GRU(门控循环单元),易懂。
一、什么是GRU?
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,与LSTM的作用类似,不过比LSTM简单,容易进行训练。
二、GRU详解
GRU模型中有两个门,重置门和更新门,具体作用后面展开说。
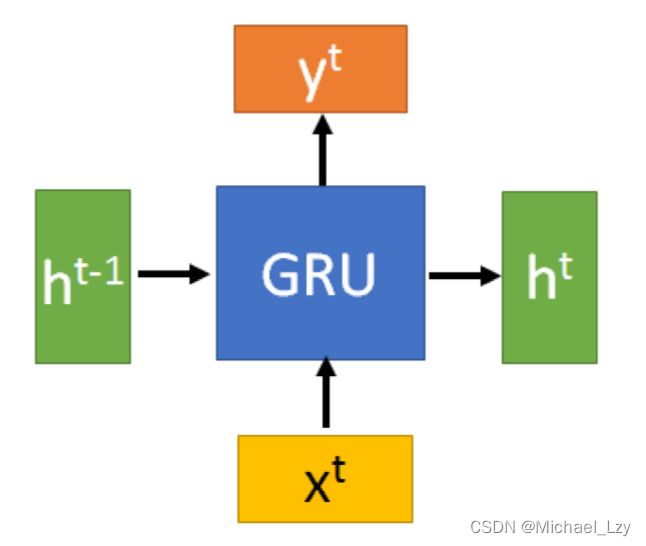
先来看一张GRU的图,看不懂没关系,后面慢慢展开说。

符号说明:
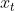 :当前时刻输入信息
:当前时刻输入信息
 :上一时刻的隐藏状态。隐藏状态充当了神经网络记忆,它包含之前节点所见过的数据的信息
:上一时刻的隐藏状态。隐藏状态充当了神经网络记忆,它包含之前节点所见过的数据的信息
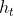 :传递到下一时刻的隐藏状态
:传递到下一时刻的隐藏状态
![]() :候选隐藏状态
:候选隐藏状态
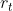 :重置门
:重置门
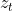 :更新门
:更新门
 :sigmoid函数,通过这个函数可以将数据变为0-1范围的数值。
:sigmoid函数,通过这个函数可以将数据变为0-1范围的数值。
tanh: tanh函数,通过这个函数可以将数据变为[-1,1]范围的数值
先不看内部具体的复杂关系,将上图简化为下图:
结合 和 ,GRU会得到当前隐藏节点的输出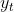 和传递给下一个节点的隐藏状态,这个
和传递给下一个节点的隐藏状态,这个
的推导是GRU的关键所在,我们看一下GRU所用到的公式:

这四个公式互有关联,并不是单独去使用,下面我们详细展开。
1. 重置门
重置门决定了如何将新的输入信息与前面的记忆相结合,这句话猛的一看也不好理解,我们再继续拆解。
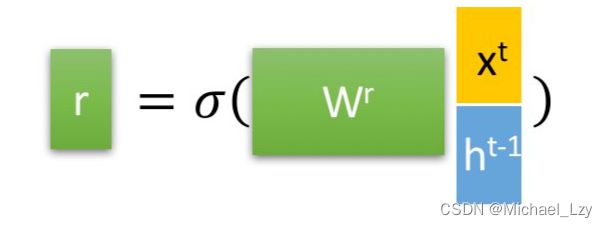
将这个图片转化为公式就是重置门的公式:
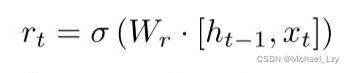
这里![]() 并不是一个值,而是一个权重矩阵。
并不是一个值,而是一个权重矩阵。
用这个权重矩阵对和拼接而成的矩阵进行线性变换(两个矩阵相乘)。然后将两个矩阵相乘得到的值投入sigmoide函数,会得到的值,比如:0.6 。这个值会用到候选隐藏状态的公式中,即下面这个公式:
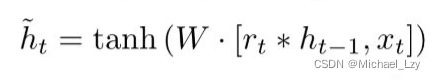
为了方便理解,我们将这个公式展开:
![]()
下面便是重点:
的值越小,它与哈达玛积出来的矩阵数值越小,再与权重矩阵相乘得到的值越小,![]() 也就是这个值越小,
也就是这个值越小,
说明上一时刻需要遗忘的越多,丢弃的越多。
的值越大,![]() 值越大,说明上一时刻需要记住的越多,新的输入信息(也就是当前的输入信息)与前面的记忆相结合的越多。
值越大,说明上一时刻需要记住的越多,新的输入信息(也就是当前的输入信息)与前面的记忆相结合的越多。
当的值接近0时,![]() 值也接近为0,说明上一时刻的内容需要全部丢弃,只保留当前时刻的输入,所以可以用来丢弃与预测无关的历史信息。
值也接近为0,说明上一时刻的内容需要全部丢弃,只保留当前时刻的输入,所以可以用来丢弃与预测无关的历史信息。
当的值接近1时,![]() 值也接近为1,表示保留上一时刻的隐藏状态。
值也接近为1,表示保留上一时刻的隐藏状态。
这就是重置门的作用,有助于捕捉时间序列里短期的依赖关系。
2.更新门
更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,也就是更新门帮助模型决定到底要将多少过去的信息传递到未来,简单来说就是用于更新记忆。结合下面两个公式比较好理解:
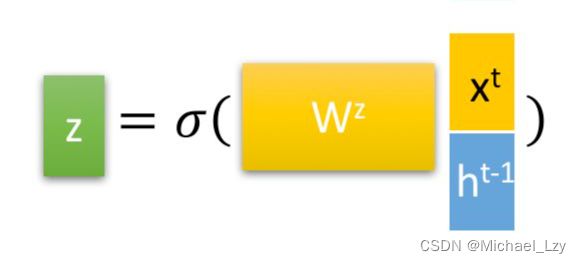
更新门公式:
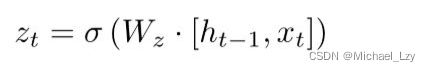
更新记忆表达式:
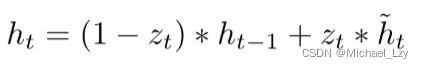
越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
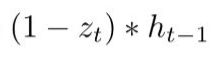 :表示对上一时刻隐藏状态进行选择性“遗忘”。忘记中一些不重要的信息,把不相关的丢弃。
:表示对上一时刻隐藏状态进行选择性“遗忘”。忘记中一些不重要的信息,把不相关的丢弃。
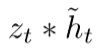 :表示对候选隐藏状态的进一步选择性”记忆“。会忘记
:表示对候选隐藏状态的进一步选择性”记忆“。会忘记 ![]() 中的一些不重要的信息。也就是对
中的一些不重要的信息。也就是对![]() 中的某些信息进一步选择。
中的某些信息进一步选择。
综上,
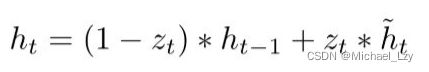
忘记传递下来的 中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
门控循环单元GRU不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元。
参考资料:
人人都能看懂的GRU - 知乎 (zhihu.com)
GRU学习总结_哔哩哔哩_bilibili