rtmp直播如何实现200ms内级别延迟?
直播技术框架简介
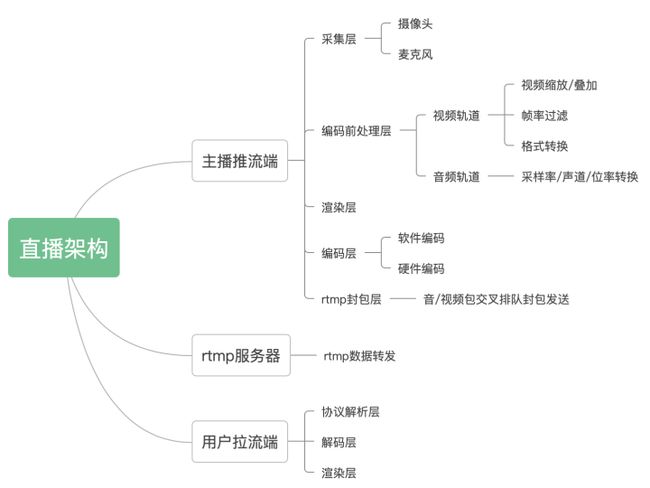
目前最流行的直播技术方案是基于ffmpeg+rtmp,本轮重点讨论的也是此项方案.直播框架总体分为三大部分:主播推流端/rtmp服务器/播放拉流端,其结构如下导图所示:
延时分析
需要做到200ms内低延迟,甚至100ms内延时,前提是需要将复杂应用模型转换为极简技术模型,只有解决了极简模型的低延时处理,复杂模型可以根据多增加的每一个因素去逐步优化,最后评估整体方案的平均延时,本文约定测试前提为下:
1.数据流模型信息:单路720p@25 1200kbps视频流+44100双声道16比特率AAC音频流
2.延迟时间路径:从主播推送端渲染显示层→流媒体服务器→用户拉流端渲染层之间延时计算
即ffmpeg直播rtmp方案在上述约定下实现200ms内直播通讯.
从直播架构上图可以分析到,直播的延迟主要有存在以下几处地方:
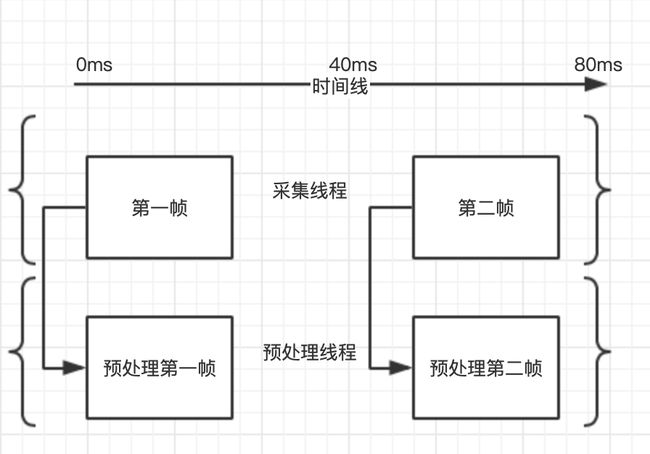
1.数据采集延时,要确保低延时,摄像头输入仅能选取非网络及非编码类本地uvc驱动摄像头,及普通usb或者笔记本自带摄像头.摄像头数据输出需要支持720p@25 yuv420p数据输出,这样可以使数据进入到编码前处理线程时候,0性能损耗直接输出720p@25yuv420p至编码层和渲染层.即数据采集延时理论上可以达到0延时,当然我们忽略了设备硬件的输出延迟.简单得出数据采集线程处理时间<=40ms
2.编码前处理阶段延迟.此阶段由于本文已假设输入数据为720p@25 yuv420p,故不需要额外做耗时操作,仅需进行数据拷贝即可.即编码前处理阶段总延迟0(ps:由于本文仅讨论极简模型,实际项目应用会有常见的画面混合,丢帧/补帧,音频升降采样及数据格式转换等处理,这些处理有可能需要消耗掉大量时间,很多项目有时候性能瓶颈也在此阶段,但有个衡量标准为,只要所有音视频耗时操作时间,保障低于帧率时间间隔,即认为0延迟,因为25帧视频流,每帧帧间间隔大致维持再1000ms/25即40ms左右,如果在采集层下一帧到达前处理完毕,即实现多线程异步加速处理.我在实际项目使用情况中,由于医疗pc终端为定制机器,实际测试双路流混合/丢帧/补帧/及音频数据处理总时长都可稳定保障在40ms内完成)
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
如上图,假设采集线程在0ms读取到第一帧,则直接拷贝到预处理线程,预处理线程在40ms内处理完耗时操作,采集线程延迟等待40ms后读取第二帧,即完成多线程异步操作.简单得编码前处理线程处理时间<=40ms
3.编码延迟,视频编码有硬件编码和软件编码区分,这里我们重点讲软编方式,要实现零延时编码需要开启zerolatency选项,具体测试见编码吞帧问题分析,从文中结果可见,编码器最少吞一帧
4.封包同步延迟,此阶段为需要对两个音视频轨道avpacket进行排序发送策略,即pts小的包优先网络发送,由于需要比对avpacket的pts大小,故队列里面至少需要有一个音频包和视频包,假设视频优先弹出,等待下一个音频包默认最大延迟间隔为一个音频包时间1024000/44100=23.2ms,简单得出封包线程处理延迟为0ms~23.2ms
5.网络延迟,包含主播端到服务器,服务器下发到拉流端延迟.此延迟跟网络状况有关系,我们默认网络rtt延迟为20ms,刚好为一个rtt时长
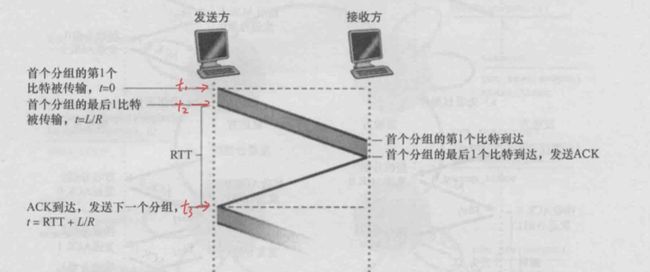
我们假定rtt为20ms即上图t3-t2时间(20ms rtt在局域网和公网情况都是比较常见情况,另外说明下,只要网络带宽是足够情况下,例如1M带宽不发送超过128kb/s速率发送数据,理论上所有数据tcp分包后的每个mtu单元延迟都在rtt时间附近,即在相应带宽范围内,不存在降低直播视频码率的视频流延迟比高码率视频流延迟要低)
6.流媒体服务器缓冲延迟(由于作者没有开发及优化过流媒体服务器,只拿了常规nginx服务器建设rtmp服务器,故暂时未知nginx的缓存策略,欢迎后台流媒体人员一起交流,不过作者根据实验结果做了下排除分析,rtmp服务器实际只是一个流转发服务器,即只需将收到的数据进行转发即可,不需要缓冲到一定数量再下发,所以我认为服务器延迟是极低的 几乎0ms,看拷贝速度了,当然服务器的关键帧缓存策略也不影响整体延迟,关键帧只需拷贝保存而已.当然这里服务器架构也是极简模式,不存在服务器做分布式架构设计/流录制/黄反分析策略等
7.拉流端协议解析延迟.我们知道h264解码的前提条件为需要一个完整的I帧才可解码,一般情况下ffmpeg在做rtmp流的avformat_find_stream_info时候往往会卡顿比较久的时间,这里我们先熟悉下行业常说的首帧秒开技术优化.
秒开策略,秒开策略即客户端从点击拉取开始计算,rtmp流经过解析/解码/渲染显示保正在1s内为秒开策略.秒开策略优化有几个主要的优化点:
服务器关键帧缓存策略:在单个视频流gop区间,客户端可能在任意时间节点拉取流,如果运气不好 刚好在第一个i帧后请求,则客户端需要等待一个gop时间才能解析到下一个I帧,造成首帧解析卡顿,为了弥补这个问题,业务上可以在服务器缓存当前gop的关键帧,新用户解析流时候保障先拿到I帧在获取当前时间的b/p帧,则可以大大提高解析时间
推流端降低gop间隔策略:根据上面分析可以很容易得出,缩短gop时间,可以很明显提高客户端首帧关键帧解析等待时间
拉流端probesize调节策略:假设客户端解析的数据包长度刚好是一个nalu单元,完整的包含一个I帧信息,即avformat_find_stream_info可立即返回,但实际情况不可能这么完美,ffmpeg内部解析数据方式可以根据指定时间和数据长度两种方式进行,probesize调节策略即在avformat_find_stream_info前尝试设置AVFormatContext.probesize长度,进行尝试解码,如果解码失败则加长probesize长度进行循环解析,直到刚好被解析的数据包含一个I帧,avformat_find_stream_info返回成功,调整解析时间长度理论上同理长度调节策略.以上两种方式都可以大幅加快avformat_find_stream_info解析接口延迟.
拉流端零延迟解码模式策略:解码器跟编码器类似,也有默认帧缓冲策略,开启0延时解码模式后,解码器最高可以缓存0帧模式输出.
拉流端渲染数据优化:在拿到解码器首帧yuv420sp数据后,常规做法为转换rgba数据再发送opengl渲染,此处我们建议直接将yuv数据推入gpu,让gpu进行rgba转换及渲染.(原因分析:1yuv转换为rgba在gpu处理可以空闲出大量cpu时间.2.yuv数据从内存直接复制到显存比rgba数据复制到显示,数据量要小2.5倍(yuv带宽为1.5x/rgba为4x)左右,所以相对而言性能大大提高)
经过秒开策略分析,笔者尝试了主播端和拉流端优化首开策略,发现效果非常好,理论上首开延迟波动在0ms~500ms.
8.解码延迟,经过拉流端零延迟解码模式策略分析,我们可以简单得出解码处理线程时间为<=40ms
9.播放渲染延迟,同上分析,拉流端渲染数据优化,我们可以简单得出渲染线程处理时间<=40ms
10.tcp累积延迟:由于rtmp基于tcp方式传输,tcp收发两端都有数据缓冲区设计,在网络波动后,两端缓冲区都会堆积满,进而影响ffmpeg中av_interleaved_write_frame同步发送时间,由于整体架构各阶段线程都有ringbuffer机制,经过网络抖动及拥塞会造成各个线程节点的环形队列都有可能填充满数据,即我们常说的tcp累计延迟.针对这个问题我们需要给直播方案设计一个丢帧率策略或简易宽带预估策略
丢帧策略:在tcp累计延迟触发时候,我们可以很容易得知编码前处理线程缓冲队列数据是否上升还是下降,参考tcp拥塞处理机制,如果buffer上升到一半阈值,则把最大值下降一半,所有buffer清空处理,待buffer数量稳定时候,再提升最大值阈值,此策略处理方式比较极端,会再网络波动的时候 通过丢掉多个连续的数据样本,拉流端可能会出现画面跳帧现象,但快速的恢复了低延迟的特性,在手术示教的低延迟要求需求定位下,低延迟相对于画面抖动是优先级最高的
简易宽带预估策略:此策略参考webrtc策略,在此基础上,笔者设计了在丢帧策略情况出发时候,进行帧率调节及码率调节,如果丢帧策略触发频率在某阈值1x的情况下,优先通知编码器做低帧率处理,线性降低25帧到10帧左右,如果触发频率在阈值x2情况下,则降低编码器输出分辨率,由720p只540p只270p多个等级线性下降
经过上述丢帧策略和宽带预估策略,我们可以再直播过程中出现网络波动时候以画面抖动/低帧率/低画质模式适应从强到弱的网络适配,总结由于直播低延时策略前提肯定在网络正常且较稳定环境得出,故我们只需要考虑常规tcp发送缓冲区和接受缓冲区大小,tcp缓冲区最大为65535字节,以1200kbps码率流为参考,两端累计最大延迟大概为1s,网络正常或较稳定情况下 我们假定延迟为20ms到80ms比较合理,预留给tcp充分时间做数据重排和重发
直播方案延迟计算分析
经过直播整体架构各节点延迟项分析,由于采用多线程方案设计,我们把各个线程低于40ms处理能力的线程认为0延迟,故延迟点计算在于:
硬件设备延迟:简单定义5到10ms 取最大值10ms
编码吞1帧造成延迟:40ms
封包延迟:0~23ms取中间值 12ms
网络传输延迟:rtt20ms
tcp累计延迟:20ms~80ms 取中间值50ms
得出结论延迟波动范围为:97ms~130ms,常态化延迟大概为162ms
补充:由于实际应用我们忽略了各类线程调度影响,各阶段的ringbuffer有可能都存在缓冲1到2帧,所以实际情况下直播延迟波动范围应该在上述范围基础上上升40ms~80ms即137ms~210ms
总结
针对rtmp直播低延迟技术方案技术细节基本已补充完毕,以上观点都是在项目实战中逐渐摸索得出,由于本文提出的大量延迟数据都为量化数据,实际上作者也没有对每一个线程每一个阶段进行非常严格的量化测试,故数据都可能存在一定的偏差,但是从最终项目上线情况来看,效果总体延迟时间是可见的,误差范围不会太大,如果有明显错误遗漏,也希望大家指出,下一篇博客我会整理下低延迟的c++测试工具并分享出来,写好测试教程供大家进一步研究与分析.
补充说明
问题1:根据群友提出的关于从采集到网络发包线程间内存拷贝几次问题
主播端和拉流端都进行了大量的多线程设计,各线程数据交互间由一个自定义大小的ringbuffer管理,线程间交互的数据一般只有avframe和avpacket结构,实际的线程数据交互只是交换avframe指针和avpacket指针,不存在实际数据内存的拷贝.另外一个由于avframe和avpacket数据都默认分配在堆内存上.下游线程使用完后,需要进行手动释放.当然ffmpeg也支持ref和unref模式,理论线程交换性能会更高
本文福利, 免费领取C++音视频学习资料包、技术视频,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓