pytorch官方教程(详细版)
由于在写DQN代码时发现对细节不够了解,因此又详细学习了一下pytorch相关内容,以下内容来自官网教程,此前的pytorch笔记:
pytorch训练分类器
pytorch基础入门
pytorch实现CartPole-v1任务的DQN代码
(一)Datasets & DataLoaders
处理数据样本的代码可能会变得凌乱,难以维护;理想情况下,我们希望数据集代码与模型训练代码分离,以获得更好的可读性和模块性。PyTorch提供了两种数据原语:torch.utils.data.DataLoader和torch.utils.data.Dataset,允许你使用预加载的数据集以及自己的数据。Dataset 存储样本及其相应的标签,DataLoader将Dataset封装成一个迭代器以便轻松访问样本。PyTorch域库提供了许多预加载的数据集(比如FashionMNIST),属于torch.utils.data.Dataset的子类,并实现指定于特定数据的功能。它们可以用于原型和基准测试你的模型。
加载数据集
这是一个从TorchVision中加载Fashion-MNIST数据集的例子,Fashion MNIST是Zalando文章图片的数据集,包含60000个训练示例和10000个测试示例。每个示例包括一个28×28的灰度图像和一个来自10个类别之一的相关标签。加载FashionMNIST需要以下参数
root:训练/测试数据存储路径train:指定训练或测试数据集download=True:如果在“根目录”中不可用,则从internet下载数据transform和target_transform指定特征和标签变换
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
train_data = datasets.FashionMNIST(root='data',train=True,download=True,transform=ToTensor())
test_data = datasets.FashionMNIST(root='data',train=False,download=True,transform=ToTensor())
迭代和可视化数据集
我们可以像列表一样手动索引Datasets:train_data[index]。使用matplotlib可视化一些训练数据样本
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",}
figure = plt.figure(figsize=(8,8))
cols,rows = 3,3
for i in range(1,cols * rows + 1):
sample_index = torch.randint(len(train_data),size=(1,)).item() # 获取随机索引
img,label = train_data[sample_index] # 找到随机索引下的图像和标签
figure.add_subplot(rows,cols,i) # 增加子图,add_subplot面向对象,subplot面向函数
plt.title(labels_map[label])
plt.axis("off") # 关闭坐标轴
plt.imshow(img.squeeze(),cmap='gray') # 对图像进行处理,cmap颜色图谱
plt.show() # 显示图像

创建自定义数据集文件
自定义数据集类必须包含三个函数:__init__, __len__,和 __getitem__。比如图像存储在img_dir目录里,标签分开存储在一个CSV 文件annotations_file
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self,annotations_file,img_dir,transform = None,target_transform = None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.traget_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
# iloc[:,:]切片,左闭右开,iloc[idx,0]取idx行0列元素
# os.path.join路径连接
img_path = os.path.join(self.img_dir,self.img_labels.iloc[idx,0])
image = read_image(img_path)
label = self.img_labels.iloc[idx,1]
if self.transform:
image = self.transform(image)
if self.traget_transform:
label = self.traget_transform(label)
return image,label
init
__init__函数在实例化Dataset对象时运行一次。我们初始化包含图像、注释文件和两种转换的目录。labels.csv文件内容如下:
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
len
__len__函数返回数据集中的样本数
def __len__(self):
return len(self.img_labels)
getitem
__getitem__函数加载和返回数据集中给定索引idx位置的一个样本。基于索引,它识别图像在磁盘上的位置,使用read_image将其转换为张量,从self.img_labelscsv数据中检索相应的标签。调用其上的变换函数(如果适用),并以元组形式返回张量图像和相应标签。
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
使用DataLoaders预备训练数据
Dataset一次检索一个样本的数据集特征和标签,在训练模型时,我们通常希望以“小minibatches”的方式传递样本,在每个epoch重新排列数据以减少模型过度拟合,并使用Python的multiprocessing加速数据检索。DataLoader 是一个迭代器能实现上面功能
from torch.utils.data import DataLoader
# shuffle如果设置为True,则会在每个epoch重新排列数据
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
通过DataLoader进行迭代
已经将数据加载到DataLoader,能够迭代遍历数据集,每次迭代都会返回批量(batch_size=64)的train_features和train_labels,设置了shuffle=True,在我们迭代所有batches之后,数据被洗牌(以便对数据加载顺序进行更细粒度的控制)
train_features,train_labels = next(iter(train_dataloader))
print(f'feature batch shape:{train_features.size()}')
print(f'label batch shape:{train_labels.size()}')
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img,cmap='gray')
plt.show()
print(f'label:{label}')
feature batch shape:torch.Size([64, 1, 28, 28])
label batch shape:torch.Size([64])
label:4
(二)Transforms
数据并不总是以训练机器学习算法所需的最终处理形式出现。我们使用transforms对数据进行一些操作,使其适合训练。所有的TorchVision数据集都有两个参数transform(修正特征),target_transform(修正标签),torchvision.transforms模块提供了几种常用的转换。
FashionMNIST特征是PIL图像形式, 标签是整数。为了训练,需要把特征作为归一化张量,标签作为一个one-hot编码张量。使用ToTensor 和Lambda实现
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
ToTensor( )
ToTensor将一个PIL image或者NumPy 数组ndarray变成浮点型张量FloatTensor,在[0,1]范围内缩放图像的像素强度值
Lambda Transforms
Lambda transforms应用任何用户定义的Lambda函数,此处定义了一个函数将整数变成one-hot编码张量,首先创建一个大小为10(标签数)的全0张量,然后调用scatter_ 在标签y的索引位置上将值修改为1
target_transform = Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1))
Tensor.scatter_(dim, index, src, reduce=None)在dim维度上,找到index对应的元素,将值换成src
print(torch.zeros(10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(3), value=1))
tensor([0., 0., 0., 1., 0., 0., 0., 0., 0., 0.])
(三)构建神经网络
使用pytorch构建神经网络进行FashionMNIST数据集中的图像分类
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('using {} device'.format(device))
using cpu device
定义神经网络类
继承nn.Module构建神经网络,包括两个部分
__init__:定义网络层forward:执行前向传播
class network(nn.Module):
def __init__(self):
super(network, self).__init__()
self.flatten = nn.Flatten() # 将连续范围的维度拉平成张量
self.layers = nn.Sequential(
nn.Linear(28*28,512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10))
def forward(self,x):
x = self.flatten(x) # 输入到网络中的是(batch_size,input)
values = self.layers(x)
return values
torch.nn.Flatten(start_dim=1, end_dim=- 1)默认只保留第一维度
-
start_dim:first dim to flatten (default = 1).
-
end_dim:last dim to flatten (default = -1).
# torch.nn.Flatten示例
input = torch.randn(32,1,5,5)
m = nn.Flatten()
output = m(input)
print(output.size())
m1 = nn.Flatten(0,2)
print(m1(input).size())
torch.Size([32, 25])
torch.Size([160, 5])
创建一个network实例并移动到 device,输出结构
model = network().to(device)
print(model)
network(
(flatten): Flatten(start_dim=1, end_dim=-1)
(layers): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
遍历输入数据,执行模型前向传播,不用直接调用forward
x = torch.rand(2,28,28,device=device)
value = model(x)
print(value)
print(value.size())
pred_probab = nn.Softmax(dim=1)(value)
print(pred_probab)
y_pred = pred_probab.argmax(1)
print(f'predicted class:{y_pred}')
tensor([[-0.0355, 0.0948, -0.1048, 0.0802, 0.0177, 0.0038, -0.0281, -0.0767,
0.0303, -0.1290],
[-0.0238, 0.1298, -0.0700, 0.0861, 0.0168, -0.0418, -0.0421, -0.0772,
0.0369, -0.1391]], grad_fn=)
torch.Size([2, 10])
tensor([[0.0977, 0.1113, 0.0912, 0.1097, 0.1030, 0.1016, 0.0984, 0.0938, 0.1043,
0.0890],
[0.0986, 0.1149, 0.0941, 0.1100, 0.1027, 0.0968, 0.0968, 0.0935, 0.1048,
0.0878]], grad_fn=)
predicted class:tensor([1, 1])
torch.nn.Softmax(dim=None)softmax归一化
# torch.nn.Softmax示例
m = nn.Softmax(dim=1)
input = torch.randn(2,3)
print(input)
output = m(input)
print(output)
tensor([[-0.5471, 1.3495, 1.5911],
[-0.0185, -0.1420, -0.0556]])
tensor([[0.0619, 0.4126, 0.5254],
[0.3512, 0.3104, 0.3384]])
模型结构层
拆解模型中的层次,观察输入和输出
原始输入
input_image = torch.rand(3,28,28)
print(input_image.size())
torch.Size([3, 28, 28])
nn.Flatten
将2维的28✖️28图像变成784像素值,batch维度(dim=0)保留
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
torch.Size([3, 784])
nn.Linear
线性转换
layer1 = nn.Linear(in_features=28*28,out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size( ))
torch.Size([3, 20])
nn.ReLU
非线性修正单元(激活函数)
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
print(hidden1.size())
Before ReLU: tensor([[ 0.4574, -0.5313, -0.4628, -0.9403, -0.7630, 0.1807, -0.2847, -0.2741,
0.0954, 0.2327, 0.4603, 0.0227, -0.1299, -0.2346, -0.1800, 0.9115,
-0.0870, -0.0171, -0.0064, 0.0540],
[ 0.0888, -0.6782, -0.2557, -0.6717, -0.4488, 0.1024, -0.3013, -0.3186,
-0.1338, 0.3944, 0.0704, 0.1429, 0.0521, -0.3326, -0.3113, 0.6518,
-0.0978, -0.0721, -0.3396, 0.4712],
[ 0.1781, 0.0885, -0.4775, -0.5661, -0.0099, 0.2617, -0.2678, -0.1444,
0.1345, 0.3259, 0.3984, 0.2392, 0.0529, -0.0349, -0.3266, 0.7488,
-0.3498, 0.1157, 0.0126, 0.3502]], grad_fn=)
After ReLU: tensor([[0.4574, 0.0000, 0.0000, 0.0000, 0.0000, 0.1807, 0.0000, 0.0000, 0.0954,
0.2327, 0.4603, 0.0227, 0.0000, 0.0000, 0.0000, 0.9115, 0.0000, 0.0000,
0.0000, 0.0540],
[0.0888, 0.0000, 0.0000, 0.0000, 0.0000, 0.1024, 0.0000, 0.0000, 0.0000,
0.3944, 0.0704, 0.1429, 0.0521, 0.0000, 0.0000, 0.6518, 0.0000, 0.0000,
0.0000, 0.4712],
[0.1781, 0.0885, 0.0000, 0.0000, 0.0000, 0.2617, 0.0000, 0.0000, 0.1345,
0.3259, 0.3984, 0.2392, 0.0529, 0.0000, 0.0000, 0.7488, 0.0000, 0.1157,
0.0126, 0.3502]], grad_fn=)
torch.Size([3, 20])
nn.Sequential
nn.Sequential 是一个模块的有序容纳器,数据按照定义的顺序传递给所有模块
seq_modules = nn.Sequential(flatten,layer1,nn.ReLU(),nn.Linear(20,10))
input_image = torch.randn(3,28,28)
values1 = seq_modules(input_image)
print(values1)
tensor([[ 0.2472, 0.2597, -0.0157, 0.3206, -0.0073, 0.1631, 0.2956, 0.0561,
0.2993, 0.1807],
[-0.0782, 0.1838, -0.0215, 0.2395, -0.0804, -0.0021, 0.0883, -0.0698,
0.1463, -0.0151],
[-0.1162, 0.0673, -0.2301, 0.1612, -0.1472, -0.0447, 0.0671, -0.2915,
0.3176, 0.2391]], grad_fn=)
nn.Softmax
神经网络的最后一个线性层返回原始值在[-\infty, \infty],经过nn.Softmax模块,输出值在[0, 1],代表了每个类别的预测概率,dim参数表示改维度的值总和为1
softmax = nn.Softmax(dim=1)
pred_probab1 = softmax(values1)
print(pred_probab1)
tensor([[0.1062, 0.1075, 0.0816, 0.1143, 0.0823, 0.0976, 0.1115, 0.0877, 0.1119,
0.0994],
[0.0884, 0.1148, 0.0935, 0.1214, 0.0882, 0.0954, 0.1044, 0.0891, 0.1106,
0.0941],
[0.0872, 0.1048, 0.0778, 0.1151, 0.0845, 0.0937, 0.1048, 0.0732, 0.1346,
0.1244]], grad_fn=)
模型参数
使用parameters()和named_parameters()能获取每层的参数,包括weight和bias
print(f'model structure:{model}\n')
for name,param in model.named_parameters():
print(f'layer:{name}|size"{param.size()}|param:{param[:2]}\n')
#print(model.parameters())
model structure:network(
(flatten): Flatten(start_dim=1, end_dim=-1)
(layers): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
layer:layers.0.weight|size"torch.Size([512, 784])|param:tensor([[ 0.0122, -0.0204, -0.0185, ..., -0.0196, 0.0257, -0.0084],
[-0.0066, -0.0195, -0.0199, ..., -0.0175, -0.0007, 0.0003]],
grad_fn=)
layer:layers.0.bias|size"torch.Size([512])|param:tensor([0.0086, 0.0104], grad_fn=)
layer:layers.2.weight|size"torch.Size([512, 512])|param:tensor([[-0.0306, -0.0408, 0.0062, ..., 0.0289, -0.0164, 0.0099],
[ 0.0015, 0.0052, 0.0182, ..., 0.0431, -0.0174, 0.0049]],
grad_fn=)
layer:layers.2.bias|size"torch.Size([512])|param:tensor([-0.0337, 0.0294], grad_fn=)
layer:layers.4.weight|size"torch.Size([10, 512])|param:tensor([[ 0.0413, 0.0015, 0.0388, ..., 0.0347, 0.0160, 0.0221],
[-0.0010, 0.0031, 0.0421, ..., -0.0226, 0.0340, -0.0220]],
grad_fn=)
layer:layers.4.bias|size"torch.Size([10])|param:tensor([0.0210, 0.0243], grad_fn=)
(四)自动差分 torch.autograd
训练神经网络使用最频繁的算法是反向传播back propagation,参数(model weights)根据损失函数的梯度gradient进行调整。为了计算梯度,pytorch内置了
差分引擎torch.autograd,支持任何一个计算图的梯度计算,以最简单的单层神经网络为例,输入x,参数w和b和一些损失函数,
import torch
x = torch.ones(5) # 输入张量
y = torch.zeros(3) # 预期输出
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
print(loss)
tensor(2.2890, grad_fn=)
张量,函数,计算图
代码定义了如下的计算图 computational graph:
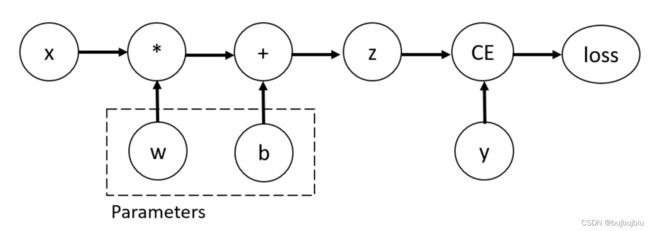
w 和 b 是需要优化的参数,因此需要计算这些变量各自对损失函数的梯度,设置张量的requires_grad属性
可以在创建一个张量的时候设置requires_grad的值,或者之后使用x.requires_grad_(True)方法,用在张量上实现前向传播和反向传播的函数是类Function的实例,反向传播函数存储在张量的grad_fn属性上
print(f'gradient function for z={z.grad_fn}\n')
print(f'gradient function for loss={loss.grad_fn}\n')
gradient function for z=
gradient function for loss=
计算梯度
为了优化网络参数的权重,需要计算x 和 y固定值下损失函数对各参数的导数 ∂ l o s s ∂ w \frac{\partial loss}{\partial w} ∂w∂loss和 ∂ l o s s ∂ b \frac{\partial loss}{\partial b} ∂b∂loss ,为了计算这些导数,需要调用loss.backward(),通过w.grad和b.grad获取梯度值
loss.backward()
print(w.grad)
print(b.grad)
tensor([[0.3263, 0.0754, 0.3122],
[0.3263, 0.0754, 0.3122],
[0.3263, 0.0754, 0.3122],
[0.3263, 0.0754, 0.3122],
[0.3263, 0.0754, 0.3122]])
tensor([0.3263, 0.0754, 0.3122])
只能获取计算图叶子节点的grad属性,其requires_grad设置为true,对于其它节点,梯度不可获取;出于性能原因,只能在给定的图形上使用“backward”进行一次梯度计算。如果要在同一个图上执行好几次“backward”调用,将“retain_graph=True”传递给“backward”调用
禁用梯度跟踪
设置requires_grad=True的张量会追踪计算历史并且支持梯度计算,但是某些情况下,不需要这么做,比如模型已经完成训练后,将其应用在输入数据上,只需执行前向传播forward,可以通过torch.no_grad()阻止跟踪计算
z = torch.matmul(x,w) + b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x,w) + b
print(z.requires_grad)
True
False
另一种有同样效果的方法是对张量使用detach()
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
False
禁用梯度跟踪有以下原因:
- 将神经网络中的一些参数标记为frozen parameters,在微调预训练网络中比较常见
- 只进行前向传播中加速计算speed up computations,没有梯度跟踪的向量计算更高效
计算图Computational Graphs
从概念上讲,autograd在由函数对象组成的有向无环图(DAG)中记录数据(张量)和所有执行的操作(以及生成的新张量)。在这个DAG中,叶是输入张量,根是输出张量。通过从根到叶追踪此图,可以使用链式规则自动计算梯度
在前向传播中,autograd自动做两件事:
- 运行请求的操作以计算结果张量
- 在DAG中保留操作的梯度函数gradient function
DAG根的.backward()被调用时,autograd :
- 依照每个
.grad_fn计算梯度 - 将其累计到各自张量的
.grad属性中 - 使用链式规则传播到叶张量
DAGs are dynamic in PyTorch,图表是从头开始创建的,在调用.backward()后,autograd开始填充新图形,这也是模型中能使用控制流语句的原因,在每次迭代,都可以改变形状,大小和操作
(五)优化模型参数
有了模型和数据后需要通过优化参数进行模型训练,验证和测试。训练模型是一个迭代的过程,每次迭代(也叫一个epoch),模型会对输出进行预测,计算预测误差(loss),收集误差对各参数的导数。使用梯度下降优化这些参数。
之前数据加载和神经网络代码:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
train_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.layers = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
values = self.layers(x)
return values
model = NeuralNetwork()
超参数Hyperparameters
超参数是可调整的参数,用来控制模型优化过程,不同的超参数值能影响模型训练和收敛速度
定义如下的超参数用于训练:
- Number of Epochs:迭代次数
- Batch Size:参数更新前通过网络传播的数据样本数量
- Learning Rate:学习率
learning_rate = 1e-3
batch_size = 64
epochs = 5
优化循环Optimization Loop
一旦设定了超参数,可以通过一个优化循环来训练和优化我们的模型。优化循环的每次迭代称为epoch。每个epoch包括两个主要的部分:
- The Train Loop:迭代训练数据集,并尝试收敛到最佳参数。
- The Validation/Test Loop:迭代测试数据集,检查模型性能是否正在改善。
loss function
当面对一些训练数据时,我们未经训练的网络可能不会给出正确的答案。损失函数衡量获得的结果与目标值的不同程度,我们希望在训练过程中最小化损失函数。为了计算损失,我们使用给定数据样本的输入进行预测,并将其与真实数据标签值进行比较。
普通的损失函数包括适合回归任务的nn.MSELoss(均方误差),适合分类的nn.NLLLoss(负对数似然),nn.CrossEntropyLoss结合了nn.LogSoftmax和nn.NLLLoss。此处使用nn.CrossEntropyLoss
# 初始化损失函数
loss_fn = nn.CrossEntropyLoss()
Optimizer
优化是在每个训练步骤中调整模型参数以减少模型误差的过程。优化算法定义了该过程的执行方式(在本例中使用随机梯度下降)。所有优化逻辑都封装在优化器对象中。这里使用SGD优化器;此外,pytorch中有许多不同的优化器,例如ADAM和RMSProp,它们可以更好地用于不同类型的模型和数据。
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
训练循环中,优化主要有三个步骤:
- 调用
optimizer.zero_grad()重置模型参数的梯度,梯度默认会累积,为了阻止重复计算,在每次迭代都会清零 - 调用
loss.backward()进行反向传播 - 一旦有了梯度,就调用
optimizer.step()来调整各参数值
训练循环和测试循环
定义train_loop训练优化,定义test_loop评估模型在测试集的表现
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集数据总量
for number, (x, y) in enumerate(dataloader):
# number迭代次数,每次迭代输入batch=64的张量(64,1,28,28)
# 计算预测和误差
pred = model(x)
loss = loss_fn(pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if number % 100 == 0:
# 每迭代100次,输出当前损失函数值及遍历进度
loss, current = loss.item(), number * len(x) # current当前已经遍历的图像数,len(x)=batch_size
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集总量
num_batches = len(dataloader) # 最大迭代次数
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
pred = model(x)
test_loss += loss_fn(pred, y).item()
# 输出如:test_loss=torch.tensor(1.0873)
# pred.argmax(1)返回值最大值对应的位置,sum()求批量的正确数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches # 单次迭代的误差总和/总迭代次数=平均误差
correct /= size # 单次迭代的正确数总和/数据总量=准确率
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
print(len(train_dataloader.dataset))
print(len(train_dataloader))
print(len(test_dataloader.dataset))
print(len(test_dataloader))
x,y = next(iter(train_dataloader))
print(len(x))
print(x.size())
print(y.size())
60000
938
10000
157
64
torch.Size([64, 1, 28, 28])
torch.Size([64])
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 2
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done!")
Epoch 1
-------------------------------
loss: 1.040251 [ 0/60000]
loss: 1.070957 [ 6400/60000]
loss: 0.869483 [12800/60000]
loss: 1.033000 [19200/60000]
loss: 0.908716 [25600/60000]
loss: 0.930925 [32000/60000]
loss: 0.973219 [38400/60000]
loss: 0.913604 [44800/60000]
loss: 0.960071 [51200/60000]
loss: 0.904625 [57600/60000]
Test Error:
Accuracy: 67.1%, Avg loss: 0.911718
Epoch 2
-------------------------------
loss: 0.952776 [ 0/60000]
loss: 1.005409 [ 6400/60000]
loss: 0.788150 [12800/60000]
loss: 0.969153 [19200/60000]
loss: 0.852390 [25600/60000]
loss: 0.862806 [32000/60000]
loss: 0.920238 [38400/60000]
loss: 0.863878 [44800/60000]
loss: 0.903000 [51200/60000]
loss: 0.858517 [57600/60000]
Test Error:
Accuracy: 68.3%, Avg loss: 0.859433
Done!
(六)保存和加载模型
最后了解如何通过保存、加载和运行模型预测来保持模型状态。torchvision.models子包包含用于处理不同任务的模型定义,包括:图像分类、像素语义分割、对象检测、实例分割、人物关键点检测、视频分类和光流。
import torch
import torchvision.models as models
保存和加载模型权重
pytorch将学习的参数存储在内部状态字典中,叫做state_dict,这些能通过torch.save方法被保留
# vgg16是一种图像分类的模型结构
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
model = models.vgg16(pretrained=True) # 以vgg16模型为例
torch.save(model.state_dict(), 'model_weights.pth')
要加载模型权重,需要先创建同一模型的实例,然后使用load_state_dict()方法加载参数
model = models.vgg16() # 不指定 pretrained=True,也就是不加载默认参数
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
在预测前一定要先调用model.eval()方法来设置dropout和batch normalization层为评估模型,否则会导致不一致的预测结果
保存和加载模型
加载模型权重时,我们需要首先实例化模型类,因为该类定义了网络的结构。为了将这个类的结构与模型一起保存,可以将model(而不是model.state_dict())传递给保存的函数:
torch.save(model, 'model.pth')
加载模型:
model = torch.load('model.pth')
这种方法在序列化模型时使用Python的pickle模块,因此它依赖于加载模型时可用的实际类定义。