【深度学习】论文阅读:(ICCV-2021))Swin Transformer
这里写目录标题
- 论文详情
- VIT缺点
- 改进点
- 概述
- 核心思想
- 整体结构
-
- 名称解释 Window、Patch、Token
- 与vit区别
- 结构过程
-
- Patch Embedding
- BasicLayer
-
- Patch Merging
- Swin Transform Block
-
- Window Attention
- Shifted Window Attention
- 总结
- SwinT模块
-
- 一、SwinT模块的使用演示,接口酷似Conv2D
- 二、使用SwinT替换Resnet50中Bottleneck中的Conv2D层,创建SwinResnet!
- 代码
-
- Patch Embedding
- Patch Merging
- Mask
论文详情
名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
地址:原论文
代码:代码地址
视频讲解:
1李沐
2胡瀚研究员:Swin Transformer和拥抱Transformer的五个理由
3霹雳吧啦Wz-Swin-Transformer网络结构详解
笔记参考:
1李沐b站视频讲解笔记
2笔记解释
3霹雳吧啦Wz
4胡瀚研究员:Swin Transformer和拥抱Transformer的五个理由
专访 Swin Transformer 作者胡瀚:面向计算机视觉中的「开放问题
6.2021-Swin Transformer Attention机制的详细推导
7.详解Swin Transformer核心实现,经典模型也能快速调优
8.很好:理论+代码【机器学习】详解 Swin Transformer (SwinT)
swin-T模块
1.SwinT-让Swin-Transformer的使用变得和CNN一样方便快捷
VIT缺点
应用:
ViT主要针对图像分类问题设计,不适合作为通用 模型的backbone,也不适合更细粒度的识别问题(如目标检测、分割等)
vit实现过程:
ViT通过将图像均分成不相交的patch,通过编码每个patch然后计算两两patch之间的self-attention,来实现聚合信息,即聚合全局信息。
简述:直接将图片切割成相同大小的块,做全局Transformer
缺点:应对更高清的图片时,划分的patch数会受计算资源掣肘。
你可以这么想,4x4=16个patch,两两计算自注意力,和100x100=10000个patch,两两计算自注意力,计算复杂度完全不一样(前者的计算16x16次,后者计算 10000x10000 次,即计算复杂度跟 (HxW)平方呈线性关系)
改进点
目前Transformer应用到图像领域主要有两大挑战:
1一个就是尺度上的问题。
图片的scale变化非常大,非标准固定的
因为比如说现在有一张街景的图片,里面有很多车和行人,里面的物体都大大小小,那这时候代表同样一个语义的词,比如说行人或者汽车就有非常不同的尺寸,这种现象在 NLP 中就没有
2.计算复杂度高:
图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
CV中使用Transformer的计算复杂度是图像尺度的平方(Self-Attention 需要对输入的所有N个 token 计算 [公式] 大小的相互关系矩阵,考虑到视觉信息本来就就是二维(图像)甚至三维(视频),分辨率稍微高一点这计算量就很难低得下来。),这会导致计算量过于庞大。
为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:
- 引入CNN中常用的层次化构建方式构建层次化Transformer
- 引入locality思想,对无重合的window区域内进行self-attention计算。
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。
移动窗口的优点:
不仅带来了更大的效率,因为跟之前的工作一样,现在自注意力是在窗口内算的,所以这个序列的长度大大的降低了;
同时通过 shifting 移动的这个操作,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有 cross-window connection,从而变相的达到了一种全局建模的能力
这种层级式的结构不仅非常灵活,可以提供各个尺度的特征信息,同时因为自注意力是在小窗口之内算的,所以说它的计算复杂度是随着图像大小而线性增长,而不是平方级增长,
将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
概述
1.SwinTransformer想设计一个可以作为密集预测任务的Transformer Backbone,其采用PatchMerging的策略,构建了层次化的特征,使得其可以作为密集预测任务的Backbone。
2.同时考虑到密集预测任务中,tokens数目太多导致计算量过大的问题,其采用一种在local window内部计算Self-Attention的机制去降低计算复杂度,使得整体计算复杂度由O(N^2)降低至O(N)水平。
3.为了弥补Local Self-Attention带来了远程依赖关系缺失的问题,其创新性地采用了Shift Window操作,引入了不同window之间的关系,并且在精度以及速度上都超越了简单的Sliding Window的方法。
是Transformer在Local Attention策略上的一次不错的尝试。
核心思想
Swin Transformer就是想让 Vision Transformer像卷积神经网络一样,也能够分成几个 block,也能做层级式的特征提取,从而导致提出来的特征有多尺度的概念
原生 Transformer 对 N 个 token 做 Self-Attention ,复杂度为 NxN,
Swin Transformer 将 N 个 token 拆为 N/n 组, 每组 n (n设为常数)个token 进行计算,复杂度降为 [N*nxn] ,考虑到 n 是常数,那么复杂度其实为N。
分组计算的方式虽然大大降低了 Self-Attention 的复杂度,但与此同时,有两个问题需要解决,
其一是分组后 Transformer 的视野局限于 n 个token,看不到全局信息,
其二是组与组之间的信息缺乏交互。
对于问题一,Swin Transformer 的解决方案即 Hierarchical,每个 stage 后对 2x2 组的特征向量进行融合和压缩(空间尺寸HxW变成0.5Hx0.5W,特征维度C->4C->2C ),这样视野就和 CNN-based 的结构一样,随着 stage 逐渐变大。
对于问题二,Swin Transformer 的解决方法是 Shifted Windows,
整个SwinTRM 其实最重要的就两个点:
一个点是相对位置信息,
一个是移动窗口注意力机制;把握住这两个点,对SwinTRM的理解就到位;
其中相对位置信息的核心点在于可以把每种相对位置信息和att对应的一行信息对应上;
移动窗口注意力机制核心点在于mask,mask矩阵的生成是通过窗口索引tensor相减得到的;
优点:
3. 相比于ViT,Swin Transfomer 计算复杂度大幅度降低,具有输入图像大小线性计算复杂度。
4. Swin Transformer随着深度加深,逐渐合并图像块来构建层次化Transformer,可以作为通用的视觉骨干网络,应用于图像分类、目标检测和语义分割等任务。
整体结构
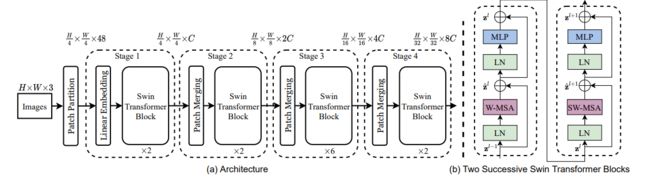
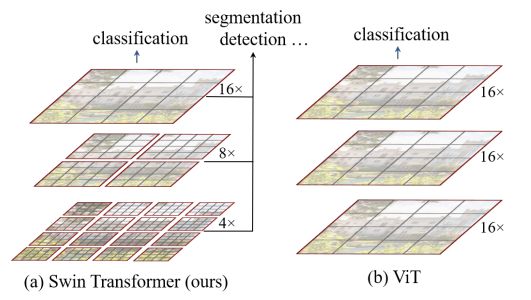
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
- 在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。
- 在每个Stage里,由Patch Merging和多个Block组成
- Patch Merging模块主要在每个Stage一开始降低图片分辨率
- Block具体结构如右图所示,主要是LayerNorm,MLP,Window Attention 和 Shifted Window Attention组成
名称解释 Window、Patch、Token
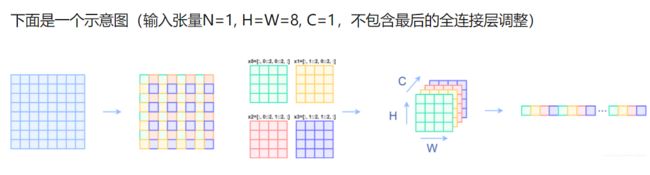
假设输入图片的尺寸为224X224,先划分成多个大小为4x4像素的小片,每个小片之间没有交集。
- 224/4=56,那么一共可以划分56x56个小片。每一个小片就叫一个patch,
- 每一个patch将会被对待成一个token。所以patch=token。
- 而一张图被划分为7x7个window,每个window之间也没有交集。那么每个window就会包含8x8个patch。
与vit区别
1 与ViT一样对于输入的图像信息先做一个PatchEmbed操作将图像进行切分后打成多个patches传入进行后续的处理,但与ViT不同的是初始的切分不再以16 * 16的大小,而是以4 * 4的大小,
2 且后续通过PatchMerging的操作不断增加尺寸,进而可以得到多尺度信息便于在目标检测和语义分割中的使用,
3 ViT在输入会给embedding进行位置编码。
Swin-T这里则是作为一个可选项(self.ape),Swin-T是在计算Attention的时候做了一个相对位置编码
4.ViT会单独加上一个可学习参数,作为分类的token。
Swin-T则是直接做平均,输出分类,有点类似CNN最后的全局平均池化层
结构过程
主要由以下模块组成:
PatchEmbed将图像换分为多个patches,
之后接入多个BasicLayer进行处理(默认是和上述结构图一致,4个虚线框中的结构),
再然后将结果做avgpool输出计算结果,
最后在进行分类操作(所以这里与ViT中不一样的是并没有采用一个cls token来进行分类而是对多个tokens取均值参与最终的分类运算)
Patch Embedding
不能直接将一整幅图片作为一个patch,所以需要对图像进行切分然后处理为一个patch,但与ViT不同的是,Swin-T不在以16*16作为一个切割大小,而是以4 * 4作为切分大小,并通过后续的Patch Merging操作不断增大每个Patch的大小,进而实现多尺度变化
BasicLayer
生成Patch之后就进入Swin- Transformer的核心模块部分了,每个basiclayer主要是由若干个Swin-Transformer Block和一个Patch Merging
Patch Merging
作用:是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 ,类似于CNN中Pooling层。进而形成层次化的设计,同时也能节省一定运算量。
启发:在做Window Attention这个操作时,数据的维度变换是和CNN是有些相似的地方的,当然SwinTransformer的初衷也是想让Transformer能像CNN一样能够分成多个Block,进而在不同层级的Block之间提取到分辨率不同的特征信息,
实现:SwinTransformer引入了Patch Merging操作来实现**,类似于CNN的池化的操作**
在CNN中,则是在每个Stage开始前用stride=2的卷积/池化层来降低分辨率。
每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。
然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍
Swin Transform Block
这部分是整个程序的核心,它由窗口多头自注意层(window multi-head self-attention, W-MSA)和移位窗口多头自注意层(shifted-window multi-head self-attention, SW-MSA)组成
包含了论文中的很多知识点,涉及到相对位置编码、mask、window self-attention、shifted window self-attention
整体流程如下:
输入到该stage的特征 z的l-1 先经过LN进行归一化,
再经过W-MSA进行特征的学习,
接着的是一个残差操作得到 z帽的l。
接着是一个LN,一个MLP以及一个残差,得到这一层的输出特征z的l。
SW-MSA层的结构和W-MSA层类似,不同的是计算特征部分分别使用了SW-MSA和W-MSA,
可以从上面的源码中看出它们除了shifted的这个bool值不同之外,其它的值是保持完全一致的。这一部分可以表示为式(2)
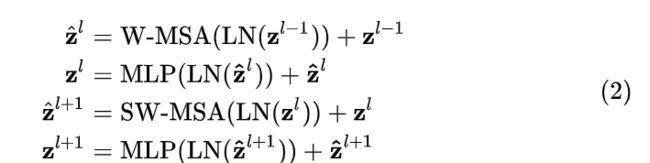
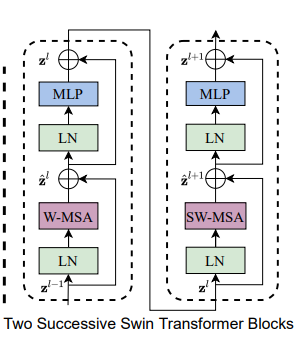
Swin Transformer使用window self-attention降低了计算复杂度,
为了保证不重叠窗口之间有联系,采用了shifted window self-attention的方式重新计算一遍窗口偏移之后的自注意力,所以Swin Transformer Block都是成对出现的 (W-MSA + SW-MSA为一对) ,不同大小的Swin Transformer的Block个数也都为偶数,Block的数量不可能为奇数。
Window Attention
传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。
而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。
WindowAttention与传统的Attention主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码
![]()
绝对位置编码是在进行self-attention计算之前为每一个token添加一个可学习的参数,
相对位置编码如上式所示,是在进行self-attention计算时,在计算过程中添加一个可学习的相对位置参数B。
实际上这里在参与Attention计算的B 是relative_position_bias_table这个可学习的参数,而relative_position_index则是作为一个index去取relative_position_bias_table中的值来参与运算
有了相对位置索引(relative_position_index)之后,后续将相对位置bias(relative_position_bias_table)加入q@k^T 中
这里比较难理解的就是relative_position_index的生成代码,如下图所示为整个relative_position_index的生成过程:
假设window_size = 2*2即每个窗口有4个token [M=2] ,如图1所示,在计算self-attention时,每个token都要与所有的token计算QK值,如图2所示,当位置1的token计算self-attention时,要计算位置1与位置(1,2,3,4)的QK值,即以位置1的token为中心点,中心点位置坐标(0,0),其他位置计算与当前位置坐标的偏移量。
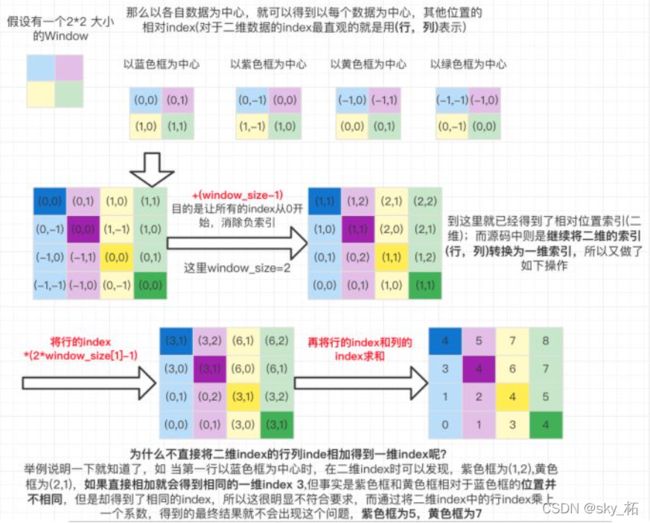
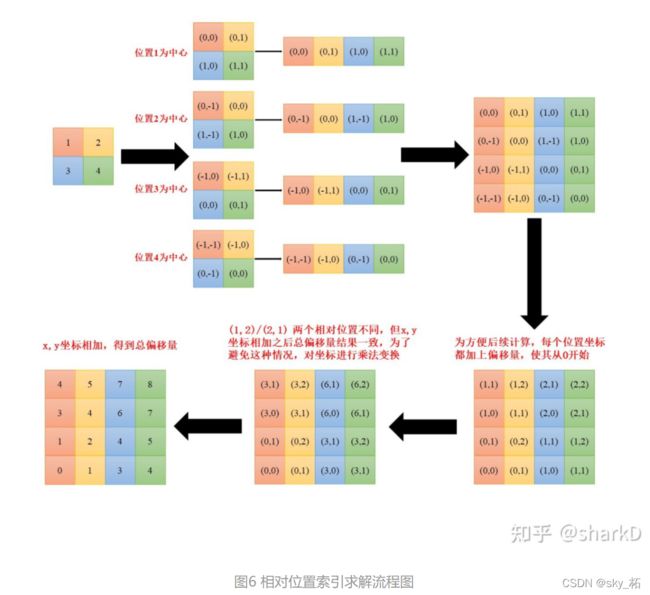
然后再最后一维上进行求和,展开成一个一维坐标,并注册为一个不参与网络学习的变量
Shifted Window Attention
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。
shifted window也就是把左侧的“规则”windows变为右侧“不规则”的windows,因为这样就能实现左侧“规则”windows之间的“信息交流”
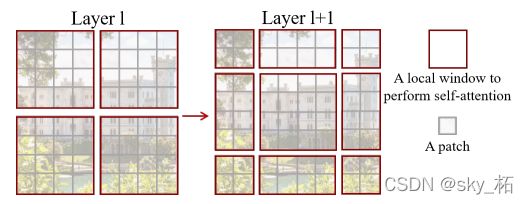
左边是没有重叠的Window Attention,而右边则是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。
为此论文提出了一种针对于shifted window Attention更加高效的计算方式,如下图所示,为论文提供的高效计算shifted window Attention的示意图
在实际代码里,我们是通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
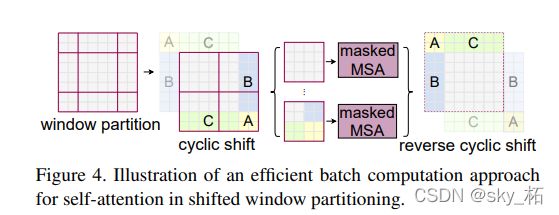
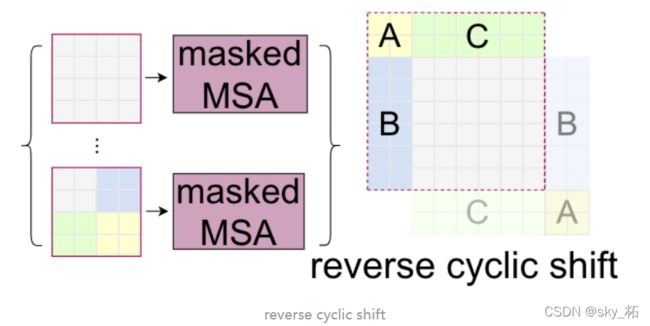
特征图移位操作
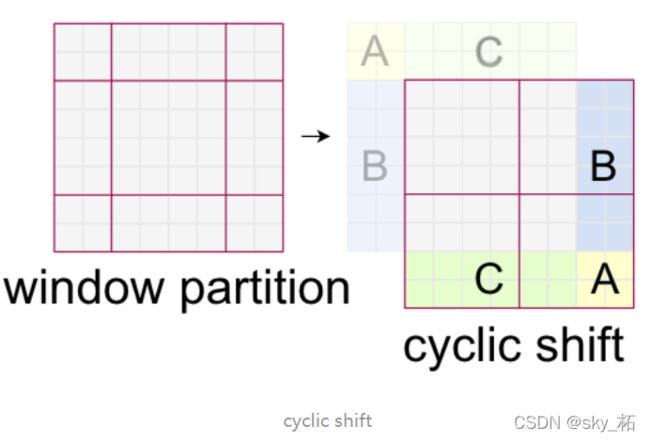
首先第一步就是将特征数据进行cyclic shift操作,这个操作具体的代码中是使用的torch.roll实现的,如下图,通过将A B C三个区域的数据移动到如图的位置,那么整个窗口的划分就变得大小一致了。

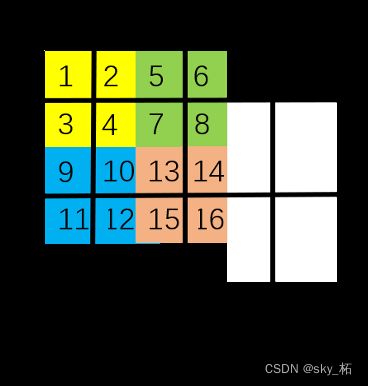
移动窗口为什么能有全局特征抽取的能力
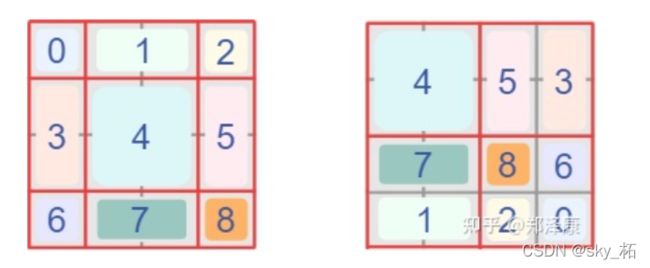
Swin Transformer中注意力机制是如何运行的,如下图。首先,我们对每个颜色内的窗口进行自注意力运算,如[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]每个列表内的元素做自注意力运算。

然后,滑动窗口,可以看作背景黑框在图像上滑动对图像进行的重新切分。
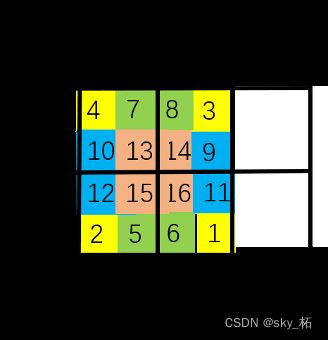
最后,将图像补回原来的大小,这一步是方便代码的编写,并且对窗口中原本不相邻的区域不做注意力运算。
注意,窗口是由黑框决定的。也就是说,由于原图像中[4,7,10,13]相邻,因此左上角[4,7,10,13]一起做注意力运算;而[16,11,6,1]原本不相邻,因此右下角[16],[11],[6],[1]单独做注意力运算,而[16],[11]之间不做注意力运算。左下角[12,15],[2,5]各自相邻,因此[12,15]做注意力运算,[2,5]做注意力运算[12,15]和[2,5]之间不做注意力运算。
通过这两步,美妙的事情发生了,
我们首先在第一步建立了[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]各自窗口之间的联系,
然后在第二步建立了[4,7,10,13]之间的联系。可以观察到,通过这二步,我们得以建立[1,2,3,4,5,6,7,8,9,10,11,12]之间的联系,
滑动窗口+原始窗口就如同一个高速通道在图像的左上角和右下角之间建立起了自注意力的联系,从而获得了全局感受野。
我们可以发现,**滑窗和不滑窗两步是缺一不可的。只有两者同时存在,我们才能够建立全局的注意力。**因此,W-MSA和SW-MSA必须作为一个整体一起使用。后续在我们的SwinT模块的源代码中,将使用W-MSA、SW-MSA和PatchMerging下采样,并将这三部分整合成一个模块。本文章的后续我们将演示这个接口如何使用,利用这个接口真实地搭建一个SwinResnet网络并对其进行性能测试!
Attention Mask
我认为这是Swin Transformer的精华,通过设置合理的mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。
得到大小一致的窗口之后,再进行带掩码的MSA操作,因为shift之后windows的大小都一致,所以在进行Attention计算时就比较好并行计算,同时通过掩码的作用,原本不属于同一个窗口的数据进行Attention之后也不会得到较高的注意力(比如蓝天和草原之间的Attention值就不会高)。
掩码操作:
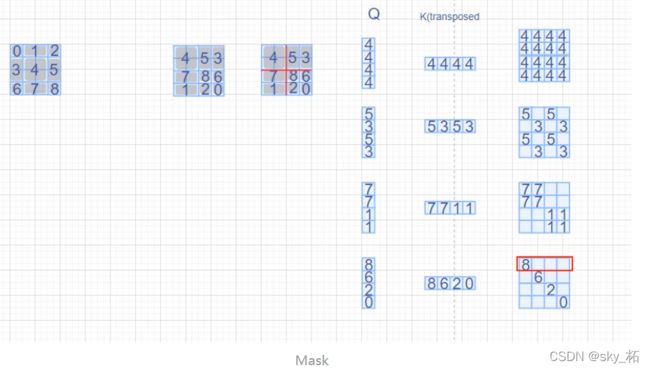
如下图,window_size=2,shift_size=-1,最左侧方块所示,我们分别对这9个方块编号为0~8,那么经过roll处理以后,每个区域的位置分布就如第二个方块所示;
再以window_size在每个window内做带掩码的MSA,具体而言就是相同编号的区域做MSA时就没有mask,不同区域之间做MSA就需要有掩码,例如
右下侧的那个window内一共有4个区域的数据(8,6,2,0),那么区域8的Q只和区域8的K^ T相乘时才不带掩码,与其他区域的K^T相乘都需要带掩码,计算结果就如右下侧的红色框中所示:
当然,做完这些之后还需要再将数据给shift回来,方便之后其他层的运算。
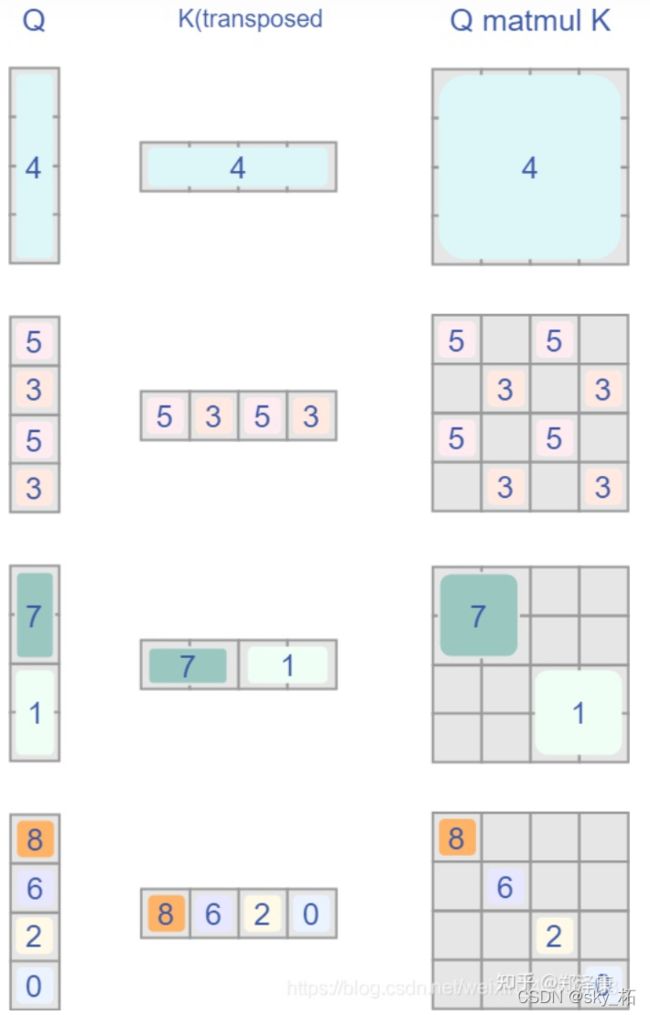
首先我们对Shift Window后的每个窗口都给上index,并且做一个roll操作(window_size=2, shift_size=-1)
希望在计算Attention的时候,让具有相同index QK进行计算,而忽略不同index QK计算结果。
而要想在原始四个窗口下得到正确的结果,我们就必须给Attention的结果加入一个mask(如下图最右边所示)
最后正确的结果如下图所示
总结
引入window这一个概念,将CNN的局部性引入,还能控制模型整体计算量。
在Shift Window Attention部分,用一个mask和移位操作,很巧妙的实现计算等价。
SwinT模块
SwinT-让Swin-Transformer的使用变得和CNN一样方便快捷
一、SwinT模块的使用演示,接口酷似Conv2D
由于以下两点原因,我们将Swin-Transformer最核心的部分制成了一个类似于nn.Conv2D的接口并命名为SwinT。其输入、输出数据形状完全和Conv2D(CNN)一样,这极大的方便了使用Transformer来编写模型代码。
1、一方面,虽然随着2020年Vit出圈以后,Transformer开始在CV领域得到快速发展;但是对于很多开发者而言,最熟悉的模块依然是CNN,由于Vit内部代码复杂,使得在不同场景下对源代码进行修改以适配实际场景也是一个费时费力的过程。
2、另一方面,使用Transformer的模型通常计算量都巨大,而又因为没有卷积核的先验偏置,通常要使用海量的数据进行预训练(自监督或有监督),使得模型调试成本大;2021年横空出世的Swin-Transformer将注意力运算量从图像尺寸的平方O(n2)降到了线性O(n1),又通过窗口自注意力+滑窗自注意力实现了近似的全局注意力(全局特征提取)。
二、使用SwinT替换Resnet50中Bottleneck中的Conv2D层,创建SwinResnet!
这部分,我们实际展示了如何使用SwinT来替换掉现有模型中相应的Conv2D模块,整个过程对源码改动小;为了展示实际的效果,我们使用Cifar10数据集对模型精度,速度两方面给出了结果,证明了SwinT模块在效果上至少是不差于Conv2D的(这是一个较简单且数据较少的数据集),由于运行整个流程需要6个小时,因此没有过多调节超参数防止过拟合。虽然普通的resnet50可以调高batch来提高速度,但是bacth大小是与模型正则化有关的一个参数,因此将batch都控制在了一个大小进行对比测试。
这里我们给出原Resnet50和具体对其修改的内容,对需要修改的地方进行了标注(修改部分使用了字符串进行注释),为了增加项目的可读性,修改后的SwinResnet放在model.py里。
下图从左到右依次为Resnet, Botnet, SwinResnet中Bottleneck部分

代码
参考笔记:swin使用安装+代码讲解很详细
代码讲解很好
很好,代码+原理【机器学习】详解 Swin Transformer (SwinT)
视频:Win10配置Swin-Transformer-Semantic-Segmentation并训练自己数据集
Patch Embedding
-
Patch Partition
作用:将RGB图转为非重叠的patch块。这里的patch尺寸为 4x4,乘上对应的RGB通道可得大小为4 x 4 x3=48。 -
Linear Embedding
作用:将处理好的patch投影到指定的维度,这里embed_dim=96。 -
核心代码实现
通过设定固定大小(4*4)的patch进行卷积,实现Patch Partition,再设定输出通道实现 Linear Embedding
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size,stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
Patch Merging
作用:将传入矩阵划分为2 x 2 大小的窗口,每个窗口的对应位置(例如下图中的同色块[^3])相merge,再对merge后的四个特征矩阵相concatenate。最后经过layer normalization和linear layer降维。
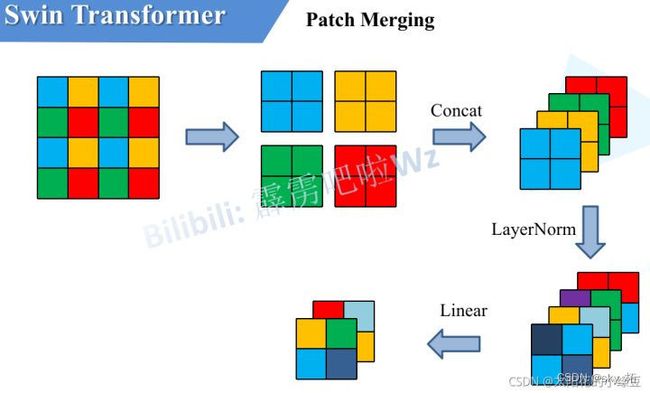
- Layer normalization和Linear layer的初始化
self.norm = norm_layer(4 * dim)
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
其中由图可知,每一层通道在传递给LayerNorm时都是原通道的4倍。传递给Linear时同理,Linear的输入为原通道的4倍,输出为原通道的2倍。
- Merging的实现
def forward(self, x, H, W):
"""
x: B, H*W, C
"""
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# padding
# 如果输入feature map的H,W不是2的整数倍,需要进行padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
# to pad the last 3 dimensions, starting from the last dimension and moving forward.
# (C_front, C_back, W_left, W_right, H_top, H_bottom)
# 注意这里的Tensor通道是[B, H, W, C],所以会和官方文档有些不同
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # [B, H/2, W/2, C]
x1 = x[:, 1::2, 0::2, :] # [B, H/2, W/2, C]
x2 = x[:, 0::2, 1::2, :] # [B, H/2, W/2, C]
x3 = x[:, 1::2, 1::2, :] # [B, H/2, W/2, C]
x = torch.cat([x0, x1, x2, x3], -1) # [B, H/2, W/2, 4*C]
x = x.view(B, -1, 4 * C) # [B, H/2*W/2, 4*C]
x = self.norm(x)
x = self.reduction(x) # [B, H/2*W/2, 2*C]
return x
其中12-17行的作用是对行数或者列数是奇数的层进行扩充;
19-24完成的是Merging操作,即每隔2行2列取一次元素并将这些元素沿最后一个维度(通道维度)concat
Mask
构建Mask是为了以后SW-MSA移动后窗口只对连续部分做self-attention,整个构建过程分为两步。
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍,起到了padding的作用
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1