手撕C语言标准库qsort(自我实现简化高效版C风格泛型快排)
文章目录
-
- 查看源代码的网址(我自己写的)
- 如果还不懂快排,推荐看看我很久以前写的一篇博客
- 具体实现细节
-
- 第一:void指针的使用
- 第二:回调函数实现
- 完整qsort实现
- 简单效率验证
-
- 本地验证
-
- 排序的元素类型 和 初始化
- 本地 效率测试
- LeetCode平台验证(912.排序数组)
查看源代码的网址(我自己写的)
- 如果对快排足够熟练可以直接来看看这源码。
这是我GitHub仓库对应的GitHub1s网址链接:
GitHub1s在线查看源码
如果还不懂快排,推荐看看我很久以前写的一篇博客
这里是几种logn排序的比较
虽然只写了实现代码
你可以根据看到过的快排的动画过程(哔哩哔哩一大堆),然后看看我这个代码实现即可,快排有很多种,我这只是最简单的两类。
具体实现细节
由于C语言缺少泛型的现代语法支持,不像C++有泛型模板,所以底层的代码复用一般采取 void 指针的方式,如果需要外界的控制则采取函数指针,然后通过回调函数实现外界控制的功能,而 qsort 就是利用的这一逻辑,用第四个参数传递函数指针,实现外界的函数控制。
第一:void指针的使用
- 想要实现C的通用函数库,一般都是把指针转为void类型,然后再根据传入的数据长度,用一个字节的char类型指针对每个元素进行操作。
比如实现 qsort 时里面所需要的 swap 函数。
- 这个swap的实现是通过qsort里面把void类型的指针转char类型再传入即可。
void swap(char *a, char *b, int width) {//把一块width大小的内存分成一个字节的换
char tmp;
if (a != b) {//不是同一片内存才开始交换
while (width--) {
tmp = *a;
*a++ = *b;
*b++ = tmp;
}
}
}
第二:回调函数实现
根据C标准的函数库来看:
- 如果按照
return a-b;则返回负值也就是aa>b返回负数的时候,那么它就会以从大到小的次序进行排序了!
讲实话,这个判断函数只需要两个状态即可,是否已经排好序,或者是没有排好序,所以完全可以直接一个 bool 型通过 0 和 1 来表示是否已经拍好,而负数则完全没有必要。暂时不清楚C标准库为什么一般都是采取负数 0 正数的方式来比较,可能是这种方式能够准确的直接通过返回值来判断两个数是 '<' or '>' or '=' 而只返回 0 和 1 则只能判断一个表达式是否正确。但在排序这里完全可以只采取 0 和 1,毕竟只需要清楚是否为正确次序即可,所以C++的 sort 都是通过直接的返回 bool 表达式来进行判断。
对应代码实现
只把用到了compar 回调函数的部分拎出来了,cmp 是作为排序的基准数,而base通过指针移位到不同的位置来与 cmp 进行判断,cmp 左边都应该小于等于它,cmp 右边都应该大于等于它。关于快排为什么会不稳定,就是因为它会在两者相等的时候停住进行数据交换,这样就无法按照开始插入的顺序进行排序,也就是可能开始插入的顺序中有紧挨着的几个相等元素,而快排可能会将他们进行数据交换。
外界函数实现
从这里
strcmp的使用就应该能从一个角度来切入为什么qsort采取int返回来控制,毕竟这样可以兼容strcmp等一众函数。
#include 内部调用(部分我实现源码)
while (tl <= tr) {
while (compar(base + (tl * size), cmp) < 0)tl++;//实际上可以直接根据0和1确定如何排序,然而C标准似乎是还需要利用到负数
while (compar(cmp, base + (tr * size)) < 0)tr--;
if (tl <= tr) {
swap(base + (tl * size), base + (tr * size), size);
tl++;
tr--;
}
}
完整qsort实现
推荐用GitHub1s在线查看,毕竟查看的各种信息界面分类更舒适。
在线查看源码界面
//
// Created by Alone on 2021/11/23.
//
#ifndef MY_TINY_STL_QSORT_H
#define MY_TINY_STL_QSORT_H
#include 简单效率验证
本地验证
排序的元素类型 和 初始化
打印和初始化代码
本地 效率测试
测试数据为1000w级别,只打印出10个数据予以证明。否则不好查看。
_qsort打印结果(我的实现)
qsort打印结果
果然不出所料,qsort 快很多!原因我大概也能想得到,主要是因为采用的一个字节一个字节的寻址操作,大大拖慢了排序的过程,实际上底层的 qsort 应该是采取了一些措施优化了编译的过程,让每次寻址操作不至于总是一个字节的处理,应该同时处理多个字节。
LeetCode平台验证(912.排序数组)
C库的qsort实现效率:
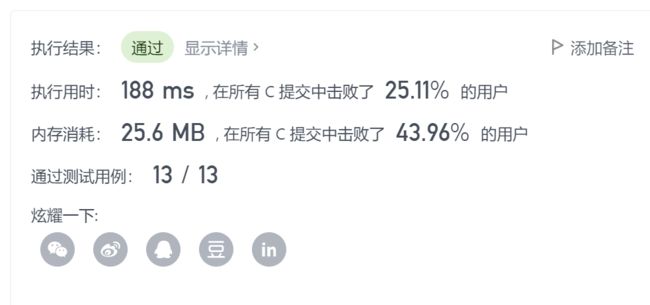
自己实现的qsort效率:
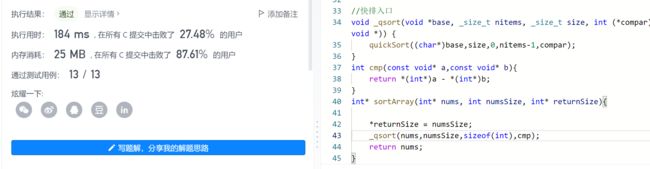
- 这里就几乎没有任何差别了,我猜原因可能是LeetCode平台会对代码作出一些编译上的优化。(毕竟我本地用的C++的g++编译器,而不是gcc)
LeetCode这题的链接:排序数组
我的提交代码
typedef long long _size_t;
void swap(char* a,char *b,int width){//把一块width大小的内存分成一个字节的换
char tmp;
if(a!=b){//不是同一片内存才开始交换
while (width--){
tmp = *a;
*a++ = *b;
*b++ = tmp;
}
}
}
//快速排序真正的处理函数,一个字节一个字节的处理,而一个size大小的字节代表一个元素
//而关于比较部分的函数compar则是外部定义的回调函数,关于回调函数的标准,大于等于0表示
void quickSort(char* base, _size_t size,_size_t left, _size_t right,int (*compar)(const void *, const void *)) {
if (left >= right)return;
_size_t tl = left, tr = right;
char cmp[size];
//以中间的数为标准进行快排,用cmp存储,使得swap不会对cmp的内容作出任何改变
memmove(cmp,(base + (tl+(tr-tl)/2)*size),size);
while (tl <= tr) {
while (compar(base+(tl*size),cmp)<0)tl++;
while (compar(cmp,base+(tr*size))<0)tr--;
if (tl <= tr) {
swap(base+(tl*size), base+(tr*size),size);
tl++;
tr--;
}
}
quickSort(base,size, left, tr,compar);
quickSort(base,size, tl, right,compar);
}
//快排入口
void _qsort(void *base, _size_t nitems, _size_t size, int (*compar)(const void *, const void *)) {
quickSort((char*)base,size,0,nitems-1,compar);
}
int cmp(const void* a,const void* b){
return *(int*)a - *(int*)b;
}
int* sortArray(int* nums, int numsSize, int* returnSize){
*returnSize = numsSize;
_qsort(nums,numsSize,sizeof(int),cmp);
return nums;
}