[论文阅读](Transformer系列)
文章目录
- 一.Video Transformer Network
- 摘要
- 引言
- 相关工作:Applying Transformers on long sequences
- Video Transformer Network
-
- Spatial backbone
- Temporal attention-based encoder
- Classification MLP head
- Looking beyond a short clip context
- Video Action Recognition with VTN
-
- Implementation Details
- Experiments
- 二.Longformer: The Long-Document Transformer
- 摘要
- Introduction
- Longformer
-
- Attention Pattern
- Implementation
- Results
- [2021] (ICLR)AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
-
- 标题 + 作者
- 摘要
- 引言
- 结论
- VIT模型
-
- Vision Transformer
- 实验
- 评价
- [2021] (ICCV) Swin transformer: Hierarchical vision transformer using shifted windows
-
- 题目
- 摘要
- 引言
- 结论
- 方法
- 主要贡献
- 消融实验
- 点评
一.Video Transformer Network
_第1张图片](http://img.e-com-net.com/image/info8/0d8072fe830447339636c2f86e5e10db.jpg)
摘要
本文提出了一种基于变压器的视频识别框架 VTN。受视觉转换器最近发展的启发,我们抛弃了视频动作识别中依赖于3D卷积网的标准方法,并引入了一种通过关注整个视频序列信息来分类动作的方法。我们的方法是通用的,构建在任何给定的2D空间网络之上。在墙运行时方面,与其他最先进的方法相比,它在推断期间训练速度快16.1,运行速度快5.1。它支持整个视频分析,通过一个单一的端到端传递,同时需要减少1.5个GFLOPs。我们报告了在Kinetics-400和Moments in Time基准上的竞争结果,并提出了一个消融研究VTN特性和准确性和推断速度之间的权衡。我们希望我们的方法将作为一个新的基线,并开始在视频识别领域的一条新的研究线。
引言
-
注意事项。近十年来,ConvNets一直统治着计算机视觉领域[21,7]。深度卷积网的应用在许多视觉识别任务中,如图像分类[30,18,32]、目标检测[16,15,26]、语义分割[23]、对象实例分割[17]、人脸识别[31,28]和视频动作识别[9,36,3,37,13,12],都产生了最先进的结果。但是,最近这种优势开始瓦解,因为基于变压器的模型在许多这些任务中显示出了有前途的结果[10,2,33,38,40,14]。
-
视频识别任务也严重依赖于卷积神经网络。为了处理时间维度,最基本的方法是使用3D ConvNets[5,3,4]。与其他直接从输入剪辑水平(from the input clip level)添加时间维度的研究相比,我们的目标是脱离3D网络。我们使用最先进的2D架构来学习空间特征表示,并添加时间信息在随后的数据流中,通过在resulting features之上使用注意机制。我们的方法只输入RGB视频帧,没有任何附加功能(例如,光流、流横向连接、多尺度推断、多视图推断、长剪辑微调等),可以获得与其他先进模型相当的结果。
-
视频识别是变形金刚的完美候选。类似于语言建模,将输入的单词或字符表示为一串标记[35],视频表示为一串图像(帧)。然而,在处理长序列时,这种相似性也是一种限制。和长文档一样,长视频也很难处理。在最近的研究中,即使是10秒的视频,如Kinetics-400基准[20]中的视频,也被处理为2秒的短片段。
-
但是,这种基于剪辑的推断(clip-based inference)如何适用于更长的视频(例如,电影电影、体育赛事或外科手术)?这似乎是违反直觉的:几小时甚至几分钟的视频中的信息,只需几秒钟的片段就可以掌握。然而,目前的网络并不是设计用来共享整个视频的长期信息。
-
VTN的时间处理组件基于Longformer[1]。这种类型的基于转换器的模型可以处理数千个令牌( tokens)的长序列。Longformer提出的注意机制使其能够超越短片段处理,保持全局注意,关注输入序列中的所有标记。
-
除了长序列处理,我们还探讨了机器学习速度与准确性之间的一个重要权衡。我们的框架展示了这种权衡的优越平衡,无论是在训练期间还是在推断时。**在训练中,尽管与其他网络相比,每个时间点的运行时间等于或大于,但我们的方法需要通过的训练数据集要少得多,以达到其最大性能;**端到端,与最先进的网络相比,这使得训练速度提高了16.1。在推断时,我们的方法可以处理多视图和全视频分析,同时保持类似的准确性。相比之下,其他网络在一次分析完整视频时性能显著下降。就GFLOPS x Views而言,它们的推断成本比VTN要高得多,这意味着GFLOPS减少了1.5,验证墙运行时间加快了5.1。
-
我们的框架结构组件是模块化的(图1)。首先,二维空间骨干可以替换为任何给定的网络。基于注意力的模块可以堆叠更多的层,更多的头,或者可以设置为不同的变形金刚模型,可以处理长序列。最后,可以修改分类头,以方便不同的基于视频的任务,如时间动作定位。
_第2张图片](http://img.e-com-net.com/image/info8/23c266e7d3ea4aaf89865e892dd202c3.jpg)
图1所示。视频变压器网络架构。连接三个模块:一个二维空间主干(f(x)),用于特征提取。接下来是基于时间注意的编码器(本研究中的Longformer),它使用特征向量(φi)与位置编码相结合。[CLS]令牌由分类MLP头处理,以获得最终的类预测。
相关工作:Applying Transformers on long sequences
- BERT[8]和它的优化版本RoBERTa[22]是基于转换器的语言表示模型。他们在大型未标记文本上进行预先训练,然后在给定的目标任务上进行微调。只需极少的修改,他们就能在各种NLP任务上取得最先进的结果。
- 这些模型和变形金刚的一个重要限制是它们处理长序列的能力。这是由于自我注意操作,其复杂度为O(n^2) /每层(n为序列长度)[35]。
- Longformer[1]解决了这个问题,并通过引入复杂度为O(n)的注意机制来支持长文档处理。这种注意机制结合了本地上下文的自我注意(由滑动窗口执行)和特定于任务的全局注意。
- 类似于ConvNets,叠加多个窗口的注意层会导致更大的接受场。Longformer的这一特性使其能够跨整个序列整合信息。全局关注部分集中于预先选择的令牌(如[CLS]令牌),并可以关注输入序列中的所有其他令牌。
Video Transformer Network
- 视频变压器网络(VTN)是视频识别的通用框架。它只处理一个数据流,从帧级一直到目标任务头部。在本研究的范围内,我们演示了我们的方法,使用动作识别任务,将输入视频分类到正确的动作类别。
- VTN的体系结构是模块化的,由三个连续的部分组成。一个二维空间特征提取模型(空间主干),一个基于时间注意的编码器,和一个分类MLP头。图1展示了我们的架构布局。
- 在推理过程中,根据视频长度,VTN是可伸缩的,并允许处理非常长的序列。由于内存的限制,我们建议几种类型的推理方法。(1)对整个视频进行端对端处理。(2)对视频帧进行分块处理,首先提取特征,然后应用于基于时间注意的编码器。(3)预先提取所有帧的特征,然后将其送入时间编码器。
Spatial backbone
空间主干作为一个学习的特征提取模块。它可以是任何工作在二维图像上的网络,无论是深的或浅的,预先训练的或没有,卷积或基于变压器。它的权值可以是固定的(预先训练的),也可以是在学习过程中训练的。
Temporal attention-based encoder
- 正如[35]所建议的,我们使用Transformer模型体系结构,该体系结构应用注意机制来在序列数据中建立全局依赖关系。然而,transformer受到它们可以同时处理的令牌数量的限制。这就限制了他们处理长时间输入的能力,比如视频,以及整合远距离信息之间的联系。
- 在这项工作中,我们建议在推理过程中一次性处理整个视频。我们使用一种有效的自我注意变体,它不是全部成对的,叫做Longformer[1]。Longformer操作使用滑动窗口关注,使用线性计算复杂度。d_backbone维数的特征向量序列(第3.1节)被馈送给Longformer编码器。这些向量充当嵌入在标准Transformer设置中的1D tokens。
- 像在BERT[8]中一样,我们在特征序列前添加一个特殊的分类标记([CLS])。在通过Longformer层传播序列之后,我们使用与这个分类标记相关的特征的最终状态作为视频的最终表示,并将其应用到给定的分类任务头部。Longformer还在这个特殊的[CLS]标记上保持全球关注。
Classification MLP head
与[10]类似,使用MLP头处理分类令牌(第3.2节),以提供最终的预测类别。MLP头部包含两个线性层,**在它们之间有GELU非线性和Dropout。**输入token表示首先通过层规范化处理。
Looking beyond a short clip context
- 目前视频动作识别研究中常用的方法是使用基于3d的网络。在推理过程中,由于加上时间维度,这些网络受到内存和运行时对小空间尺度和低帧数剪辑的限制。在[3]中,作者在推断过程中使用了整个视频,在时间上平均预测。获得最先进结果的最新研究在推断过程中处理了大量但相对较短的片段。在[37]中,通过从全长视频中平均采样10个片段进行推理,并对softmax得分进行平均,从而实现最终预测。SlowFast[13]遵循相同的实践,并引入了术语视图带有空间裁剪的时间剪辑。SlowFast在推断时使用10个时间片段和3个空间作物;因此,对30个不同的视图取平均值,最终进行预测。X3D[12]遵循相同的实践,但除此之外,它使用更大的空间尺度来实现在30个不同的视图上的最佳效果。
_第3张图片](http://img.e-com-net.com/image/info8/ffc7dbefacba49c892f3627131e0579f.jpg)
图2。在Kinetics-400数据集[20]中平均从abseiling类别的视频中提取16帧。分析视频的整体背景和关注相关部分比分析围绕特定帧构建的几个片段更直观,因为许多帧可能会导致错误的预测。
- 这种常见的多视图(multi-view)推断有点违反直觉,特别是在处理长视频时。更直观的方法是在决定行动之前查看整个视频环境,而不是只查看其中的一小部分。图2显示了从一个降绳类别的视频中均匀提取的16帧。在视频的几个部分,实际的动作是模糊的或不可见的;在许多观点中,这可能导致错误的行动预测。**专注于视频中最相关的部分是一种强大的能力。**然而,在使用短片段训练的方法中,全视频推理的性能较差(表3和表4)。此外,在实践中,由于硬件、内存和运行时等方面的原因,全视频推理也受到了限制。
Video Action Recognition with VTN
- 为了评估我们的方法以及上下文注意力对视频动作识别的影响,我们使用了几个在2D图像上预先训练过的空间主干。
- ViT-B-VTN。结合最先进的图像分类模型,vt - base[10]作为VTN的主干。我们使用的是预先在ImageNet- 21K上训练的vitc - base网络。使用ViT作为VTN的骨干产生了一个基于端到端变压器的网络,它在空间和时间领域都使用了注意力。
- R50/101-VTN。作为比较,我们还使用标准的2D ResNet-50和ResNet-101网络[18],在ImageNet上进行了预训练。
- DeiT-B / BD / Ti-VTN。由于viti - base是在ImageNet- 21k上训练的,我们还想通过使用在ImageNet上训练的类似网络来比较VTN。我们使用[33]的最新成果,并应用DeiT-Tiny、DeiT-Base和deit - base(DeiT-Base-Distilled)蒸馏作为VTN的主干。
Implementation Details
-
训练。我们使用的空间主干在ImageNet或ImageNet-21k上进行了预训练。从均值为0、标准差为0.02的正态分布中随机初始化Longformer和MLP分类头,利用视频片段对模型进行端到端训练。这些视频是以随机选取一帧为起点,以2.56秒或5.12秒为时间间隔进行采样的方式形成的。根据设置,最后的剪辑帧均匀下采样到固定帧数N(N = 16,32)。
-
对于空间域,我们随机将剪辑中所有帧的短边调整为[256,320]比例,并随机将所有帧裁剪为224 224。水平翻转也应用于整个剪辑随机。
-
烧蚀实验在4-GPU机器上进行。使用批量大小为16的vit - vtn(每个剪辑输入16帧)和批量大小为32的R50/101-VTN。我们使用SGD优化器,初始学习率为10e-3,学习率降低策略不同,vit - vtn版本采用基于步骤的策略,R50/101-VTN版本采用余弦时间表衰减。为了报告墙壁运行时间,我们使用了一台8- v100 gpu机器。
-
由于我们使用2D模型作为空间骨干,我们可以操作输入剪辑形状
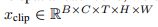
,通过将所有clip中的所有帧叠加在一起,创建形状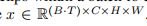
的单个帧批。因此,在训练期间,我们在一次向前向后的传递中传播所有批处理帧。 -
对于Longformer,我们使用了大小为32的有效注意窗口,适用于每一层。另外两个超参数是Hidden size和FFN inner Hidden size的维数。这些是空间主干的直接衍生。因此,在R50/101-VTN中,我们分别使用2048和4096,而对于vitb - vtn,我们分别使用768和3072。此外,我们以0.1的概率应用Attention Dropout。我们还探讨了Longformer层数的影响.
-
位置嵌入(PE)信息只与基于时间注意的编码器相关(图1)。我们探索了三种位置嵌入方法(表2b):(1)学习位置嵌入-由于片段是用取自完整视频序列的帧表示的,我们可以学习使用原始视频中的帧位置(索引)作为输入,给Transformer关于片段在整个序列中的位置的信息;(2)固定绝对编码——我们使用与DETR[2]中类似的方法,并将其修改为仅在时间轴上工作;(3)没有位置嵌入——在时间维度中没有添加任何信息,但我们仍然使用全局位置来标记特殊的[CLS]标记位置。
_第4张图片](http://img.e-com-net.com/image/info8/265aa1bebc144de482f78af2d4db46c3.jpg)
-
推理。为了展示不同模型之间的比较,我们使用了常见的多视图推理和全视频推理方法(第3.4节)。
-
在多视图方法中,我们从视频中平均抽样10个 clips。对于每个 clip,我们首先调整短边为256,然后从左、中、右选取大小为224 224的三个剪辑。结果是每个视频30次观看,最后的预测是所有观看softmax分数的平均值。
-
在全视频推理方法中,我们读取视频中的所有帧。然后,我们为批处理目的,通过子采样或上采样,均匀地对齐到250帧。在空间域中,我们将较短的边调整为256,并将中心裁剪为224 224。
Experiments
- Longformer深度。接下来,我们探索注意层的数量如何影响性能。每一层有12个注意力头,骨干是vitb。表2a显示了第1、3、6和12个注意层的验证top-1和top-5精度。对比表明,性能上的差异很小。这违背了越深越好这一事实。这可能与动力学有关,400个视频相对较短,大约10秒。我们认为,处理较长的视频将受益于使用较深的Longformer获得的大接收场。
_第5张图片](http://img.e-com-net.com/image/info8/f548a30481d64f8782445656fac4775f.jpg)
-
没有任何位置嵌入的版本比固定和学习版本的效果略好。 由于这是一个有趣的结果,我们也使用相同的训练模型,并只在验证集视频中随机打乱输入帧后对其进行评估。这是通过首先获取未打乱的帧嵌入,然后打乱它们的顺序,最后添加位置嵌入来完成的。这又带来了另一个令人惊讶的发现,shuffle版本的结果更好,在无位置嵌入版本中达到了78.9%的前1位精度。即使在学习嵌入的情况下,它也不会有减弱的影响。与Longformer深度相似,我们认为这可能与Kinetics- 400中相对较短的视频有关,较长的序列可能更多地受益于位置信息。我们还认为,这可能意味着dynamics -400主要是一个静态框架,基于外观的分类问题,而不是一个运动问题[29]。
-
注意有关系吗?我们的方法的一个关键组成部分是注意在功能上对VTN感知整个视频序列的方式的影响。为了传达这种影响,我们训练了两个VTN网络,在Longformer中使用了三层,但每层只有一个头。在一个网络中,头部照常训练,而在第二个网络中,我们不再基于查询/关键点乘积和softmax计算注意力,而是用一个在反向传播过程中不更新的硬编码均匀分布来代替注意力矩阵。
-
如图4所示为两种网络的学习曲线。虽然训练有相似的趋势,但习得注意力表现得更好。相比之下,统一注意力的有效性在几个时代后就失效了,表明这个网络的泛化能力很差。进一步,我们通过使用单头训练网络处理图2中的相同视频来可视化[CLS]令牌注意权值,并在图3中描述了第一注意层的所有权值对齐到视频帧。有趣的是,在与滑绳相关的部分,重量要高得多。在附录a中,我们展示了更多的例子。
_第6张图片](http://img.e-com-net.com/image/info8/852e829afc51442fb3c7816872ec002c.jpg)
二.Longformer: The Long-Document Transformer
_第7张图片](http://img.e-com-net.com/image/info8/2aa4a1cbe09f4a4a8528c28a07527bf9.jpg)
摘要
基于变压器的模型不能处理长序列,因为它的自关注操作与序列长度成二次关系。为了解决这个限制,我们引入了Longformer,它具有随序列长度线性伸缩的注意机制,使得处理包含数千个或更长的标记的文档变得容易。Longformer的注意机制是标准自我注意的替代,它将局部窗口注意与任务驱动的全球注意结合起来。在之前的长序列转换器工作之后,我们在字符级语言建模上评估了Longformer,并在text8和enwik8上取得了最先进的结果。与之前的大多数工作相比,我们还对Longformer进行了预训练,并在各种下游任务中对其进行微调。我们的训练有素的Longformer在长文档任务上一贯优于RoBERTa,并在WikiHop和TriviaQA上设置了最新的结果。最后,我们介绍了Longformer- encoder - decoder (LED),这是一个支持长文档生成顺序到顺序任务的Longformer变体,并在arXiv摘要数据集上验证了它的有效性。
Introduction
- 变形金刚(Vaswani等人,2017年)在包括生成语言建模在内的各种自然语言任务中取得了最先进的成果(Dai等人,2019年;Radford等人,2019年)和辨别性语言理解(Devlin等人,2019年)。这一成功的部分原因是由于自我注意组件使网络能够从整个序列中捕捉上下文信息。虽然功能强大,但自我关注对内存和计算的要求也在增长与序列长度二次相关,使得处理长序列变得不可行的(或非常昂贵)。
- 为了解决这一限制,我们提出了Longformer,这是一种改进的Transformer架构,具有自关注操作,可随序列长度线性伸缩,使其可用于处理长文档(图1)。这对于长文档分类、问答(QA)、以及相互引用解析,现有的方法将长上下文划分或缩短为更小的序列,这些序列属于bert风格的预训练模型的典型512令牌限制。这样的划分可能会潜在地导致重要的跨分区信息的丢失,为了减轻这个问题,现有的方法通常依赖于复杂的体系结构来处理这样的交互。另一方面,我们提出的Longformer能够使用多层注意力构建整个上下文的上下文表示,减少需要特定于任务的体系结构。
- Longformer的注意机制是窗口局部环境自我注意(windowed local-context self-attention)和最终任务驱动的全局注意的结合(end task motivated global attention),后者编码了对任务的归纳偏见( inductive bias)。通过实验和对照实验,我们发现两种类型的注意都是至关重要的,局部注意主要用于构建上下文表征,而全局注意则使Longformer能够构建预测的完整序列表征。
_第8张图片](http://img.e-com-net.com/image/info8/5a5e994dcb8b40b1b17c24c4bb9c8769.jpg)
Longformer
原始的Transformer模型具有O(n2)时间和内存复杂度的自我注意组件,其中n是输入序列长度。为了解决这个问题,我们根据一种指定相互注意的输入位置对的注意模式,对完全自我注意矩阵进行稀疏化。与完全的自我注意不同,我们提出的注意模式与输入序列呈线性关系,使得它对较长的序列有效。本节讨论这个注意模式的设计和实现。
Attention Pattern
- 考虑到 local context的重要性(Kovaleva等人,2019年),我们的注意力模式使用了围绕每个token的固定大小的窗口注意力。使用这种窗口化注意的多个堆叠层会产生一个大的感受野,其中顶层可以访问所有输入位置,并有能力构建包含整个输入信息的表示,类似于cnn (Wu et al., 2019)。给定一个固定的窗口大小w,每个令牌在每边处理1/2 w个令牌(图2b)。此模式的计算复杂度为O(nw),它与输入序列长度n成线性比例。在一个具有 l 层的变压器中,顶层的接收场大小为lw(假设所有层的w都是固定的)。根据应用程序的不同,为每一层使用不同的w值可能有助于平衡效率和模型表示能力(4.1)。
_第9张图片](http://img.e-com-net.com/image/info8/e66aa853c78b4fee875cdaf3c3b8fdaa.jpg)
图2:比较Longformer的完全自我注意模式和注意模式的配置。
- 扩大的滑动窗口(Dilated Sliding Window)为了在不增加计算量的情况下进一步增加接收域,可以扩大滑动窗口。这类似于膨胀的cnn (van den Oord et al., 2016),窗口存在膨胀大小为d的间隙(图2c)。假设所有层的d和w都是固定的,那么接收域为l * d *w,即使d值很小,也可以达到数万个令牌。
- Global Attention:在最先进的bert风格的自然语言任务模型中,最优输入表示因语言建模而不同,也因任务而不同。对于掩码语言建模(MLM),模型使用局部上下文来预测掩码词,而对于分类,模型将整个序列的表示集合成一个特殊的标记(BERT时为[CLS])。对于QA,问题和文档是连接在一起的,允许模型通过自我关注来比较问题和文档。
- 在我们的例子中,窗口式和扩张式注意力不够灵活,无法学习特定于任务的表示。因此,我们在几个预先选定的输入位置上增加了全局关注。重要的是,我们使这个注意操作是对称的:也就是说,a token with a global attention attends to all tokens across the sequence, and all tokens in the sequence attend to it。图2d显示了一个在自定义位置的几个令牌上具有全局注意的滑动窗口注意的示例。例如,在分类中,全局关注用于[CLS]标记,而在QA中对所有问题标记提供全局关注。由于此类令牌的数量相对于n较小,且独立于n,因此结合局部和全局注意的复杂性仍然为O(n)。虽然指定全局注意力是特定于任务的,但在模型的注意力中添加归纳偏差是一种简单的方法,it is much simpler than existing task specific approaches that use complex architecture to combine information across smaller input chunks.
- Linear Projections for Global Attention: 回想一下,给定线性投影Q, K, V,变压器模型(Vaswani et al., 2017)计算注意力分数如下
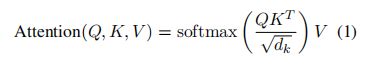
我们使用两组投影projections,Q_s, K_s, V_s来计算滑动窗口注意力的注意力分数,Q_g, K_g, V_g来计算全局注意力的注意力分数。额外的预测为建模不同类型的注意力提供了灵活性,我们表明,这对于在下游任务中获得最佳表现至关重要。Qg, Kg, Vg都用匹配Qs, k, Vs的值初始化。
_第10张图片](http://img.e-com-net.com/image/info8/34490aaa775f4e6295a13a7377433b8b.jpg)
_第11张图片](http://img.e-com-net.com/image/info8/0695de4fa99e43bd8fb55ad92f6b1aa4.png)
Implementation
在普通变压器中,注意分数的计算方法如方程式1所示。代价昂贵的操作是矩阵乘法,因为Q和K都有n个(序列长度)投影。对于Longformer,扩大的滑动窗口注意只计算固定数量的QK^T对角线。如图1所示,这导致了内存使用的线性增长,而完全自我注意则是二次增长。然而,实现它需要一种带状矩阵乘法,而现有的深度学习库(如PyTorch/Tensorflow)不支持这种形式。图1比较了三种不同实现方法的性能:loop是一种内存效率高的PyTorch实现,支持扩展,但运行速度慢得不可用,只用于测试;chunk只支持非扩张情况,用于训练前/微调设置;cuda是我们使用TVM实现的功能完备、高度优化的定制cuda内核(Chen et al., 2018),用于语言建模实验(详见附录A)。
Results
_第12张图片](http://img.e-com-net.com/image/info8/661f487c08ea493a825d51126b0ecb52.jpg)
_第13张图片](http://img.e-com-net.com/image/info8/ff7c86ad5f054bb694e7da6561418ed8.jpg)
[2021] (ICLR)AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
标题 + 作者
一张图片等价于很多16*16大小的单词
- 为什么是1616的单词?将图片看成是很多的patch,假如把图片分割成很多方格的形式,每一个方格的大小都是1616,那么这张图片就相当于是很多16*16的patch组成的整体
使用transformer去做大规模的图像识别
作者团队来自于google research和google brain team
摘要
虽然说transformer已经是NLP(自然语言处理)领域的一个标准:BERT模型、GPT3或者是T5模型,但是用transformer来做CV还是很有限的
在视觉领域,自注意力要么是跟卷积神经网络一起使用,要么用来把某一些卷积神经网络中的卷积替换成自注意力,但是还是保持整体的结构不变
- 这里的整体结构是指:比如说对于一个残差网络(Res50),它有4个stage:res2、res3、res4、res5,上面说的整体结构不变指的就是这个stage是不变的,它只是去取代每一个stage、每一个block的操作
这篇文章证明了这种对于卷积神经网络的依赖是完全不必要的,一个纯的Vision Transformer直接作用于一系列图像块的时候,也是可以在图像分类任务上表现得非常好的,尤其是当在大规模的数据上面做预训练然后迁移到中小型数据集上面使用的时候,Vision Transformer能够获得跟最好的卷积神经网络相媲美的结果
这里将ImageNet、CIFAR-100、VATB 当作中小型数据集
- 其实ImageNet对于很多人来说都已经是很大的数据集了
Transformer的另外一个好处:它只需要更少的训练资源,而且表现还特别好
- 作者这里指的少的训练资源是指2500天TPUv3的天数
- 这里的少只是跟更耗卡的模型去做对比(类似于一个小目标)
引言
自注意力机制的网络,尤其是Transformer,已经是自然语言中的必选模型了,现在比较主流的方式,就是先去一个大规模的数据集上去做预训练,然后再在一些特定领域的小数据集上面做微调(这个是在BERT的文章中提出来的)
得益于transformer的计算高效性和可扩展性,现在已经可以训练超过1000亿参数的模型了,比如说GPT3
随着模型和数据集的增长,目前还没有发现任何性能饱和的现象
- 很多时候不是一味地扩大数据集或者说扩大模型就能够获得更好的效果的,尤其是当扩大模型的时候很容易碰到过拟合的问题,但是对于transformer来说目前还没有观测到这个瓶颈
- 最近微软和英伟达又联合推出了一个超级大的语言生成模型Megatron-Turing,它已经有5300亿参数了,还能在各个任务上继续大幅度提升性能,没有任何性能饱和的现象
回顾transformer :
- transformer中最主要的操作就是自注意力操作,自注意力操作就是每个元素都要跟每个元素进行互动,两两互相的,然后算得一个attention(自注意力的图),用这个自注意力的图去做加权平均,最后得到输出
- 因为在做自注意力的时候是两两互相的,这个计算复杂度是跟序列的长度呈平方倍的。
- 目前一般在自然语言处理中,硬件能支持的序列长度一般也就是几百或者是上千(比如说BERT的序列长度也就是512)
将transformer运用到视觉领域的难处:
首先要解决的是如何把一个2D的图片变成一个1D的序列(或者说变成一个集合)。最直观的方式就是把每个像素点当成元素,将图片拉直放进transformer里,看起来比较简单,但是实现起来复杂度较高。
- 一般来说在视觉中训练分类任务的时候图片的输入大小大概是224224,如果将图片中的每一个像素点都直接当成元素来看待的话,他的序列长度就是224224=50176个像素点,也就是序列的长度,这个大小就相当于是BERT序列长度的100倍,这还仅仅是分类任务,对于检测和分割,现在很多模型的输入都已经变成600600或者800800或者更大,计算复杂度更高,所以在视觉领域,卷积神经网络还是占主导地位的,比如AlexNet或者是ResNet
所以现在很多工作就是在研究如何将自注意力用到机器视觉中:一些工作是说把卷积神经网络和自注意力混到一起用;另外一些工作就是整个将卷积神经网络换掉,全部用自注意力。这些方法其实都是在干一个事情:因为序列长度太长,所以导致没有办法将transformer用到视觉中,所以就想办法降低序列长度
Wang et al.,2018:既然用像素点当输入导致序列长度太长,就可以不用图片当transformer的直接输入,可以把网络中间的特征图当作transformer的输入
- 假如用残差网络Res50,其实在它的最后一个stage,到res4的时候的featuremap的size其实就只有14*14了,再把它拉平其实就只有196个元素了,即这个序列元素就只有196了,这就在一个可以接受的范围内了。所以就通过用特征图当作transformer输入的方式来降低序列的长度
Wang et al.,2019;Wang et al.,2020a(Stand-Alone Attention&Axial Attention,孤立自注意力和轴自注意力)
- 孤立自注意力:之所以视觉计算的复杂度高是来源于使用整张图,所以不使用整张图,就用一个local window(局部的小窗口),这里的复杂度是可以控制的(通过控制这个窗口的大小,来让计算复杂度在可接受的范围之内)。这就类似于卷积操作(卷积也是在一个局部的窗口中操作的)
- 轴自注意力:之所以视觉计算的复杂度高是因为序列长度N=H*W,是一个2D的矩阵,将图片的这个2D的矩阵想办法拆成2个1D的向量,所以先在高度的维度上做一次self-attention(自注意力),然后再在宽度的维度上再去做一次自注意力,相当于把一个在2D矩阵上进行的自注意力操作变成了两个1D的顺序的操作,这样大幅度降低了计算的复杂度
最近的一些模型,这种方式虽然理论上是非常高效的,但事实上因为这个自注意力操作都是一些比较特殊的自注意力操作,所以说无法在现在的硬件上进行加速,所以就导致很难训练出一个大模型,所以截止到目前为止,孤立自注意力和轴自注意力的模型都还没有做到很大,跟百亿、千亿级别的大transformer模型比还是差的很远,因此在大规模的图像识别上,传统的残差网络还是效果最好的
所以,自注意力早已经在计算机视觉里有所应用,而且已经有完全用自注意力去取代卷积操作的工作了,所以本文换了一个角度来讲故事
本文是被transformer在NLP领域的可扩展性所启发,本文想要做的就是直接应用一个标准的transformer直接作用于图片,尽量做少的修改(不做任何针对视觉任务的特定改变),看看这样的transformer能不能在视觉领域中扩展得很大很好
但是如果直接使用transformer,还是要解决序列长度的问题
- vision transformer将一张图片打成了很多的patch,每一个patch是16*16
- 假如图片的大小是224224,则sequence lenth(序列长度)就是N=224224=50176,如果换成patch,一个patch相当于一个元素的话,有效的长宽就变成了224/16=14,所以最后的序列长度就变成了N=14*14=196,所以现在图片就只有196个元素了,196对于普通的transformer来说是可以接受的
- 然后将每一个patch当作一个元素,通过一个fc layer(全连接层)就会得到一个linear embedding,这些就会当作输入传给transformer,这时候一张图片就变成了一个一个的图片块了,可以将这些图片块当成是NLP中的单词,一个句子中有多少单词就相当于是一张图片中有多少个patch,这就是题目中所提到的一张图片等价于很多16*16的单词
本文训练vision transformer使用的是有监督的训练
- 为什么要突出有监督?因为对于NLP来说,transformer基本上都是用无监督的方式训练的,要么是用language modeling,要么是用mask language modeling,都是用的无监督的训练方式但是对于视觉来说,大部分的基线(baseline)网络还都是用的有监督的训练方式去训练的
_第14张图片](http://img.e-com-net.com/image/info8/858b858faafb4b4f9fa961d400c53bfd.jpg)
到此可以发现,本文确实是把视觉当成自然语言处理的任务去做的,尤其是中间的模型就是使用的transformer encoder,跟BERT完全一样,这篇文章的目的是说使用一套简洁的框架,transformer也能在视觉中起到很好的效果
这么简单的想法,之前其实也有人想到过去做,本文在相关工作中已经做了介绍,跟本文的工作最像的是一篇ICLR 2020的paper
- 这篇论文是从输入图片中抽取2*2的图片patch
- 为什么是22?因为这篇论文的作者只在CIFAR-10数据集上做了实验,而CIFAR-10这个数据集上的图片都是3232的,所以只需要抽取22的patch就足够了,1616的patch太大了
- 在抽取好patch之后,就在上面做self-attention
从技术上而言他就是Vision Transformer,但是本文的作者认为二者的区别在于本文的工作证明了如果在大规模的数据集上做预训练的话(和NLP一样,在大规模的语料库上做预训练),那么就能让一个标准的Transformer,不用在视觉上做任何的更改或者特殊的改动,就能取得比现在最好的卷积神经网络差不多或者还好的结果,同时本文的作者还指出之前的ICLR的这篇论文用的是很小的22的patch,所以让他们的模型只能处理那些小的图片,而Vision Transformer是能够处理224224这种图片的
所以这篇文章的主要目的就是说,Transformer在Vision领域能够扩展的有多好,就是在超级大数据集和超级大模型两方的加持下,Transformer到底能不能取代卷积神经网络的地位
一般引言的最后就是将最想说的结论或者最想表示的结果放出来,这样读者不用看完整篇论文就能知道文章的贡献有多大
本文在引言的最后说在中型大小的数据集上(比如说ImageNet)上训练的时候,如果不加比较强的约束,Vit的模型其实跟同等大小的残差网络相比要弱一点
- 作者对此的解释是:这个看起来不太好的结果其实是可以预期的,因为transformer跟卷积神经网路相比,它缺少了一些卷积神经网络所带有的归纳偏置
- 这里的归纳偏置其实是指一种先验知识或者说是一种提前做好的假设
对于卷积神经网络来说,常说的有两个inductive bias(归纳偏置):
- locality:因为卷积神经网络是以滑动窗口的形式一点一点地在图片上进行卷积的,所以假设图片上相邻的区域会有相邻的特征,靠得越近的东西相关性越强
- translation equivariance(平移等变性或平移同变性):f(g(x))=g(f(x)),就是说不论是先做g这个函数,还是先做f这个函数,最后的结果是不变的。这里可以把f理解成卷积,把g理解成平移操作,意思是说无论是先做平移还是先做卷积,最后的结果都是一样的(因为在卷积神经网络中,卷积核就相当于是一个模板,不论图片中同样的物体移动到哪里,只要是同样的输入进来,然后遇到同样的卷积核,那么输出永远是一样的)
一旦神经网络有了这两个归纳偏置之后,他就拥有了很多的先验信息,所以只需要相对较少的数据来学习一个相对比较好的模型,但是对于transformer来说,它没有这些先验信息,所以它对视觉的感知全部需要从这些数据中自己学习
- 为了验证这个假设,作者在更大的数据集(14M-300M)上做了预训练,这里的14M是ImageNet 22k数据集,300M是google自己的JFT 300M数据集,然后发现大规模的预训练要比归纳偏置好
Vision Transformer只要在有足够的数据做预训练的情况下,就能在下游任务上取得很好的迁移学习效果。具体来说,就是当在ImageNet 21k上或者在JFT 300M上训练,Vit能够获得跟现在最好的残差神经网络相近或者说更好的结果
- VTAB也是作者团队所提出来的一个数据集,融合了19个数据集,主要是用来检测模型的稳健性,从侧面也反映出了Vision Transformer的稳健性也是相当不错的
总的来说,引言写的简洁明了
- 第一段先说因为Transformer在NLP中扩展的很好,越大的数据或者越大的模型,最后performance会一直上升,没有饱和的现象,然后提出:如果将Transformer使用到视觉中,会不会产生同样的效果
- 第二段开始讲前人的工作,讲清楚了自己的工作和前人工作的区别:之前的工作要么就是把卷积神经网络和自注意力结合起来,要么就是用自注意力去取代卷积神经网络,但是从来没有工作直接将transformer用到视觉领域中来,而且也都没有获得很好的扩展效果
- 第三段讲Vision Transformer就是用了一个标准的Transformer模型,只需要对图片进行预处理(把图片打成块),然后送到transformer中就可以了,而不需要做其他的改动,这样可以彻底地把一个视觉问题理解成是一个NLP问题,就打破了CV和NLP领域的壁垒
- 最后两段展示了结果,只要在足够多的数据做预训练的情况下,Vision Transformer能够在很多数据集上取得很好的效果
结论
这篇论文的工作是直接拿NLP领域中标准的Transformer来做计算机视觉的问题,跟之前用自注意力的那些工作的区别在于:
- 除了在刚开始抽图像块的时候,还有位置编码用了一些图像特有的归纳偏置
除此之外就再也没有引入任何图像特有的归纳偏置了,这样的好处就是不需要对Vision领域有多少了解,可以直接把图片理解成一个序列的图像块,就跟一个句子中有很多单词一样,然后就可以直接拿NLP中一个标准的Transformer来做图像分类了
当这个简单而且扩展性很好的策略和大规模预训练结合起来的时候效果出奇的好:Vision Transformer在很多图像分类的benchmark上超过了之前最好的方法,而且训练起来还相对便宜
目前还没有解决的问题(对未来的展望)
如何用transformer来做cv
第一个问题:Vit不能只做分类,还有检测和分割
- DETR:去年目标检测的一个力作,相当于是改变了整个目标检测之前的框架
鉴于Vit和DETR良好的表现,所以作者说拿Vision Transformer做视觉的其他问题应该是没有问题的
- 事实上,在Vit出现短短的一个半月之后,2020年12月检测这块就出来了一个叫Vit-FRCNN的工作,就已经将Vit用到检测上面了
- 图像分割这一块也是一样的,同年12月就有一篇SETR的paper将Vit用到分割里了
- 紧接着3个月之后Swin Transformer横空出世,它将多尺度的设计融合到了Transformer中,更加适合做视觉的问题了,真正证明了Transformer是能够当成一个视觉领域的通用骨干网络
另外一个未来的工作方向就是说要去探索一下自监督的预训练方案,因为在NLP领域,所有的大的transformer全都是用自监督的方式训练的,Vit这篇paper也做了一些初始实验,证明了用这种自监督的训练方式也是可行的,但是跟有监督的训练比起来还是有不小的差距的
最后作者说,继续将Vision Transformer变得更大,有可能会带来更好的结果
- 过了半年,同样的作者团队又出了一篇paper叫做Scaling Vision Transformer,就是将Transformer变得很大,提出了一个Vit-G,将ImageNet图像分类的准确率提高到了90以上了
VIT模型
在模型的设计上是尽可能按照最原始的transformer来做的,这样做的好处就是可以直接把NLP中比较成功的Transformer架构拿过来用,而不用再去对模型进行改动,而且因为transformer因为在NLP领域已经火了很久了,它有一些写的非常高效的实现,同样ViT也可以直接拿来使用
下图是模型的总览图,模型的总览图对论文来说是非常重要的,画的好的模型总览图能够让读者在不读论文的情况下,仅仅通过看图就能够知道整篇论文的大致内容
_第15张图片](http://img.e-com-net.com/image/info8/3e4ef53ddc524c44b086ad154db6e49e.jpg)
- 首先给定一张图,先将这张图打成了很多的patch(如上图左下角所示),这里是将图打成了九宫格
- 然后再将这些patch变成了一个序列,每个patch通过线性投射层的操作得到一个特征(就是本文中提到的patch embedding)
- 自注意力是所有元素之间两两做交互,所以本身并不存在顺序的问题,但是对于图片来说,图片本身是一个整体,这个九宫格是有自己的顺序的,如果顺序颠倒了就不是原来的图片了。所以类似于NLP,给patch embedding加上了一个position embedding,等价于加上了一个位置编码
- 在加上这个位置编码信息之后,整体的token就既包含了图片块原本有的图像信息,又包含了这个图片块的所在位置信息
- 在得到了这个token之后,接下来就跟NLP中完全一样了,直接将它们输入进一个Transformer encoder,然后Transformer encoder就会得到很多输出
- 这么多输出,应该拿哪个输出去做分类? 这里借鉴了BERT,BERT中有一个extra learnable embedding,它是一个特殊字符CLS(分类字符),所以这里也添加了一个特殊的字符,用*代替,而且它也是有position embedding,它的位置信息永远是0,如下图红色圆圈所示
_第16张图片](http://img.e-com-net.com/image/info8/ca0caf7facee42009bf01cd1f0f852d9.jpg)
- 因为所有的token都在跟其它token做交互信息,所以作者相信,class embedding能够从别的序列后面的embedding中学到有用的信息,从而只需要根据class embedding的输出做最后的判断就可以了
- MLP Head其实就是一个通用的分类头
- 最后用交叉熵函数进行模型的训练
模型中的Transformer encoder是一个标准的Transformer,具体的结构如下图右图所示
_第17张图片](http://img.e-com-net.com/image/info8/2847f39bb8084985bdc5edd15252ffcc.jpg)
- Transformer的输入是一些patch
- 一个Transformer block叠加了L次
整体上来看Vision Transformer的架构还是相当简洁的,它的特殊之处就在于如何把一个图片变成一系列的token
具体的模型的前向过程
- 假如说有一个2242243的图片X,如果使用1616的patch size大小,就会得到196个图像块,每一个图像块的维度就是16163=768,到此就把原先224224*3的图片变成了196个patch,每个patch的维度是768
- 接下来就要将这些patch输入一个线性投射层,这个线性投射层其实就是一个全连接层(在文章中使用E表示),这个全连接层的维度是768768,第二个768就是文章中的D,D是可以变的,如果transformer变得更大了,D也可以相应的变得更大,第一个768是从前面图像的patch算来的(1616*3),它是不变的。
- 经过了线性投射就得到了patch embedding(XE),它是一个196768的矩阵(X是196768,E是768768),意思就是现在有196个token,每个token向量的维度是768
- 到目前为止就已经成功地将一个vision的问题变成了一个NLP的问题了,输入就是一系列1d的token,而不再是一张2d的图片了
- 除了图片本身带来的token以外,这里面加了一个额外的cls token,它是一个特殊的字符,只有一个token,它的维度也是768,这样可以方便和后面图像的信息直接进行拼接。所以最后整体进入Transformer的序列的长度是197*768(196+1:196个图像块对应的token和一个特殊字符cls token)
- 最后还要加上图像块的位置编码信息,这里是将图片打成了九宫格,所以位置编码信息是1到9,但是这只是一个序号,并不是真正使用的位置编码,具体的做法是通过一个表(表中的每一行就代表了这些1到9的序号,每一行就是一个向量,向量的维度是768,这个向量也是可以学的)得到位置信息,然后将这些位置信息加到所有的token中(注意这里是加,而不是拼接,序号1到9也只是示意一下,实际上应该是1到196),所以加上位置编码信息之后,这个序列还是197*768
- 到此就做完了整个图片的预处理,包括加上特殊的字符cls和位置编码信息,也就是说transformer输入的embedded patches就是一个197*768的tensor
- 这个tensor先过一个layer norm,出来之后还是197*768
- 然后做多头自注意力,这里就变成了三份:k、q、v,每一个都是197768,这里因为做的是多头自注意力,所以其实最后的维度并不是768,假设现在使用的是VIsion Transformer的base版本,即多头使用了12个头,那么最后的维度就变成了768/12=64,也就是说这里的k、q、v变成了19764,但是有12个头,有12个对应的k、q、v做自注意力操作,最后再将12个头的输出直接拼接起来,这样64拼接出来之后又变成了768,所以多头自注意力出来的结果经过拼接还是197*768
- 然后再过一层layer norm,还是197*768
- 然后再过一层MLP,这里会把维度先对应地放大,一般是放大4倍,所以就是197*3072
- 然后再缩小投射回去,再变成197*768,就输出了
_第18张图片](http://img.e-com-net.com/image/info8/6f7ca4393a074bf2958dcd9471480956.jpg)

_第19张图片](http://img.e-com-net.com/image/info8/07b2f8d293564de7a349dbc3057fac65.jpg)
- 以上就是一个Transformer block的前向传播的过程,进去之前是197768,出来还是197768,这个序列的长度和每个token对应的维度大小都是一样的,所以就可以在一个Transformer block上不停地往上叠加Transformer block,最后有L层Transformer block的模型就构成了Transformer encoder
Vision Transformer
- Transformer从头到尾都是使用D当作向量的长度的,都是768,这个维度是不变的
- 对于位置编码信息,本文用的是标准的可以学习的1d position embedding,它也是BERT使用的位置编码。作者也尝试了了别的编码形式,比如说2d aware(它是一个能处理2d信息的位置编码),但是最后发现结果其实都差不多,没有什么区别
消融实验(附录)
针对特殊的class token还有位置编码,作者还做了详细的消融实验,因为对于Vision Transformer来说,怎么对图片进行预处理以及怎样对图片最后的输出进行后处理是很关键的,因为毕竟中间的模型就是一个标准的Transformer
1、class token
因为在本文中,想要跟原始的Transformer尽可能地保持一致,所以也使用了class token,因为class token在NLP的分类任务中也有用到(也是当作一个全局的对句子的理解的特征),本文中的class token是将它当作一个图像的整体特征,拿到这个token的输出以后,就在后面接一个MLP(MLP中是用tanh当作非线性的激活函数来做分类的预测)
- 这个class token的设计是完全从NLP借鉴过来的,之前在视觉领域不是这么做的,比如说有一个残差网络Res50,在最后一个stage出来的是一个14*14的feature map,然后在这个feature map之上其实是做了一个叫做gap(global average pooling,全局平均池化)的操作,池化以后的特征其实就已经拉直了,就是一个向量了,这个时候就可以把这个向量理解成一个全局的图片特征,然后再拿这个特征去做分类
对于Transformer来说,如果有一个Transformer模型,进去有n个元素,出来也有n个元素,为什么不能直接在n个输出上做全局平均池化得到一个最后的特征,而非要在前面加上一个class token,最后用class token的输出做分类?
- 通过实验,作者最后的结论是:这两种方式都可以,就是说可以通过全局平均池化得到一个全局特征然后去做分类,也可以用一个class token去做。本文所有的实验都是用class token去做的,主要的目的是跟原始的Transformer尽可能地保持一致(stay as close as possible),作者不想人觉得某些效果好可能是因为某些trick或者某些针对cv的改动而带来的,作者就是想证明,一个标准的Transformer照样可以做视觉
两种方法的效果对比如下图所示
_第20张图片](http://img.e-com-net.com/image/info8/29a4a199eeec4a2cad9d6a1442c83635.jpg)
- 绿线表示全局平均池化
- 蓝线表示class token
- 可以发现到最后绿线和蓝线的效果是差不多的,但是作者指出绿线和蓝线所使用的学习率是不一样的,如果直接将蓝线的学习率拿过来使用得到的效果可能如橙线所示,也就是说需要进行好好调参
2、位置编码
作者也做了很多的消融实验,主要是三种
-
1d:就是NLP中常用的位置编码,也就是本文从头到尾都在使用的位置编码
-
2d:比如1d中是把一个图片打成九宫格,用的是1到9的数来表示图像块,2d就是使用11、12、13、21等来表示图像块,这样就跟视觉问题更加贴近,因为它有了整体的结构信息。具体的做法就是,原有的1d的位置编码的维度是d,现在因为横坐标、纵坐标都需要去表示,横坐标有D/2的维度,纵坐标也有D/2的维度,就是说分别有一个D/2的向量去表述横坐标和纵坐标,最后将这两个D/2的向量拼接到一起就又得到了一个长度为D的向量,把这个向量叫做2d的位置编码
_第21张图片](http://img.e-com-net.com/image/info8/881b59b6ed89447c9652eebf58fb68a1.jpg)
-
relative positional embedding(相对位置编码):在1d的位置编码中,两个patch之间的距离既可以用绝对的距离来表示,又可以用它们之间的相对距离来表示(文中所提到的offset),这样也可以认为是一种表示图像块之间位置信息的方式
但是这个消融实验最后的结果也是:三种表示方法的效果差不多,如下图所示
_第22张图片](http://img.e-com-net.com/image/info8/77ff61f4b8504990be4b3ddc147a89be.jpg)
- No Pos表示不加任何的位置编码,效果不太好,但也不算特别差。transformer根本没有感知图片位置的能力,在没有位置编码的情况下,还能够达到61的效果其实已经相当不错了
- 对比以上三种位置编码的形式发现,所有的performance都是64,没有任何区别
- 对此作者给出了他认为合理的解释,他所做的Vision Transformer是直接在图像块上做的,而不是在原来的像素块上做的,因为图像块很小,1414,而不是全局的那种224224,所以在排列组合这种小块或者想要知道这些小块之间相对位置信息的时候还是相对比较容易的,所以使用任意的位置编码都无所谓
通过以上的消融实验可以看出,class token也可以使用全局平均池化替换,最后1d的位置信息编码方式也可以用2d或者相对位置编码去替换,但是为了尽可能对标准的transformer不做太多改动,所以本文中的vision transformer还是使用的是class token和1d的位置信息编码方式
transformer encoder
transformer在现在看来是一个比较标准的操作了,作者对于transformer(或者说多头注意力机制)的解释放在附录中了
作者用整体的公式将整个过程总结了一下,如下图中的公式所示
_第23张图片](http://img.e-com-net.com/image/info8/d324e0ac744248788d7c3f56772a0918.jpg)
- X表示图像块的patch,一共有n个patch
- E表示线性投影的全连接层,得到一些patch embedding
- 得到patch embedding之后,在它前面拼接一个class embedding(Xclass),因为需要用它做最后的输出
- 一旦得到所有的tokens,就需要对这些token进行位置编码,所以将位置编码信息Epos也加进去
- Z0就是整个transformer的输入
- 接下来就是一个循环,对于每个transformer block来说,里面都有两个操作:一个是多头自注意力,一个是MLP。在做这两个操作之前,都要先经过layer norm,每一层出来的结果都要再去用一个残差连接
- ZL’就是每一个多头自注意力出来的结果
- ZL就是每一个transformer block整体做完之后出来的结果
- L层循环结束之后将ZL(最后一层的输出)的第一个位置上的ZL0,也就是class token所对应的输出当作整体图像的特征,然后去做最后的分类任务
归纳偏置
vision transformer相比于CNN而言要少很多图像特有的归纳偏置,比如在CNN中,locality(局部性)和translate equivariance(平移等变性)是在模型的每一层中都有体现的,这个先验知识相当于贯穿整个模型的始终
但是对于ViT来说,只有MLP layer是局部而且平移等变性的,但是自注意力层是全局的,这种图片的2d信息ViT基本上没怎么使用(就只有刚开始将图片切成patch的时候和加位置编码的时候用到了,除此之外,就再也没有用任何针对视觉问题的归纳偏置了)
而且位置编码其实也是刚开始随机初始化的,并没有携带任何2d的信息,所有关于图像块之间的距离信息、场景信息等,都需要从头开始学习
这里也是对后面的结果做了一个铺垫:vision transformer没有用太多的归纳偏置,所以说在中小数据集上做预训练的时候效果不如卷积神经网络是可以理解的
混合模型
既然transformer全局建模的能力比较强,卷积神经网络又比较data efficient(不需要太多的训练数据),所以搞出了一个混合的网络,前面是卷积神经网络,后面是transformer
作者对此做了实验:
- 原先是假设有一个图片,将它打成16*16的patch,得到了196个元素,这196个元素和全连接层做一次操作,最后得到patch embedding
- 现在不将图片打成块了,就按照卷积神经网络的方式去进行处理,将一整张图输入一个CNN,比如说Res50,最后出来一个14*14的特征图,这个特征图拉直了以后恰好也是196个元素,然后用新的到的196个元素去和全连接层做操作得到新的patch embedding
以上就是两种不同的对图片进行预处理的方式
- 一种是将图片打成patch,然后直接经过全连接层
- 另外一种就是经过一个CNN
因为这两种方式得到的序列的长度都是196,所以后续的操作都是一样的,都是直接输入一个transformer,最后再做分类
遇到更大尺寸图片的时候如何做微调
之前有工作说如果在微调的时候,能用比较大的图像尺寸(不是用224224,而是用256256,甚至更大的320*320,就会得到更好的结果)就能够得到更好的效果
vision transformer也想在在更大的尺寸上做微调,但是用一个预训练好的vision transformer其实是不太好去调整输入尺寸的。当使用更大尺寸的图片的时候,如果将patch size保持一致,但是图片扩大了,那么序列长度就增加了,所以transformer从理论上来讲是可以处理任意长度的,只要硬件允许,任意长度都可以。
但是提前预训练好的位置编码有可能就没用了,因为原来的位置编码是有明确的位置信息的意义在里面的,现在图片变大了,如果保持patch size不变的话,patch增多了,
- 这个时候位置编码该如何使用?作者发现其实做一个简单的2d的插值就可以了(使用torch官方自带的interpolate函数就可以完成了)。
- 但是这里的插值也不是想插多长就插多长,当从一个很短的序列变成一个很长的序列时,简单的插值操作会导致最终的效果下降,所以说这里的插值只是一种临时的解决方案,这也算是vision transformer在微调的时候的一个局限性
- 因为使用了图片的位置信息进行插值,所以这块的尺寸改变和抽图像块是vision transformer里唯一用到2d信息的归纳偏置的地方
实验
主要是对比了残差网络、vit和它们混合模型的表征学习能力
为了了解训练好每个模型到底需要多少数据,在不同大小的数据集上做预训练,然后在很多的数据集上做测试
当考虑到预训练的时间代价(预训练的时间长短)的时候,vision transformer表现得非常好,能在大多数数据集上取得最好的结果,同时需要更少的时间进行训练
最后作者还做了一个自监督的实验,自监督实验的结果虽然没有最好,但是还是可以,还是比较有潜力
- 时隔一年之后,MAE就证明了自监督的方式去训练ViT确实效果很好
数据集的使用方面主要是用了
- ImageNet的数据集:ImageNet-1k(最常用的有1000个类别、130万张图片)、ImageNet-21k(有21000个类别、1400万张图片)
- JFT数据集:Google自己的数据集(有3亿张图片)
下游任务全部是做的分类,用的也是比较常用的数据集
- CIFAR
- Oxford Pets
- Oxford Flowers
模型的变体
一共有三种模型,参数如下图所示
_第24张图片](http://img.e-com-net.com/image/info8/76bb76f079ab4a07bf09462c96385ebd.jpg)
- Base
- Large
- Huge
- Layers:transformer block的个数
- Hidden size D:向量维度
- MLP size:
- Heads:多头自注意力中头的数量
因为本文中的模型,不光跟transformer本身有关系,还和输入有关系。当patch size大小变化的时候,模型的位置编码就不一样,所以patch size也要考虑在模型的命名里面,所以模型的命名方式就是
- vit-l 16:表示用的是一个vit large的模型,输入的patch size是16*16
transformer的序列长度其实是跟patch size成反比的,因为patch size越小,切成的块就越多,patch size越大,切成的块就越少,所以当模型用了更小的patch size的时候计算起来就会更贵,因为序列长度增加了
结果如下图所示,下表是说当它已经在大规模的数据上进行过预训练之后,在左边这一列的数据集上去做fine-tune(微调)的时候得到的表现
_第25张图片](http://img.e-com-net.com/image/info8/20fc35ca700d4066952798472554b9a0.jpg)
- 上表对比了几个vit的变体和卷积神经网络(bit和noisy student)
- 和bit做对比的原因是因为bit确实是之前卷积神经网络里做得比较大的,而且也是因为他是作者团队自己本身的工作,所以正好可以拿来对比
- 和noisy student做对比是因为它是ImageNet之前表现最好的方法,它所采用的方法是用pseudo-label(伪标签)去进行self training,也就是常说的用伪标签也取得了很好的效果
- 从上表中可以看出,vit huge用比较小的patch 14*14能取得所有数据集上最好的结果。
但是因为这些数值都太接近了,仅仅相差零点几个点或者一点几个点,没有特别大的差距,所以作者觉得没有展示出vision transformer的威力,所以作者就得从另外一个角度来体现vit的优点:因为训练起来更便宜
- 作者所说的更便宜是指最大的vit huge这个模型也只需要训练2500天tpuv3天数,正好bit和noisy student也都是google的工作,也都是用tpuv3训练的,所以刚好可以拿来比较,bit用了9900天,noisy student用了一万多天,所以从这个角度上来说,vit不仅比之前bit和noisy student要训练的快,而且效果要好,所以通过这两点可以得出vit真的是比卷积神经网络要好的结论
分析
vision trasformer到底需要多少数据才能训练的比较好?
下图中图三是整个vision trasformer论文最重要的take home message,是作者最想让读者知道的,这张图基本上把所有的实验都快概括了
_第26张图片](http://img.e-com-net.com/image/info8/f345c86ed1664602a8f8d3b08a8de49c.jpg)
-
图三表示当时用不同大小的数据集的时候,比如说ImageNet是1.2m,而ImageNet-21k是14m,JFT是300m,当数据集不断增大的时候,resnet和vit到底在ImageNet的fine-tune的时候效果如何
-
图三的主要意思是说,灰色代表bit,也就是各种大小的resnet,最下面表示50,最上面表示152,如下图所示,他所想要展示的是在中间的灰色区域就是resnet能达到的效果范围,剩下的圆点就是各种大小不一的vision transformer
_第27张图片](http://img.e-com-net.com/image/info8/ea10241800d447a7bdc03d9b7647e161.jpg)
-
在最小的ImageNet上做预训练时,vision transformer是完全不如resnet,vision transformer基本上所有的点都在灰色区域的下面。这说明vision transformer在中小型数据集上做预训练的时候的效果是远不如残差网络的,原因就是因为vision transformer没有使用先验知识(归纳偏置),所以它需要更大的数据去让网络学得更好
-
在ImageNet-21k上做预训练的时候,vision transformer和resnet已经是差不多了,vision transformer基本上所有的点都落在灰色区域内
-
只有当用特别大的数据集JFT-300M时,vision transformer是比bit对应的res152还要高的
总之这个图所要表达的是两个信息
- 如果想用vision transformer,那么得至少准备差不多和ImageNet-21k差不多大小的数据集,如果只有很小的数据集,还是选择使用卷积神经网络比较好
- 当已经拥有了比ImageNet-21k更大的数据集的时候,用vision transformer就能得到更好的结果,它的扩展性更好一些
其实整篇论文所讲的就是这个scaling
图四如下图右图所示,因为作者在图三中要用vision transformer跟resnet做比较,所以在训练的时候用了一些强约束(比如说dropout、weight decay、label smoothing),所以就不太好分析vision transformer模型本身的特性,所以在图四中做了linear few-shot evaluation(在拿到预训练的模型之后,直接把它当成一个特征提取器,不去fine-tune,而是直接拿这些特征做了一个just take a regression就可以了),同时作者选择了few-shot,图示中标出了5-shot,就是在ImageNet上做linear evaluation的时候,每一类随机选取了5个sample,所以这个evaluation做起来是很快的,作者用这种方式做了大量的消融实验
_第28张图片](http://img.e-com-net.com/image/info8/afa543b3cd134f0a8acc504c1ed24bfa.jpg)
- 图四中横轴表示预训练数据集的大小,这里就使用了JFT,没有用别的数据集,但是他取了一些JFT的子集:10M、30M、100M、300M,这样因为所有的数据都是从一个数据集里面得来的,就没有那么大的distribution gap,这样比较起来模型的效果就更加能体现出模型本身的特质
- 图四中的结果其实跟图三差不多,图中浅灰色的线是res50,深灰色的线是res152,当用很小的预训练的数据集的时候vision transformer是完全比不过resnet的
- 本文给出的解释是因为缺少归纳偏置和约束方法(weight decay、label smoothing等),所以就导致在10M数据集的情况下vision transformer容易过拟合,导致最后学到的特征不适合做其他任务,但是随着预训练数据集的增大,vision transformer的稳健性就提升上来了
- 但是因为这里的提升也不是很明显,作者也在最后一段写了如何用vision transformer去做这种小样本的学习是一个非常有前途的方向
由于vision transformer这篇论文之前说了,**它的预训练比用卷积神经网络便宜,**所以这里就需要做更多的实验来支持它的论断,因为大家对transformer的印象都是又大又贵,很难训练,下图图五中画了两个表
_第29张图片](http://img.e-com-net.com/image/info8/af1af822c5fe4ccdad6e1c0a289d0c80.jpg)
图五
-
左图的average-5就是他在五个数据集(ImageNet real、pets、flowers、CIFAR-10、CIFAR-100)上做了evaluation,然后把这个数字平均了
-
因为ImageNet太重要了,所以作者将ImageNet单独拎出来又画了一张表,如右图所示
-
但是其实这两张表的结果都差不多
-
蓝色的圆点表示vit
-
灰色的圆点表示resnet
-
橙色的加号表示混合模型(前面是卷积神经网络,后面是transformer)
-
图中大大小小的点就是各种配置下大小不一样的vision transformer的变体,或者说是resnet的变体
-
左右两张图中所有的模型都是在JFT 300M数据集上训练的,作者这样训练的目的不想让模型的能力受限于数据集的大小,所以说所有的模型都在最大的数据集上做预训练
上图中几个比较有意思的现象
-
如果拿蓝色的圆圈所表示的vit去跟灰色圆圈的resnet作比较,就会发现,在同等计算复杂度的情况下,一般transformer都是比resnet要好的,这就证明了:训练一个transformer是要比训练一个卷积神经网络要便宜的
-
在比较小的模型上面,混合模型的精度是非常高的,它比对应的vision transformer和resnet都要高,按道理来讲,混合模型都应该是吸收了双方的优点:既不需要太多的数据去做预训练,同时又能达到跟vision transformer一样的效果
-
但是当随着模型越来越大的时候,混合模型就慢慢的跟vision transformer差不多了,甚至还不如在同等计算条件下的vision transformer,为什么卷积神经网络抽出来的特征没有帮助vision transformer更好的去学习?这里作者对此也没有做过多的解释,其实怎么预处理一个图像,怎么做tokenization是个非常重要的点,之后很多论文都去研究了这个问题
-
如果看整体趋势的话,随着模型的不断增加,vision transformer的效果也在不停地增加,并没有饱和的现象(饱和的话一般就是增加到一个平台就不增加了),还是在不停的往上走的。但是但从这个图中来看的话,其实卷积神经网络的效果也没有饱和
分析完训练成本以后,作者也做了一些可视化,希望通过这些可视化能够分析一下vit内部的表征
- vision transformer的第一层(linear projection layer,E),下图展示了E是如何embed rgb value,这里主要展示了头28个主成分,其实vision transformer学到了跟卷积神经网络很像,都是这种看起来像gabor filter,有颜色和纹理,所以作者说这些成分是可以当作基函数的,也就,它们可以用来描述每一个图像块的底层的结构
_第30张图片](http://img.e-com-net.com/image/info8/14e428ac1acc40388e4647a82a1df847.jpg)
- 位置编码是如何工作的?如下图所示,这张图描述的是位置编码的相似性,(vit_L_32)数字越大相似性越高(-1到1,cos),横纵坐标分别是对应的patch,如果是同一个坐标,自己和自己相比,相似性肯定是最高的。从图中可以发现,学到的位置编码是可以表示一些距离信息的,同时它还学习到了一些行和列的规则,每一个图像块都是同行同列的相似性更高,也就意味着虽然它是一个1d的位置编码,但是它已经学到了2d图像的距离概念,这也可以解释为什么在换成2d的位置编码以后,并没有得到效果上的提升,是因为1d已经够用了
_第31张图片](http://img.e-com-net.com/image/info8/cfc764a82fb34ffe8e82e05cee657a0e.png)
-
最后作者想看一下自注意力是否起作用了,只为之所以想用transformer,就是因为自注意力的操作能够模拟长距离的关系。在NLP中,一个很长的句子里开头的一个词和结尾的一个词也能互相有关联,类比在图像里很远的两个像素点也能够做自注意力,所以作者就是想看一下自注意力到底是不是想期待的一样去工作的。下图展示的是vit large 16这个模型,vit large有24层,所以横坐标所表示的网络深度就是从0到24,图中五颜六色的点就是每一层的transformer block中多头自注意力的头,对于vit large来说一共有16个头,所以每一列其实有16个点。纵轴所表示的是mean attention distance(平均注意力的距离:假如说图上有两个点,平均注意力距离表示的就是整两个点真正的像素之间差的距离乘以他们之间的attention weights,因为自注意力是全局都在做,所以说每个像素点跟每个像素点都会有一个自注意力权重,平均注意力的距离就能反映模型到底能不能注意到两个很远的像素)。图中的规律还还是比较明显的:投机层中,有的自注意力中的头注意的距离还是挺近的,能达到20个像素,但是有的头能达到120个像素,这也就证明了自注意力真的能够在网络最底层,也就是刚开始的时候就已经能够注意到全局上的信息了,而不是像卷神经网络一样,刚开始第一层的receptive field(感受野)非常小,只能看到附近的一些像素;随着网络越来越深,网络学到的特征也会变得越来越高级,越来越具有语义信息;大概在网络的后半部分,模型的自注意力的距离已经非常远了,也就是说它已经学到了带有语义性的概念,而不是靠邻近的像素点去进行判断
_第32张图片](http://img.e-com-net.com/image/info8/b23a4884cbc3457885883ff0569949dc.jpg)
-
为了验证上面所得到的结论,作者又画了另外一个图,如下图所示。图中是用网络中最后一层的out token所作的图,从图中可以发现,如果用输出的token的自注意力折射回原来的输入图片,可以发现模型确实是学习到了这些概念。对于全局来说,因为输出的token是融合了所有的信息(全局的特征),模型已经可以关注到与最后分类有关的图像区域
_第33张图片](http://img.e-com-net.com/image/info8/e37a07a5df5f41e3a18582ba812093f9.jpg)
在文章的最后,作者还做了如何用自监督的方式去训练vision transformer的测试
这篇论文算上附录22页,在这么多的结果中,作者把别的结果都放到了附录里,而把自监督放到了正文中,可见它的重要性。它之所重要主要是因为在nlp领域,transformer这个模型确实起到了很大的推动作用,但另外一个真正让transformer火起来的原因其实是大规模的自监督训练,二者缺一不可。NLP中的自监督无非就是完形填空或者是预测下一个词,但是因为这篇论文主要仿照的是BERT,所以作者就想能不能也借鉴BERT这个目标函数去创建一个专属于vision的目标函数,BERT使用的就是完形填空(mask language modeling,给定一个句子,然后将一些词mask掉,然后通过一个模型,最后将它预测出来),同理,本文就仿造了一个mask patch prediction,意思就是给定一张图片,将它打成很多patch,然后将某些patch随机抹掉,通过这个模型以后,再将这些patch重建出来。
但是最后vit base 16在ImageNet只能达到80的左右的准确率,虽然相对于从头来训练vision transformer已经提高了两个点,但是跟最好的有监督的训练方式比差了4个点,所以作者将跟对比学习的结果当作是未来的工作(对比学习是去年CV圈最火的人们话题,是所有自监督学习中表现最好的,所以紧接着vit MoCo v3和DINO就出现了,这两篇论文都是用对比学习的方式去训练了一个vision transformer)
评价
这篇论文写的还是相当简洁明了的,在有这么多内容和结果的情况下,做到了有轻有重,把最重要的结果都放到了论文里,图和表也都做的一目了然
从内容上来说,可以从各个角度来进行分析、提高或者推广vision transformer
-
如果从任务角度来说,vision transformer只是做了分类,所以还可以拿他去做检测、分割甚至别的领域的任务
-
如果从改变结构的角度来讲,可以去改变刚开始的tokenization,也可以改中间的transformer block,后来就已经有人将自注意力换成了MLP,而且还是可以工作得很好(几天前,甚至有一篇论文叫做mataformer,他认为transformer真正工作的原因是transformer这个架构而不是因为某些算子,所以他就将自注意力直接换成了池化操作然后发现,用一个甚至不能学习的池化操作(文中提出了一个pool former模型)也能在视觉领域取得很好的效果),所以在模型的改进上也大有可为
-
如果从目标函数来讲,可以继续采用有监督,也可以尝试很多不同的自监督训练的方式
最重要的是vit打破了NLP和CV之间的鸿沟,挖了一个更大的多模态的坑,可以用它去做视频、音频,甚至还可以去做一些基于touch的信号,也就是说各种modality的信号都可以拿来使用
_第34张图片](http://img.e-com-net.com/image/info8/1466b3b8625d46fabd9693943b6a8b67.jpg)
_第35张图片](http://img.e-com-net.com/image/info8/00d8e41ba51842bca50ea2abdf2c90c1.jpg)
[2021] (ICCV) Swin transformer: Hierarchical vision transformer using shifted windows
_第36张图片](http://img.e-com-net.com/image/info8/75b5cb5c9ec0436d9a86396476f5f9b2.jpg)
参考
题目
Swin Transformer是一个用了移动窗口的层级式的Vision Transformer
- Swin:来自于 Shifted Windows ,S 和 win,Shifted Window(移动窗口)也是 Swin Transformer这篇论文的主要贡献
- 层级式 Hierarchical
其实 Swin Transformer就是想让 Vision Transformer像卷积神经网络一样,也能够分成几个 block,也能做层级式的特征提取,从而导致提出来的特征有多尺度的概念
作者团队来自 MSRA
- MSRA 经常被誉为是研究者的黄埔军校,从里面出来了一众大佬,而且产出了一系列非常有影响力的工作,比如说大家耳熟能详的、现在单篇引用已经超过10万的 ResNet,也是四位作者都在 MSRA 的时候完成的工作
摘要
这篇论文提出了一个新的 Vision Transformer 叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络
- 之所以这么说,是因为ViT 在结论的部分指出,他们那篇论文只是做了分类任务,把下游任务比如说检测和分割留给以后的人去探索,所以说在 ViT 出来之后,大家虽然看到了Transformer在视觉领域的强大潜力,但是并不确定Transformer能不能把所有视觉的任务都做掉,所以 Swin Transformer这篇论文的研究动机就是想告诉大家用 Transformer没毛病,绝对能在方方面面上取代卷积神经网络,接下来大家都上 Transformer 就好了
但是直接把Transformer从 NLP 用到 Vision 是有一些挑战的,这个挑战主要来自于两个方面
- 一个就是尺度上的问题。因为比如说现在有一张街景的图片,里面有很多车和行人,里面的物体都大大小小,那这时候代表同样一个语义的词,比如说行人或者汽车就有非常不同的尺寸,这种现象在 NLP 中就没有
- 另外一个挑战是图像的 resolution太大了,如果要以像素点作为基本单位的话,序列的长度就变得高不可攀,所以说之前的工作要么就是用后续的特征图来当做Transformer的输入,要么就是把图片打成 patch 减少这个图片的 resolution,要么就是把图片画成一个一个的小窗口,然后在窗口里面去做自注意力,所有的这些方法都是为了减少序列长度
基于这两个挑战,本文的作者就提出了 hierarchical Transformer,它的特征是通过一种叫做移动窗口的方式学来的
- 移动窗口的好处:不仅带来了更大的效率,因为跟之前的工作一样,现在自注意力是在窗口内算的,所以这个序列的长度大大的降低了;同时通过 shifting 移动的这个操作,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有 cross-window connection,从而变相的达到了一种全局建模的能力
然后作者说这种层级式的结构不仅非常灵活,可以提供各个尺度的特征信息,同时因为自注意力是在小窗口之内算的,所以说它的计算复杂度是随着图像大小而线性增长,而不是平方级增长,这其实也为作者之后提出 Swin V2 铺平了道路,从而让他们可以在特别大的分辨率上去预训练模型
因为 Swin Transformer 拥有了像卷积神经网络一样分层的结构,有了这种多尺度的特征,所以它很容易使用到下游任务里,所以在这篇论文里,作者不光是在 ImageNet-1K 上做了实验,而且达到了非常好的准确度87.3;而且还在密集预测型的任务上,比如说物体检测、物体分割上取得了很好的成绩,比如说在 COCO 上刷到58.7的 AP,比之前最好的方法高了2.7个点;然后在语义分割上,ADE上 也刷到了53.5,比之前最好的方法高了3.2个点
这些数据集其实都是大家常刷的数据集,在上面往往只要能提升一个点,甚至可能不到一个点,只要故事讲的好可能都能发论文,但是 Swin Transformer 都提的大概3个点,提升是相当显著的,所以作者说这种基于 Transformer 的模型在视觉领域是非常有潜力的
为了凸显这篇文章的贡献,也就是 Shifted Windows 移动窗口的作用,这个版本又加了一句话:对于 MLP 的架构用 shift window 的方法也能提升,这句话其实这个版本才加入的,之前第一个版本就是投稿上那篇论文其实没有这句话,因为当时还没有 MLP Mixer 这篇论文
引言
引言的前两段其实跟 ViT 非常一致,都是先说在视觉领域,之前卷积神经网络是主导地位,但是Transformer在 NLP 领域用的这么好,所以也想把Transformer用到视觉领域里面
但因为 ViT 已经把这件事干了,所以说Swin Transformer在第三段的开始说他们的研究动机,是想证明Transformer是可以用作一个通用的骨干网络,就是对所有视觉的任务,不光是分类,在检测、分割视频上也都能取得很好的效果
_第37张图片](http://img.e-com-net.com/image/info8/a54ab6085ff64d0c9830325ceeb59d7d.jpg)
图1所示。(a)拟议的Swin Transformer通过在更深的层中合并图像块(如图灰色部分)来构建分层特征映射,由于只在每个局部窗口内(如图红色部分)进行自我注意计算,对输入图像大小具有线性计算复杂度。因此,它可以作为图像分类和密集识别任务的通用骨干。(b)相比之下,以前的视觉变形金刚[20]产生单一低分辨率的特征图,由于全局自注意计算,对输入图像大小的计算复杂度为二次型。
- 图一如上图所示,作者先说了一下 Vision Transformer,把它放在右边做对比
- Vision Transformer就是把图片打成 patch,因为 ViT 里用的 patch size 是16*16的,所以说这里的16 ×,也就意味着是16倍的下采样率,这也就意味着每一个 patch,也就是每一个 token,自始至终代表的尺寸都是差不多的;每一层的Transformer block 看到token的尺寸都是16倍下采样率。虽然它可以通过这种全局的自注意力操作,达到全局的建模能力,但是它对多尺寸特征的把握就会弱一些
- 对于视觉任务,尤其是下游任务比如说检测和分割来说,多尺寸的特征是至关重要的,比如说对目标检测而言,运用最广的一个方法就是 FPN(a feature pyramid network:当有一个分层式的卷积神经网络之后,每一个卷积层出来的特征的 receptive field (感受野)是不一样的,能抓住物体不同尺寸的特征,从而能够很好的处理物体不同尺寸的问题;对于物体分割任务来说,那最常见的一个网络就是 UNet,UNet 里为了处理物体不同尺寸的问题,提出来一个叫做 skip connection 的方法,当一系列下采样做完以后,去做上采样的时候,不光是从 bottleneck 里去拿特征,还从之前也就是每次下采样完之后的东西里去拿特征,这样就把那些高频率的图像细节又全都能恢复出来了,当然分割里大家常用的网络结构还有 PspNet 、DeepLab,这些工作里也有相应的处理多尺寸的方法,比如说使用空洞卷积、使用 psp 和 aspp 层
_第38张图片](http://img.e-com-net.com/image/info8/b2c6eca11b674844a60873a98255592e.jpg)
- 总之,对于计算机视觉的下游任务,尤其是密集预测型的任务(检测、分割),有多尺寸的特征是至关重要的
但是在 ViT 里处理的特征都是单一尺寸,而且是 low resolution,也就是说自始至终都是处理的16倍下采样率过后的特征,所以说,它可能就不适合处理这种密集预测型的任务,同时对 ViT 而言,自注意力始终都是在最大的窗口上进行,也就是说始终都是在整图上进行的,所以它是一个全局建模,它的复杂度是跟随图像的尺寸进行平方倍的增长,像检测和分割领域,一般现在常用的输入尺寸都是800乘以800或者1000乘1000,之前虽然用 patch size 16能处理 224*224 的图片,但是当图片变到这么大的时候,即使用patch size16,序列长度还是会上千,计算复杂度还是难以承受的
所以基于这些挑战,作者提出了 Swin Transformer,Swin Transformer 其实是借鉴了很多卷积神经网络的设计理念以及先验知识
-
比如说为了减少序列的长度、降低计算复杂度,Swin Transformer采取了在小窗口之内算自注意力,而不是像 ViT 一样在整图上算自注意力,这样只要窗口大小是固定的,自注意力的计算复杂度就是固定的,整张图的计算复杂度就会跟图片的大小而成的线性增长关系,就是说图片增大了 x 倍,窗口数量也增大了 x 倍,计算复杂度也就乘以 x,而不是乘以 x 的平方
-
这个就算是利用了卷积神经网络里的 Locality 的 Inductive bias,就是利用了局部性的先验知识,同一个物体的不同部位或者语义相近的不同物体还是大概率会出现在相连的地方,所以即使是在一个 Local,一个小范围的窗口算自注意力也是差不多够用的,全局计算自注意力对于视觉任务来说,其实是有点浪费资源的
-
另外一个挑战是如何生成多尺寸的特征,卷积神经网络为什么会有多尺寸的特征?主要是因为有 Pooling (池化)这个操作,池化能够增大每一个卷积核能看到的感受野,从而使得每次池化过后的特征抓住物体的不同尺寸,所以类似的 ,Swin Transformer也提出来了一个类似于池化的操作叫做 patch merging,就是把相邻的小 patch 合成一个大 patch,这样合并出来的这一个大patch其实就能看到之前四个小patch看到的内容,它的感受野就增大了,同时也能抓住多尺寸的特征
-
所以所上图中图一左边所示,Swin Transformer 刚开始的下采样率是4倍,然后变成了8倍、16倍,之所以刚开始是4×的,是因为最开始的 patch 是4乘4大小的,一旦有了多尺寸的特征信息,有了这种4x、8x、16x的特征图,那自然就可以把这些多尺寸的特征图输给一个 FPN,从而就可以去做检测了
-
同样的道理,有了这些多尺寸的特征图以后,也可以把它扔给一个 UNET,然后就可以去做分割了
-
所以这就是作者在这篇论文里反复强调的,Swin Transformer是能够当做一个通用的骨干网络的,不光是能做图像分类,还能做密集预测性的任务
第四段主要就开始讲 Swin Transformer一个关键的设计因素----移动窗口的操作,如下图中图二所示
_第39张图片](http://img.e-com-net.com/image/info8/0d4b5dbe17db4ac4aff2a602037ed57d.jpg)
- 如果在 Transformer 第 L 层把输入或者特征图分成小窗口的话,就会有效的降低序列长度,从而减少计算复杂度
- 图中每一个灰色的小 patch 是最基本的元素单元,也就是图一中4*4的 patch;每个红色的框是一个中型的计算单元,也就是一个窗口
- 在 Swin Transformer 这篇论文里,一个小窗口里面默认有七七四十九个小patch的
shift 的操作
如果用一个大的蓝色的正方形来描述整体的特征图,其实 shift 操作就是往右下角的方向整体移了两个 patch,也就变成了像下图中右图的格式
然后在新的特征图里把它再次分成四方格,如下图中右图所示
最后 shift 完就能得到下图中红线标出的结果了
这样的好处是窗口与窗口之间可以进行互动,因为如果按照原来的方式,就是没有 shift,这些窗口之间都是不重叠的,如果每次自注意力的操作都在小的窗口里头进行了,每个窗口里的 patch 就永远无法注意到别的窗口里的 patch 的信息,这就达不到使用 Transformer 的初衷
- 因为Transformer的初衷就是更好的理解上下文,如果窗口都是不重叠的,那自注意力真的就变成孤立自注意力,就没有全局建模的能力
- 但如果加上 shift 的操作,每个 patch 原来只能跟它所在的窗口里的别的 patch 进行交互,但是 shift 之后,这个 patch就可以跟新的窗口里的别的 patch就进行交互了,而这个新的窗口里所有的 patch 其实来自于上一层别的窗口里的 patch,这也就是作者说的能起到 cross-window connection,就是窗口和窗口之间可以交互了
再配合上之后提出的 patch merging,合并到 Transformer 最后几层的时候,每一个 patch 本身的感受野就已经很大了,就已经能看到大部分图片了,然后再加上移动窗口的操作,它所谓的窗口内的局部注意力其实也就变相的等于是一个全局的自注意力操作了
- 这样就是既省内存,效果也好
第五段作者再次展示了一下结果,因为 Swin Transformer 的结果确实非常好,最后一段作者就展望了一下,作者说他们坚信一个 CV 和NLP 之间大一统的框架是能够促进两个领域共同发展的
- 确实如此,因为人在学习的过程中也是一个多模态的学习过程,但 Swin Transformer还是利用了更多视觉里的先验知识,从而在视觉任务上大杀四方
- 但是在模型大一统上,也就是 unified architecture 上来说,其实 ViT 还是做的更好的,因为它真的可以什么都不改,什么先验信息都不加,就能让Transformer在两个领域都能用的很好,这样模型不仅可以共享参数,而且甚至可以把所有模态的输入直接就拼接起来,当成一个很长的输入,直接扔给Transformer去做,而不用考虑每个模态的特性
结论
这篇论文提出了 Swin Transformer,它是一个层级式的Transformer,而且它的计算复杂度是跟输入图像的大小呈线性增长的
Swin Transformerr 在 COCO 和 ADE20K上的效果都非常的好,远远超越了之前最好的方法,所以作者说基于此,希望 Swin Transformer 能够激发出更多更好的工作,尤其是在多模态方面
因为在Swin Transformer 这篇论文里最关键的一个贡献就是基于 Shifted Window 的自注意力,它对很多视觉的任务,尤其是对下游密集预测型的任务是非常有帮助的,但是如果 Shifted Window 操作不能用到 NLP 领域里,其实在模型大一统上论据就不是那么强了,所以作者说接下来他们的未来工作就是要把 Shifted Windows用到 NLP 里面,而且如果真的能做到这一点,那 Swin Transformer真的就是一个里程碑式的工作了,而且模型大一统的故事也就讲的圆满了
方法
主要分为两大块
- 大概把整体的流程讲了一下,主要就是过了一下前向过程,以及提出的 patch merging 操作是怎么做的
- 基于 Shifted Window 的自注意力,Swin Transformer怎么把它变成一个transformer block 进行计算
模型总览图如下图所示
_第40张图片](http://img.e-com-net.com/image/info8/44893896e4e444bea532c2059130cb2d.jpg)
前向过程
- 假设说有一张2242243(ImageNet 标准尺寸)的输入图片
- 第一步就是像 ViT 那样把图片打成 patch,在 Swin Transformer 这篇论文里,它的 patch size 是44,而不是像 ViT 一样1616,所以说它经过 patch partition 打成 patch 之后,得到图片的尺寸是565648,56就是224/4,因为 patch size 是4,向量的维度48,因为443,3 是图片的 RGB 通道
- 打完了 patch ,接下来就要做 Linear Embedding,也就是说要把向量的维度变成一个预先设置好的值,就是 Transformer 能够接受的值,在 Swin Transformer 的论文里把这个超参数设为 c,对于 Swin tiny 网络来说,也就是上图中画的网络总览图,它的 c 是96,所以经历完 Linear Embedding 之后,输入的尺寸就变成了565696,前面的56*56就会拉直变成3136,变成了序列长度,后面的96就变成了每一个token向量的维度,其实 Patch Partition 和 Linear Embedding 就相当于是 ViT 里的Patch Projection 操作,而在代码里也是用一次卷积操作就完成了,
- 第一部分跟 ViT 其实还是没有区别的,但紧接着区别就来了
- 首先序列长度是3136,对于 ViT 来说,用 patch size 16*16,它的序列长度就只有196,是相对短很多的,这里的3136就太长了,是目前来说Transformer不能接受的序列长度,所以 Swin Transformer 就引入了基于窗口的自注意力计算,每个窗口按照默认来说,都只有七七四十九个 patch,所以说序列长度就只有49就相当小了,这样就解决了计算复杂度的问题
- 所以也就是说, stage1中的swin transformer block 是基于窗口计算自注意力的,现在暂时先把 transformer block当成是一个黑盒,只关注输入和输出的维度,对于 Transformer 来说,如果不对它做更多约束的话,Transformer输入的序列长度是多少,输出的序列长度也是多少,它的输入输出的尺寸是不变的,所以说在 stage1 中经过两层Swin Transformer block 之后,输出还是565696
- 到这其实 Swin Transformer的第一个阶段就走完了,也就是先过一个 Patch Projection 层,然后再过一些 Swin Transformer block ,接下来如果想要有多尺寸的特征信息,就要构建一个层级式的 transformer,也就是说需要一个像卷积神经网络里一样,有一个类似于池化的操作
这篇论文里作者就提出 Patch Merging 的操作,Patch Merging 其实在之前一些工作里也有用到,它很像 Pixel Shuffle 的上采样的一个反过程,Pixel Shuffle 是 lower level 任务中很常用的一个上采样方式
Patch Merging 操作举例如下图所示
_第41张图片](http://img.e-com-net.com/image/info8/d5b0f7ac65b042faa7c819b446e91a7f.jpg)
-
假如有一个张量, Patch Merging 顾名思义就是把临近的小 patch 合并成一个大 patch,这样就可以起到下采样一个特征图的效果了
-
这里因为是想下采样两倍,所以说在选点的时候是每隔一个点选一个,也就意味着说对于这个张量来说,每次选的点是1、1、1、1
-
其实在这里的1、2、3、4并不是矩阵里有的值,而是给它的一个序号,同样序号位置上的 patch 就会被 merge 到一起,这个序号只是为了帮助理解
-
经过隔一个点采一个样之后,原来的这个张量就变成了四个张量,也就是说所有的1都在一起了,2在一起,3在一起,4在一起,如果原张量的维度是 h * w * c ,当然这里 c 没有画出来,经过这次采样之后就得到了4个张量,每个张量的大小是 h/2、w/2,它的尺寸都缩小了一倍
-
现在把这四个张量在 c 的维度上拼接起来,也就变成了下图中红线所画出来的形式,张量的大小就变成了 h/2 * w/2 * 4c,相当于用空间上的维度换了更多的通道数
-
通过这个操作,就把原来一个大的张量变小了,就像卷积神经网络里的池化操作一样,为了跟卷积神经网络那边保持一致(不论是 VGGNet 还是 ResNet,一般在池化操作降维之后,通道数都会翻倍,从128变成256,从256再变成512),所以这里也只想让他翻倍,而不是变成4倍,所以紧接着又再做了一次操作,就是在 c 的维度上用一个1乘1的卷积,把通道数降下来变成2c,通过这个操作就能把原来一个大小为 hwc 的张量变成 h/2 * w/2 *2c 的一个张量,也就是说空间大小减半,但是通道数乘2,这样就跟卷积神经网络完全对等起来了
整个这个过程就是 Patch Merging,经历过这次Patch Merging操作之后,输出的大小就从565696变成了2828192,经过stage2中的 Transformer block,尺寸是不变的,所以出来之后还是2828192
这样第二阶段也就完成了,第三和第四阶段都是同理,都是先进来做一次Patch Merging,然后再通过一些 Swin Transformer block,所以维度就进一步降成了1414384以及77768
这里其实会发现,特征图的维度真的跟卷积神经网络好像,因为如果回想残差网络的多尺寸的特征,就是经过每个残差阶段之后的特征图大小也是5656、2828、1414,最后是77
而且为了和卷积神经网络保持一致**,Swin Transformer这篇论文并没有像 ViT 一样使用 CLS token**,ViT 是给刚开始的输入序列又加了一个 CLS token,所以这个长度就从196变成了197,最后拿 CLS token 的特征直接去做分类,但 Swin Transformer 没有用这个 token,它是像卷积神经网络一样,在得到最后的特征图之后用global average polling,就是全局池化的操作,直接把7*7就取平均拉直变成1了
作者这个图里并没有画,因为 Swin Transformer的本意并不是只做分类,它还会去做检测和分割,所以说它只画了骨干网络的部分,没有去画最后的分类头或者检测头,但是如果是做分类的话,最后就变成了1768,然后又变成了11,000
- 如果是做ImageNet的话,这样就完成了整个一个分类网络的前向过程
所以看完整个前向过程之后,就会发现 Swin Transformer 有四个 stage,还有类似于池化的 patch merging 操作,自注意力还是在小窗口之内做的以及最后还用的是 global average polling,所以说 Swin Transformer 这篇论文真的是把卷积神经网络和 Transformer 这两系列的工作完美的结合到了一起,也可以说它是披着Transformer皮的卷积神经网络
主要贡献
这篇论文的主要贡献就是基于窗口或者移动窗口的自注意力,这里作者又写了一段研究动机,就是为什么要引入窗口的自注意力,其实跟之前引言里说的都是一个事情,就是说全局自注意力的计算会导致平方倍的复杂度,同样当去做视觉里的下游任务,尤其是密集预测型的任务,或者说遇到非常大尺寸的图片时候,这种全局算自注意力的计算复杂度就非常贵了,所以就用窗口的方式去做自注意力
窗口划分举例
原图片会被平均的分成一些没有重叠的窗口,拿第一层之前的输入来举例,它的尺寸就是565696,也就说有一个维度是56*56张量,然后把它切成一些不重叠的方格,也就是下图中用橘黄色表示的方格
- 每一个橘黄色的方格就是一个窗口,但是这个窗口并不是最小的计算单元,最小的计算单元其实还是之前的那个 patch,也就意味着每一个小窗口里其实还有 m * m 个 patch,在 Swin Transformer 这篇论文里一般 m 默认为7,也就是说,一个橘黄色的小方格里有七七四十九个小 patch
- 现在所有自注意力的计算都是在这些小窗口里完成的,就是说序列长度永远都是七七四十九
- 原来大的整体特征图到底里面会有多少个窗口呢?其实也就是每条边56/7就8个窗口,也就是说一共会有8*8等于64个窗口,就是说会在这64个窗口里分别去算它们的自注意力
基于窗口的自注意力模式的计算复杂度
说到底,基于窗口的自注意力计算方式能比全局的自注意力方式省多少呢?在Swin Transformer这篇论文里作者就给出了一个大概的估计,它给出了两个公式如下图所示
_第42张图片](http://img.e-com-net.com/image/info8/ccf3bfddd70f434b80c5754fa9c095e3.jpg)
- 公式(1)对应的是标准的多头自注意力的计算复杂度
- 每一个图片大概会有 h*w 个 patch,在刚才的例子里,h 和 w 分别都是56,c 是特征的维度
- 公式(2)对应的是基于窗口的自注意力计算的复杂度,这里的 M 就是刚才的7,也就是说一个窗口的某条边上有多少个patch
公式推算
以标准的多头自注意力为例
- 如果现在有一个输入,自注意力首先把它变成 q k v 三个向量,这个过程其实就是原来的向量分别乘了三个系数矩阵
- 一旦得到 query 和 k 之后,它们就会相乘,最后得到 attention,也就是自注意力的矩阵
- 有了自注意力之后,就会和 value 做一次乘法,也就相当于是做了一次加权
- 最后因为是多头自注意力,所以最后还会有一个 projection layer,这个投射层会把向量的维度投射到我们想要的维度
如果这些向量都加上它们该有的维度,也就是说刚开始输入是 hwc
- 首先,to_q_k_v()函数相当于是用一个 hwc 的向量乘以一个 cc 的系数矩阵,最后得到了 hwc。所以每一个计算的复杂度是 hwc^2,因为有三次操作,所以是三倍的 hw*c^2
- 然后,算自注意力就是 hwc乘以 k 的转置,也就是 chw,所以得到了 hwhw,这个计算复杂度就是(hw)^2*c
- 接下来,自注意力矩阵和value的乘积的计算复杂度还是 (hw)2*c,所以现在就成了2*(h*w)2c
- 最后一步,投射层也就是hwc乘以 cc 变成了 hwc ,它的计算复杂度就又是 hw*c^2
- 最后合并起来就是最后的公式(1)
基于窗口的自注意力计算复杂度又是如何得到的呢?
- 因为在每个窗口里算的还是多头自注意力,所以可以直接套用公式(1),只不过高度和宽度变化了,现在高度和宽度不再是 h * w,而是变成窗口有多大了,也就是 M*M,也就是说现在 h 变成了 M,w 也是 M,它的序列长度只有 M * M 这么大
- 所以当把 M 值带入到公式(1)之后,就得到计算复杂度是4 * M^2 * c^2 + 2 * M^4 * c,这个就是在一个窗口里算多头自注意力所需要的计算复杂度
- 那我们现在一共有 h/M * w/M 个窗口,现在用这么多个窗口乘以每个窗口所需要的计算复杂度就能得到公式(2)了
对比公式(1)和公式(2),虽然这两个公式前面这两项是一样的,只有后面从 (hw)^2变成了 M^2 * h * w,看起来好像差别不大,但其实如果仔细带入数字进去计算就会发现,计算复杂的差距是相当巨大的,因为这里的 hw 如果是56*56的话, M^2 其实只有49,所以是相差了几十甚至上百倍的
这种基于窗口计算自注意力的方式虽然很好地解决了内存和计算量的问题,但是窗口和窗口之间没有通信,这样就达不到全局建模了,也就文章里说的会限制模型的能力,所以最好还是要有一种方式能让窗口和窗口之间互相通信起来,这样效果应该会更好,因为具有上下文的信息,所以作者就提出移动窗口的方式
移动窗口就是把原来的窗口往右下角移动一半窗口的距离,如果Transformer是上下两层连着做这种操作,先是 window再是 shifted window 的话,就能起到窗口和窗口之间互相通信的目的了
所以说在 Swin Transformer里, transformer block 的安排是有讲究的,每次都是先要做一次基于窗口的多头自注意力,然后再做一次基于移动窗口的多头自注意力,这样就达到了窗口和窗口之间的互相通信。如下图所示
_第43张图片](http://img.e-com-net.com/image/info8/a99cf319056d4a86a8c96a3e766ee6d1.jpg)
- 每次输入先进来之后先做一次 Layernorm,然后做窗口的多头自注意力,然后再过 Layernorm 过 MLP,第一个 block 就结束了
- 这个 block 结束以后,紧接着做一次Shifted window,也就是基于移动窗口的多头自注意力,然后再过 MLP 得到输出
- 这两个 block 加起来其实才算是 Swin Transformer 一个基本的计算单元,这也就是为什么stage1、2、3、4中的 swin transformer block 为什么是 *2、*2、*6、*2,也就是一共有多少层 Swin Transformer block 的数字总是偶数,因为它始终都需要两层 block连在一起作为一个基本单元,所以一定是2的倍数
到此,Swin Transformer整体的故事和结构就已经讲完了,主要的研究动机就是想要有一个层级式的 Transformer,为了这个层级式,所以介绍了 Patch Merging 的操作,从而能像卷积神经网络一样把 Transformer 分成几个阶段,为了减少计算复杂度,争取能做视觉里密集预测的任务,所以又提出了基于窗口和移动窗口的自注意力方式,也就是连在一起的两个Transformer block,最后把这些部分加在一起,就是 Swin Transformer 的结构
其实作者后面还讲了两个点
- 一个是怎样提高移动窗口的计算效率,他们采取了一种非常巧妙的 masking(掩码)的方式
- 另外一个点就是这篇论文里没有用绝对的位置编码,而是用相对的位置编码
但这两个点其实都是为了提高性能的一些技术细节,跟文章整体的故事已经没有多大关系了
_第44张图片](http://img.e-com-net.com/image/info8/a461686699a349d681cfcaad00596d76.jpg)
-
上图是一个基础版本的移动窗口,就是把左边的窗口模式变成了右边的窗口方式
-
虽然这种方式已经能够达到窗口和窗口之间的互相通信了,但是会发现一个问题,就是原来计算的时候,特征图上只有四个窗口,但是做完移动窗口操作之后得到了9个窗口,窗口的数量增加了,而且每个窗口里的元素大小不一,比如说中间的窗口还是4*4,有16个 patch,但是别的窗口有的有4个 patch,有的有8个 patch,都不一样了,如果想做快速运算,就是把这些窗口全都压成一个 patch直接去算自注意力,就做不到了,因为窗口的大小不一样
-
有一个简单粗暴的解决方式就是把这些小窗口周围再 pad 上0 ,把它照样pad成和中间窗口一样大的窗口,这样就有9个完全一样大的窗口,这样就还能把它们压成一个batch,就会快很多
-
但是这样的话,无形之中计算复杂度就提升了,因为原来如果算基于窗口的自注意力只用算4个窗口,但是现在需要去算9个窗口,复杂度一下提升了两倍多,所以还是相当可观的
-
那怎么能让第二次移位完的窗口数量还是保持4个,而且每个窗口里的patch数量也还保持一致呢?作者提出了一个非常巧妙的掩码方式,如下图所示
_第45张图片](http://img.e-com-net.com/image/info8/e1c5a372e23f41cfb37988fe3f2fcb67.jpg)
-
上图是说,当通过普通的移动窗口方式,得到9个窗口之后,现在不在这9个窗口上算自注意力,先再做一次循环移位( cyclic shift )
-
经过这次循环移位之后,原来的窗口(虚线)就变成了现在窗口(实线)的样子,那如果在大的特征图上再把它分成四宫格的话,我在就又得到了四个窗口,意思就是说移位之前的窗口数也是4个,移完位之后再做一次循环移位得到窗口数还是4个,这样窗口的数量就固定了,也就说计算复杂度就固定了
-
但是新的问题就来了,虽然对于移位后左上角的窗口(也就是移位前最中间的窗口)来说,里面的元素都是互相紧挨着的,他们之间可以互相两两做自注意力,但是对于剩下几个窗口来说,它们里面的元素是从别的很远的地方搬过来的,所以他们之间,按道理来说是不应该去做自注意力,也就是说他们之间不应该有什么太大的联系
-
解决这个问题就需要一个很常规的操作,也就是掩码操作,这在Transformer过去的工作里是层出不穷,很多工作里都有各式各样的掩码操作
-
在 Swin Transformer这篇论文里,作者也巧妙的设计了几种掩码的方式,从而能让一个窗口之中不同的区域之间也能用一次前向过程,就能把自注意力算出来,但是互相之间都不干扰,也就是后面的 masked Multi-head Self Attention(MSA)
-
算完了多头自注意力之后,还有最后一步就是需要把循环位移再还原回去,也就是说需要把A、B、C再还原到原来的位置上去,原因是还需要保持原来图片的相对位置大概是不变的,整体图片的语义信息也是不变的,如果不把循环位移还原的话,那相当于在做Transformer的操作之中,一直在把图片往右下角移,不停的往右下角移,这样图片的语义信息很有可能就被破坏掉了
-
所以说整体而言,上图介绍了一种高效的、批次的计算方式,比如说本来移动窗口之后得到了9个窗口,而且窗口之间的patch数量每个都不一样,为了达到高效性,为了能够进行批次处理,先进行一次循环位移,把9个窗口变成4个窗口,然后用巧妙的掩码方式让每个窗口之间能够合理地计算自注意力,最后再把算好的自注意力还原,就完成了基于移动窗口的自注意力计算
掩码操作举例
掩码可视化
_第46张图片](http://img.e-com-net.com/image/info8/f4cbe86c5afe48bb9bf9181433afe8df.jpg)
_第47张图片](http://img.e-com-net.com/image/info8/c1754a2071c04b03b49b95dbd79274a2.jpg)
_第48张图片](http://img.e-com-net.com/image/info8/b504456551a04ba5b3abc706b69164ae.jpg)
- 作者通过这种巧妙的循环位移的方式和巧妙设计的掩码模板,从而实现了只需要一次前向过程,就能把所有需要的自注意力值都算出来,而且只需要计算4个窗口,也就是说窗口的数量没有增加,计算复杂度也没有增加,非常高效的完成了这个任务
在方法的最后一节也就是3.3节,作者大概介绍了一下他们提出的 Swin Transformer的几个变体
Swin Tiny
Swin Small
Swin Base
Swin Large
Swin Tiny的计算复杂度跟 ResNet-50 差不多,Swin Small 的复杂度跟 ResNet-101 是差不多的,这样主要是想去做一个比较公平的对比
这些变体之间有哪些不一样呢?,其实主要不一样的就是两个超参数
- 一个是向量维度的大小 c
- 另一个是每个 stage 里到底有多少个 transform block
这里其实就跟残差网络就非常像了,残差网络也是分成了四个 stage,每个 stage 有不同数量的残差块
消融实验
实验结果如下图所示
_第49张图片](http://img.e-com-net.com/image/info8/e9cc9cdbfac3431fafe96d6832f1185e.jpg)
- 上图中表4主要就是想说一下移动窗口以及相对位置编码到底对 Swin Transformer 有多有用
- 可以看到,如果光分类任务的话,其实不论是移动窗口,还是相对位置编码,它的提升相对于基线来说,也没有特别明显,当然在ImageNet的这个数据集上提升一个点也算是很显著了
- 但是他们更大的帮助,主要是出现在下游任务里,就是 COCO 和 ADE20K 这两个数据集上,也就是目标检测和语义分割这两个任务上
- 可以看到,用了移动窗口和相对位置编码以后,都会比之前大概高了3个点左右,提升是非常显著的,这也是合理的,因为如果现在去做这种密集型预测任务的话,就需要特征对位置信息更敏感,而且更需要周围的上下文关系,所以说通过移动窗口提供的窗口和窗口之间的互相通信,以及在每个 Transformer block都做更准确的相对位置编码,肯定是会对这类型的下游任务大有帮助的
点评
虽然前面已经说了很多 Swin Transformer 的影响力啊已经这么巨大了,但其实他的影响力远远不止于此,论文里这种对卷积神经网络,对 Transformer,还有对 MLP 这几种架构深入的理解和分析是可以给更多的研究者带来思考的,从而不仅可以在视觉领域里激发出更好的工作,而且在多模态领域里,相信它也能激发出更多更好的工作