《Deep Learning for Computer Vision withPython》阅读笔记-StarterBundle(第4 - 5章)
4.图像分类基础
这句格言在我们的生活中已经听过无数次了。它只是意味着一个复杂的想法可以在一个单一的图像中传达。无论是查看我们股票投资组合的折线图,查看即将到来的足球比赛的传播,还是简单地学习绘画大师的艺术和笔触,我们都在不断地吸收视觉内容,解释其含义,并存储知识以备日后使用。
然而,对于计算机来说,解释图像的内容并不是那么简单——我们的计算机看到的只是一个巨大的数字矩阵。它不知道图像试图传达的思想、知识或意义。
为了理解图像的内容,我们必须应用图像分类,这是使用计算机视觉和机器学习算法从图像中提取意义的任务。此操作可以简单到为图像包含的内容指定标签,也可以高级到解释图像内容并返回人类可读的句子。
图像分类是一个非常大的研究领域,涵盖了各种各样的技术——随着深度学习的普及,它正在继续发展。
现在是驾驭深度学习和图像分类浪潮的时候了——成功做到这一点的人将获得丰厚的回报。
图像分类和图像理解目前(并将继续)是未来十年计算机视觉最流行的子领域。在未来,我们将看到谷歌、微软、百度等公司迅速收购成功的形象理解初创公司。我们将在智能手机上看到越来越多能够理解和解释图像内容的消费者应用程序。甚至战争也可能使用无人驾驶飞机进行,无人驾驶飞机使用计算机视觉算法自动引导。
在本章中,我将从较高的层次概述什么是图像分类,以及图像分类算法必须克服的许多挑战。我们还将回顾与图像分类和机器学习相关的三种不同类型的学习。
最后,我们将通过讨论培训图像分类深度学习网络的四个步骤以及这四个步骤与传统的,手工设计的特征提取管道。
4.1什么是图像分类?
图像分类的核心是从一组预定义的类别中为图像指定标签。
实际上,这意味着我们的任务是分析输入图像并返回对图像进行分类的标签。标签始终来自一组预定义的可能类别。
例如,假设我们的一组可能类别包括:
categories = {cat, dog, panda}
然后,我们向我们的分类系统展示以下图像(图4.1):

我们的目标是获取这个输入图像,并从我们的类别集中为其指定一个标签——在本例中为dog。
我们的分类系统还可以通过概率为图像分配多个标签,例如dog:95%;cat:4%;熊猫:1%。
更正式地说,假设我们的输入图像是W×H像素,分别有三个通道,即红色、绿色和蓝色,我们的目标是获取W×H×3=N像素的图像,并找出如何正确分类图像的内容。
4.1.1关于术语的说明
在执行机器学习和深度学习时,我们有一个试图从中提取知识的数据集。数据集中的每个示例/项(无论是图像数据、文本数据、音频数据等)都是一个数据点。因此,数据集是数据点的集合(图4.2)。
我们的目标是应用机器学习和深度学习算法来发现数据集中的潜在模式,使我们能够正确地对算法尚未遇到的数据点进行分类。现在花点时间熟悉以下术语:
- 在图像分类的上下文中,我们的数据集是图像的集合。
- 因此,每个图像都是一个数据点。
在本书的其余部分中,我将交替使用术语“图像”和“数据点”,所以现在请记住这一点。

4.1.2语义鸿沟
查看图4.3中的两张照片(上图)。对我们来说,分辨这两张照片之间的区别应该是相当简单的——很明显,左边是一只猫,右边是一只狗。但计算机看到的只是两个大的像素矩阵(下图)。
考虑到计算机看到的只是一个巨大的像素矩阵,我们得出了语义鸿沟的问题。语义鸿沟是人类对图像内容的感知方式与计算机对图像表示方式之间的差异。
同样,快速目视检查上述两张照片可以揭示这两种动物之间的差异。但实际上,计算机一开始并不知道图像中有动物。为了明确这一点,请参见图4.4,其中包含一张宁静海滩的照片。
我们可以这样描述图像:•空间:天空在图像顶部,沙子/海洋在底部颜色:天空是深蓝色的,海水是比天空浅蓝色的,而沙子是棕色的纹理:天空有一个相对均匀的图案,而沙子非常粗糙。
我们如何以计算机能够理解的方式对所有这些信息进行编码?答案是应用特征提取来量化图像的内容。特征提取是获取输入图像、应用算法并获得量化图像的特征向量(即数字列表)的过程。
为了实现这一过程,我们可以考虑应用手工工程特征,如HOG,LBPS,或其他“传统”的方法来量化图像。另一种方法,也是本书采用的方法,是应用深度学习来自动学习一组特征,这些特征可用于量化并最终标记图像本身的内容。
然而,这并不是那么简单。因为一旦我们开始在现实世界中检查图像,我们就会面临很多很多挑战。

4.1.3挑战
如果语义差异还不足以构成问题,我们还必须处理图像或对象外观的变化因素[10]。图4.5显示了这些变化因素的可视化。
首先,我们有视点变化,在视点变化中,可以根据拍摄和捕捉对象的方式在多个维度上定向/旋转对象。不管我们从哪个角度捕捉这个树莓圆周率,它仍然是一个树莓圆周率。
我们还必须考虑尺度变化。你有没有从星巴克点过一杯高杯、大杯或通风杯的咖啡?从技术上讲,它们都是一样的东西——一杯咖啡。但它们都是不同大小的咖啡。此外,同样的venti咖啡在近距离拍摄时与在远处拍摄时看起来会有很大的不同。我们的图像分类方法必须能够容忍这些类型的尺度变化。
最难解释的变化之一是变形。对于那些熟悉电视连续剧《甘比》的人,我们可以看到上图中的主角。正如这部电视剧的名字所暗示的那样,这个角色有弹性、可伸展,并且能够以多种不同的姿势扭曲身体。我们可以将这些Gumby图像视为一种对象变形——所有图像都包含Gumby字符;然而,它们彼此都有着显著的不同
我们的图像分类也应该能够处理遮挡,其中大部分我们想要分类的对象在图像中是隐藏的(图4.5)。在左边我们必须有一张狗的照片。在右边我们有一张同一只狗的照片,但请注意狗是如何在被子下面休息的,挡住了我们的视线。狗仍然清晰地出现在两张图片中——她只是在一张图片中比在另一张图片中更显眼。图像分类算法应该仍然能够检测和标记两幅图像中是否有狗。

正如上面提到的变形和遮挡一样具有挑战性,我们还需要处理照明的变化。看看在标准和低照度下拍摄的咖啡杯(图4.5)。左边的图像是用标准顶灯拍摄的,而右边的图像是用很少的灯光拍摄的。我们仍在检查同一个杯子——但根据照明条件,杯子看起来有很大的不同(很好,杯子的垂直纸板接缝在低照明条件下清晰可见,但在标准照明条件下却看不到)。
继续讲下去,我们还必须考虑到背景的混乱。玩过沃尔多在哪里的游戏吗?(沃利在哪里?面向我们的国际读者。)如果是这样,那么你知道游戏的目标是找到我们最喜欢的红白条纹衬衫朋友。然而,这些谜题不仅仅是一个有趣的儿童游戏——它们也是背景混乱的完美表现。这些图像令人难以置信地“嘈杂”,而且里面有很多东西。我们只对图像中的一个特定对象感兴趣;然而,由于所有的“噪音”,很难分辨出沃尔多/沃利。如果这对我们来说不容易,想象一下,对于一台对图像没有语义理解的计算机来说是多么困难!
最后,我们有类内变异。计算机视觉中类内变化的典型例子是展示椅子的多样化。从我们用来蜷缩着看书的舒适椅子,到家庭聚会时摆在厨房桌子上的椅子,再到著名家庭中的超现代艺术装饰椅子,椅子仍然是椅子——我们的图像分类算法必须能够正确地对所有这些变化进行分类。
您是否开始对构建图像分类器的复杂性感到有些不知所措?不幸的是,情况只会变得更糟——我们的图像分类系统单独对这些变化具有鲁棒性是不够的,但我们的系统还必须同时处理多个变化!
那么,我们如何解释物体/图像中如此多的变化呢?总的来说,我们尽可能地把问题框起来。我们对图像的内容以及我们希望容忍的变化做出假设。我们也考虑我们的项目的范围-最终目标是什么?我们想建立什么?

成功的计算机视觉、图像分类和深入学习系统部署到现实世界中,在编写一行代码之前都会进行仔细的假设和考虑。
如果你的方法过于宽泛,比如“我想对厨房里的每一个物体进行分类和检测”(那里可能有数百个可能的物体),那么你的分类系统就不可能表现良好,除非你有多年的图像分类器构建经验——即使如此,这项工程的成功没有保证。
但是,如果你把问题框起来,缩小范围,比如“我只想识别炉灶和冰箱”,那么你的系统就更有可能准确、有效,特别是如果这是你第一次使用图像分类和深度学习的话。
这里的关键是要始终考虑图像分类器的范围。虽然深度学习和卷积神经网络在各种挑战下表现出了显著的鲁棒性和分类能力,但您仍然应该保持项目的范围尽可能紧密和明确。
请记住,事实上,图像分类算法的标准基准数据集ImageNet[42]由我们日常生活中遇到的1000个对象组成——研究人员仍在积极使用该数据集,试图推动深度学习的最新进展。
深入学习不是魔法。相反,深度学习就像车库里的卷轴锯——正确使用时强大而有用,但如果使用不当则危险。在本书的其余部分中,我将指导您深入学习,并帮助您指出何时应该使用这些电动工具,何时应该使用更简单的方法(或者在图像分类无法解决问题时提及)。
4.2学习类型
在机器学习和深度学习职业生涯中,您可能会遇到三种类型的学习:监督学习、非监督学习和半监督学习。本书主要关注深度学习背景下的监督学习。尽管如此,以下介绍了所有三种类型的学习。
4.2.1监督学习
想象一下:你刚从大学毕业,拥有计算机科学学士学位。你还年轻。打破了在这个领域寻找工作——也许你甚至会在找工作时感到迷失。
邮件分类问题:
相反,你真正需要的是机器学习。你们需要一个训练集,包括电子邮件本身以及它们的标签,在这种情况下是垃圾邮件还是非垃圾邮件。根据这些数据,您可以分析电子邮件中的文本(即单词的分布),并利用垃圾邮件/非垃圾邮件标签向机器学习分类器传授垃圾邮件中出现了哪些单词,哪些没有——所有这些都无需手动创建一系列冗长复杂的if/else语句。
这个创建垃圾邮件过滤系统的例子就是一个监督学习的例子。监督学习可以说是机器学习中最广为人知和最受研究的类型。给定我们的训练数据,通过训练过程创建模型(或“classier”),其中对输入数据进行预测,然后在预测错误时进行纠正。该训练过程持续进行,直到模型达到某些期望的停止标准,例如低错误率或最大训练迭代次数
常见的监督学习算法包括逻辑回归、支持向量机(SVM)[43,44]、随机森林[45]和人工神经网络。

在图像分类的上下文中,我们假设我们的图像数据集由图像本身及其相应的类标签组成,我们可以使用它们来教授机器学习分类每个类别的“外观”。如果我们的分类器做出了错误的预测,那么我们可以应用方法来纠正错误。
通过查看表4.1中的示例,可以最好地理解有监督、无监督和半监督学习之间的差异。表的第一列是与特定图像关联的标签。剩下的六列对应于每个数据点的特征向量——在这里,我们选择通过分别计算每个RGB颜色通道的平均值和标准偏差来量化图像内容。
我们的监督学习算法将对每个特征向量进行预测,如果预测不正确,我们将尝试通过告诉它正确的标签实际是什么来纠正它。然后,该过程将继续,直到达到所需的停止标准,例如精度、学习过程的迭代次数,或者仅仅是任意数量的墙时间。
为了解释有监督、无监督和半监督学习之间的差异,我选择使用基于特征的方法(即RGB颜色通道的平均值和标准偏差)来量化图像的内容。当我们开始使用卷积神经网络时,我们实际上会跳过特征提取步骤,使用原始像素强度本身。由于图像可能是大的M×N矩阵(因此无法很好地适合此电子表格/表格示例),因此我使用了特征提取过程来帮助可视化学习类型之间的差异。
4.2.2无监督学习
与监督学习相比,无监督学习(有时称为自学学习)没有与输入数据相关的标签,因此,如果模型做出错误的预测,我们就无法纠正模型。
回到电子表格示例,将监督学习问题转换为非监督学习问题非常简单,只需删除“标签”列(表4.2)。
无监督学习有时被认为是机器学习和图像分类的“圣杯”。当我们考虑Flickr上的图像数量或YouTube上的视频数量时,我们很快意识到互联网上有大量未标记的数据可用。如果我们能够让我们的算法从未标记的数据中学习模式,那么我们就不必花费大量时间(和金钱)费力地为监督任务标记图像。
当我们能够学习数据集的底层结构,然后反过来将我们学习到的特征应用于标记数据太少而无法使用的有监督学习问题时,大多数无监督学习算法最为成功。
用于无监督学习的经典机器学习算法包括主成分分析(PCA)和k-均值聚类。具体到神经网络,我们看到的是自动编码器SOMs,自适应共振理论应用于无监督学习。无监督学习是一个非常活跃的研究领域,也是一个有待解决的问题。在本书中,我们不关注无监督学习。

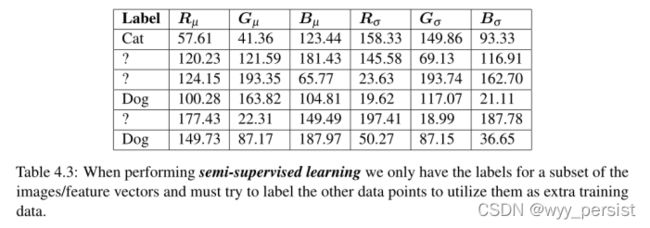
4.2.3半监督学习
那么,如果我们只有一些与数据相关联的标签,而没有其他标签,会发生什么呢?有没有一种方法可以应用监督和非监督学习的混合,并且仍然能够对每个数据点进行分类?事实证明答案是肯定的——我们只需要应用半监督学习。
回到我们的电子表格示例,假设我们只有一小部分输入数据的标签(表4.3)。我们的半监督学习算法将获取已知的数据片段,对其进行分析,并尝试标记每个未标记的数据点,以用作额外的训练数据。当半监督算法学习数据的“结构”以做出更准确的预测并生成更可靠的训练数据时,此过程可以重复多次迭代。
半监督学习在计算机视觉中尤其有用,因为在计算机视觉中,标记训练集中的每一幅图像往往耗时、繁琐且昂贵(至少在工时方面)。如果我们根本没有时间或资源来标记每个单独的图像,我们只能标记一小部分数据,并利用半监督学习来标记和分类其余的图像。
半监督学习算法通常以较小的标记输入数据集换取分类精度的一定程度的降低。通常情况下,有监督学习算法的训练越准确,其预测就越准确(对于深度学习算法尤其如此)。
随着训练数据量的减少,准确性不可避免地受到影响。半监督学习将准确度和数据量之间的这种关系考虑在内,并试图将分类准确度保持在可容忍的范围内,同时大幅减少构建模型所需的训练数据量–最终结果是一个准确的分类器(但通常不如有监督的分类器准确),所需的工作量和时间更少培训数据。半监督学习的流行选择包括标签传播[46]、标签传播[47]、阶梯网络[48]和共同学习/共同培训[49]。
同样,我们将在本书中主要关注监督学习,因为在计算机视觉深度学习的背景下,无监督和半监督学习仍然是非常活跃的研究课题,没有明确的方法使用指南。
4.3深度学习分类管道
基于我们前面两节关于图像分类和学习算法类型的内容,您可能会开始感到有点被新的术语、考虑事项和构建图像分类器时看起来无法克服的变化所困扰,但事实是构建图像分类器相当简单,一旦你了解了这个过程。
在本节中,我们将回顾在使用机器学习时,您需要进行的重要思维转变。在此,我将回顾构建基于深度学习的图像分类器的四个步骤,并比较和对比传统的基于特征的机器学习与端到端深度学习。
4.3.1心态的转变
在我们讨论任何复杂的事情之前,让我们先从我们都(很可能)熟悉的事情开始:斐波那契序列。
正如您所看到的,斐波那契序列非常简单,是一个函数族的示例:
- 接受输入,返回输出。
- 流程定义明确。
- 输出的正确性易于验证。
- 适用于代码覆盖率和测试套件。
与编写算法来计算斐波那契序列或对数字列表进行排序不同,如何创建算法来区分猫和狗的图片并不直观或明显。因此,我们不必试图构建一个基于规则的系统来描述每个类别的“外观”,而是可以采用数据驱动的方法,提供每个类别外观的示例,然后使用这些示例教我们的算法识别类别之间的差异。
我们将这些示例称为标记图像的训练数据集,其中训练数据集中的每个数据点包括:
- 一张图像;
- 图像的标签/类别(即狗、猫、熊猫等)
同样重要的是,这些图像中的每一个都有与之相关联的标签,因为我们的监督学习算法需要看到这些标签来“自学”如何识别每一个类别。记住这一点,让我们继续并完成构建深度学习模型的四个步骤。
4.3.2第1步:收集数据集
构建深度学习网络的第一个组成部分是收集初始数据集。我们需要图像本身以及与每个图像相关联的标签。这些标签应该来自一组有限的类别,例如:类别=狗、猫、熊猫
此外,每个类别的图像数量应大致相同(即,每个类别的示例数量相同)。如果我们的猫图像的数量是狗图像的两倍,熊猫图像的数量是猫图像的五倍,那么我们的分类器自然会倾向于过度拟合这些具有高度代表性的类别。
类不平衡是机器学习中的一个常见问题,有很多方法可以克服它。我们将在本书后面讨论其中的一些方法,但请记住,避免由于类不平衡而出现学习问题的最佳方法是完全避免类不平衡
4.3.3第2步:分割数据集
现在我们有了初始数据集,我们需要将其分为两部分:1.训练集2.测试集;
我们的分类器使用一个训练集,通过对输入数据进行预测来“学习”每个类别的外观,然后在预测错误时进行自我纠正。训练分类器后,我们可以在测试集上评估分类器的性能。
训练集和测试集相互独立且不重叠,这一点非常重要!如果您使用测试集作为训练数据的一部分,那么您的分类器具有不公平的优势,因为它之前已经看到了测试示例并从中“学习”。相反,您必须将此测试集与培训过程完全分开,并仅用于评估您的网络。
训练集和测试集的常见分割大小分别为66.6%、33.3%、75%/25%和90%/10%。(图4.7):

这些数据分割是有意义的,但是如果您有参数要调整呢?神经网络有许多需要调整的旋钮和杠杆(例如,学习率、衰减、正则化等)并拨号以获得最佳性能。我们将这些类型的参数称为超参数,正确设置它们是至关重要的。
在实践中,我们需要测试一组超参数,并确定最有效的参数集。您可能会试图使用您的测试数据来调整这些值,但同样,这是一个主要的禁忌!测试集仅用于评估网络的性能。
相反,您应该创建第三个数据拆分,称为验证集。这组数据(通常)来自于训练数据,并用作“假测试数据”,所以我们可以调整超参数。只有在我们使用验证集确定超参数值之后,我们才能继续收集测试数据中的最终精度结果。
我们通常分配大约10-20%的培训数据进行验证。如果将数据分割成块听起来很复杂,那么实际上并不复杂。正如我们将在下一章中看到的,由于scikit学习库,它非常简单,只需一行代码即可完成。
4.3.4第3步:训练你的网络
根据我们的培训图像集,我们现在可以培训我们的网络。这里的目标是让我们的网络学习如何识别标记数据中的每个类别。当模型出错时,它会从错误中吸取教训并自我改进。
那么,实际的“学习”是如何工作的呢?一般来说,我们采用梯度下降的形式,如第9章所述。这本书的其余部分致力于演示如何从头开始训练神经网络,因此我们将推迟到那时再详细讨论训练过程。
4.3.5第4步:评估
最后,我们需要评估我们经过培训的网络。对于测试集中的每个图像,我们将它们呈现给网络,并要求网络预测它认为图像的标签是什么。然后,我们将模型对测试集中图像的预测制成表格。
最后,将这些模型预测与我们测试集的地面真值标签进行比较。地面真实值标签表示图像类别的实际内容。从那里,我们可以计算我们的分类器得到正确预测的数量,并计算聚合报告,如精度、召回率和f-measure,这些报告用于量化整个网络的性能。
4.3.6基于特征的学习与图像分类的深度学习
在传统的基于特征的图像分类方法中,实际上在步骤2和步骤3之间插入了一个步骤——这一步骤是特征提取。在这一阶段,我们应用手工程算法,如HOG[32]、LBPs[21]等,根据我们要编码的图像的特定成分(即形状、颜色、纹理)量化图像内容。鉴于这些特征,我们接着训练分类器并对其进行评估。
在构建卷积神经网络时,我们实际上可以跳过特征提取步骤。这是因为CNN是端到端模型。我们将原始输入数据(像素)呈现给网络。然后,网络在其隐藏层中学习过滤器,这些过滤器可用于区分对象类。然后,网络的输出是类标签上的概率分布。
使用CNN的一个令人兴奋的方面是,我们不再需要对手工设计的功能大惊小怪——我们可以让我们的网络学习这些功能。然而,这种权衡是有代价的。培训CNN可能是一个不平凡的过程,因此要准备花大量时间熟悉经验,并进行许多实验,以确定哪些是有效的,哪些是无效的。
4.3.7当我的预测不正确时会发生什么?
不可避免地,您将在您的培训集上培训一个深度学习网络,在您的测试集上评估它(发现它具有很高的准确性),然后将其应用于培训集和测试集之外的图像,结果发现该网络表现不佳。
这个问题称为泛化,即网络泛化并正确预测图像的类别标签的能力,该图像不存在于其训练或测试数据中。
网络的泛化能力实际上是深度学习研究中最重要的一个方面——如果我们能够在不进行再培训或微调的情况下培训能够泛化到外部数据集的网络,我们将在机器学习方面取得巨大进步,使网络能够在各种领域中重复使用。本书将多次讨论网络的泛化能力,但我现在想提出这个主题,因为你将不可避免地遇到泛化问题,特别是当你学习深度学习的诀窍时。
不要对你的模型感到沮丧,而不能正确地对图像进行分类,考虑上面提到的一组变化因素。您的培训数据集是否准确反映了这些变化因素的示例?如果没有,您将需要收集更多的培训数据(并阅读本书的其余部分以学习其他技术来对抗泛化)。
4.4摘要
在这一章中,我们了解了什么是图像分类,以及为什么要让计算机很好地执行它是一项具有挑战性的任务(尽管人类似乎不费吹灰之力就能凭直觉完成)。然后,我们讨论了机器学习的三种主要类型:监督学习、无监督学习、半监督学习——本书主要关注监督学习,其中我们有训练示例和与之相关的类标签。半监督学习和无监督学习都是深度学习(以及一般的机器学习)的开放研究领域。
最后,我们回顾了深度学习分类管道中的四个步骤。这些步骤包括收集数据集、将数据拆分为培训、测试和验证步骤、培训网络以及最终评估模型。
与传统的基于特征的方法不同,传统方法要求我们利用手工算法从图像中提取特征,图像分类模型(如卷积神经网络)是端到端分类器,其内部学习可用于区分图像类别的特征。
5.用于图像分类的数据集
现在,我们已经习惯了图像分类管道的基本原理——但在我们深入研究如何获取数据集和构建图像分类器的任何代码之前,让我们首先回顾一下您将在Python计算机视觉深度学习中看到的数据集。
其中一些数据集基本上是“已解决”的,使我们能够轻松获得极高精度的分类器(>95%精度)。其他数据集代表了计算机视觉和深度学习的范畴,这些问题今天仍然是开放的研究课题,远未解决。最后,一些数据集是图像分类竞赛和挑战的一部分(e.x.,Kaggle Dogs vs.Cats和cs231n Tiny ImageNet 200)。
现在回顾这些数据集是很重要的,这样我们就可以在后面的章节中更高层次地了解我们在处理这些数据集时可能遇到的挑战。
5.1 MNIST

MNIST(“NIST”代表国家标准与技术研究所,而“M”代表“修改”,因为数据已经过预处理,以减少计算机视觉处理的负担,并仅专注于数字识别任务)数据集是计算机视觉和机器视觉领域研究最充分的数据集之一学习文学。
此数据集的目标是正确分类手写数字0− 9.在许多情况下,该数据集是一个基准,是机器学习算法排名的标准。事实上,MNIST的研究非常深入,杰弗里·辛顿(Geoffrey Hinton)将该数据集描述为“机器学习的果蝇”[10](果蝇是果蝇的一个属),比较了萌芽生物学研究人员如何使用这些果蝇,因为它们易于集体培养,世代时间短,突变容易获得。
同样,MNIST数据集对于早期深度学习实践者来说是一个简单的数据集,他们可以不费吹灰之力就“第一次体验”训练神经网络(很容易获得>97%的分类准确率)——在MNIST上训练神经网络模型在很大程度上等同于机器学习中的“你好,世界”。
MNIST本身由60000个训练图像和10000个测试图像组成。每个特征向量为784 dim,对应于图像的28×28灰度像素强度。这些灰度像素强度是无符号整数,属于[0255]范围。所有数字均置于黑色背景上,前景为白色,阴影为灰色。给定这些原始像素强度,我们的目标是训练一个神经网络来正确分类数字。
在入门包的早期章节中,我们将主要使用这个数据集来帮助我们“弄湿脚”,学习神经网络的诀窍。
5.2动物:狗、猫和熊猫

此数据集的目的是将图像正确分类为包含狗、猫或熊猫。“动物”数据集仅包含3000幅图像,是另一个“入门”数据集,我们可以在CPU或GPU上快速训练深度学习模型,并获得合理的准确性。
在第10章中,我们将使用该数据集演示如何使用图像像素作为特征向量,除非我们使用卷积神经网络(CNN),否则不会转化为高质量的机器学习模型。
该数据集的图像是通过对Kaggle Dogs vs.Cats图像以及熊猫示例的ImageNet数据集进行采样而收集的。动物数据集主要仅用于初学者包。
5.3 CIFAR-10

与MNIST一样,CIFAR-10被认为是计算机视觉和机器学习文献中用于图像分类的另一个标准基准数据集。CIFAR-10由60000个32×32×3(RGB)图像组成,其特征向量维数为3072。
顾名思义,CIFAR-10由10类组成,包括:飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车。
虽然在MNIST上训练一个分类准确率>97%的模型非常容易,但要为CIFAR-10(以及它的大哥CIFAR-100)获得这样一个模型却非常困难[50]。
挑战来自于物体如何出现的巨大差异。例如,我们不能再假设在给定(x,y)-坐标处包含绿色像素的图像是青蛙。该像素可能是包含鹿的森林背景的一部分。或者,像素可能只是绿色卡车的颜色。
这些假设与MNIST数据集形成鲜明对比,在MNIST数据集中,网络可以学习关于像素强度空间分布的假设。例如,数字1的前景像素的空间分布实质上不同于0或5。
虽然CIFAR-10是一个小数据集,但它仍然经常用于测试新的CNN体系结构。我们将在初学者包和实践者包中使用CIFAR-10。
5.4微笑
顾名思义,微笑数据集[51]由微笑或不微笑的人脸图像组成。数据集中总共有13165个灰度图像,每个图像的大小为64×64。
该数据集中的图像被紧密地裁剪在脸部周围,这使我们能够设计出只关注微笑识别任务的机器学习算法。将计算机视觉预处理与机器学习(尤其是基准数据集)分离是一种你会看到的常见趋势在查看流行的基准数据集时。在某些情况下,假设机器学习研究人员在应用自己的机器学习算法之前有足够的计算机视觉经验来正确预处理图像数据集是不公平的。
这就是说,这一趋势正在迅速改变,任何有兴趣将机器学习应用于计算机视觉问题的实践者都被认为至少具有计算机视觉的基本背景。这一趋势将在未来继续,因此如果你计划在任何深度学习计算机视觉的深度学习,一定要用一点计算机视觉来补充你的教育,即使它只是基础。
如果您发现需要提高计算机视觉技能,请查看实用Python和OpenCV[8]。
5.5 Kaggle: Dogs vs. Cats
“狗对猫”挑战赛是Kaggle竞赛的一部分,旨在设计一种学习算法,将图像正确分类为包含狗或猫的图像。总共提供25000张图像,用于训练具有不同图像分辨率的算法。数据集的示例如图5.5所示。
您决定如何预处理图像可能会导致不同的性能水平,再次证明计算机视觉和图像处理基础知识的背景对学习深度学习有很大帮助。
当我演示如何使用AlexNet架构在Kaggle Dogs vs.Cats排行榜上排名前25位时,我们将在Practices Bundle中使用此数据集。
5.6 Flowers-17
Flowers-17数据集是一个17类数据集,由Nilsback等人策划,每类80幅图像。[52]。该数据集的目标是正确预测给定输入图像的花卉种类。Flowers-17数据集的示例如图5.6所示。
Flowers-17可以被认为是一个具有挑战性的数据集,因为它在规模、视角、背景杂波、不同的照明条件和类内变化等方面发生了巨大变化。此外,由于每堂课只有80张图像,因此深度学习模型在不过度拟合的情况下学习每个类的表示形式变得很有挑战性。作为一般的经验法则,在训练深度神经网络时,建议每个类有1000-5000张示例图像[10]。

我们将研究从业者包中的Flowers-17数据集,并探索使用转移学习方法(如特征提取和微调)改进分类的方法。
5.7 CALTECH-101
由Fei Fei等人[53]于2004年推出的CALTECH-101数据集是一种流行的目标检测基准数据集。通常用于对象检测(即,预测图像中特定对象边界框的(x,y)-坐标),我们也可以使用CALTECH-101研究深度学习算法。
该数据集共有8677幅图像,包括101个类别,涵盖了各种各样的物体,包括大象、自行车、足球,甚至人脑,仅举几个例子。加州理工学院101号数据集显示出严重的阶级不平衡(这意味着某些类别的示例图像比其他类别多),这使得从阶级不平衡的角度进行研究变得有趣。
以前将图像分类到CALTECH-101的方法获得了35-65%的准确率[54,55,56]。然而,正如我将在Practices Bundle中演示的,我们很容易利用深度学习进行图像分类,以获得99%以上的分类准确率。
5.8 Tiny ImageNet 200
斯坦福大学优秀的cs231n:用于视觉识别的卷积神经网络课程[57]为学生提出了一个图像分类挑战,类似于ImageNet挑战,但范围较小。该数据集中共有200个图像类,其中500个图像用于培训,50个图像用于验证,每个类50个图像用于测试。每幅图像都经过预处理并裁剪为64×64×3像素,使学生更容易专注于深度学习技术,而不是计算机视觉预处理功能。

然而,正如我们将在PracticeBundle中发现的那样,Karpathy和Johnson应用的预处理步骤实际上使问题变得更加困难,因为一些重要的、有区别的信息在预处理任务中被裁剪掉了。也就是说,我将演示如何在此数据集上培训VGGNet、GoogLenet和ResNet体系结构,并在排行榜上占据领先地位。
5.9 Adience
Adience数据集由Eidinger et al.2014[58]构建,用于促进年龄和性别识别的研究。数据集中共包含26580张图像,年龄范围为0-60岁。该数据集的目标是正确预测图像中主体的年龄和性别。我们将在ImageNet包中进一步讨论Adience数据集(并构建我们自己的年龄和性别识别系统)。您可以在图5.7中看到Adience数据集的示例。
5.10 ImageNet
在计算机视觉和深度学习社区中,您可能会遇到一些关于ImageNet是什么和不是什么的上下文混淆。
5.10.1什么是ImageNet?
ImageNet实际上是一个项目,旨在根据定义的一组单词和短语将图像标记和分类为近22000个类别。
在撰写本文时,ImageNet项目中有超过1400万张图像。为了组织如此大量的数据,ImageNet遵循WordNet层次结构[59]。WordNet中每个有意义的单词/短语简称为“同义词集”或“同义词集”。在ImageNet项目中,图像根据这些语法集进行组织,目标是每个语法集有1000多个图像。
5.10.2 ImageNet大规模视觉识别挑战赛(ILSVRC)

本次挑战中图像分类跟踪的目标是训练一个模型,该模型可以使用大约120万张图像进行训练,50000张用于验证,100000张用于测试,将图像分类为1000个单独的类别。这1000个图像类别代表我们在日常生活中遇到的对象类,例如狗、猫、各种家庭对象、车辆类型等等。您可以在以下ILSVRC挑战中找到对象类别的完整列表:http://pyimg.co/x1ler.
说到图像分类,ImageNet挑战是计算机视觉分类算法的事实标准——自2012年以来,卷积神经网络和深度学习技术一直占据着这一挑战的排行榜。
在ImageNet捆绑包中,我将演示如何在这个流行的数据集上从头开始训练开创性的网络体系结构(AlexNet、SqueezeNet、VGGNet、GoogLeNet、ResNet),使您能够复制您在各自的研究论文中看到的最新成果。
5.11 Kaggle:面部表情识别挑战
Kaggle提出的另一个挑战,面部表情识别挑战(FER)的目标是从一张人脸照片中正确识别一个人正在经历的情绪。FER挑战赛共提供35888张图像,目标是将给定的面部表情分为七个不同类别:
1.生气2。厌恶(由于阶级不平衡,有时与“恐惧”组合在一起)3。恐惧4。快乐5。悲伤的6。惊喜 7.中立

我将演示如何在ImageNet包中使用此数据集进行情感识别。
5.12 Indoor CVPR
顾名思义,室内场景识别数据集[60]由许多室内场景组成,包括商店、房屋、休闲空间、工作区和公共空间。该数据集的目标是正确训练能够识别每个区域的模型。但是,我们将在ImageNet捆绑包中使用该数据集来自动检测和纠正图像方向,而不是将其用于其原始目的。
5.13 Stanford Cars
斯坦福大学整合的另一个数据集,Cars数据集[61]由196类汽车的16185张图像组成。您可以根据车辆制造商、型号甚至制造商年份,以任何方式对该数据集进行切片和切分。尽管每个类别的图像相对较少(类别严重不平衡),但我将演示如何使用卷积神经网络在标记车辆品牌和型号时获得>95%的分类精度。
5.14摘要
在本章中,我们回顾了在使用Python进行计算机视觉深入学习的剩余部分中您将遇到的数据集。其中一些数据集被认为是“玩具”数据集,是我们可以用来学习神经网络和深度学习的小图像集。由于历史原因,其他数据集很受欢迎,可以作为评估新模型体系结构的优秀基准。最后,像ImageNet这样的数据集仍然是开放式的研究主题,用于推进深度学习的最新技术。
现在花点时间简单地熟悉一下这些数据集——在各自章节中首次介绍这些数据集时,我将详细讨论它们。


上述实验代码详见本人github地址:
TheWangYang/Code_For_Deep_Learning_for_Computer_Vision_with_Python: A code repository for Deep Learning for Computer Vision with Python. (github.com)