论文阅读_知识蒸馏_TinyBERT
英文题目:TINYBERT: DISTILLING BERT FOR NATURAL LAN-GUAGE UNDERSTANDING
中文题目:TinyBERT: 提炼BERT的自然语言理解能力
论文地址:https://arxiv.org/pdf/1909.10351.pdf
领域:NLP,知识蒸馏
发表时间:2020
作者:Xiaoqi Jiao, 华中科技大学
出处:ICLR
被引量:67
代码和数据:https://github.com/Lisennlp/TinyBert
阅读时间:22.09.16
读后感
对BERT模型进行蒸馏,老师模型和学生模型都使用Transformer架构,但是层数和每层的输出维度可以不同,从而实现对模型的精减。
介绍
预训练的大模型难以应用到资源受限的系统中,文中提出针对Transformer模型的蒸馏方法,将BERT模型作为老师模型,将知识蒸馏到学生模型TinyBERT中。同时在预训练和精调的场景中进行蒸馏,它可以达到其老师模型96%的准确率,比老师模型小7.5倍 ,快9.4倍。
实现的具体方法是根据BERT层设计了多种损失函数。与现有模型的差异如表-1所示:

文章贡献
- 优化了基于Transformer框架的蒸馏方法
- 支持预训练和精调两个场景的蒸馏
- 实验证明TinyBERT的效果
方法
蒸馏
蒸馏方法的如公式-5所示:
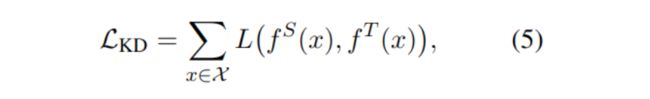
将fs定义为学生模型,将ft定义为老师模型,把实例代入模型,计算预测结果,L()为损失函数,评价师生的差异,目标是尽量让老师与学生结果一致。
Transformer蒸馏
蒸馏方法允许老师和学生是完全不同的模型,TinyBERT设计过程中将老师和学生模型都设计使用Transformer结构。
符号定义
设学生模型有M个Transformer层,老师模型有N个Transformer层,在二者之间建立一个映射函数 n=g(m),学生的第m层从老师的第g(m)层学习。将嵌入层定义为第0层,预测层定义为M+1层。根据经验选择g()映射函数。其整体损失函数定义如下:

公式-6与公式-5类似,它针对学习的m个层优化,λm为超参数,指定每层的重要程度。
Transformer层蒸馏
Transformer层蒸馏包含对注意力的蒸馏和对隐藏状态的蒸馏,如图-2所示:

注意力层的蒸馏致力于学习BERT捕捉的丰富语言学知识,学生模型首先拟合老师模型的多头注意力,损失函数如下:
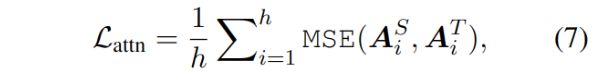
其中h是头数,A为注意力矩阵,MSE为均方误差损失。这里直接使用Attention,而未使用归一化的softmax,是由于实验证明直接使用效果更好。
除了Attention,还对transformer层的输出进行了拟合:
![[Pasted image 20220916212451.png]]
这里的HS和HT分别是学生和老师模型的隐藏层,学生模型隐藏层的维度往往小于老师层的维度,使用W参数在两个维度间进行转换。
嵌入层蒸馏
嵌入层的蒸馏与上述隐藏层处理方法类似,也可使用不同维度,通过W进行映射,本文中使用了相同维度。
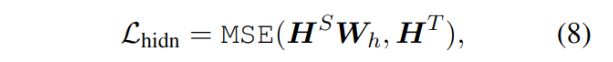
预测层蒸馏
另外,还对最后一层的预测层进行了蒸馏,具体使用了软的交叉熵作为损失函数,这是为了从老师模型中除了最终结果类别,还能学到每一个类别的匹配度。
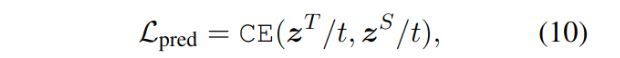
其中zS和zT分别对学生和老师预测的向量进行指数运算,t是温度系数,本文实验中t=1时表现最好。
综上,对不同层使用不同的损失函数:

TinyBERT学习
一般训练BERT模型包含两个场景:预训练和精调。对预训练模型的蒸馏将丰富的语言学知识转换到小模型中,提升小模型的泛化性能。流程如图-1所示:
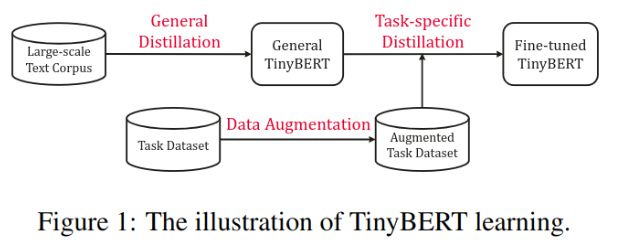
另外,还支持进一步针对具体任务的蒸馏。
通用蒸馏
使用普通的BERT作为老师模型,并利用大规模数据集来蒸馏,生成的TinyBERT可用于进一步训练下游任务。此处训练出的TinyBERT是一个中间模型,效果比BERT差。
针对任务蒸馏
由于大模型的众多参数不一定都能通过精调优化,精调质量不一定很高,所以蒸馏模型有可能达到与普通的调优模型类似的效果。此处,用附加的针对任务的数据调优模型。将针对任务调优的BERT模型作为老师,使用数据增强方法来扩展训练数据,以提升学生模型的泛化能力。
数据增强
使用预训练的BERT和GloVE词嵌入实现词级别替换来增强数据。
用BERT来找到单个词替换,用Glove词嵌入来检索最相似的词组替换,通过概率p来决定是否替换当前词。算法-1展示了数据加强的方法。预训练的蒸馏模型为针对任务的模型提供初始模型参数。

实验
主实验结果如表-1所示:

可以看到,TinyBERT 在参数少且速度快的情况下,相对于其它小模型效果更好,基本于MobileBERT持平。