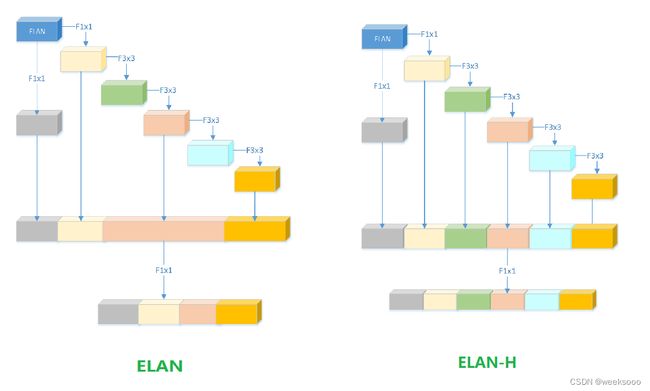
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
…
场景三:SPPCSPC
空间金字塔池化改进 SPP / SPPF / ASPP / RFB / SPPCSPC
1.1 SPPCSPC
设计理念是什么?????欢迎讨论,很多博主这里结构画错了,这里是正解.
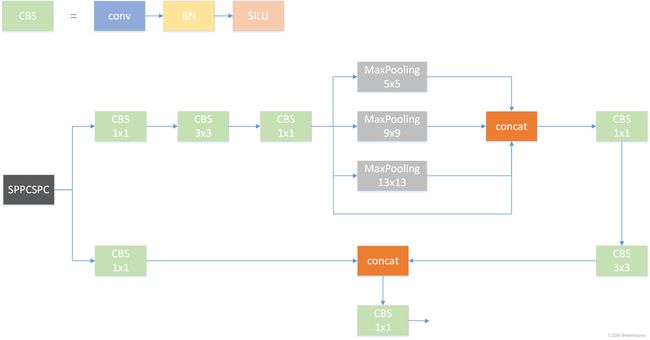
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
1.2 SPP与SPPF
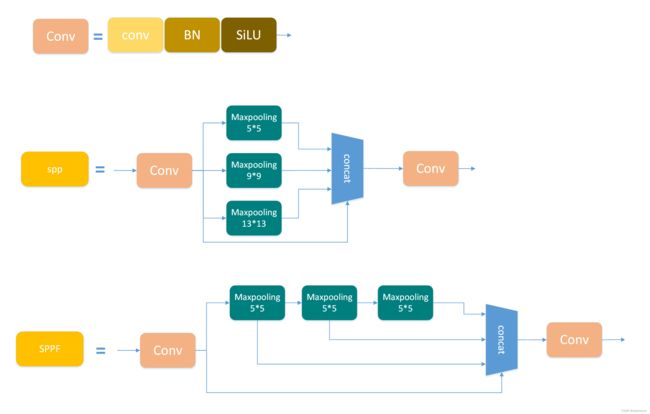
1.3 SPP3
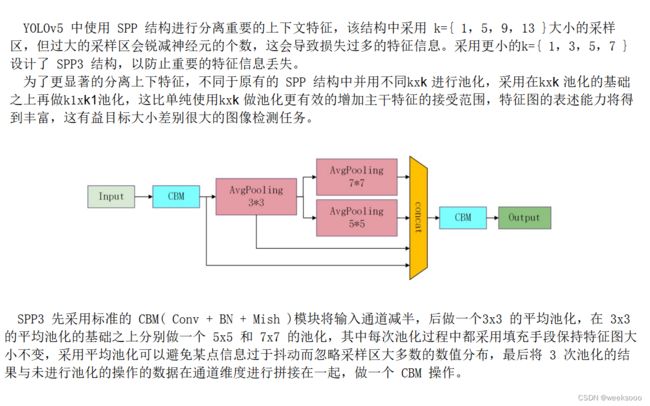
class SPP3(nn.Module):
def __init__(self, c1, c2, k1):
super().__init__()
c_ = c1 // 2
k1, k2, k3 = 3, 5, 7
self.cn1 = Conv(c1, c_, 1, 1)
self.cn2 = Conv(c_ * 4, c2, 1, 1)
self.m1 = nn.AvgPool2d(kernel_size=k1, stride=1, padding=k1 // 2)
self.m2 = nn.AvgPool2d(kernel_size=k2, stride=1, padding=k2 // 2)
self.m3 = nn.AvgPool2d(kernel_size=k3, stride=1, padding=k3 // 2)
def forward(self, x):
x = self.cn1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
m1 = self.m1(x)
m2 = self.m2(m1)
m3 = self.m3(m1)
return self.cn2(torch.cat([x, m1, m2, m3],1))
…
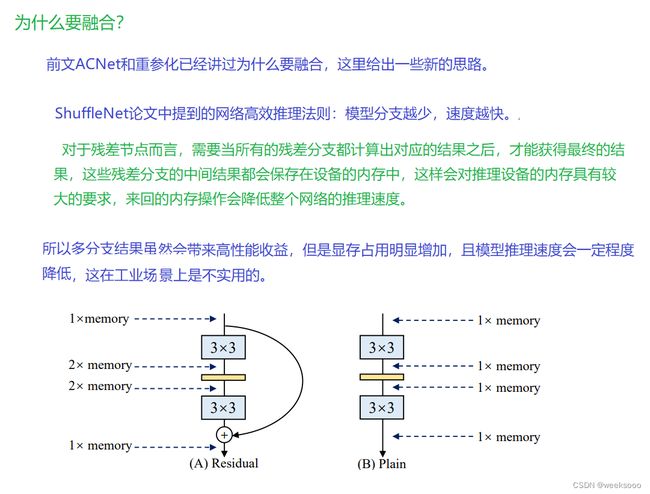
场景四:结构重参数化
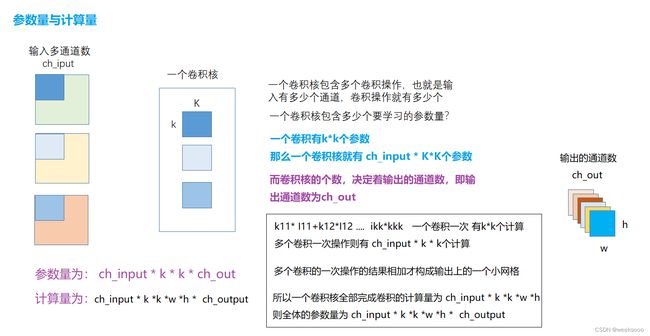
1.1 前言
结构重参数化:利用参数转换解耦训练和推理结构
解读模型压缩6:结构重参数化技术:进可暴力提性能,退可无损做压缩


1.2 ACNet
ACNet论文地址
【CNN结构设计】无痛的涨点技巧:ACNet
33卷积+13卷积+3*1卷积=白给的精度提升 | ICCV 2019

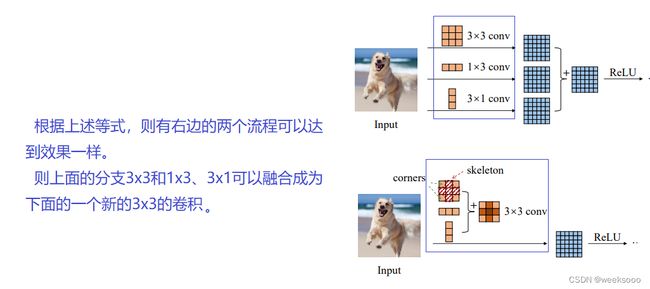
训练阶段
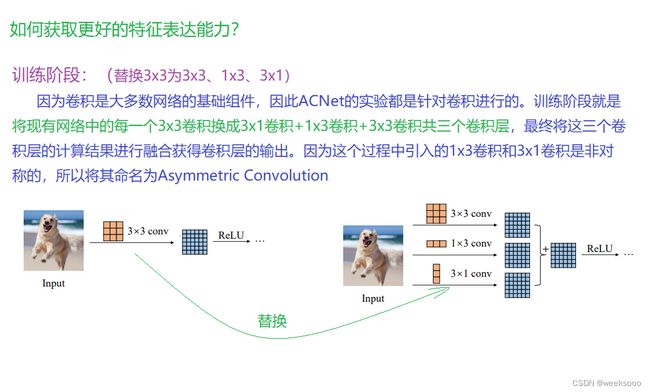
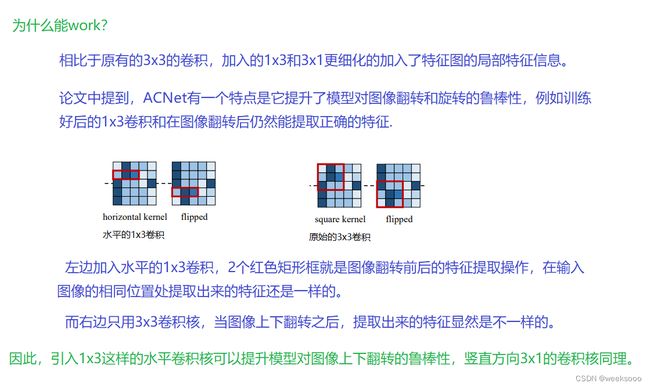

推理阶段
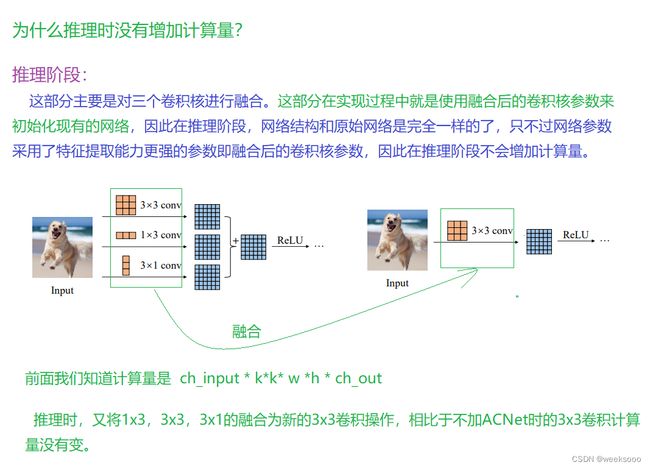

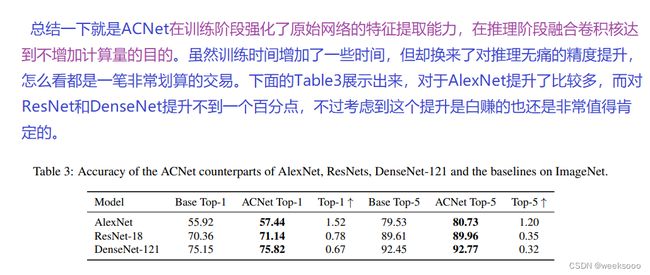
总结

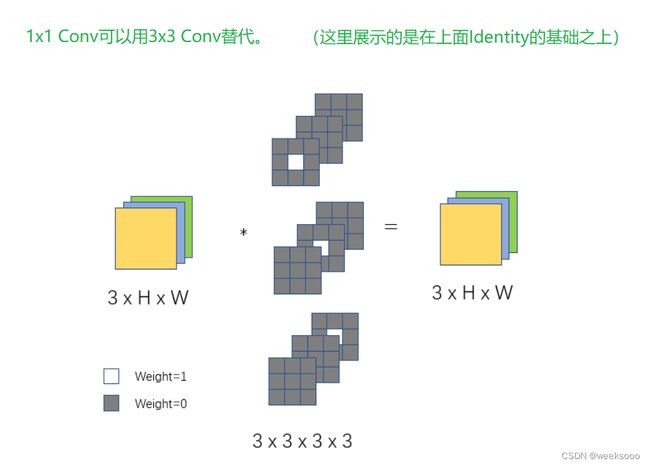
1.3 RepVGG
论文地址
RepVGG算法详解
深度解读:RepVGG
比ResNet更强的RepVGG代码详解

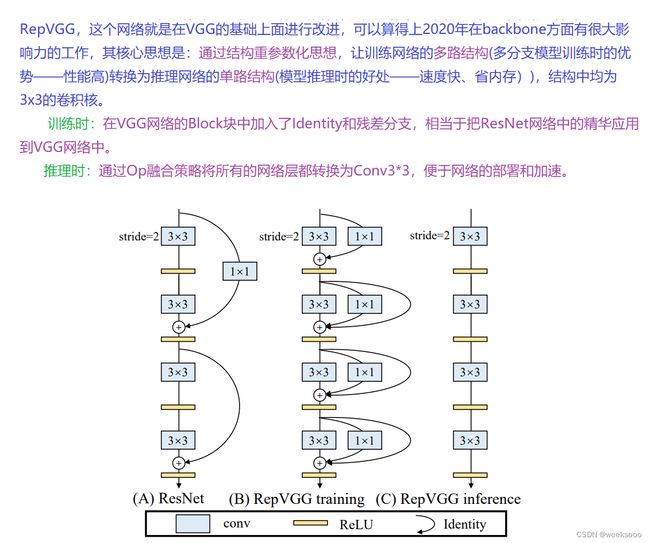
训练阶段


推理阶段

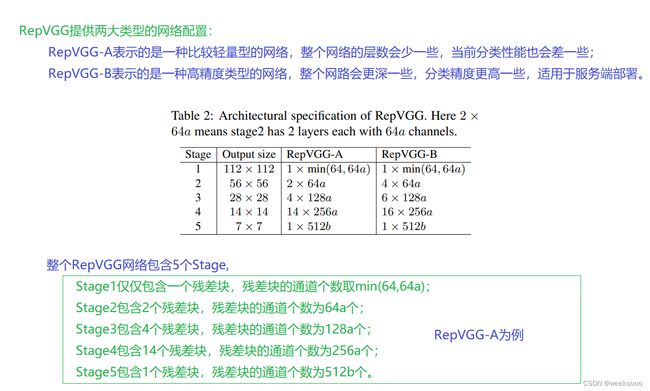
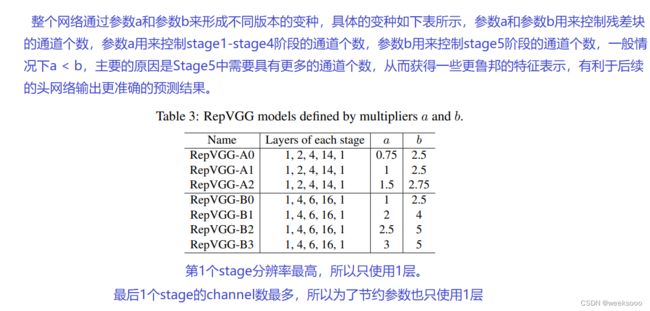
不同版本
1.4 Yolov7中的RepConv
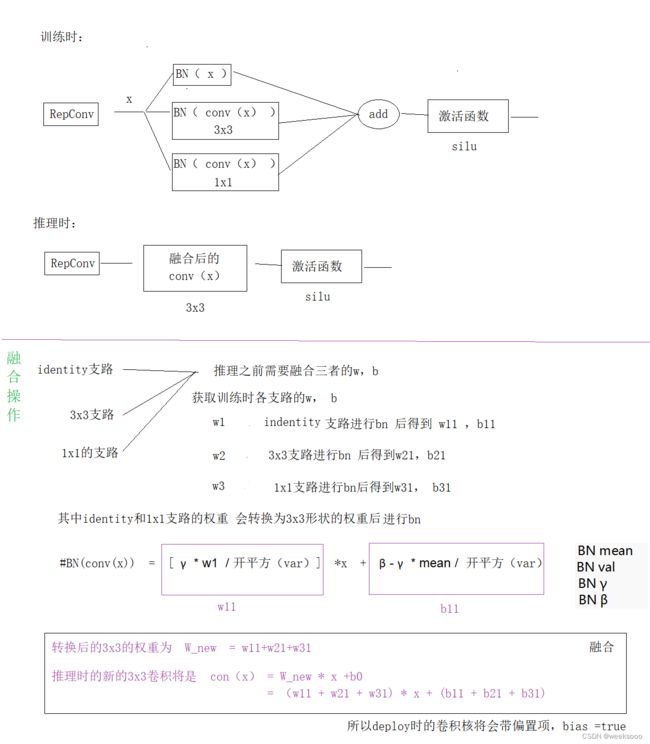
#Yolov7里面的RepConv借鉴的是RepVGG
# 重参化结构
class RepConv(nn.Module):
#RepVGG网址 https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy # deploy是推理部署的意思
self.groups = g # 输入的特征层分为几组,这是分组卷积概念,单卡GPU不用考虑,默认为1,分组卷积概念详见下面
self.in_channels = c1 # 输入通道数
self.out_channels = c2 #输出通道数
assert k == 3
assert autopad(k, p) == 1 # 为什么这么设置呢,图像padding=1后经过 3x3 卷积之后图像大小不变
padding_11 = autopad(k, p) - k // 2
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# 定义推理模型时,基本block就是一个简单的 conv2D
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
# 定义训练模型时,基本block是 identity、1x1 conv_bn、3x3 conv_bn 组合
# 如果是训练模式,就是执行identity操作+bn ,也就是输入直接+bn
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
# 普通的3x3的卷积+bn操作
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
# 普通的1x1的卷积+bn操作
self.rbr_1x1 = nn.Sequential(
nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self, inputs):
# hasattr() 函数用于判断对象是否包含对应的属性,也就是如果上面是deploy模式,就有了rbr_reparam属性,也就是重参化参数
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs)) # 推理阶段, conv2D 后 SiLU
if self.rbr_identity is None: #如果bn(x)的操作是0,也就是输入是0,那么输出为0
id_out = 0
else:
id_out = self.rbr_identity(inputs)
# (返回3x3的卷积+bn) + (1x1的卷积1x1+bn) + (identity+bn的结果)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
#repvgg的转换,也就是训练模式转换为部署模式
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return (
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),
)
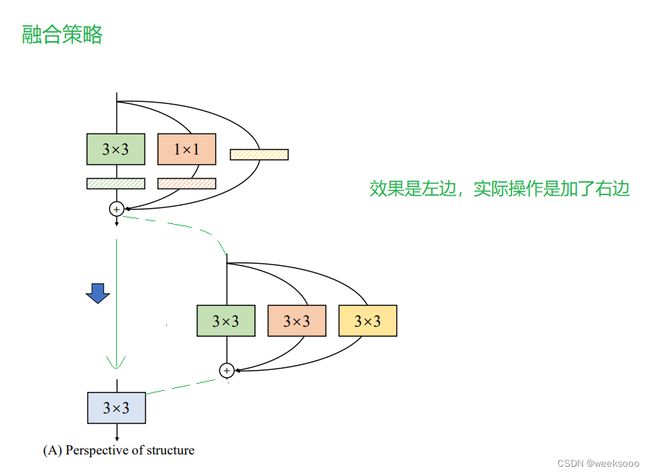
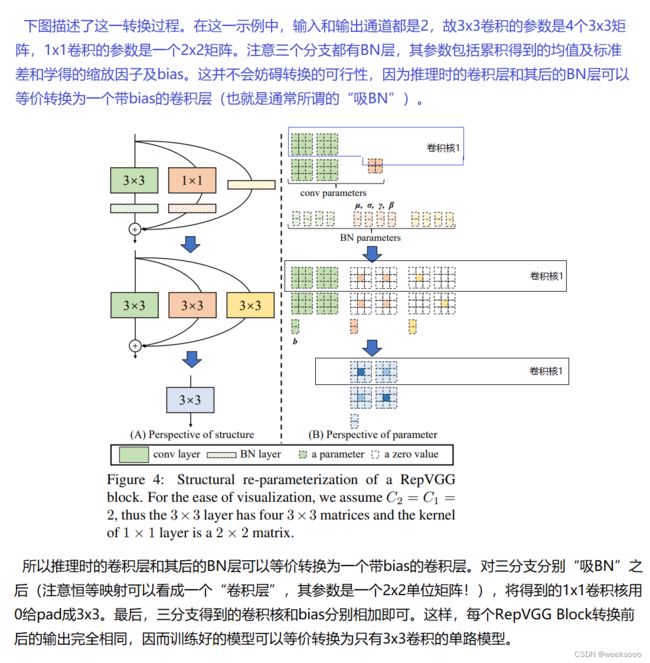
#下面这个函数就是按照论文的方法把1×1卷积和Identity操作转化成3×3卷积的------------------------------------------------------------------
#最后返回的是2个量:kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid和bias3x3 + bias1x1 + biasid。
#分别代表这个等价的3×3卷积的权重和偏置。
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense) # BN(3x3 卷积核两个参数 W 和 b)后 提出来
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1) #BN(1x1 卷积核两个参数 W 和 b)后 提出来
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
# 卷积核运算本质就是 W(x)+b,融合的策略是w相加,b相加 ,但是为啥 identity 可以提取W、b?看后面
return (
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
bias3x3 + bias1x1 + biasid,
)
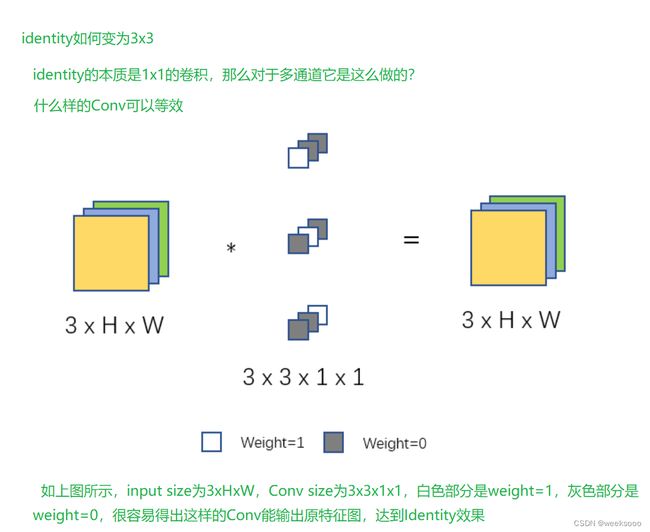
#将1x1的卷积转换为3x3的卷积
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
# 这代码讲的是将 1x1 conv padding 一圈成 3x3 conv,填充的是0
# [0 0 0]
# [1] >>>padding>>> [0 1 0]
# [0 0 0]
# 各分支的卷积进行bn操作,返回对应的bn
# 融合bn操作,这个函数的作用是“吸BN”,是怎么返回w 核 b
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
# 当branch不是3x3、1x1、BN,那就返回 W=0, b=0
# 普通的3x3的卷积+bn操作 self.rbr_dense = nn.Sequential( nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False), nn.BatchNorm2d(num_features=c2),)
# 普通的1x1的卷积+bn操作 self.rbr_1x1 = nn.Sequential( nn.Conv2d( c1, c2, 1, s, padding_11, groups=g, bias=False), nn.BatchNorm2d(num_features=c2), )
# 当branch是3x3、1x1卷积时候,返回以上数据,为后面做融合
if isinstance(branch, nn.Sequential):
kernel = branch[0].weight # conv权重 ,这里不考虑卷积带偏置项的情况
running_mean = branch[1].running_mean # BN mean
running_var = branch[1].running_var # BN val
gamma = branch[1].weight # BN γ
beta = branch[1].bias # BN β
eps = branch[1].eps # 防止分母为0
else:
#如果是identity的操作,这里branch就是nn.BatchNorm2d ; 前文 self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups # 通道分组,单个GPU不用考虑,详情去搜索分组卷积
# 定义 Conv size为(in_channles, input_dim , 3,3)的全0数组
kernel_value = np.zeros(
(self.in_channels, input_dim, 3, 3), dtype=np.float32
)
# 将卷积核中心部分部分赋予1, 1x1的卷积-->3x3的卷积的本质是 在1的周围填充0,也就是将(1,1)的位置设置为1
#假如输入输出的通道数是3 , 也就是有3个卷积核 , 每个卷积核有3个1x1的卷积操作,
# indentity-->3x3的卷积操作就是 将 (0 , 0 ,1,1) , (1,1,1,1), (2,2,1,1)的位置为0
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
#这样操作以后的identity的权重就变为了3x3
kernel = self.id_tensor # conv权重
running_mean = branch.running_mean # BN mean
running_var = branch.running_var # BN va
gamma = branch.weight # BN γ
beta = branch.bias # BN β
eps = branch.eps # 防止分母为0
#BN(conv(x)) = [ γ *w / 开平方(var)] *x + β - γ * mean / 开平方(var)
std = (running_var + eps).sqrt()
#kernel是四维张量,而t是个1维向量,所以会t = (gamma / std).reshape(-1, 1, 1, 1)使其维度和kernel匹配上。
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
#--------------------------------------------------------------------------------------------------------------------------------------------------
def fuse_conv_bn(self, conv, bn):
std = (bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t = (bn.weight / std).reshape(-1, 1, 1, 1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels = conv.in_channels,
out_channels = conv.out_channels,
kernel_size = conv.kernel_size,
stride=conv.stride,
padding = conv.padding,
dilation = conv.dilation,
groups = conv.groups,
bias = True,
padding_mode = conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)
return conv
def fuse_repvgg_block(self):
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
# Fuse self.rbr_identity
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity, nn.modules.batchnorm.SyncBatchNorm)):
# print(f"fuse: rbr_identity == BatchNorm2d or SyncBatchNorm")
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
# print(f"fuse: rbr_identity != BatchNorm2d, rbr_identity = {self.rbr_identity}")
bias_identity_expanded = torch.nn.Parameter( torch.zeros_like(rbr_1x1_bias) )
weight_identity_expanded = torch.nn.Parameter( torch.zeros_like(weight_1x1_expanded) )
#print(f"self.rbr_1x1.weight = {self.rbr_1x1.weight.shape}, ")
#print(f"weight_1x1_expanded = {weight_1x1_expanded.shape}, ")
#print(f"self.rbr_dense.weight = {self.rbr_dense.weight.shape}, ")
self.rbr_dense.weight = torch.nn.Parameter(self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None
…
场景五:标签分配–>细分方法:simOTA





…
场景六:模型复合缩放
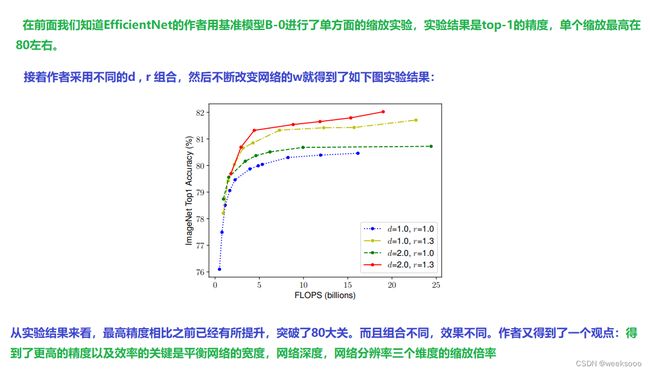
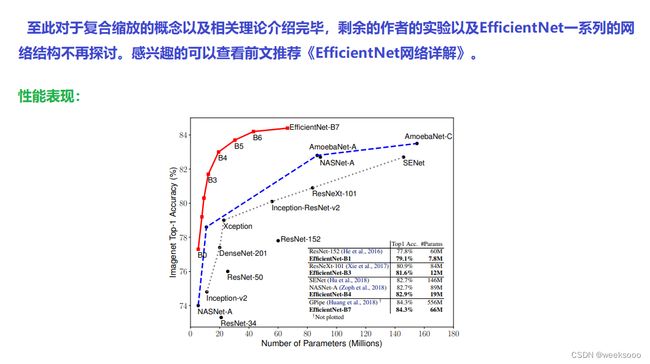
1.1 模型缩放
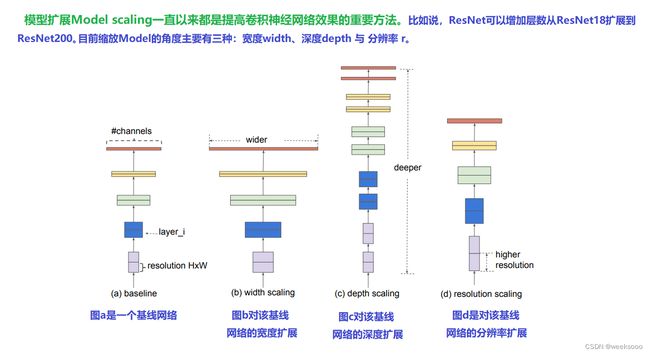

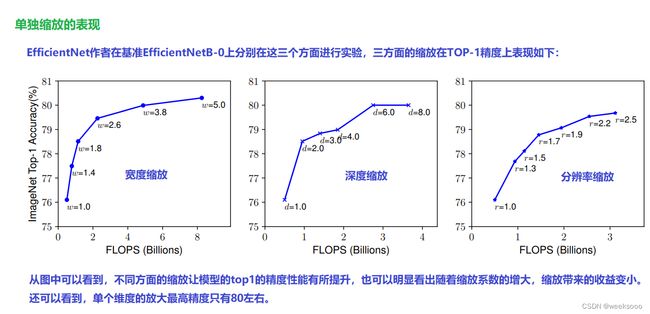


1.2 EfficientNet
EfficientNet论文地址
EfficientNet网络详解
【一看就懂】EfficientNet详解。凭什么EfficientNet号称当今最强?
神经结构搜索(Neural Architecture Search, NAS)学习
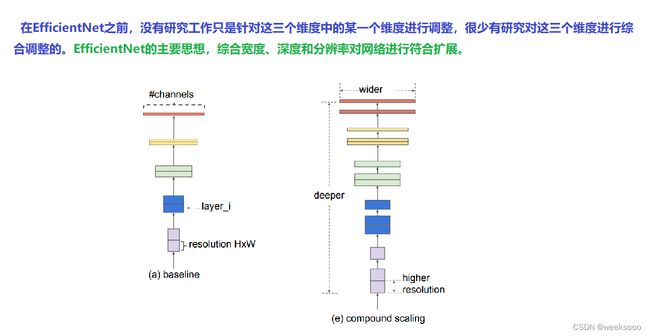



…
you did it
