语音增强——谱减法的改进(过减法)及其python实现
参考视频:
https://www.bilibili.com/video/BV1CM4y1M7kb?spm_id_from=333.999.0.0&vd_source=77c874a500ef21df351103560dada737
语音降噪是语音信号处理的初始步骤,目前已经有很多成熟的算法。而谱减法作为经典的降噪算法实现简单,运行处理快,被广泛的应用在语音降噪领域。
基本谱减法的缺点及其改进
谱减法最显著的缺点是会引入“音乐噪声”,由于谱减过程中可能出现负的幅度值,半波整流是一种直接的解决办法,但是这种非线性处理会导致频谱随机频率位置上出现小的、独立的峰值,在时域中表现为明显的多频颤音,也称为“音乐噪声”。如果处理不当,在某些语音段,“音乐噪声”的影响甚至比干扰噪声更为明显。造成“音乐噪声”的常见原因有:
1、对谱减过程中负值的非线性处理。
2、噪声谱估计不匹配。静音段的平均噪声谱可能与实际语音段的噪声分量有着较大差别,相减后会有残留的孤立噪声段。
3、谱估计方法的误差。例如周期图等有偏功率谱估计方法带来的偏差。
4、抑制函数有较大的可变性。
为了减小音乐噪声,学者们提出了一系列的改进方法,感兴趣的读者可以自行了解。这里介绍过减法的使用方法,相比直接置零,该方法设置了一个谱值下限。具体可表示为:

若γ=1,上述过程相当于能量谱的谱减法;若γ=0.5,上述过程相当于幅度谱的谱减法
程序如下:
import librosa
from librosa.core.spectrum import amplitude_to_db
import numpy as np
from scipy.signal import lfilter, firwin, freqz
import soundfile as sf
import matplotlib.pyplot as plt
if __name__ == "__main__":
clean_wav_file = "sf1_cln.wav"
clean,fs = librosa.load(clean_wav_file,sr=None)
print(fs)
noisy_wav_file = "sf1_n0L.wav"
noisy,fs = librosa.load(noisy_wav_file,sr=None)
# 计算 nosiy 信号的频谱
S_noisy = librosa.stft(noisy,n_fft=256, hop_length=128, win_length=256) # D x T
D,T = np.shape(S_noisy)
Mag_noisy= np.abs(S_noisy)
Phase_nosiy= np.angle(S_noisy)
Power_nosiy = Mag_noisy**2
print(fs)
# 估计噪声信号的能量
# 由于噪声信号未知 这里假设 含噪(noisy)信号的前30帧为噪声
Mag_nosie = np.mean(np.abs(S_noisy[:,:30]),axis=1,keepdims=True)
Power_nosie = Mag_nosie**2
Power_nosie = np.tile(Power_nosie,[1,T])
## 方法1 直接减
# # 能量减
# Power_enhenc = Power_nosiy-Power_nosie
# # 保证能量大于0
# Power_enhenc[Power_enhenc<0]=0
# Mag_enhenc = np.sqrt(Power_enhenc)
# 幅度减
# Mag_enhenc = np.sqrt(Power_nosiy) - np.sqrt(Power_nosie)
# Mag_enhenc[Mag_enhenc<0]=0
## 方法2 超减
# 引入参数
alpha = 4
gamma = 1
Power_enhenc = np.power(Power_nosiy,gamma) - alpha*np.power(Power_nosie,gamma)
Power_enhenc = np.power(Power_enhenc,1/gamma)
# 对于过小的值用 beta* Power_nosie 替代
beta = 0.0001
mask = (Power_enhenc>=beta*Power_nosie)-0
print(mask.shape)
Power_enhenc = mask*Power_enhenc + beta*(1-mask)*Power_nosie
Mag_enhenc = np.sqrt(Power_enhenc)
# 对信号进行恢复
S_enhec = Mag_enhenc*np.exp(1j*Phase_nosiy)
enhenc = librosa.istft(S_enhec, hop_length=128, win_length=256)
sf.write("enhce_2.wav",enhenc,fs)
print(fs)
# 绘制谱图
plt.subplot(3,1,1)
plt.specgram(clean,NFFT=256,Fs=fs)
plt.xlabel("clean specgram")
plt.subplot(3,1,2)
plt.specgram(noisy,NFFT=256,Fs=fs)
plt.xlabel("noisy specgram")
plt.subplot(3,1,3)
plt.specgram(enhenc,NFFT=256,Fs=fs)
plt.xlabel("enhece specgram")
plt.show()
运行结果如下:
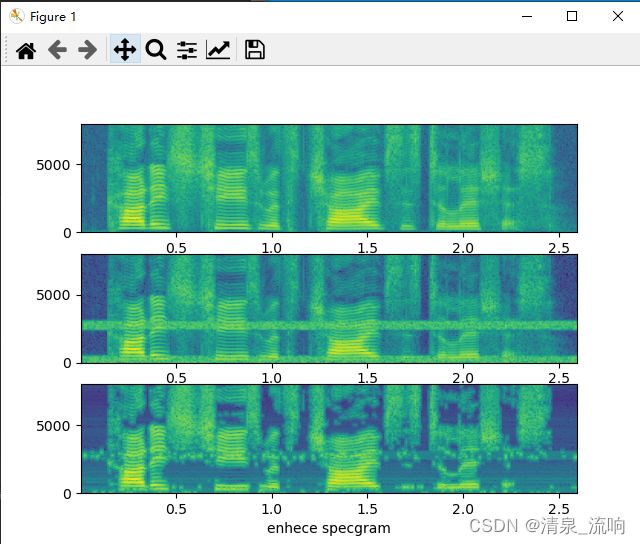
上面的方法会导致谱线的不连续,因此在该方法基础上引入平滑机制。
为了减小音乐噪声,这里介绍引入平滑机制的过减法,相比直接置零,该方法设置了一个谱值下限。在噪声估计阶段,计算一个最大噪声帧,如果谱减后某时频点的值小于最大噪声帧的对应频点值,则将其替换为相邻帧的最小值。具体可表示为:

程序如下:
import librosa
from librosa.core.spectrum import amplitude_to_db
import numpy as np
from scipy.signal import lfilter, firwin, freqz
import soundfile as sf
import matplotlib.pyplot as plt
if __name__ == "__main__":
clean_wav_file = "sf1_cln.wav"
clean,fs = librosa.load(clean_wav_file,sr=None)
print(fs)
noisy_wav_file = "sf1_n0L.wav"
noisy,fs = librosa.load(noisy_wav_file,sr=None)
# 计算 nosiy 信号的频谱
S_noisy = librosa.stft(noisy,n_fft=256, hop_length=128, win_length=256) # D x T
D,T = np.shape(S_noisy)
Mag_noisy= np.abs(S_noisy)
Phase_nosiy= np.angle(S_noisy)
Power_nosiy = Mag_noisy**2
print(fs)
# 估计噪声信号的能量
# 由于噪声信号未知 这里假设 含噪(noisy)信号的前30帧为噪声
Mag_nosie = np.mean(np.abs(S_noisy[:,:31]),axis=1,keepdims=True)
Power_nosie = Mag_nosie**2
Power_nosie = np.tile(Power_nosie,[1,T])
## 方法1 直接减
# # 能量减
# Power_enhenc = Power_nosiy-Power_nosie
# # 保证能量大于0
# Power_enhenc[Power_enhenc<0]=0
# Mag_enhenc = np.sqrt(Power_enhenc)
# 幅度减
# Mag_enhenc = np.sqrt(Power_nosiy) - np.sqrt(Power_nosie)
# Mag_enhenc[Mag_enhenc<0]=0
## 方法2 超减
# # 引入参数
# alpha = 6
# gamma = 1
# Power_enhenc = np.power(Power_nosiy,gamma) - alpha*np.power(Power_nosie,gamma)
# Power_enhenc = np.power(Power_enhenc,1/gamma)
# # 对于过小的值用 beta* Power_nosie 替代
# beta = 0.01
# mask = (Power_enhenc>=beta*Power_nosie)-0
# print(mask.shape)
# Power_enhenc = mask*Power_enhenc + beta*(1-mask)*beta*Power_nosie
# Mag_enhenc = np.sqrt(Power_enhenc)
## 方法3 引入平滑
Mag_noisy_new = np.copy(Mag_noisy)
k=1
for t in range(k,T-k):
Mag_noisy_new[:,t] = np.mean(Mag_noisy[:,t-k:t+k+1],axis=1)
Power_nosiy = Mag_noisy_new**2
# 超减法去噪
alpha = 4
gamma = 1
Power_enhenc = np.power(Power_nosiy,gamma) - alpha*np.power(Power_nosie,gamma)
Power_enhenc = np.power(Power_enhenc,1/gamma)
# 对于过小的值用 beta* Power_nosie 替代
beta = 0.0001
mask = (Power_enhenc>=beta*Power_nosie)-0
Power_enhenc = mask*Power_enhenc + beta*(1-mask)*Power_nosie
Mag_enhenc = np.sqrt(Power_enhenc)
Mag_enhenc_new = np.copy(Mag_enhenc)
# 计算最大噪声残差
maxnr = np.max(np.abs(S_noisy[:,:31])-Mag_nosie,axis =1)
k = 1
for t in range(k,T-k):
index = np.where(Mag_enhenc[:,t]运行结果如下:
