CVPR2017(Segmentation):DeepLabV3-论文解读《Rethinking Atrous Convolution for Semantic Image Segmentation》
文章目录
-
- 原文地址
- 论文阅读方法
- 初识(Abstract & Introduction & Conclusion)
- 相知(Body)
-
- 2.Related Work
- 3.Methods
-
- 3.1.Atrous Convolution for Dense Feature Extraction
- 3.2. Going Deeper with Atrous Convolution
-
- 3.2.1. Multi-grid Method
- 3.3. Atrous Spatial Pyramid Pooling
- 4. Experimental Evaluation
-
- 4.1 Training Protocol
- 4.2 Going Deeper with Atrous Convolution
-
- 4.3. Atrous Spatial Pyramid Pooling
- 回顾(Review)
- 代码
原文地址
https://arxiv.org/abs/1706.05587
论文阅读方法
三遍论文法
初识(Abstract & Introduction & Conclusion)
这篇文章是DeepLab系列更新的第三个版本“DeepLabv3”,发表于CVPR2017。
- Motivation:在使用深度神经网络做语义分割的时,作者认为主要有两个挑战:一个是由于连续的池化操作和步长大于1的卷积操作,导致特征映射的分辨率减少;另一个分割对象存在多尺度的特性。

- 第一个挑战,可以通过空洞卷积来解决,因为空洞卷积可以准确地控制特征映射的分辨率。
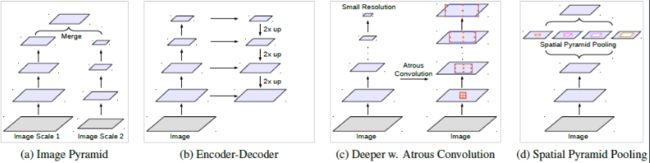
-
第二个挑战,目前有很多方式来解决,作者这里主要考虑上图的四个方案。a)是图像金字塔,将不同尺度的输入网络;b)是Encoder-Decoder结构;c)是使用额外的级联卷积层去逐渐获得长距离信息(DeepLabV1、V2通过后接Dense CRF模块获取长距离信息);d)使用空间金字塔结构,以不同尺度的卷积或者池化操作进行特征提取。
-
Contribution:
- a) 主要还是重新考虑空洞卷积的应用,作者设计了不同的模块进行实验。
- b) 在先前提出的ASPP模块上做了扩展,除了多尺度捕获卷积特征的同时,还新增了编码全局上下文信息的image-level特征。
- c) 详细说明了实现细节以及分享了训练模型时的经验。
- d) 性能的提升,使得模型在PASCAL VOC 2012基准上具有竞争力(SOTA)。
相知(Body)
2.Related Work
这里主要介绍了上面那个图(四种不同的方法):
- a) Image Pyramid:给模型送入不同尺度的输入。小尺度图像编码长距离上下文,大尺度图像保留了小物体细节。
- b) Encoder-Decoder:其中编码阶段的特征图空间维度逐渐减少,在深层编码器的输出容易捕获到长距离信息。在解码阶段,物体细节和空间维度得到逐渐恢复。
- c) Context module:使用额外的级联模块去编码长距离上下文。
- d) Spatial pyramid pooling:利用空间金字塔池化去捕获不同距离的上下文。
随后,作者也提了一下DeepLabV1,V2的工作,应用空洞卷积作为context module和空间金字塔池化的工具(Atrous Spatial Pyramid Pooling),并且还使用了Dense CRF作为后处理模块。
3.Methods
3.1.Atrous Convolution for Dense Feature Extraction
空洞卷积始终贯穿着DeepLab系列,其既能获取到更大的感受野,也不用减少特征映射的分辨率,并且也不用增加额外的参数,关于这一部分可以详细看我的博客。
deconvolution;Atrous convolution;Depthwise separable convolution是什么?
3.2. Going Deeper with Atrous Convolution
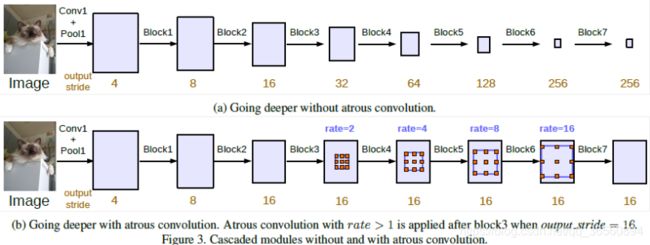
首先我们明确一下output_stride的定义,就是输入图像的尺寸/输出图像的尺寸,这个在DeepLabV1中有过详细介绍。因为经过池化下采样特征分辨率就会减少(目前常用的2x2 max pool,就会使得每次pooling过后,output增加一倍),一般用于图像分类网络的output_stride为32(ResNet、Vgg等)。
上图体现了有/无空洞卷积的级联模块,网络中Block类似于ResNet中Block,其中Block4就是原生ResNet的最后一个模块。Block5-7都是Block4的副本(简单的复制),每个Block包含3个卷积层,最后一个卷积的步幅为2所以会导致output_stride变化。虽然a)最后能够将全局信息有效地融合在一个小尺寸的特征图中,但是由于空间维度的损失,我们丢失了物体的细节信息,这对语义分割是不利的。所以b)中Block4之后应用了不同膨胀率的空洞卷积,得到了output=16的结果。
3.2.1. Multi-grid Method
此外,还采用了多网格方法,就是在一个模块中使用了不同尺寸的网格结果。意思很简单,上图的b)中每个Block的Atrous Rate是一样是一样的,比如Block4的rate=2。但是我们可以给一个block中的不同卷积层赋予不同尺寸,因此我们定义Multi_Grid=(r1,r2,r3)。当output_stride=16时,我们定义Multi_Grid=(1,2,4),那么Block4中不同卷积层的rate为(1,2,4)*2=(2,4,8)。
3.3. Atrous Spatial Pyramid Pooling
回顾DeepLabV2所提出的ASPP,其应用了4个平行的不同rate的空洞卷积在特征图的顶部提取多尺度信息。与之前的不同,新的ASPP包含了Batch Norm。并且,作者发现,随着空洞卷积膨胀率的增加,卷积核的有效权重会减少(有效权重指的就是应用在特征映射上有效区域的卷积核权重,而不是零填充区域)。
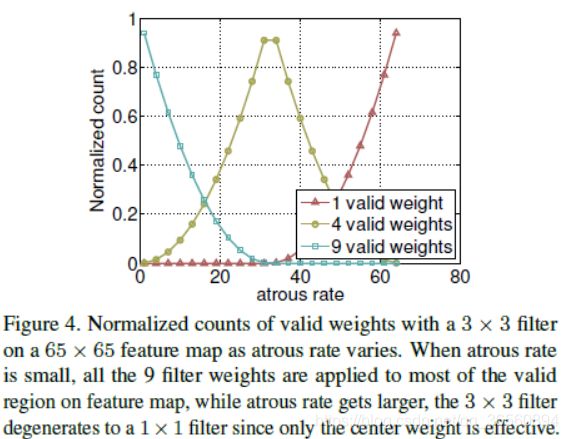
如上图所示,还存在一个极端情况,当膨胀率非常接近特征图的尺寸时,3x3的卷积其实退化成了一个1x1的卷积。这个其实比较好理解,举的例子中特征图尺寸为65x65,当膨胀率接近65时,其实只有卷积核中间的权重是有效的,所以就退化成了一个1x1卷积。
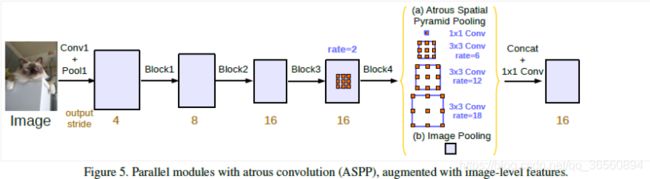
为了解决这个问题和更好地捕获全局信息,采用了一个图像级的特征,所谓的Image-Level的特征就是对输入特征图做一个全局平均池化,然后进行一个1x1卷积(256个channel),卷积后进行一个batchnorm操作,随后再进行双线性插值上采样到所需的空间维度。
最后,作者新提出的ASPP模块中,包含了1个1x1卷积、3个不同膨胀率的3x3空洞卷积(每个卷积为256channel,并且卷积后进行BatchNorm处理)和一个Image-Level的特征。当我们所需的output_stride=16时,三个空洞卷积的膨胀率为(6,12,18),当output_stride=8时,膨胀率加倍,为(12,24,36)。最后我们将5个分支的结果进行一个Concat,然后通过一个1x1卷积(256个Channel),然后再通过1个1x1卷积得到最后的概率分布图,如下图所示。
4. Experimental Evaluation
实验采用的Backbone为在ImageNet上进行过预训练的ResNet101,使用的数据集为PASCAL VOC 2012,其中还用了额外的标注数据(trainaug),使用Mean IOU衡量模型性能。
4.1 Training Protocol
Learning rate policy:"poly"策略进行动态调整,power参数为0.9。
**Crop Size:**513,裁剪的尺寸要大一些,因为尺寸过小的,会导致中间特征图进行空洞卷积时产生许多无用的权重,变为1x1卷积。
**Batch Normalization:**所有在ResNet后增加的模块都使用了批次归一化(Batch Normalization),这对训练很重要。并且作者先在output_stride=16情况下训练,然后固定batch normalization的参数,再在output=8训练。同时,作者还讨论了在不同训练阶段使用空洞卷积能够控制output_stride,并且无需额外增加参数量。但是output_stride=16比output_stride=8确实要快很多,因为它们的空间维度差得比较大,output_stride=8要比16大了4倍,但是output_stride越小,特征图提供的信息也越多,分割效果也会越好。
**Upsampling logits:**在之前的DeepLabV1、V2中,在网络训练时,由于output_stride=8,所以会将groundtruth进行下采样8x用于监督。但是作者后来发现,保持groundtruth的完整很重要,因为会提供更精细的反馈。所以从V3开始,对logits进行8x的上采样(双线性插值),再用完整的groundtruth来监督。
**Data augmentation:**主要使用了随机尺度变化(0.5-2.0)以及随机左右翻转。
4.2 Going Deeper with Atrous Convolution

**ResNet-50:**将ResNet扩充到7个block,从而探索output_stride对分割性能的影响,其中利用空洞卷积来调整output_stride。

ResNet-50 vs ResNet-101: 将ResNet-50和网络结构更深的ResNet-101进行比较,output_stride=16的情况下,ResNet-101优于50,并且增加到7个block的时候,ResNet-50的性能出现了略微的下降,而ResNet-101还能继续提升。

**Multi Grid:**探索多网格方法,可以观察到三个结论 a)多网格方法优于普通方法(Multi-Grid=1,1,1);b)简单的加倍是没用的,比如(1,1,1)->(2,2,2);c)使用多网格方法加深网络会提升性能。

**Inference strategy on val set:**在测试时使用多尺度输入(Multi Scale input)和左右翻转(left-right Flip)能够进一步提升性能。
4.3. Atrous Spatial Pyramid Pooling
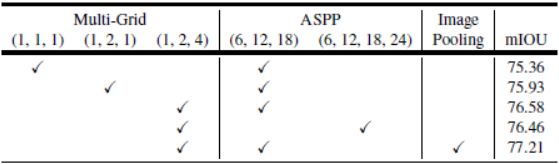
ASPP:在并行模块中进行多网格方法的测试(固定ASPP,更改block4的Multi_Grid),最优模型Multi_Grid=(1,2,4),ASPP=(6,12,18)。
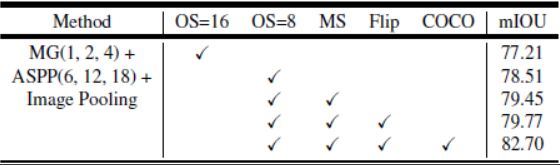
验证集上的推理策略:在测试时使output_stride=8,ASPP最优模型(未使用COCO预训练)为79.77%优于级联模型的79.35%。
与DeepLabv2对比:DeepLabv3在未使用DenseCRF后处理以及MS-COCO预训练的情况下优于DeepLabv2(使用后处理、MSCOCO预训练)。

对比:最后为了打榜,作者使用了简单有效的重采样方法来解决分割不好的类别(简单来说,就是在训练集中多复制几份难分割图像),在训练时使用output_stride=8,并且先在MS-COCO上进行预训练,然后再在增广数据集上进行微调,最后在官方数据集上做最后微调(因为官方数据集标注结果更精细),这样可以达到85.7%的性能。为了冲SOTA,又在JFT-300M上预训练了一波,最后达到最优性能86.9%。
回顾(Review)
DeepLab系列在分割领域一直很受欢迎,知名度很高。单看DeepLabV3,其实真正的创新点没有前两篇丰富,没有增加新的模块,而是针对于前两个版本做了一下升华和总结。在文中作者也说了,为什么能在不加DenseCRF后处理的情况下超越前几个版本的性能,两点:1)Batch Normalization的引入;2)ASPP模块的探索,加入了image-level的特征。其实,我觉得本文主要的亮点在于对Atrous Convolution并行/串行两种应用方式的探索。
从这个系列来看,DeepLabV1、V2工作很novelty,并且能达到不错的performance;V3其实在前面的工作上增加了一些小的点(batch normalization 和 Image-level feature),但很work。虽然novelty的工作很少,但是奈何performance牛逼啊,然后写作上注重消融实验。学术创新不易啊~
代码
DeepLabV3的开源代码很多,大家可以在github搜索,等有空我再自己复现一篇将地址贴在这里~
以上为个人的浅见,水平有限,如有不对,望大佬们指点。
未经本人同意,请勿转载,谢谢。