特征对齐的PCD模块解释
参考文章:**EDVR: Video Restoration with Enhanced Deformable Convolutional Networks **
3.2. Alignment with Pyramid, Cascading and Deformable Convolution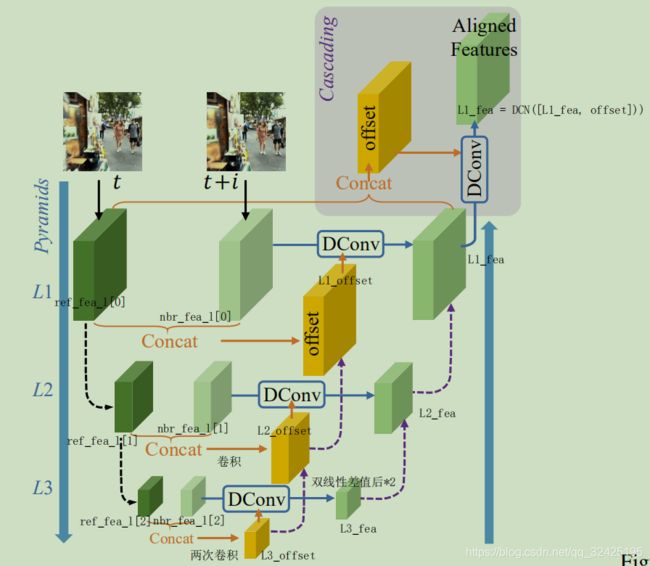
整体流程:先金字塔下采样得到nbr_fea_l(包括nbr_fea_l[0],nbr_fea_l[1],nbr_fea_l[2])和ref_fea_l(包括ref_fea_l[0],ref_fea_l[1],ref_fea_l[2]),然后从最底层开始用DCN计算offset和对齐featuremap.其中下层计算的offset会通过上采样,concat和卷积与上层的offset结合在一起,下一层计算的warp后的feature_map会通过上采样和concat和上层的warp后的feature map结合在一起。
代码:
其中nbr_fea_l, ref_fea_l的含义见上图,DCN的解释见下面
from models.archs.DCNv2.dcn_v2 import DCN_sep as DCN
class PCD_Align(nn.Module):
''' Alignment module using Pyramid, Cascading and Deformable convolution
with 3 pyramid levels.
'''
def __init__(self, nf=64, groups=8):
super(PCD_Align, self).__init__()
# L3: level 3, 1/4 spatial size
self.L3_offset_conv1 = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for diff
self.L3_offset_conv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.L3_dcnpack = DCN(nf, nf, 3, stride=1, padding=1, dilation=1, deformable_groups=groups,
extra_offset_mask=True)
# L2: level 2, 1/2 spatial size
self.L2_offset_conv1 = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for diff
self.L2_offset_conv2 = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for offset
self.L2_offset_conv3 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.L2_dcnpack = DCN(nf, nf, 3, stride=1, padding=1, dilation=1, deformable_groups=groups,
extra_offset_mask=True)
self.L2_fea_conv = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for fea
# L1: level 1, original spatial size
self.L1_offset_conv1 = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for diff
self.L1_offset_conv2 = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for offset
self.L1_offset_conv3 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.L1_dcnpack = DCN(nf, nf, 3, stride=1, padding=1, dilation=1, deformable_groups=groups,
extra_offset_mask=True)
self.L1_fea_conv = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for fea
# Cascading DCN
self.cas_offset_conv1 = nn.Conv2d(nf * 2, nf, 3, 1, 1, bias=True) # concat for diff
self.cas_offset_conv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.cas_dcnpack = DCN(nf, nf, 3, stride=1, padding=1, dilation=1, deformable_groups=groups,
extra_offset_mask=True)
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
def forward(self, nbr_fea_l, ref_fea_l):
'''align other neighboring frames to the reference frame in the feature level
nbr_fea_l, ref_fea_l: [L1, L2, L3], each with [B,C,H,W] features
'''
# L3
L3_offset = torch.cat([nbr_fea_l[2], ref_fea_l[2]], dim=1)
L3_offset = self.lrelu(self.L3_offset_conv1(L3_offset))
L3_offset = self.lrelu(self.L3_offset_conv2(L3_offset))
L3_fea = self.lrelu(self.L3_dcnpack([nbr_fea_l[2], L3_offset]))
# L2
L2_offset = torch.cat([nbr_fea_l[1], ref_fea_l[1]], dim=1)
L2_offset = self.lrelu(self.L2_offset_conv1(L2_offset))
L3_offset = F.interpolate(L3_offset, scale_factor=2, mode='bilinear', align_corners=False)
L2_offset = self.lrelu(self.L2_offset_conv2(torch.cat([L2_offset, L3_offset * 2], dim=1)))
L2_offset = self.lrelu(self.L2_offset_conv3(L2_offset))
L2_fea = self.L2_dcnpack([nbr_fea_l[1], L2_offset])
L3_fea = F.interpolate(L3_fea, scale_factor=2, mode='bilinear', align_corners=False)
L2_fea = self.lrelu(self.L2_fea_conv(torch.cat([L2_fea, L3_fea], dim=1)))
# L1
L1_offset = torch.cat([nbr_fea_l[0], ref_fea_l[0]], dim=1)
L1_offset = self.lrelu(self.L1_offset_conv1(L1_offset))
L2_offset = F.interpolate(L2_offset, scale_factor=2, mode='bilinear', align_corners=False)
L1_offset = self.lrelu(self.L1_offset_conv2(torch.cat([L1_offset, L2_offset * 2], dim=1)))
L1_offset = self.lrelu(self.L1_offset_conv3(L1_offset))
L1_fea = self.L1_dcnpack([nbr_fea_l[0], L1_offset])
L2_fea = F.interpolate(L2_fea, scale_factor=2, mode='bilinear', align_corners=False)
L1_fea = self.L1_fea_conv(torch.cat([L1_fea, L2_fea], dim=1))
# Cascading
offset = torch.cat([L1_fea, ref_fea_l[0]], dim=1)
offset = self.lrelu(self.cas_offset_conv1(offset))
offset = self.lrelu(self.cas_offset_conv2(offset))
L1_fea = self.lrelu(self.cas_dcnpack([L1_fea, offset]))
return L1_fea
可变形卷积DCN:
**DCN采用几层卷积预测offset(特征图上每个位置的卷积的每个位置的偏移,所以offset的size为(2*kernel[0]kernel[1],h,w))和卷积加权的权重mask(权重mask的size为(kernel[0]kernel[1],h,w)),然后进行加权求和得到响应值。
所以,不管用几层卷积,怎么操作,都要预测一个这种尺寸的offset(mask不是必须要预测的),然后根据offset加权求和得到响应值的过程。
DCN_sep as DCN
self.L3_dcnpack = DCN(nf, nf, 3, stride=1, padding=1, dilation=1, deformable_groups=groups,extra_offset_mask=True)
self.L3_dcnpack([nbr_fea_l[2], L3_offset]) #输入nbr_fea_l[2]是需要做变形卷积处理的feature_map,L3_offset类似于fixed feature map和warp feature map的差异。DCN根据L3_offset求出要warp feature map的偏移(xoffset和yoffset),然后根据偏移对nbr_fea_l[2]做warp,得到warp后的feature map作为输出。所以nbr_fea_l[2], L3_offset的尺寸和通道数是一样的,DCN根据L3_offset计算整体的(并没有根据某个通道单独计算)的xoffset和yoffset.
实现:
class DCN_sep(DCNv2):
init:
self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels, *self.kernel_size)) #这个self.weight是用来做操作的参数,可变形卷积也是一次卷积操作
channels_ = self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1] #kernel_size=(3,3),所以channels=1*3*3*3=27
self.conv_offset_mask = nn.Conv2d(self.in_channels, channels_, kernel_size=self.kernel_size,stride=self.stride, padding=self.padding, bias=True) #self.in_channels=nf=64,channels_=27,kernel_size=3
forward:
#因为我们的extra_offset_mask=True,所以forward函数有两个输入
if self.extra_offset_mask:
# x = [input, features]
out = self.conv_offset_mask(x[1]) #输入1为extra_offset_mask,对应上面的L3_offset,out = self.conv_offset_mask(L3_offset),out的size为(batchsize,27,h,w)
x = x[0] #输入0为特征,对应nbr_fea_l[2]
o1, o2, mask = torch.chunk(out, 3, dim=1)#把out的27个通道分为9+9+9,o1,o2,mask的size为(batchsize,9,h,w),o1,o2为偏移值,mask为加权的权重。根据该划分可知,x方向坐标偏移为前9个通道,y方向坐标偏移为中间9个通道,权重值为后面9个通道
offset = torch.cat((o1, o2), dim=1) #offset的size为(batchsize,2*9,h,w)
mask = torch.sigmoid(mask)
offset_mean = torch.mean(torch.abs(offset)) #这里只是用来判断offset是不是过大,过大则表明很可能发生了错误
#dcn_v2_conv函数本身是根据预测的offset和mask,进行可变形卷积的加权计算。这里应该没有参数(?),只是用已经预测的offset和mask做计算
dcn_v2_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding,self.dilation, self.deformable_groups)
#dcn_v2_conv(nbr_fea_l[2],offset),self.weight是根据kernelsize的大小位置成正太分布,self.weight.data.uniform_(-stdv, stdv)
output = _backend.dcn_v2_forward(input, weight, bias, offset, mask, ctx.kernel_size[0],
ctx.kernel_size[1], ctx.stride[0], ctx.stride[1],
ctx.padding[0], ctx.padding[1], ctx.dilation[0],
ctx.dilation[1], ctx.deformable_groups)
最后会运行到.cu中
const float *data_offset_ptr = data_offset + (b_col * deformable_group + deformable_group_index) * 2 * kernel_h * kernel_w * height_col * width_col;
DCN更详细的解释参考:https://zhuanlan.zhihu.com/p/62661196

常规卷积,DCNV1,DCNV2参考:
https://blog.csdn.net/u014380165/article/details/88072737