DeepLabV3(Rethinking Atrous Convolution for Semantic Image Segmentation)
目录
1.DeepLabV3的提出
2.四种不同类型的全卷积网络
(1)图像金字塔(Image pyramid)
(2)Encoder-decoder
(3)更深的空洞卷积
(4)空间金字塔池化(Spatial Pyramid Pooling)
3.提出的第一种模型(Cascaded modules)
(1)Multi-grid Method
4.提出的第二种模型结构(Atrous Spatial Pyramid Pooling)
5.实验结果
(1)训练技巧
①学习率策略
②裁剪
③Batch Normalization
④Upsampling logits
⑤数据增强
(2)Cascaded modules实验
①multi-grid
②在验证集上的策略
(3)Atrous Spatial Pyramid Pooling实验
① Multi-grid
②Image Pooling
③在验证集上的策略
DeepLabV1
DeepLabV2
1.DeepLabV3的提出
本文提出的主要解决的问题是:主要是针对分割目标对象的多尺度问题。因此提出了空洞卷积级联或者平行的方式捕捉多尺度上下文信息(通过设置不同的rate)。
2.四种不同类型的全卷积网络
(1)图像金字塔(Image pyramid)
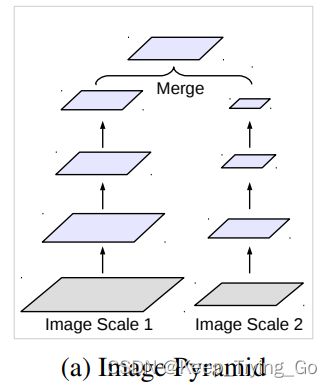
一般相同的模型通常共享权重,应用于多尺度的输入,将不同的尺度进行融合输出特征图(但是这样的结构的缺点是不能很好的扩展到更多或者更深的DCNN)。
(2)Encoder-decoder
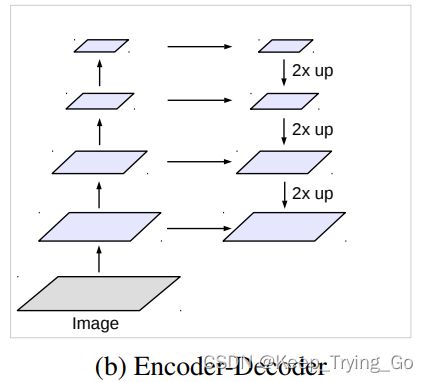
从图中可以看到主要由两部分组成,左边的部分首先进行下采样(Downsampling)到一定大小的特征图,这样做的好处是输出的内容包含更长范围的信息;右边部分对其进行上采样(Upsampling),并且和来自左边的部分进行融合。
(3)更深的空洞卷积
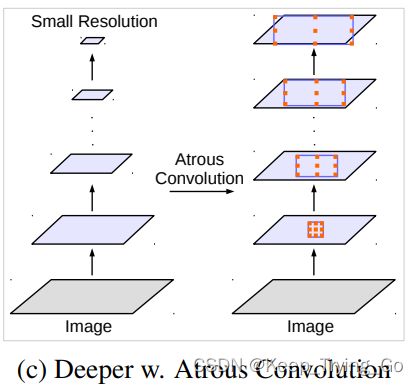
采用不同的rate得到不同的分辨率特征图大小。
(4)空间金字塔池化(Spatial Pyramid Pooling)
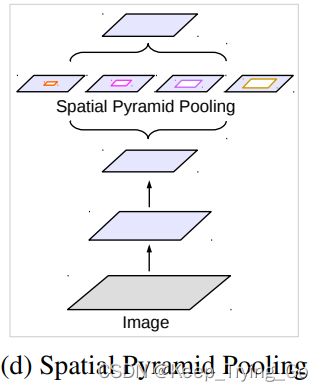
采用空间金字塔池化的方式在多个范围内捕获上下文的信息(DeepLabv2提出Atrous Spatial Pyramid Pooling)。
3.提出的第一种模型(Cascaded modules)
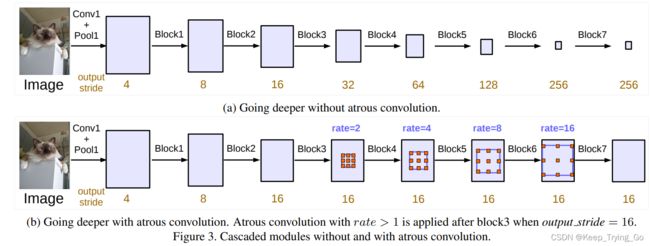
该模型的结构(a)并没有使用空洞卷积,其中Block1,Block2,Block3,Block4是原始ResNet网络中的层结构,但在Block4中将第一个残差结构里的3x3卷积层以及捷径分支上的1x1卷积层步距stride由2改成了1(即不再进行下采样),并且所有残差结构里3x3的普通卷积层都换成了膨胀卷积层。后面的block5,block6,block7都是block4的副本。
DeepLabV3网络简析
(1)Multi-grid Method
采用不同大小的网格层次结构,并从block4到block7采用不同的rate,其中三个单元卷积设置为Multi Grid = (r1, r2, r3);卷积层的最终rate等于单元卷积的Multi Grid = (r1, r2, r3)*2,例如当output_stride=16和Multi Grid = (1,2,4)时,rate=2*(1,2,4)=(2,4,8)。
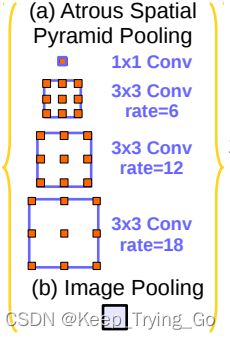
4.提出的第二种模型结构(Atrous Spatial Pyramid Pooling)
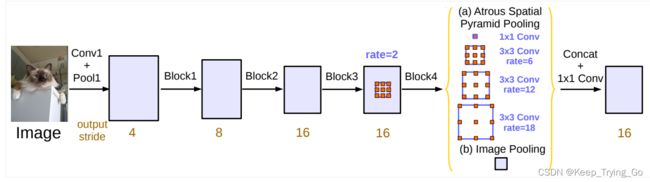
该模型结构采用了四个具有不同rate进行空洞卷积,对不同尺度的特征图进行重采样对于任意尺度的区域进行分类是非常有效的(该结构包含了Batch Normalization)。在image pooling部分,主要由1x1和3x3的卷积组成,并且3x3卷积采用不同的rate从而得到是三个不同的输出特征图

随着atrous rate的变化,在一定程度上将会导致卷积核退化为为1x1卷积。
DeepLabV2的ASPP结构:
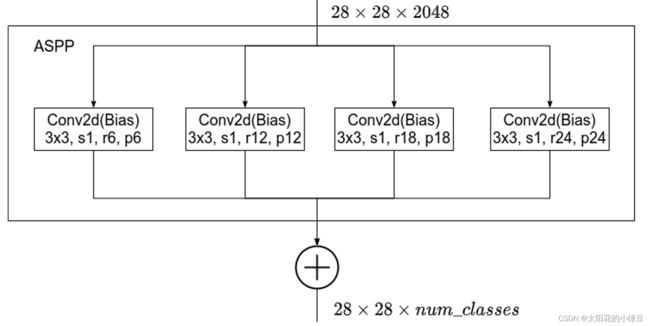
DeepLabV3的ASPP结构:
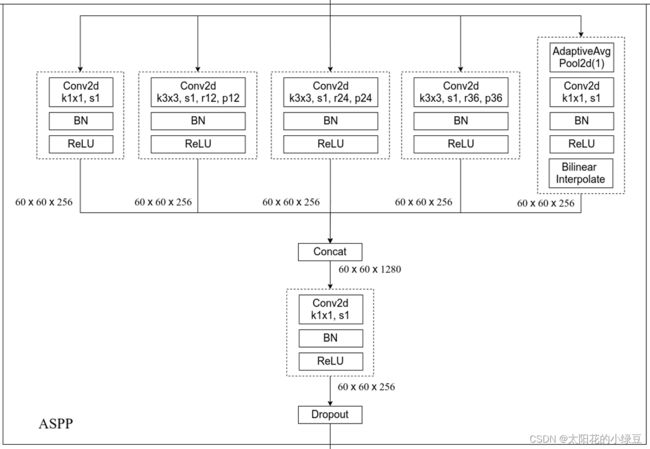
DeepLabV3网络简析
DeepLabV3的ASPP结构相比于DeepLabV2的ASPP结构要更加的“丰富”,其中主要添加的有:激活函数(ReLU)和批量归一化(Batch Normalization),以及多出来的一个分支。该分支的结构细节是,首先是进行全局的平均池化,之后经过一个1x1且步长为1的标准卷积,之后就是激活函数(ReLU)和批量归一化(Batch Normalization),最后采用线性插值。
5.实验结果
(1)训练技巧
①学习率策略
和DeepLabV2一样采用相同的学习策略方式,使用的公式为:(1-iter/max_iter)^power,默认power=0.9.
②裁剪
在训练期间从图像裁剪出patches,由于使用的是较大的atrous rate,因此裁剪的尺寸比较大;在PASCAL VOC 2012上的训练集和测试集裁剪的尺寸为513.
③Batch Normalization
Batch Normalization对于训练是非常重要的,对于训练的效果是非常有用的。其中当设置的output_stride=16时,Batch Normalization的decay=0.9997,在训练了30k iterations之后,初始化的学习率为lr=0.007;当设置的output_stride=8时,在PASCAL VOC 2012验证集上进行30k it而iterations和lr=0.001(output_stride=16比output_strde=8的训练速度要快,但是output_stride=16输出的特征图较coarse).
④Upsampling logits
在之前的DeepLabV2中,使用的output_stride=8,时,并且ground truth在训练期间也被下采样8倍,最终计算损失函数,但是对于ground truth进行8倍的下采样的话, 会导致细节的信息丢失,且不能恢复。
⑤数据增强
将图片从0.5到2.0之间进行随机缩放输入的图片,训练期间进行随机的翻转。
(2)Cascaded modules实验

将ResNet50和block7 (额外的block5,block6和block7)结合使用探索不同步长的效果。
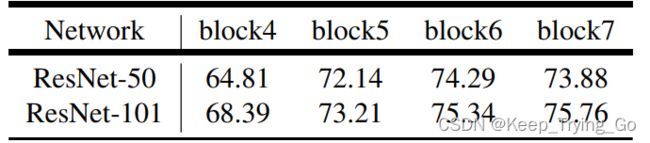
对于ResNet50和ResNet101在output_stride=16上使用不同的数量的cascade blocks结果对比 ,其中‘block4’, ‘block5’, ‘block6’, and ‘block7’额外的增加了0,1,2,3级联模块,通过更多的级联模块来提高性能。
注:output_stride=16.
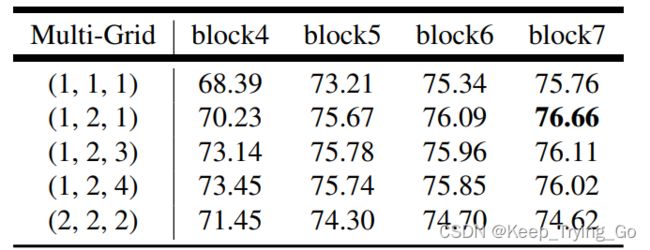
①multi-grid
从图中可以看到当multi-grid为(1,2,1)的效果是最好的,并且这里的膨胀系数等于rates*multi-grid(r1,r2,r3).
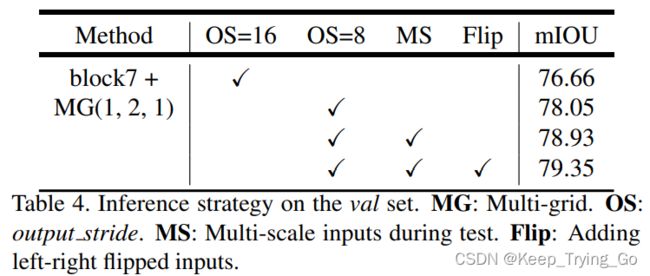
②在验证集上的策略
当训练的时候output_stride=16,在推理的过程中采用output_stride=8时,性能提高1.39%。多尺度的输入设置为:scales = {0.5, 0.75, 1.0, 1.25, 1.5, 1.75}。
(3)Atrous Spatial Pyramid Pooling实验
注:output_stride=16.

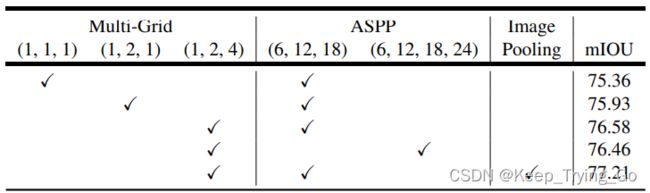
① Multi-grid
采用Multi-grid(1,2,4)的效果是最好的。
②Image Pooling
③在验证集上的策略
当训练的时候output_stride=16,在推理的过程中采用output_stride=8时,性能提高1.39%。多尺度的输入设置为:scales = {0.5, 0.75, 1.0, 1.25, 1.5, 1.75}。
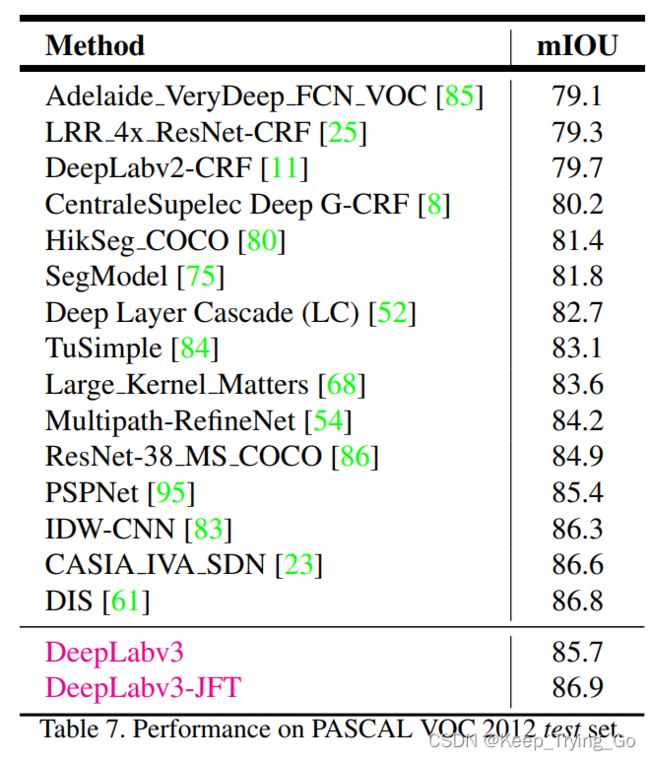
在DeepLabV2中使用CRF之后的效果达到79.7%(DeepLabV2-CRF);DeepLabV3和DeepLabV3-JFT分别达到了85.7%和86.9%的最好效果。